自动驾驶中单目摄像头检测输出3-D边界框的方法一览
Posted CVer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动驾驶中单目摄像头检测输出3-D边界框的方法一览相关的知识,希望对你有一定的参考价值。
重磅干货,第一时间送达
https://zhuanlan.zhihu.com/p/57029694
本文已由原作者授权,未经允许,不得二次转载
单目图像估计3-D检测框是目前自动驾驶研发流行的,单纯的2-D检测框无法在3-D空间去做规划控制,去年百度Apollo发布2.5版本特意提到这方面的解决方案。
这里分析一下公开发表的有关论文,特别是近期的深度学习CNN框架,供参考。
其实最早看到3-D BBox的工作是Mobileye以前的CEO Shashua教授给的PPT demo(没有paper了):
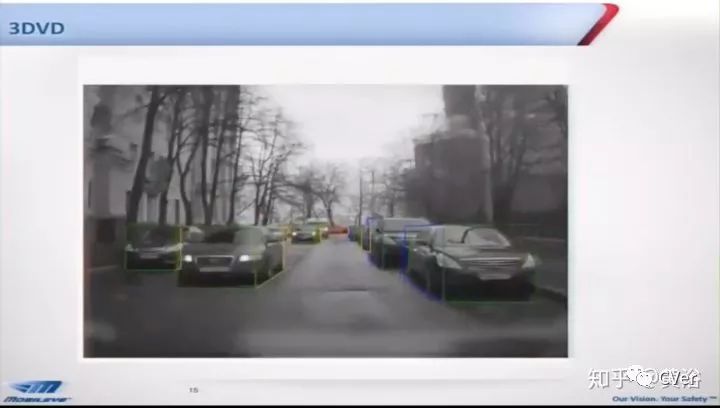
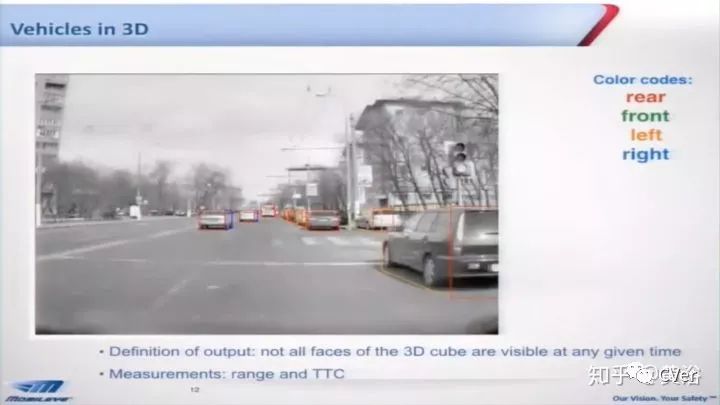

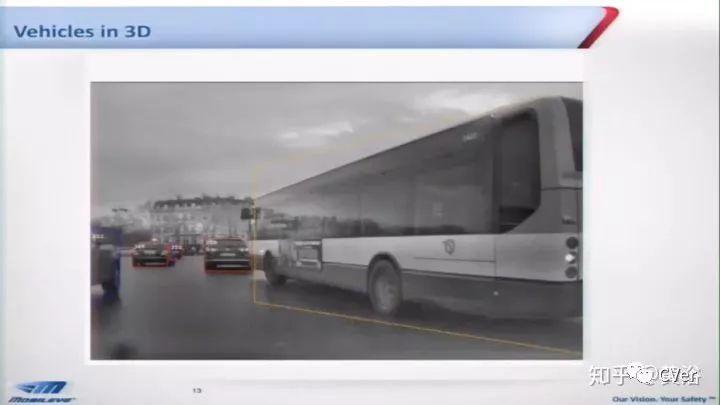
结果Tesla和Nvidia全都这么干了,潮流:)。
注:关于单目镜头估计物体的姿态有不少论文,也是跟这个课题相关的,一些深度学习的方法也不错,不过不是本文的重点,在此不做重复介绍。
3D Bounding Boxes for Road Vehicles: A One-Stage, Localization Prioritized Approach using Single Monocular Images,9,2018
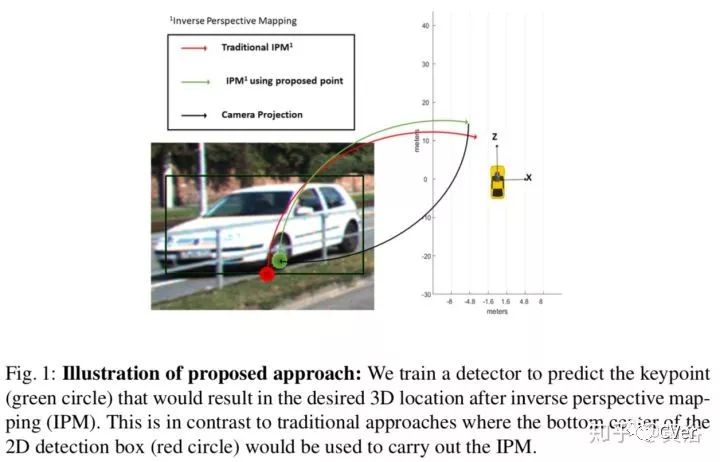
来自UC San Diego的论文。简单讲,该方法提出估计center of bottom face of 3D bounding box (CBF) 来解决2-D图像得到3-D边框的问题,为加速也采用了LUT。同时估计的还有物体的大小尺寸以及姿态。
下图解释了他们采用key point预测的方法而不是传统2-D边框底边中心去推理3-D的位置。
这是他们的3-D边框估计的算法结构:
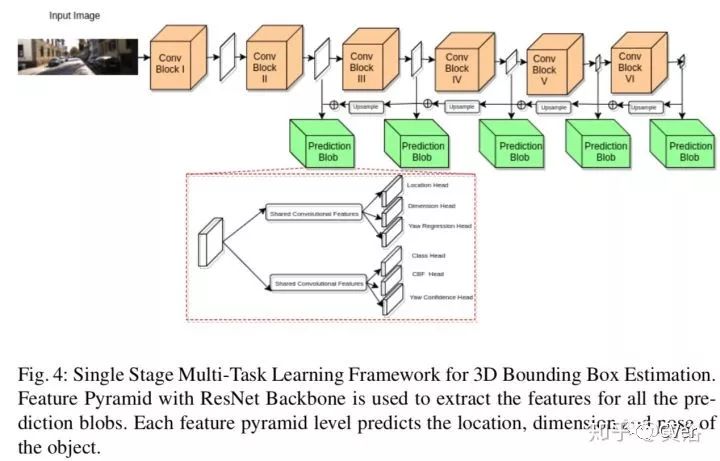
3D Bounding Box Estimation Using Deep Learning and Geometry,CVPR,2017
该文也是百度Apollo引用的方法:
首先估计物体3-D朝向,然后回归物体尺寸和3-D中心,最后得到物体的整个姿态和位置。这是2-D和3-D边框的对应关系图:

