ElasticSearch实战(四十七)-Canal 实现 MySQL 数据实时同步方案
Posted 张志翔ۤ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch实战(四十七)-Canal 实现 MySQL 数据实时同步方案相关的知识,希望对你有一定的参考价值。
Canal 主要用途是基于 mysql 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 Canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
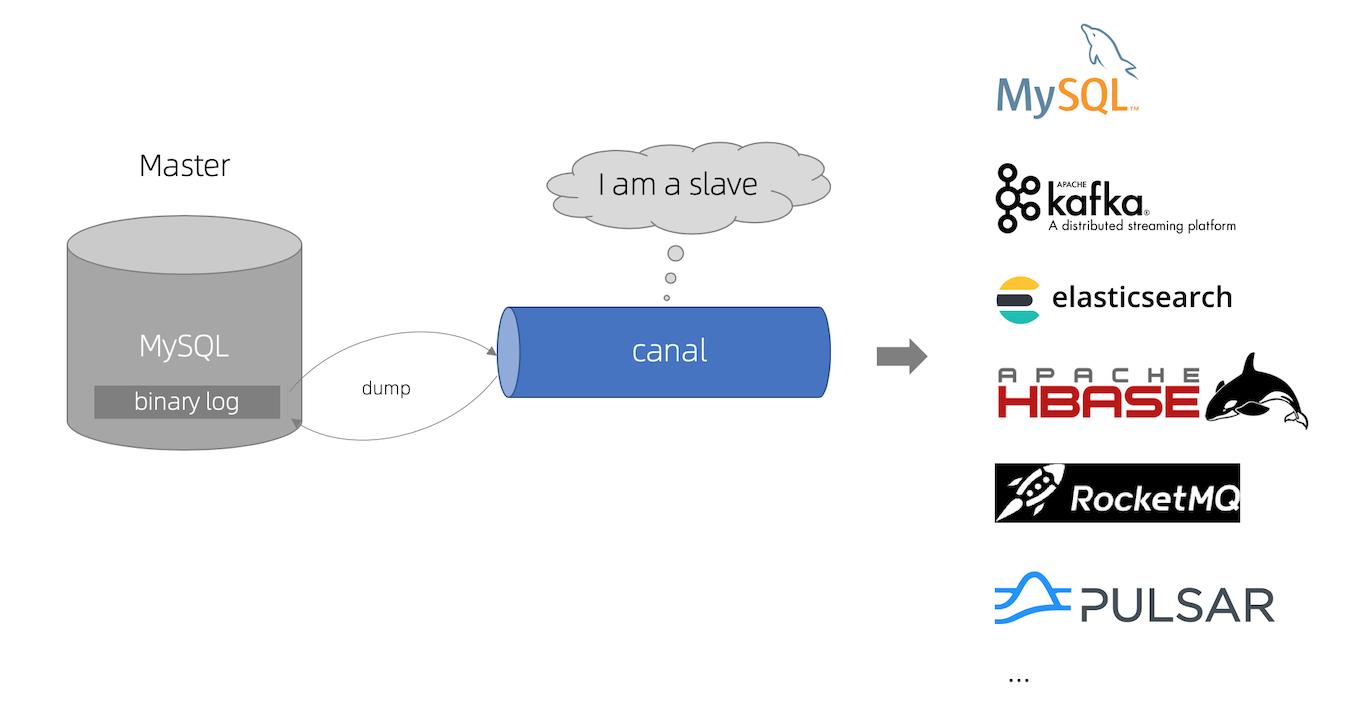
一、Canal 工作原理
1、工作原理
MySQL主备复制原理:
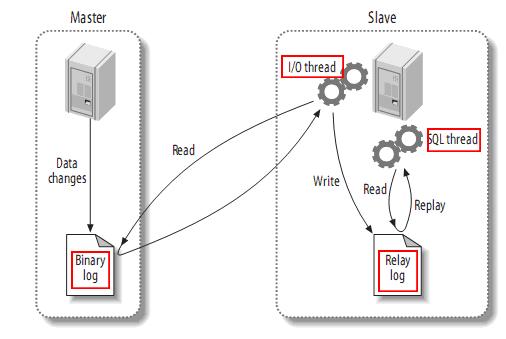
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
Canal 工作原理:
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
二、Canal 快速开始
对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下:
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
注:针对阿里云 RDS for MySQL , 默认打开了 binlog , 并且账号默认具有 binlog dump 权限 , 不需要任何权限或者 binlog 设置,可以直接跳过这一步
授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
1、启动
下载 canal, 访问 release 页面 , 选择需要的包下载, 如以 1.1.5 版本为例,命令如下:
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
解压缩,命令如下:
$ mkdir /tmp/canal
$ tar zxvf canal.deployer-$version.tar.gz -C /tmp/canal
解压完成后,进入 /tmp/canal 目录,可以看到如下结构:
drwxr-xr-x 2 jianghang jianghang 136 2013-02-05 21:51 bin
drwxr-xr-x 4 jianghang jianghang 160 2013-02-05 21:51 conf
drwxr-xr-x 2 jianghang jianghang 1.3K 2013-02-05 21:51 lib
drwxr-xr-x 2 jianghang jianghang 48 2013-02-05 21:29 logs
配置修改,命令如下:
$ vim conf/example/instance.properties## mysql serverId
canal.instance.mysql.slaveId = 1234
#position info,需要改成自己的数据库信息
canal.instance.master.address = 127.0.0.1:3306
canal.instance.master.journal.name =
