论文解读SMOKE 单目相机 3D目标检测(CVPR2020)
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读SMOKE 单目相机 3D目标检测(CVPR2020)相关的知识,希望对你有一定的参考价值。
前言
SMOKE是一种用于自动驾驶的实时单目 3D 物体检测器。为什么会注意这边文章呢?是因为这两天发布的百度Apollo 7.0 的摄像头障碍物感知,也是基于这个模型改进的;于是令我产生了一些兴趣。
论文名称:SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation
论文地址:https://arxiv.org/pdf/2002.10111.pdf
开源地址:https://github.com/lzccccc/SMOKE
环境搭建:https://mp.csdn.net/mp_blog/creation/editor/122243245

本文创建一个基于docker的SMOKE开发环境;SMOKE模型效果如下。

目录
一、论文动机
1.1 对于已有的两阶段单目3D目标检测框架:
a、基于2D目标检测网络生成目标的2D候选区域;
b、针对获取到的目标的“2D patch特征” 预测目标位姿;
深度学习中的patch是做什么的?参考链接:https://www.zhihu.com/question/312883184
1.2 SMOKE
a、论文认为其中的2D检测对于单目3D检测任务来说是冗余的,且会引入噪声影响3D检测性能。
b、若已知相机内参和目标的3D属性,反过来是可以推测出目标的2D检测框的;
(即:基于3D box在图像平面上的投影点求取满足条件的最小外接矩形即可)
本论文抛弃了2D候选区域生成这一步,提出了一个基于关键点预测的一阶段单目3D检测框架SMOKE(Single-Stage Monocular 3D Object Detection via Keypoint Estimation),直接预测目标的3D属性信息。
二、单目3D目标检测
针对单张RGB图像,宽度 W、高度 H、通道数 3;
给出其中每个目标的类别标签 C、3D边界框 B;其中B 可以用7个参数表示(h、w、l、x、y、z、θ)
需要加水相机的内参矩阵已知。

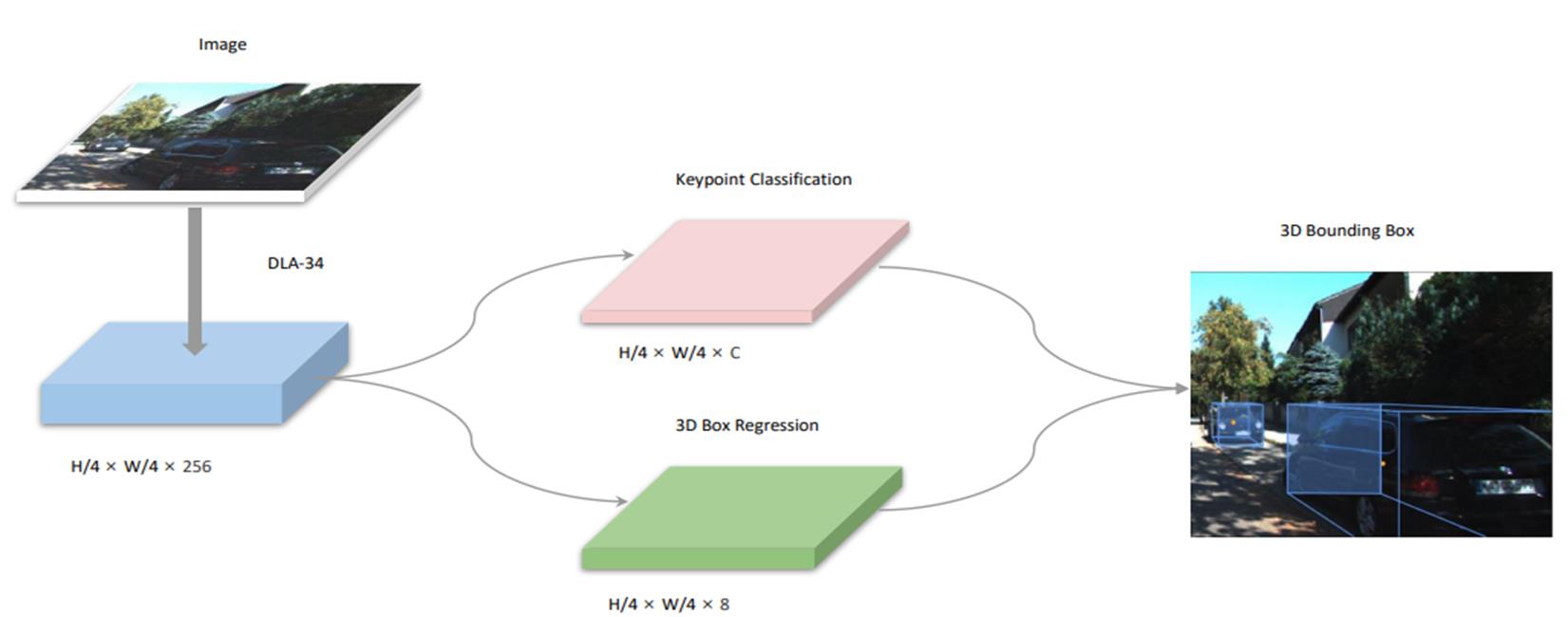
三、SMOKE 整体框架
输入图像经过DLA-34 Backbone进行特征提取。
网络主要包含两个分支:关键点分支和3D边界框回归分支。
四、SMOKE的 Backbone(主干网络)
目录
4.1、Deep Layer Aggregation,DLA-34网络(基础)
4.2、Deformable Convolutional ,可变形卷积(改进点)
5.3、Group Normbalization,组归一化(改进点)
4.1 DLA
Deep Layer Aggregation,DLA,一种网络特征融合方法。(CVPR 2018)