论文提出一种MultiBin方法求解物体朝向(相邻bin之间可以重叠一部分),CNN模型如下图:
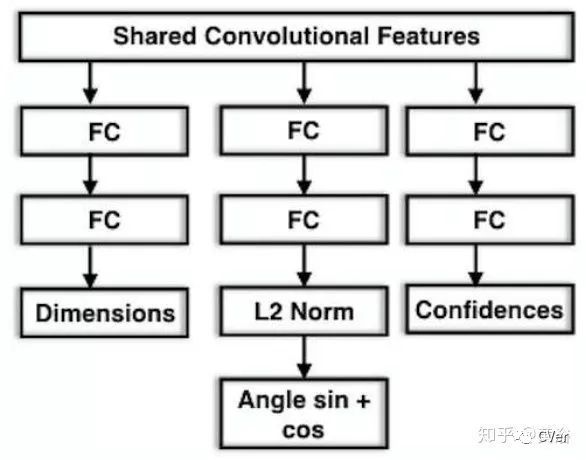
朝向的局部和全局的关系如下所示:
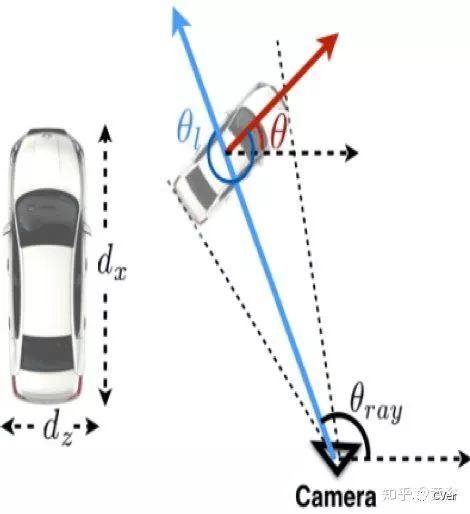
总之,该方法利用了几何约束从2-D边框来估计3-D边框,其中朝向估计很关键。一些结果见下图:

Joint Monocular 3D Vehicle Detection and Tracking, 11,2018
该方法是对上面工作的推广,增加了跟踪模块,提高了稳定性。
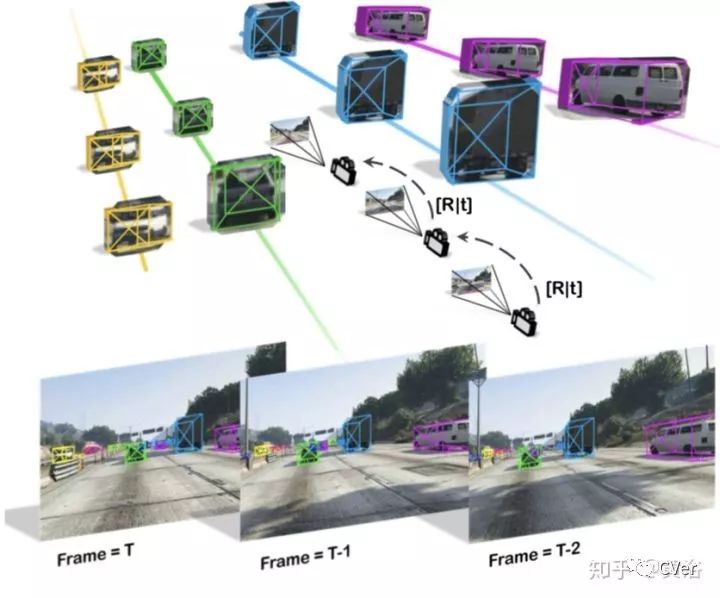
这是算法的流程图:在RPN预测3-D中心的2-D投影位置,其中采用ROIalign而不是ROIpool减小了misalignment。每个求解3-D边框的ROI包括以下几项:2d Bbox, 3d box 中心投影, confidence score 和 对应特征向量。
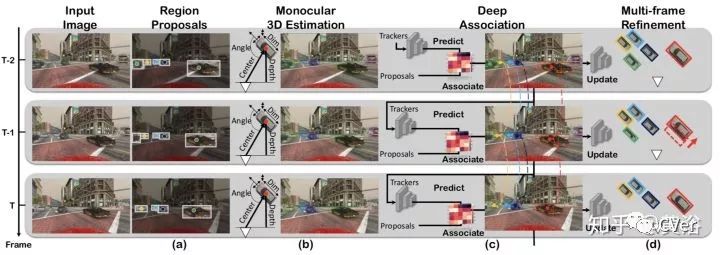
其他跟踪部分就不重点提了,下图是一些结果展示:

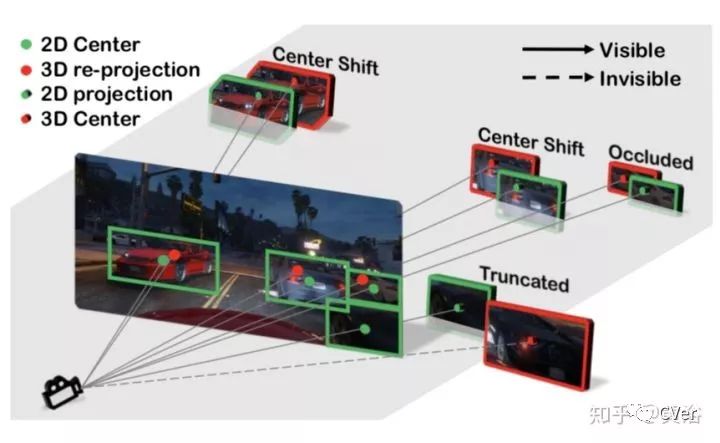
下图解释了2-D边框中心和3-D边框中心的不同:
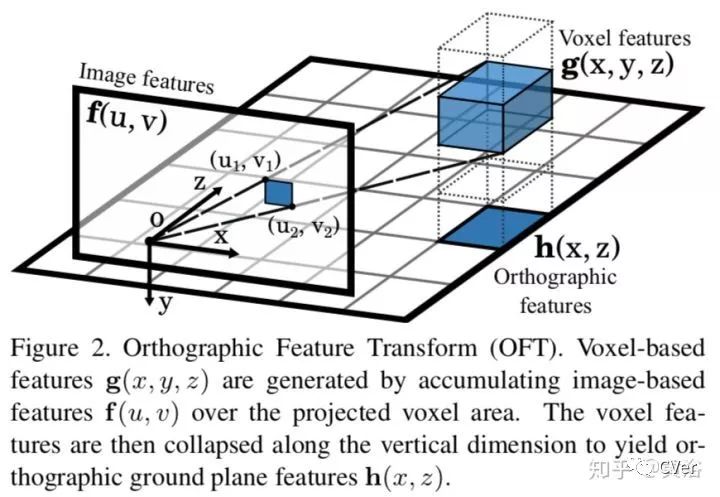
Orthographic Feature Transform for Monocular 3D Object Detection,11,2018
本文提出一个orthographic feature transform(OFT)用于解决2-D图像推理物体3-D边框的问题,原理如下图:
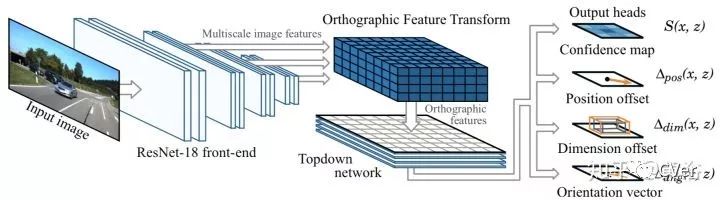
在一个深度学习框架下,该模块可以把图像特征图映射到正交鸟瞰图,如下图所示,输入到一个top down network进行推理。
结果就不讨论了,细节在论文里。
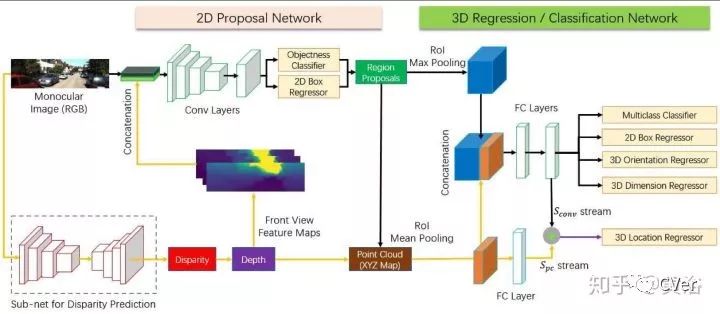
Multi-Level Fusion based 3D Object Detection from Monocular Images, CVPR, 2018
这是去年CVPR‘18的论文,下面是算法结构: 采用两步法,加了一个估计深度图的模型,结果送入RPN模块,比较奢侈的做法,后面还将视差图转换成点云,进入detection模块。
这是他们展示的结果:

看来大家对单目估计深度图/视差图很有信心。
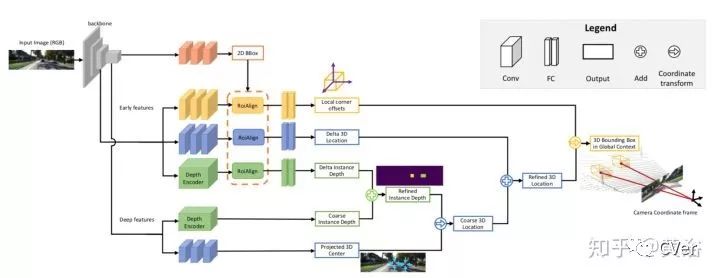
MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization, 11, 2018
微软的一篇论文,下图是算法框图:提出instance depth estimation (IDE),不是图像的深度图,可以直接估计物体3-D边框的深度,还是采用ROIalign取代ROIpool;包括4个模块,即2d detection(棕色), instance depth estimation(绿色), 3d location estimation(蓝色) 和 local corner regression(黄色)。
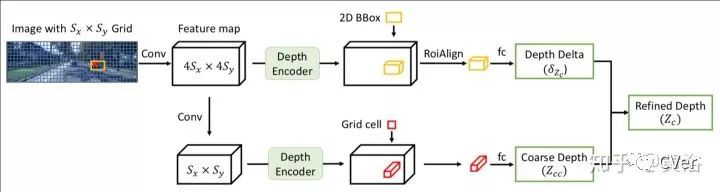
这是估计Instance depth的模型结构:
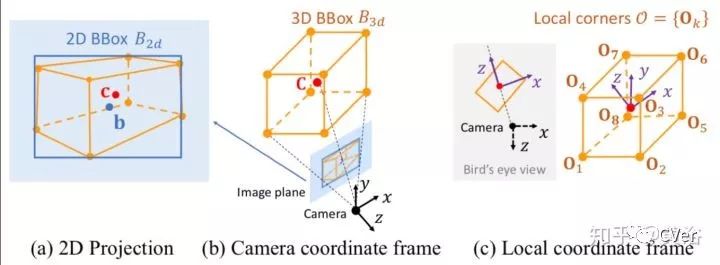
这个示意图告诉我们3-D边框的图像定位关系:
Instance depth的概念的解释如下图,的确是比较节俭的做法:
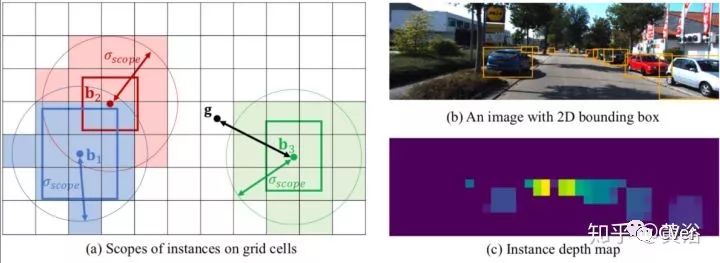
一些结果展示:

Mono3D++: Monocular 3D Vehicle Detection with Two-Scale 3D Hypotheses and Task Priors, 1, 2019
Face++和UCLA的最新论文,算法框图见下图:该方法不光用了深度估计,还借用了路面假设作为约束;另外,采用morphable wireframe model,不过为避免landmark敏感,对3-D边框做了模糊表示;除此之外,还有一个模块叫3D-2D consistency。

这是3D-2D consistency的框图介绍:包括几个部分 2D Bounding box,2D Landmark,3D Orientation 和 scale hypotheses。
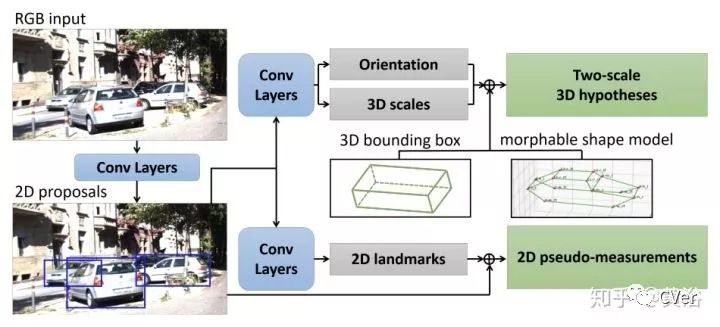
感觉还是比较奢侈的做法。
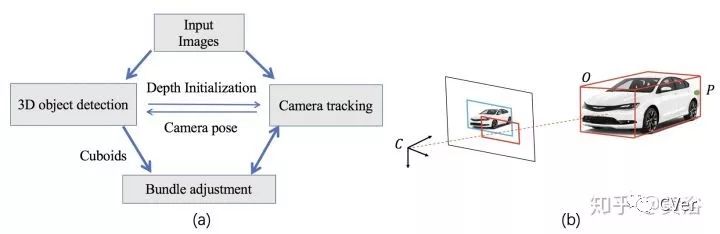
CubeSLAM: Monocular 3D Object Detection and SLAM without Prior Models, 6, 2018
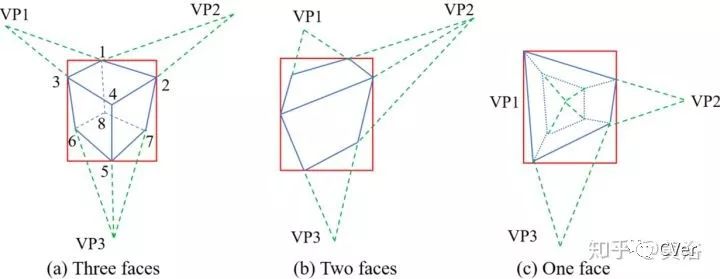
从2-D边框和消失点产生3-D cuboid proposals,随后在单目视觉SLAM框架中优化,如下图:
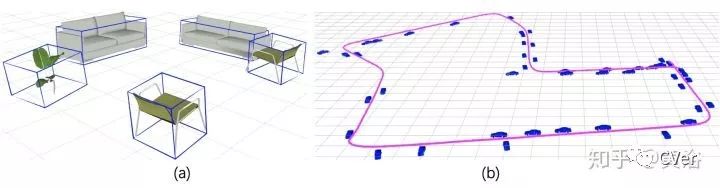
这是产生Proposals的方法:根据可视的面数目将Cuboids分成3类
下面是SLAM框架:在ORB SLAM基础上改进,加入物体信息。
特征点的相关性处理方法采用物体点为先,景物点为后,如图:绿色点是map上的,其他颜色的点属于物体。
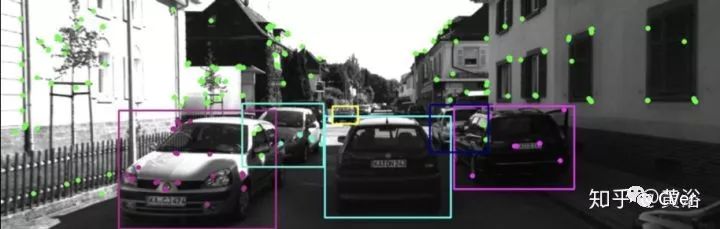
一些结果展示:

BoxCars: Improving Fine-Grained Recognition of Vehicles using 3D Bounding Boxes in Traffic Surveillance,CVPR,2016
3D 物体边框是从监控视频 (比车载视频容易些)的2-D边框得到的,如图所示:利用了轮廓信息和姿态信息。
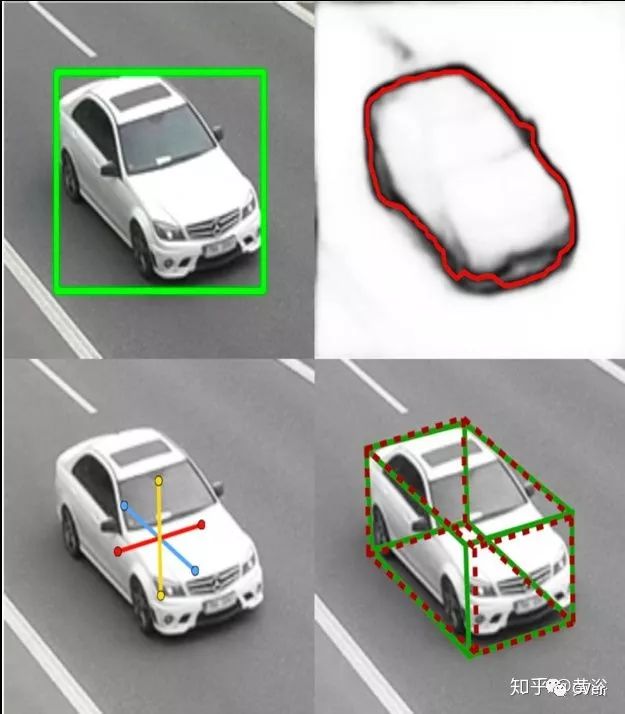
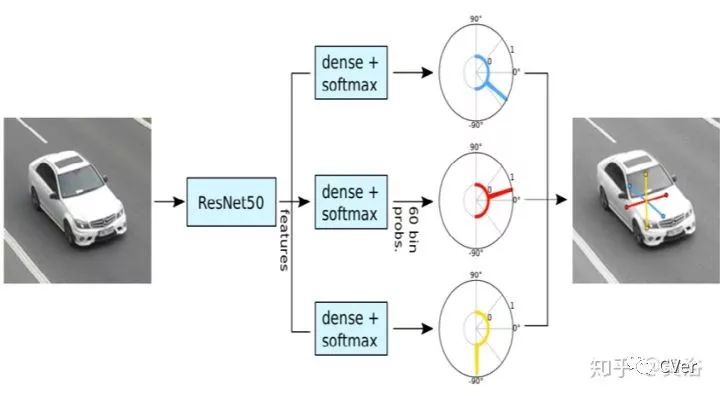
其实它的方法是把3-D边框各个面拆开,如图:然后输入到CNN模型推理3-D信息。