canal.instance.master.position =
canal.instance.master.timestamp =
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#username/password,需要改成自己的数据库信息
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
canal.instance.defaultDatabaseName =
canal.instance.connectionCharset = UTF-8
#table regex
canal.instance.filter.regex = .\\*\\\\\\\\..\\*
- canal.instance.connectionCharset 代表数据库的编码方式对应到 java 中的编码类型,比如 UTF-8,GBK , ISO-8859-1
- 如果系统是1个 cpu,需要将 canal.instance.parser.parallel 设置为 false
启动,命令如下:
$ sh bin/startup.sh
查看 server 日志,命令如下:
$ vim logs/canal/canal.log</pre>
2013-02-05 22:45:27.967 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## start the canal server.
2013-02-05 22:45:28.113 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[10.1.29.120:11111]
2013-02-05 22:45:28.210 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## the canal server is running now ......
查看 instance 的日志,命令如下:
$ vim logs/example/example.log
2013-02-05 22:50:45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]
2013-02-05 22:50:45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]
2013-02-05 22:50:45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2013-02-05 22:50:45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful....
2、关闭
$ sh bin/stop.sh到此就完成了快速启动,一般工作中不会这么干,一般是和kafka一起使用。
三、Kafka快速开始
1、环境版本
- 操作系统:CentOS release 7.8
- java版本: jdk1.8
- kafka 版本: kafka_2.11-1.1.1.tgz
2、安装kafka
下载压缩包, 复制到固定目录并解压,命令如下:
$ wget https://www.apache.org/dyn/closer.cgi?path=/kafka/1.1.1/kafka_2.11-1.1.1.tgz