目的:更好地融合空间特征和语义信息;即:融合浅层的底层信息和深层的语义信息。
论文地址:https://arxiv.org/pdf/1707.06484.pdf
开源代码:https://github.com/ucbdrive/dla
DLA-34
论文中采用DLA-34作为主干网络进行特征提取,以便对不同层之间的特征进行聚合。
网络中主要做了两点改动如下:
1、 将所有的分层聚合连接替换为可变形卷积;
2、将所有的BN层用GN(GroupNorm)替换,因为GN对batch size大小不敏感,且对训练噪声更鲁棒,作者在实验部分也对这一点进行了验证。
Deep Layer Aggregation 解读参考:https://zhuanlan.zhihu.com/p/364196632
Deep Layer Aggregation 解读参考2: https://zhuanlan.zhihu.com/p/127949403
4.2 可变形卷积
Deformable Convolutional ,可变形卷积( ICCV 2017)
论文地址:https://arxiv.org/pdf/1703.06211.pdf
开源地址:https://github.com/msracver/Deformable-ConvNets
指卷积核在每一个元素上额外增加了一个参数方向参数,这样卷积核就能在训练过程中扩展到很大的范围。

(a)是传统的标准卷积核,尺寸为3x3(图中绿色的点);
(b)可变形卷积,通过在图(a)的基础上给每个卷积核的参数添加一个方向向量(图b中的浅绿色箭头),使的卷积核可以变为任意形状;
(c)和(d)是可变形卷积的特殊形式。
传统的卷积核通常是固定尺寸、固定大小的(例如3x3,5x5),它对于未知的变化适应性差,泛化能力不强。
例如:同一CNN层的激活单元的感受野尺寸都相同,但是不同的位置可能对应有不同尺度的物体,这些层需要能够自动调整尺度或者感受野的方法。
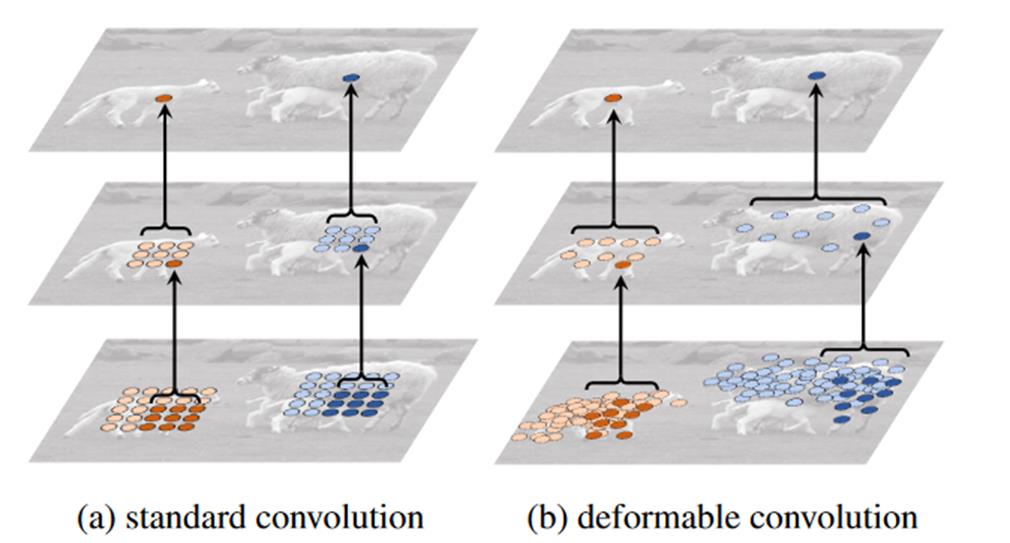
可变形卷积的卷积核可以根据实际情况调整本身的形状,更好的提取输入的特征。
即:卷积核的形状是可变的,也就是感受野可以变化,但注意感受野的元素是“不变”的。
参考:https://blog.csdn.net/LEEANG121/article/details/104234927
4.3 Group Normbalization
Group Normbalization(GN)是一种新的深度学习归一化方式,它解决了BN式归一化对batch size依赖的影响。

五、SMOKE的 3D检测网络
此部分主要包括关键点检测、3D边界框回归分支。
5.1 关键点检测
在关键点分支中,图像中的每一个目标用一个关键点进行表示。 这里的关键点被定义为目标3D框的中心点在图像平面上的投影点,而不是目标的2D框中心点。

设关键点坐标为(𝑥𝑐,𝑦𝑐)(x_c,y_c),则其与目标在相机坐标系下的位置(𝑥,𝑦,𝑧)(x,y,z)之间的关系表示如下边公式:
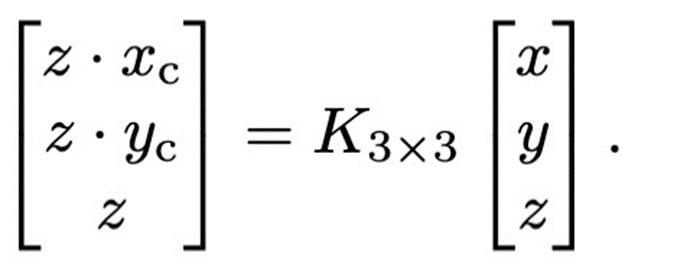
补充理解篇(相机模型)


参考:【视觉SLAM十四讲 高翔】https://www.bilibili.com/video/BV1Z5411t7oB?p=4
5.2 3D边界框回归分支
由于公式乱码,直接复制我的论文分享PPT了。

