从TPU3.0到DeepMind支持的Android P,谷歌I/O 2018的AI亮点全在这了
Posted 机器之心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从TPU3.0到DeepMind支持的Android P,谷歌I/O 2018的AI亮点全在这了相关的知识,希望对你有一定的参考价值。
机器之心报道
参与:机器之心编辑部
2018 年 5 月 8 日,一年一度的谷歌 I/O 开发者大会在美国加州山景城开幕。2016 年谷歌从移动优先到人工智能优先(AI-first),两年来我们从谷歌 I/O 看到了谷歌如何践行这一战略。在今日刚刚结束的 Keynote 中,机器学习依旧是整个大会的主旋律:谷歌发布了 TPU 3.0、Google Duplex,以及基于 AI 核心的新一代安卓操作系统 android P,也介绍了自己在 News、Map、Lens 等众多产品中对 AI 与机器学习模型的应用。本文带你一览谷歌 I/O 2018 首日 keynote 的核心亮点。
在今天的 Keynote 中,谷歌 CEO 桑德尔·皮查伊等人介绍了谷歌一年来的多方面 AI 研究成果,例如深度学习医疗、TPU3.0、Google Duplex 等,也展示了 AI 如何全方位地融入了谷歌每一条产品线,从安卓到 Google Lens 和 Waymo。在本文中,机器之心对 Keynote 的核心内容进行了整理。
深度学习医疗
大会刚开始,昨天谷歌所有的 AI 研究合并出的 Google AI 发布了一篇博客,介绍谷歌在医疗领域的研究:
联合斯坦福医学院、加州大学旧金山分校 、芝加哥大学医学中心,谷歌今天在 Nature Partner Journals: Digital Medicine 上发布了一篇论文《Scalable and Accurate Deep Learning with Electronic Health Records》。
在此研究中,谷歌使用深度学习模型根据去识别的电子病历做出大量与病人相关的预测。重要的是,谷歌能够使用原始数据,不需要人工提取、清洁、转换病历中的相关变量。
在预测之前,深度学习模型读取早期到现在所有的数据点,然后学习对预测输出有帮助的数据。由于数据点数量巨大,谷歌基于循环神经网络与前馈网络开发出了一种新型的深度学习建模方法。
病人病历中的数据以时间线的形式展示
至于预测准确率(标准:1.00 为完美得分),如果病人就医时间较长,论文提出的模型预测得分为 0.86,而传统的 logistic 回归模型得分为 0.76。这一预测准确率已经相当惊人。
Looking to Listen:音频-视觉语音分离模型
而后,皮查伊介绍了谷歌博客不久前介绍的新型音频-视觉语音分离模型。
在论文《Looking to Listen at the Cocktail Party》中,谷歌提出了一种深度学习音频-视觉模型,用于将单个语音信号与背景噪声、其他人声等混合声音分离开来。这种方法用途广泛,从视频中的语音增强和识别、视频会议,到改进助听器,不一而足,尤其适用于有多个说话人的情景。
据介绍,这项技术的独特之处是结合了输入视频的听觉和视觉信号来分离语音。直观地讲,人的嘴的运动应当与该人说话时产生的声音相关联,这反过来又可以帮助识别音频的哪些部分对应于该人。视觉信号不仅在混合语音的情况下显著提高了语音分离质量(与仅仅使用音频的语音分离相比),它还将分离的干净语音轨道与视频中的可见说话者相关联。
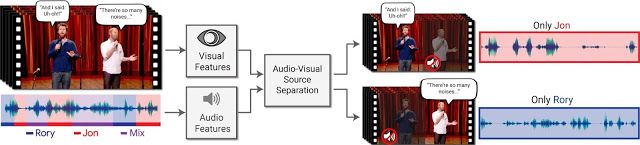