$ mkdir -p /usr/local/kafka
$ cp kafka_2.11-1.1.1.tgz /usr/local/kafka
$ tar -zxvf kafka_2.11-1.1.1.tgz
3、修改配置文件
$ vim /usr/local/kafka/kafka_2.11-1.1.1/config/server.properties
zookeeper.connect=192.168.1.110:2181
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://192.168.1.117:9092 #本机ip
# ...
4、启动server
启动kafka,命令如下:
$ bin/kafka-server-start.sh -daemon config/server.properties &
查看所有topic,命令如下:
$ bin/kafka-topics.sh --list --zookeeper 192.168.1.110:2181
查看指定 topic 下面的数据,命令如下:
$ bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.117:9092 --from-beginning --topic example_t
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
到此就完成了kafka快速启动。
四、Zookeeper 快速开始
1、环境版本
- 操作系统:CentOS release 7.8
- java版本: jdk1.8
- zookeeper版本: zookeeper-3.4.11
2、安装jdk
安装文章已经准备好,传送门如下:
3、安装zookeeper
下载源码包,并解压,命令如下:
$ wget http://mirror.olnevhost.net/pub/apache/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
$ tar zxvf zookeeper-3.4.11.tar.gz
$ mv zookeeper-3.4.11 /usr/local/zookeeper
4、修改环境变量
编辑 /etc/profile 文件, 在文件末尾添加以下环境变量配置:
# ZooKeeper Env
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
运行以下命令使环境变量生效:
$ source /etc/profile5、重命名配置文件
初次使用 ZooKeeper 时,需要将$ZOOKEEPER_HOME/conf 目录下的 zoo_sample.cfg 重命名为 zoo.cfg, zoo.cfg,命令如下:
$ mv $ZOOKEEPER_HOME/conf/zoo_sample.cfg $ZOOKEEPER_HOME/conf/zoo.cfg
6、单机模式--修改配置文件
创建目录/usr/local/zookeeper/data 和/usr/local/zookeeper/logs 修改配置文件
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
clientPort=2181
如果是多节点,配置文件中尾部增加
server.1=192.168.1.110:2888:3888
server.2=192.168.1.111:2888:3888
server.3=192.168.1.112:2888:3888
同时,增加
#master
echo "1">/usr/local/zookeeper/data/myid
#slave1
echo "2">/usr/local/zookeeper/data/myid
#slave2
echo "3">/usr/local/zookeeper/data/myid
7、启动 ZooKeeper 服务
# cd /usr/local/zookeeper/zookeeper-3.4.11/bin
# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.11/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Mode: follower
8、验证ZooKeeper服务
服务启动完成后,可以使用 telnet 和 stat 命令验证服务器启动是否正常:
# telnet 127.0.0.1 2181
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.
stat
Zookeeper version: 3.4.11-37e277162d567b55a07d1755f0b31c32e93c01a0, built on 11/01/2017 18:06 GMT
Clients:
/127.0.0.1:48430[0](queued=0,recved=1,sent=0)
Latency min/avg/max: 0/0/0
Received: 1
Sent: 0
Connections: 1
Outstanding: 0
Zxid: 0x0
Mode: standalone
Node count: 4
Connection closed by foreign host.
9、停止 ZooKeeper 服务
想要停止 ZooKeeper 服务, 可以使用如下命令:
# cd /usr/local/zookeeper/zookeeper-3.4.11/bin
# ./zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.11/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED10、zk ui安装 (选装,页面查看zk的数据)
拉取代码,命令如下:
$ git clone https://github.com/DeemOpen/zkui.git
源码编译需要安装 maven,命令如下:
$ wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
$ cd zkui/
$ yum install -y maven
$ mvn clean install
修改配置文件默认值,命令如下:
$ vim config.cfg
serverPort=9090 #指定端口
zkServer=192.168.1.110:2181
sessionTimeout=300000
11、启动程序至后台
2.0-SNAPSHOT 会随软件的更新版本不同而不同,执行时请查看target 目录中真正生成的版本,命令如下:
$ nohup java -jar target/zkui-2.0-SNAPSHOT-jar-with-dependencies.jar &
用浏览器访问:http://192.168.1.110:9090/
五、Canal Kafka 快速启动
Canal 1.1.1版本之后, 默认支持将canal server接收到的binlog数据直接投递到MQ, 目前默认支持的MQ系统有:
- kafka: GitHub - apache/kafka: Mirror of Apache Kafka
- RocketMQ : GitHub - apache/rocketmq: Mirror of Apache RocketMQ
1、环境版本
- 操作系统:CentOS release 7.8
- java版本: jdk1.8
- canal 版本: 请下载最新的安装包,本文以当前v1.1.1 的canal.deployer-1.1.1.tar.gz为例
- MySQL版本 :5.7.18
- 注意 : 关闭所有机器的防火墙,同时注意启动可以相互telnet ip 端口
2、安装zookeeper
参照上面的zookeeper快速开始。
3、安装kafka
参照上面的kafka快速开始。
4、安装canal.server
下载压缩包,到官网地址(release)下载最新压缩包,请下载 canal.deployer-latest.tar.gz,将canal.deployer 复制到固定目录并解压,命令如下:
$ mkdir -p /usr/local/canal
$ cp canal.deployer-1.1.5.tar.gz /usr/local/canal
$ tar -zxvf canal.deployer-1.1.5.tar.gz
5、配置修改参数
首先修改 instance 配置文件,命令如下:
$ vim conf/example/instance.properties# 按需修改成自己的数据库信息
#################################################
...
canal.instance.master.address=192.168.1.20:3306
# username/password,数据库的用户名和密码
...