这个CNN模型用来估计沿着消失点的方向:
结果是这样的:

Vehicle Detection and Pose Estimation for Autonomous Driving (Thesis),2017
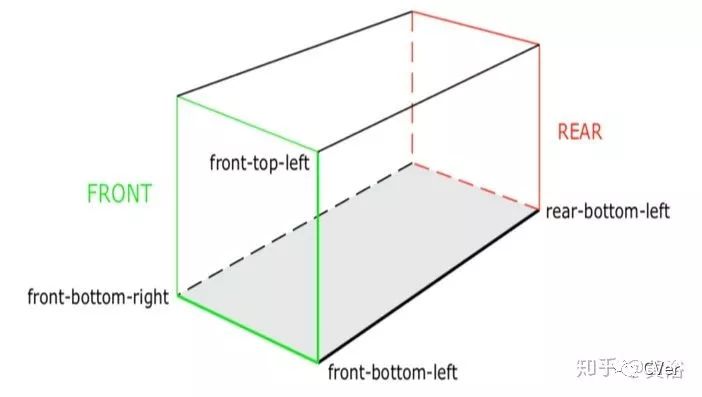
一个博士论文。采用FCN模型训练得到2-D和3-D边框,如图:定义3-D边框的3个方向,即front-bottom, left-bottom, front-left。

3D边框定义如下:8个角点,6个面。
也是路面假设,这是得到3-D边框的关键,下面是图像逆投影公式:
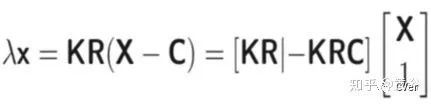
根据逆投影和路面假设,可以先得到3-D边框在路面的位置。下图是3-D边框投影到路面的效果:平行四边形,然后被推理出实际3D边框底部的正方形。
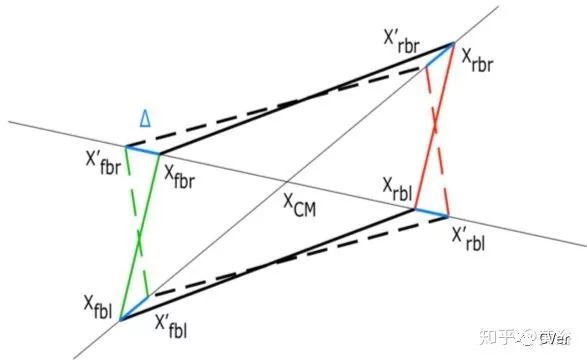
加上估计的物体高度,就得到3-D边框。首先,先估算路面,算法如下:

利用前面提到的,bottom-left line 作为frontal plane 的法向量,然后用front-bottom-left 的点计算front plane;找到frontal plane 和逆投影的交点即得到顶点位置,这样高度就得到了。
一些结果展示:包括顶视图

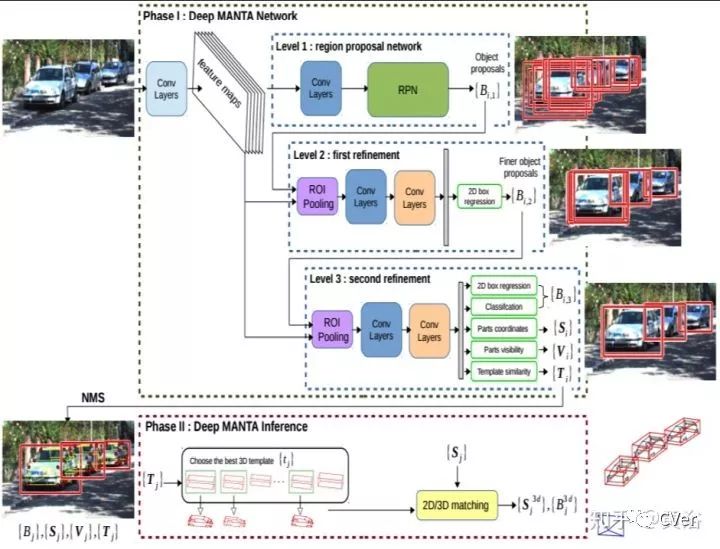
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image,CVPR,2017
MANTA是Many-Tasks的意思。完全通过CNN模型估计多个信息,如图展示的结果:检测, 部件定位, 可视性 和3D尺寸大小。
车辆模型的定义:wireframe模型比较复杂,不过能推理出遮挡的部件。
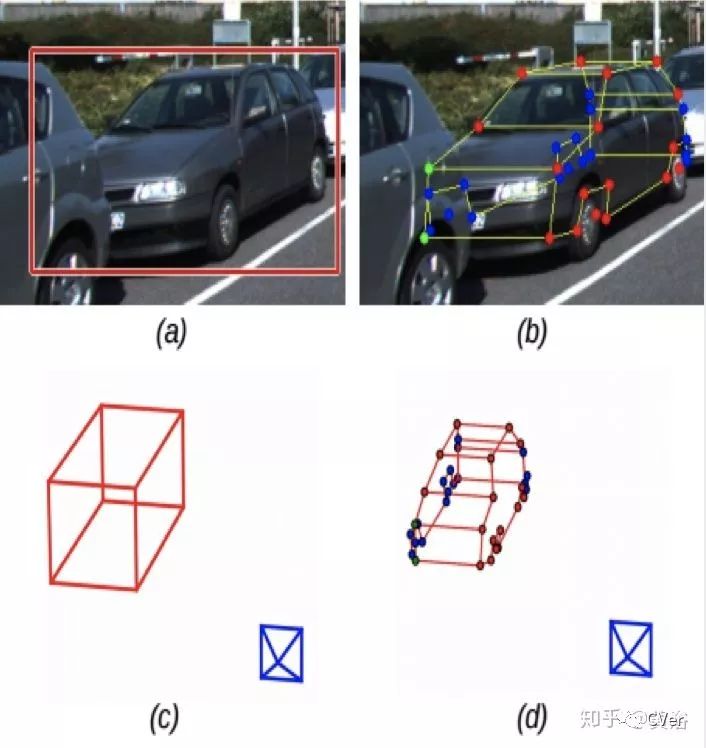
定义的车辆模版如图:这是一个半自动的标注工程。