在谷歌提出的方法中,输入是具有一个或多个说话人的视频,其中我们需要的语音受到其他说话人和/或背景噪声的干扰。输出是将输入音频轨道分解成的干净语音轨道,其中每个语音轨道来自视频中检测到的每一个人。
皮查伊还介绍了谷歌其他 NLP 应用,例如通过谷歌的键盘输入摩斯电码让语言障碍者重新获得表达能力、GMail 中利用语言模型与语境信息预测输入。
之后,皮查伊介绍了谷歌在计算机领域的一些研究成果与应用,包括医疗影像方面的研究,移动设备中应用的照片理解、抠图、自动上色和文档处理等。
TPU 3.0
去年,谷歌 I/0 公布了 TPU 2.0,且开放给了谷歌云客户。今天,皮查伊正式宣布 TPU 3.0 版本。

皮查伊介绍,TPU 3.0 版本功能强大,采用液冷系统,计算性能是 TPU 2.0 的 8 倍,可解决更多问题,让用户开发更大、更好、更准确的模型。更多有关 TPU 3.0 的信息也许会在之后放出。
Google Assitant 与 Google Duplex
集成谷歌人机交互研究的 Google Assistant 在今日的 keynote 中必然会亮相。Google Assitant 负责工程的副总裁 Scott Huffman 介绍了 Google Assitant 过去一年的成果,谷歌产品管理总监 Lilian Rincon 介绍了带有视觉体验的 Google Assistant 产品,且有数款产品将在今年 7 月份发布。
而后谷歌 CEO 桑德尔·皮查伊在 Keynote 中展示了语言交互的重要性,并正式介绍了一种进行自然语言对话的新技术 Google Duplex。这种技术旨在完成预约等特定任务,并使系统尽可能自然流畅地实现对话,使用户能像与人对话那样便捷。
这种自然的对话非常难以处理,因为用户可能会使用更加不正式或较长的句子,且语速和语调也会相应地增加。此外,在交互式对话中,同样的自然语句可能会根据语境有不同的意思,因为人类之间的自然对话总是根据语境尽可能省略一些语言。
如下所示,输入语音将输入到 ASR 系统并获得输出,在结合 ASR 的输出与语境信息后可作为循环神经网络的输入。这一深度 RNN 最终将基于输入信息输出对应的响应文本,最后响应文本可传入文本转语音(TTS)系统完成对话。RNN 的输出与 TTS 系统对于生成流畅自然的语音非常重要,这也是 Duplex 系统关注的核心问题。
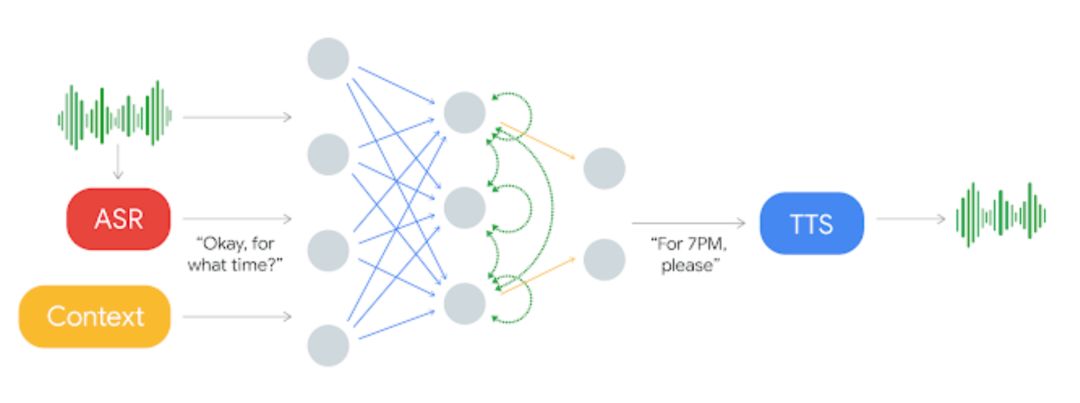
在 Duplex 系统的语音生成部分,谷歌结合了拼接式的 TTS 系统和合成式的 TTS 系统来控制语音语调,即结合了 Tacotron 和 WaveNet。
由于这样的系统引入了「嗯、额」等停顿语,系统生成的语音会显得更加的自然。当结合拼接式 TTS 引擎中大量不同的语音单元或添加合成式停顿时,这些引入的停顿语允许系统以自然的方式表示它还需要一些处理时间。
总的来说,Google Duplex 的这些结构与方法对生成更自然的对话与语音有非常大的帮助。目前虽然主要是针对特定领域中的语言交互,但确实提升了语音会话中的用户体验。
安卓以及闪现的 DeepMind
即将在今年 9 月迎来自己 10 岁生日的安卓也在 I/O 上宣布了新一代操作系统。继承 Android Oreo 工作的新版安卓系统被命名为 Android P。
「本次发布有三个主题,分别是智能(Intelligence)、简洁(Simplicity)与数字健康(Digital Wellbeing)。Android P 是我们『AI 位于操作系统核心』愿景的第一步,而 AI 也是『智能』主题的奠基石。」谷歌工程副总裁 Dave Burke 如是展开了他的演讲。