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
...
# mq config
canal.mq.topic=example
# 针对库名或者表名发送动态topic
#canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\\\..*,.*\\\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#库名.表名: 唯一主键,多个表之间用逗号分隔
#canal.mq.partitionHash=mytest.person:id,mytest.role:id
#################################################对应 ip 地址的MySQL 数据库需进行相关初始化与设置, 可参考上述 Canal 快速开始。
然后修改 canal 配置文件,打开配置文件,命令如下:
$ vim /usr/local/canal/conf/canal.properties# ...
# 可选项: tcp(默认), kafka, RocketMQ
canal.serverMode = kafka
# ...
# kafka/rocketmq 集群配置: 192.168.1.117:9092,192.168.1.118:9092,192.168.1.119:9092
canal.mq.servers = 127.0.0.1:6667
canal.mq.retries = 0
# flagMessage模式下可以调大该值, 但不要超过MQ消息体大小上限
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
# flatMessage模式下请将该值改大, 建议50-200
canal.mq.lingerMs = 1
canal.mq.bufferMemory = 33554432
# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时
canal.mq.canalGetTimeout = 100
# 是否为flat json格式对象
canal.mq.flatMessage = false
canal.mq.compressionType = none
canal.mq.acks = all
# kafka消息投递是否使用事务
canal.mq.transaction = falsemq 相关参数说明,如下所示:
| 参数名 | 参数说明 | 默认值 |
|---|---|---|
| canal.mq.servers | kafka为bootstrap.servers rocketMQ中为nameserver列表 | 127.0.0.1:6667 |
| canal.mq.retries | 发送失败重试次数 | 0 |
| canal.mq.batchSize | kafka为ProducerConfig.BATCH_SIZE_CONFIGrocketMQ无意义 | 16384 |
| canal.mq.maxRequestSize | kafka为ProducerConfig.MAX_REQUEST_SIZE_CONFIGrocketMQ无意义 | 1048576 |
| canal.mq.lingerMs | kafka为ProducerConfig.LINGER_MS_CONFIG , 如果是flatMessage格式建议将该值调大, 如: 200rocketMQ无意义 | 1 |
| canal.mq.bufferMemory | kafka为ProducerConfig.BUFFER_MEMORY_CONFIGrocketMQ无意义 | 33554432 |
| canal.mq.acks | kafka为ProducerConfig.ACKS_CONFIGrocketMQ无意义 | all |
| canal.mq.kafka.kerberos.enable | kafka为ProducerConfig.ACKS_CONFIGrocketMQ无意义 | false |
| canal.mq.kafka.kerberos.krb5FilePath | kafka kerberos认证 rocketMQ无意义 | ../conf/kerberos/krb5.conf |
| canal.mq.kafka.kerberos.jaasFilePath | kafka kerberos认证 rocketMQ无意义 | ../conf/kerberos/jaas.conf |
| canal.mq.producerGroup | kafka无意义 rocketMQ为ProducerGroup名 | Canal-Producer |
| canal.mq.accessChannel | kafka无意义 rocketMQ为channel模式,如果为aliyun则配置为cloud | local |
| --- | --- | --- |
| canal.mq.vhost= | rabbitMQ配置 | 无 |
| canal.mq.exchange= | rabbitMQ配置 | 无 |
| canal.mq.username= | rabbitMQ配置 | 无 |
| canal.mq.password= | rabbitMQ配置 | 无 |
| canal.mq.aliyunuid= | rabbitMQ配置 | 无 |
| --- | --- | --- |
| canal.mq.canalBatchSize | 获取canal数据的批次大小 | 50 |
| canal.mq.canalGetTimeout | 获取canal数据的超时时间 | 100 |
| canal.mq.parallelThreadSize | mq数据转换并行处理的并发度 | 8 |