即:
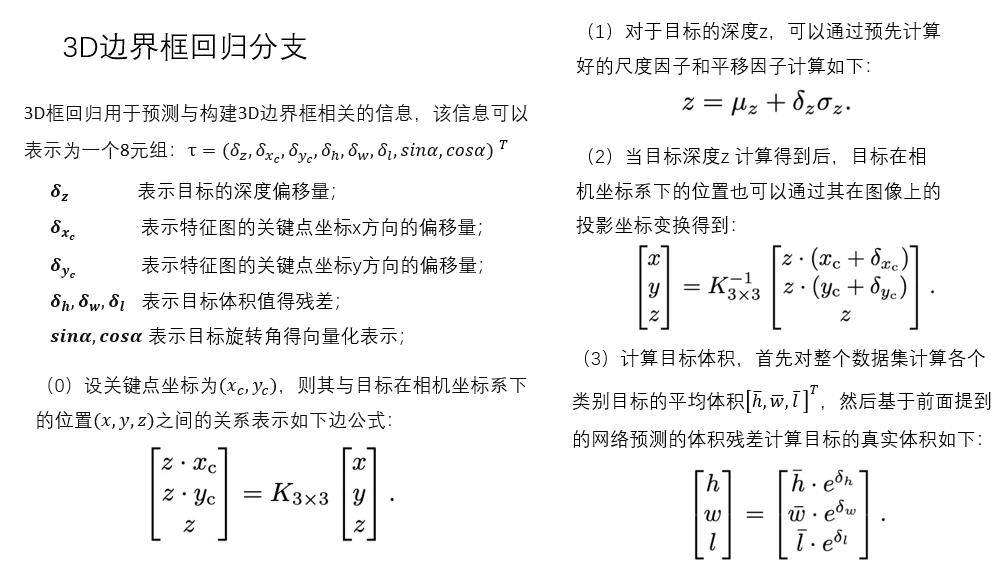
关于深度z的参数,参考如下:

六、损失函数

七、训练细节

八、实验结果
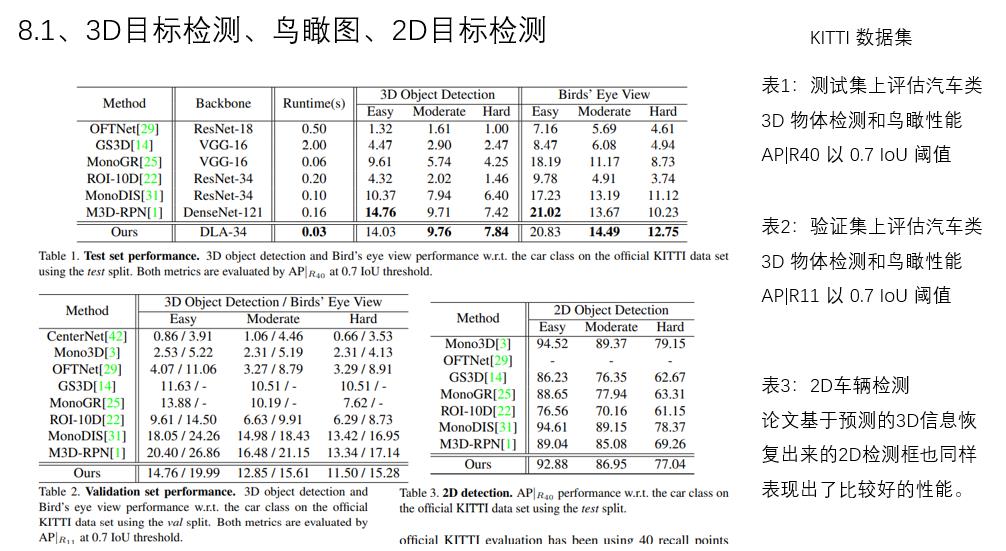
8.1、3D目标检测、鸟瞰图、2D目标检测
8.2、消融实验
9.3、模型效果


9、SMOKE在百度Apollo7.0中应用

参考:https://github.com/ApolloAuto/apollo/blob/4dd49367131537416cee1f5493d8d9c2e2c2a823/modules/perception/camera/README_CN.MD

以上是关于论文解读SMOKE 单目相机 3D目标检测(CVPR2020)的主要内容,如果未能解决你的问题,请参考以下文章
CVPR2020 SMOKE 单目相机 3D目标检测环境搭建篇
CVPR2020 SMOKE 单目相机 3D目标检测环境搭建篇