智能部分里首先介绍了两个功能,Adaptive Battery 自适应电池管理系统和 Adaptive Brightness 自适应亮度调节系统。
其中,Adaptive Battery 通过卷积神经网络来预测用户接下来会使用的应用程序,通过适应用户的使用模式将电池仅用于你接下来可能需要的应用程序中,这减少了 30% 的后台 CPU 唤醒。而 Adaptive Brightness 则不再单纯根据照明情况调节亮度,而是加上了用户喜好和所处环境因素。超过一半的测试用户减少了他们手动调节亮度条的频率。
事实上,这两个功能均来自之前一度被美媒质疑「烧钱还傲娇不干实事」的 DeepMind。DeepMind 本次并没有直接在 I/O 露出,只是在博客上发表了一篇文章(https://deepmind.com/blog/deepmind-meet-android/),说明了 Android 的这两个新功能来自 DeepMind for Google 团队。
除此之外,Android P 也将去年发布的、准确率达到 60% 的「用户接下来可能使用哪个 App」预测更进一步,转而预测「用户接下来可能用什么 App 进行什么操作」,并直接在上滑菜单顶部呈现给用户。
Dave Burke 在介绍上述每一个功能时都着重强调了所有的预测均由在端上运行的机器学习模型完成,以确保用户隐私得到最大程度的保护。
除了将 AI 融入操作系统的优化之外,Android 还试图降低非机器学习背景的开发者使用相关技能的门槛:包括图片标注、文字识别、智能回复等一系列 AI 相关的 API 将以 ML Kit 的形式开放给开发者。
「你可以将 ML Kit 视作基于 TensorFlow Lite 提供的、为移动设备优化过的、随拿随用机器学习模型。」Dave Kurve 介绍说。而且,谷歌非常大方地同时对 ios 系统开放了这一 API 集。
开发者今天就能在 Pixel 上实验 Android P Beta 的效果了。值得一提的是,除了 Pixel 之外,Android P Beta 还对其他 7 家手机生产厂商的旗舰机开放,其中有 4 家都来自中国,它们分别是小米、vivo、oppo 和一加。
无人驾驶
昨日,起源于斯坦福人工智能实验室的自动驾驶汽车初创公司 Drive.ai 于 7 日宣布,将与德克萨斯州的弗里斯科政府以及 Hall 集团进行合作,在德州落地首个无人出租车服务。而在今天的 Keynote 中,Waymo CEO John Krafcik 通过视频展示了居住在凤凰城的一些人参与其 EarlyRider 项目(即体验 Waymo 的自动驾驶技术)的场景。Krafcik 称 Waymo 将在今年于凤凰城开始 passenger-pickup 项目,凤凰城是第一站。
结语
一年一度的谷歌 I/O 开发者大会首日 Keynote 中的核心内容如上,相比于偏重机器学习技术的 2016 年与 2017 年,今年的内容更多关于 AI 的应用与产品。两年来,我们看到了谷歌如何践行 AI First 战略。接下来几天,机器之心将会继续报道谷歌 I/O 2018 的更多精彩内容。
蚂蚁金服举办首届金融科技领域算法类大赛——ATEC 蚂蚁开发者大赛人工智能大赛,点击「阅读原文」 进入大赛官网了解比赛信息,比赛报名请使用PC端浏览器打开官网。
以上是关于从TPU3.0到DeepMind支持的Android P,谷歌I/O 2018的AI亮点全在这了的主要内容,如果未能解决你的问题,请参考以下文章
前沿 | DeepMind提出新型架构IMPALA:帮助实现单智能体的多任务强化学习
DeepMind 的 Sonnet 提供了 Keras 没有的啥?
参数量仅为4%,性能媲美GPT-3:开发者图解DeepMind的RETRO