| canal.mq.flatMessage | 是否为json格式 如果设置为false,对应MQ收到的消息为protobuf格式 需要通过CanalMessageDeserializer进行解码 | false |
| --- | --- | --- |
| canal.mq.topic | mq里的topic名 | 无 |
| canal.mq.dynamicTopic | mq里的动态topic规则, 1.1.3版本支持 | 无 |
| canal.mq.partition | 单队列模式的分区下标, | 1 |
| canal.mq.partitionsNum | 散列模式的分区数 | 无 |
| canal.mq.partitionHash | 散列规则定义 库名.表名 : 唯一主键,比如mytest.person: id 1.1.3版本支持新语法,见下文 | 无 |
canal.mq.dynamicTopic 表达式说明:
Canal 1.1.3版本之后, 支持配置格式:schema 或 schema.table,多个配置之间使用逗号或分号分隔
- 例子1:test\\\\.test 指定匹配的单表,发送到以test_test为名字的topic上
- 例子2:.*\\\\..* 匹配所有表,则每个表都会发送到各自表名的topic上
- 例子3:test 指定匹配对应的库,一个库的所有表都会发送到库名的topic上
- 例子4:test\\\\..* 指定匹配的表达式,针对匹配的表会发送到各自表名的topic上
- 例子5:test,test1\\\\.test1,指定多个表达式,会将test库的表都发送到test的topic上,test1\\\\.test1的表发送到对应的test1_test1 topic上,其余的表发送到默认的canal.mq.topic值
为满足更大的灵活性,允许对匹配条件的规则指定发送的topic名字,配置格式:topicName:schema 或 topicName:schema.table
- 例子1: test:test\\\\.test 指定匹配的单表,发送到以test为名字的topic上
- 例子2: test:.*\\\\..* 匹配所有表,因为有指定topic,则每个表都会发送到test的topic下
- 例子3: test:test 指定匹配对应的库,一个库的所有表都会发送到test的topic下
- 例子4:testA:test\\\\..* 指定匹配的表达式,针对匹配的表会发送到testA的topic下
- 例子5:test0:test,test1:test1\\\\.test1,指定多个表达式,会将test库的表都发送到test0的topic下,test1\\\\.test1的表发送到对应的test1的topic下,其余的表发送到默认的canal.mq.topic值
大家可以结合自己的业务需求,设置匹配规则,建议MQ开启自动创建topic的能力。
canal.mq.partitionHash 表达式说明
Canal 1.1.3版本之后, 支持配置格式:schema.table:pk1^pk2,多个配置之间使用逗号分隔
- 例子1:test\\\\.test:pk1^pk2 指定匹配的单表,对应的hash字段为pk1 + pk2
- 例子2:.*\\\\..*:id 正则匹配,指定所有正则匹配的表对应的hash字段为id
- 例子3:.*\\\\..*:$pk$ 正则匹配,指定所有正则匹配的表对应的hash字段为表主键(自动查找)
- 例子4: 匹配规则啥都不写,则默认发到0这个partition上
- 例子5:.*\\\\..* ,不指定pk信息的正则匹配,将所有正则匹配的表,对应的hash字段为表名
- 按表hash: 一张表的所有数据可以发到同一个分区,不同表之间会做散列 (会有热点表分区过大问题)
- 例子6: test\\\\.test:id,.\\\\..* , 针对test的表按照id散列,其余的表按照table散列
注意:大家可以结合自己的业务需求,设置匹配规则,多条匹配规则之间是按照顺序进行匹配(命中一条规则就返回)
mq 顺序性问题
binlog 本身是有序的,写入到mq之后如何保障顺序是很多人会比较关注,在issue里也有非常多人咨询了类似的问题,这里做一个统一的解答
- canal目前选择支持的kafka/rocketmq,本质上都是基于本地文件的方式来支持了分区级的顺序消息的能力,也就是binlog写入mq是可以有一些顺序性保障,这个取决于用户的一些参数选择
- canal支持MQ数据的几种路由方式:单topic单分区,单topic多分区、多topic单分区、多topic多分区
- canal的消费顺序性,主要取决于描述2中的路由选择,举例说明:
- canal.mq.dynamicTopic,主要控制是否是单topic还是多topic,针对命中条件的表可以发到表名对应的topic、库名对应的topic、默认topic name
- canal.mq.partitionsNum、canal.mq.partitionHash,主要控制是否多分区以及分区的partition的路由计算,针对命中条件的可以做到按表级做分区、pk级做分区等
- 单topic单分区,可以严格保证和binlog一样的顺序性,缺点就是性能比较慢,单分区的性能写入大概在2~3k的TPS
- 多topic单分区,可以保证表级别的顺序性,一张表或者一个库的所有数据都写入到一个topic的单分区中,可以保证有序性,针对热点表也存在写入分区的性能问题
- 单topic、多topic的多分区,如果用户选择的是指定table的方式,那和第二部分一样,保障的是表级别的顺序性(存在热点表写入分区的性能问题),如果用户选择的是指定pk hash的方式,那只能保障的是一个pk的多次binlog顺序性 ** pk hash的方式需要业务权衡,这里性能会最好,但如果业务上有pk变更或者对多pk数据有顺序性依赖,就会产生业务处理错乱的情况. 如果有pk变更,pk变更前和变更后的值会落在不同的分区里,业务消费就会有先后顺序的问题,需要注意
MQ发送性能数据
1.1.5版本可以在5k~50k左右,具体可参考:Canal-MQ-Performance