MANTA的系统框图:CNN模型,region proposal network为先,之后修正两次,分别是proposal改进和2-D边框估计,最后NMS优化和3-D边框估计。
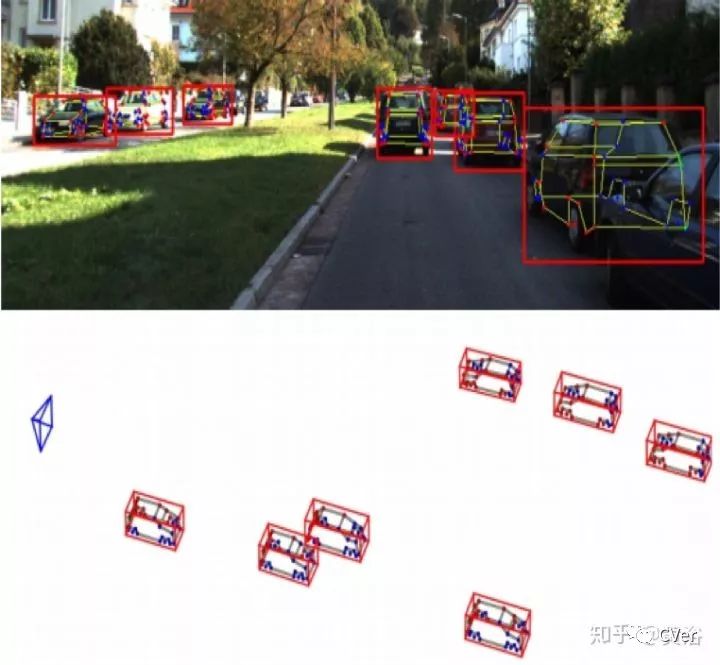
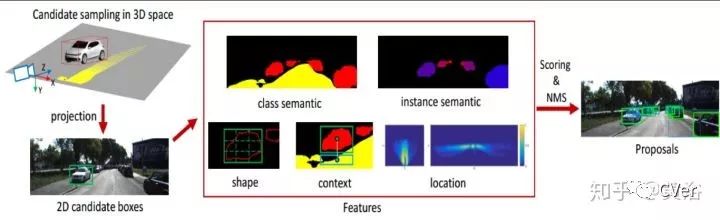
Monocular 3D Object Detection for Autonomous Driving,CVPR,2016
比较有开拓性的CNN模型做3-D检测的工作。如图介绍系统如何产生3-D边框的proposal:仍然有路面假设,有各种信息,包括分割,2D边框,上下文,形状,位置等等。
采用的CNN模型结构对3-D边框的proposal打分:
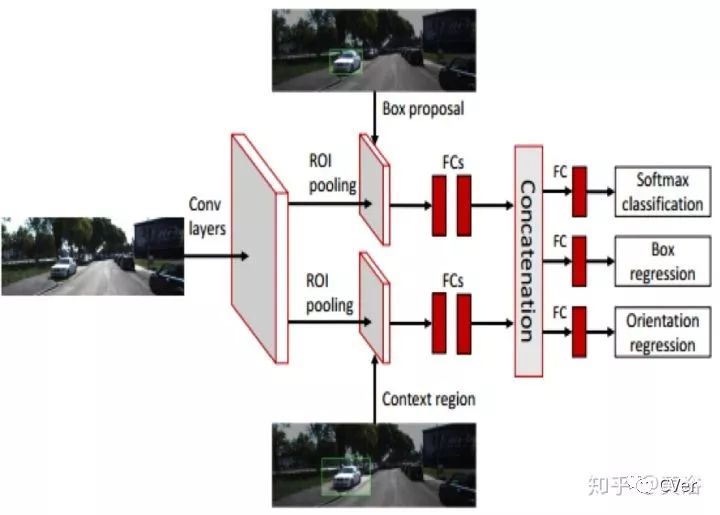
打分的公式是:包括什么提到的各种信息term
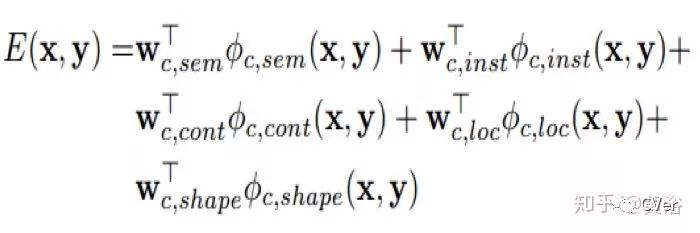
结果展示:

Joint SFM and Detection Cues for Monocular 3D Localization in Road Scenes,CVPR,2015
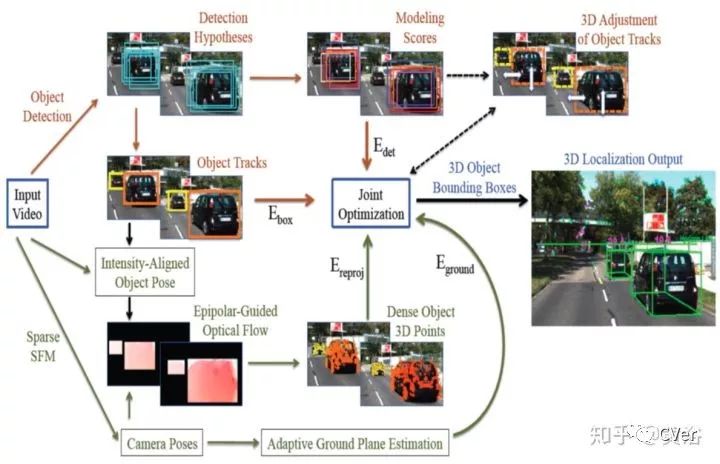
NEC Lab早些的工作,给出的系统框图如下:将SFM和检测结合起来。
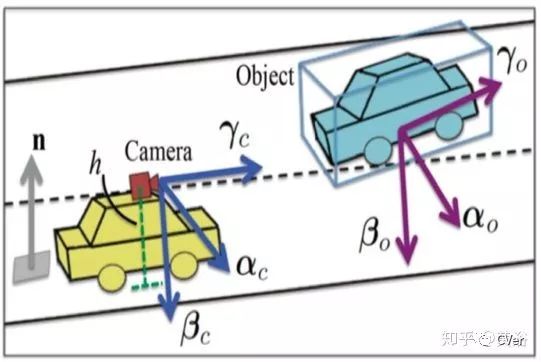
3-D定位物体是有假设路面的前提,首先看坐标系的定义如下图:
而2-D边框的底部可以通过路面假设反投到3-D空间:
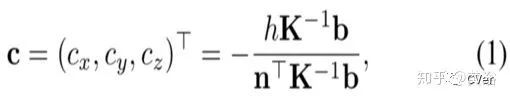
下图是物体的SFM部分:
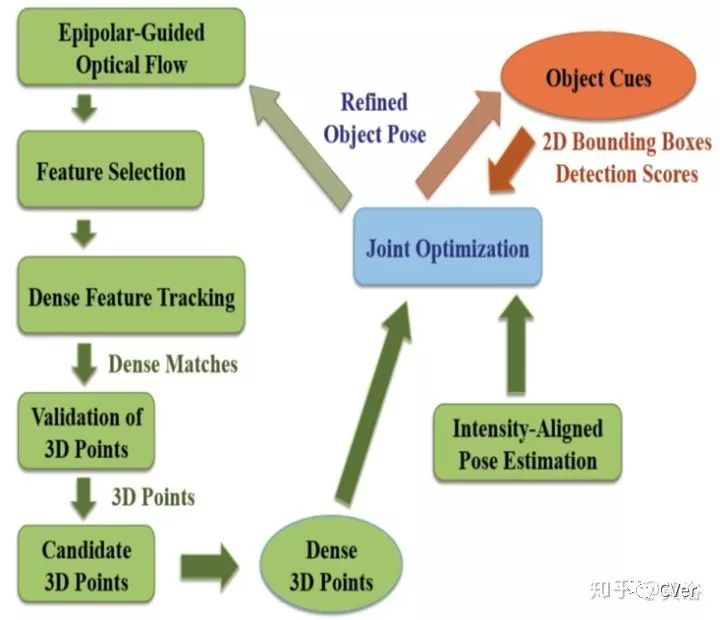
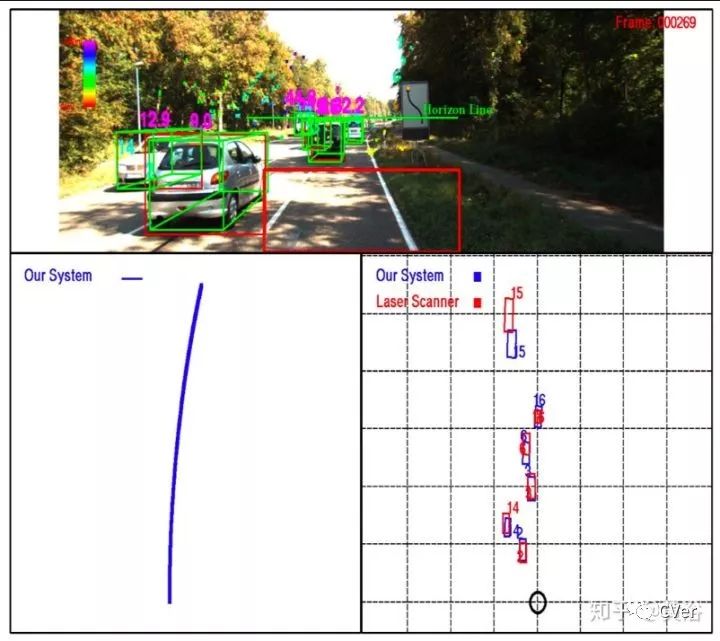
整个定位输出如图这样:其中右下角顶视图有激光雷达ground truth显示为红色。
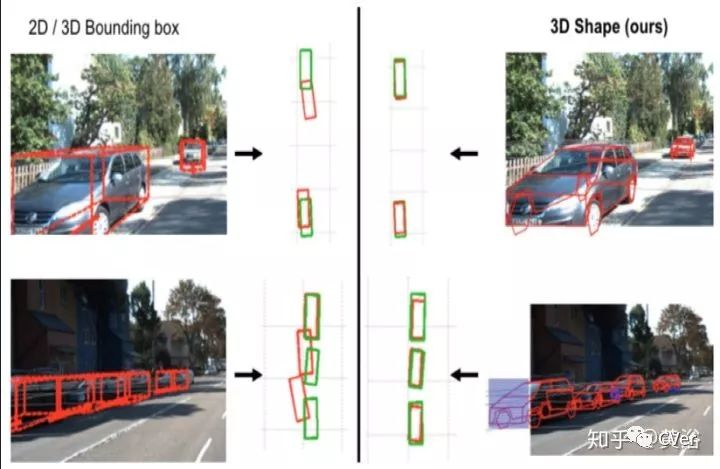
Are Cars Just 3D Boxes? – Jointly Estimating the 3D Shape of Multiple Objects,CVPR,2014
也比较旧的论文,下图展示该系统通过shape modeling得到更精确的3-D定位:
根据路面假设和occlusion mask的3-D景物模型:
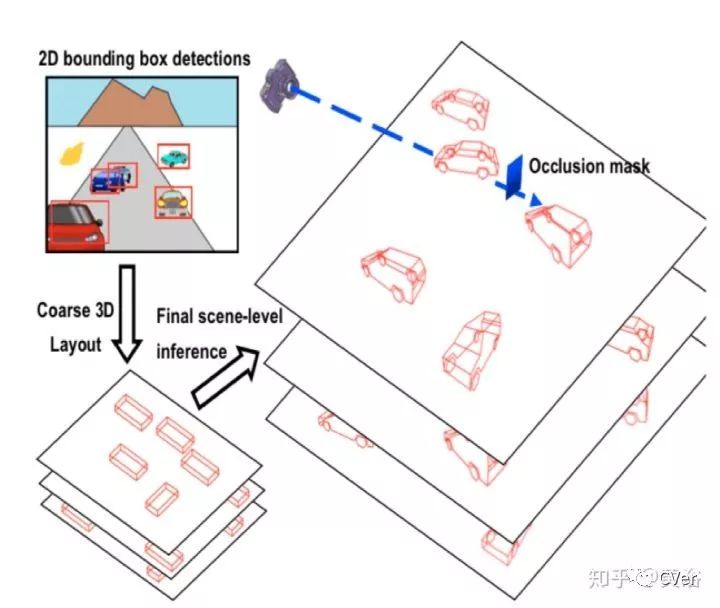
产生Scene particles,然后推理最后的deformable shapes,如图算法:

一些结果如图:
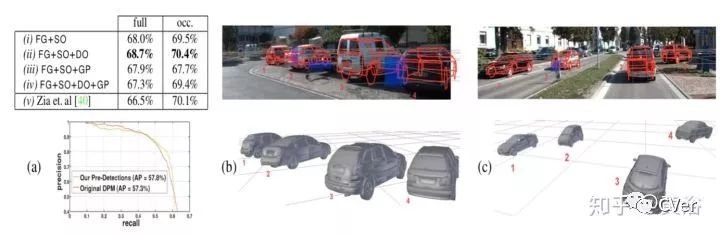
Monocular Visual Scene Understanding: Understanding Multi-Object Traffic Scenes,CVPR,2012
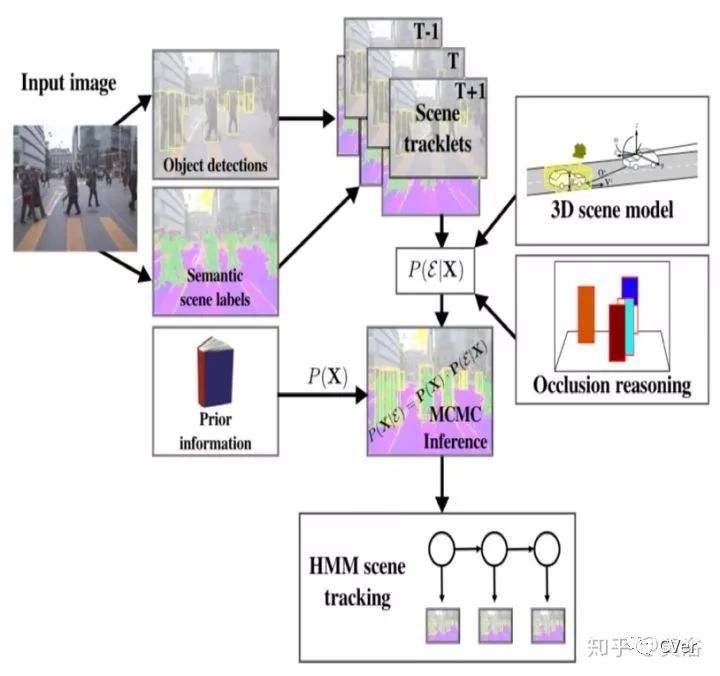
更早的论文,系统示意图如下:有路面假设的景物模型,有遮挡推理模型,有跟踪,有分割;HMM做跟踪算法,MCMC方法做推理。
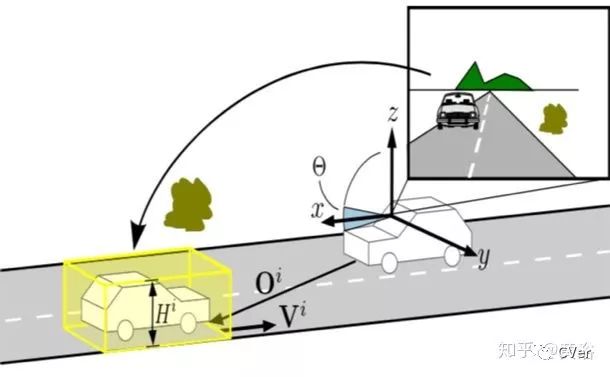
下图是路面假设下的车载坐标系和世界坐标系的关系:
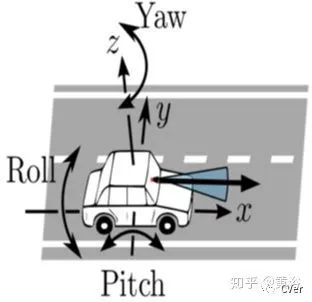
这里介绍的是车载摄像头的旋转:
目标距离的估计类似Mobileye,如图:
------End------
想要了解最新最快最好的论文速递、开源项目和干货资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、学术竞赛交流、Re-ID、风格迁移、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别和超分辨率等方向。
扫码进群
这么硬的干货总结,麻烦给我一个好看
麻烦给我一个好看!
以上是关于自动驾驶中单目摄像头检测输出3-D边界框的方法一览的主要内容,如果未能解决你的问题,请参考以下文章
论文解读SMOKE 单目相机 3D目标检测(CVPR2020)
CVPR2020 SMOKE 单目相机 3D目标检测环境搭建篇
论文解读SMOKE 单目相机 3D目标检测(CVPR2020)
CVPR2020 SMOKE 单目相机 3D目标检测环境搭建篇