6、启动
$ cd /usr/local/canal/
$ sh bin/startup.sh
7、查看日志
查看 logs/canal/canal.log,命令如下:
$ vim logs/canal/canal.log查看instance的日志,命令如下:
$ vim logs/example/example.log
8、关闭
$ cd /usr/local/canal/
$ sh bin/stop.sh
9、MQ数据消费
canal.client下有对应的MQ数据消费的样例工程,包含数据编解码的功能
- kafka模式: com.alibaba.otter.canal.example.kafka.CanalKafkaClientExample
- rocketMQ模式: com.alibaba.otter.canal.example.rocketmq.CanalRocketMQClientExample
六、Canal Admin 快速启动
canal-admin设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作
1、准备
canal-admin 的限定依赖:
- MySQL,用于存储配置和节点等相关数据
- canal版本,要求>=1.1.4 (需要依赖canal-server提供面向admin的动态运维管理接口)
2、部署
下载 canal-admin, 访问 release 页面 , 选择需要的包下载, 如以 1.1.4 版本为例:
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.admin-1.1.5.tar.gz
解压缩,命令如下:
$ mkdir /tmp/canal-admin
$ tar zxvf canal.admin-$version.tar.gz -C /tmp/canal-admin
解压完成后,进入 /tmp/canal 目录,可以看到如下结构:
drwxr-xr-x 6 agapple staff 204B 8 31 15:37 bin
drwxr-xr-x 8 agapple staff 272B 8 31 15:37 conf
drwxr-xr-x 90 agapple staff 3.0K 8 31 15:37 lib
drwxr-xr-x 2 agapple staff 68B 8 31 15:26 logs
配置修改,命令如下:
vim conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: canal
password: canal
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin初始化元数据库,命令如下:
mysql -h127.1 -uroot -p
# 导入初始化SQL
> source conf/canal_manager.sql
初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化 b. canal_manager.sql默认会在conf目录下,也可以通过链接下载 canal_manager.sql
3、启动
$ sh bin/startup.sh
查看 admin 日志,命令如下:
$ vim logs/admin.log
2019-08-31 15:43:38.162 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat initialized with port(s): 8089 (http)
2019-08-31 15:43:38.180 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Initializing ProtocolHandler ["http-nio-8089"]
2019-08-31 15:43:38.191 [main] INFO org.apache.catalina.core.StandardService - Starting service [Tomcat]
2019-08-31 15:43:38.194 [main] INFO org.apache.catalina.core.StandardEngine - Starting Servlet Engine: Apache Tomcat/8.5.29
....
2019-08-31 15:43:39.789 [main] INFO o.s.w.s.m.m.annotation.ExceptionHandlerExceptionResolver - Detected @ExceptionHandler methods in customExceptionHandler
2019-08-31 15:43:39.825 [main] INFO o.s.b.a.web.servlet.WelcomePageHandlerMapping - Adding welcome page: class path resource [public/index.html]
此时代表canal-admin已经启动成功,可以通过 http://127.0.0.1:8089/ 访问,默认密码:admin/123456,图示如下:
4、关闭
$ sh bin/stop.sh
5、canal-server端配置
使用canal_local.properties的配置覆盖canal.properties
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
启动admin-server即可。
或在启动命令中使用参数:sh bin/startup.sh local 指定配置。
到此 Canal 实现 MySQL 数据实时同步方案介绍完成。
以上是关于ElasticSearch实战(四十七)-Canal 实现 MySQL 数据实时同步方案的主要内容,如果未能解决你的问题,请参考以下文章