R语言—数据分析1
Posted 三只产品数据汪1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言—数据分析1相关的知识,希望对你有一定的参考价值。
本章内容是以案例的形式提供。
本案例将介绍一些数据挖掘的基本任务:数据预处理,探索性数据分析和预测性模型的构建。(本案例内容会持续更新)
一:问题描述与目标
高浓度的藻类,对河流的生态环境的破坏很严重。针对这一问题,在一年内,不同的时间收集了多条不同河流的水样。
数据说明:每条记录有11个变量构成。其中3个变量是名义变量,描述水样手机的季节,收集样品的河流大小,河水速度;剩下的8个变量观测水样的不同化学参数,即
最大PH值
最小含氧量(O2)
平均氯化物含量(Cl)
平均硝酸盐含量(NO3-)
平均氨含量(NH4+)
平均正磷酸盐含量(PO43-)
平均磷酸盐含量(PO4)
平均叶绿素含量
二:数据加载
我们用R提供的包,输入下面两行代码即可。
函数head()显示数据框的前6行。
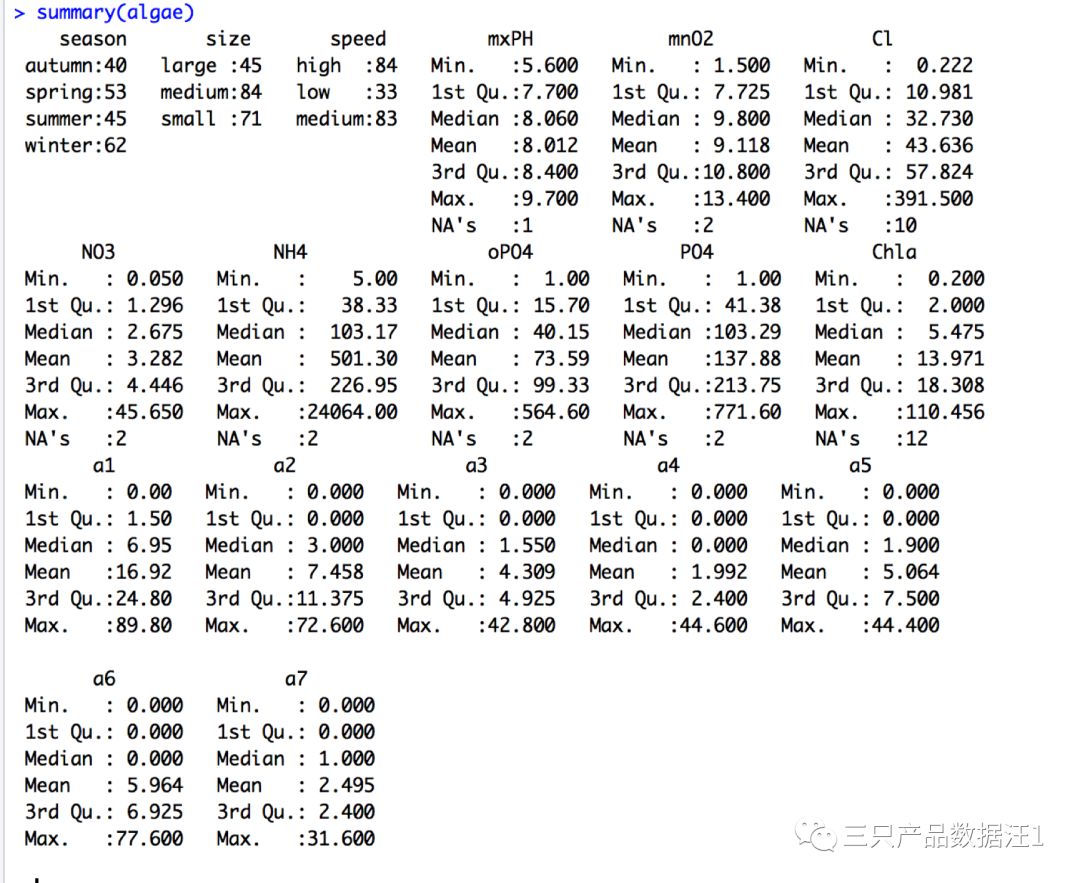
2.1探索数据,获取数据统计特征,如下获取数据描述性统计摘要:
展示变量的最大值,最小值,中位置,四分位置等特征
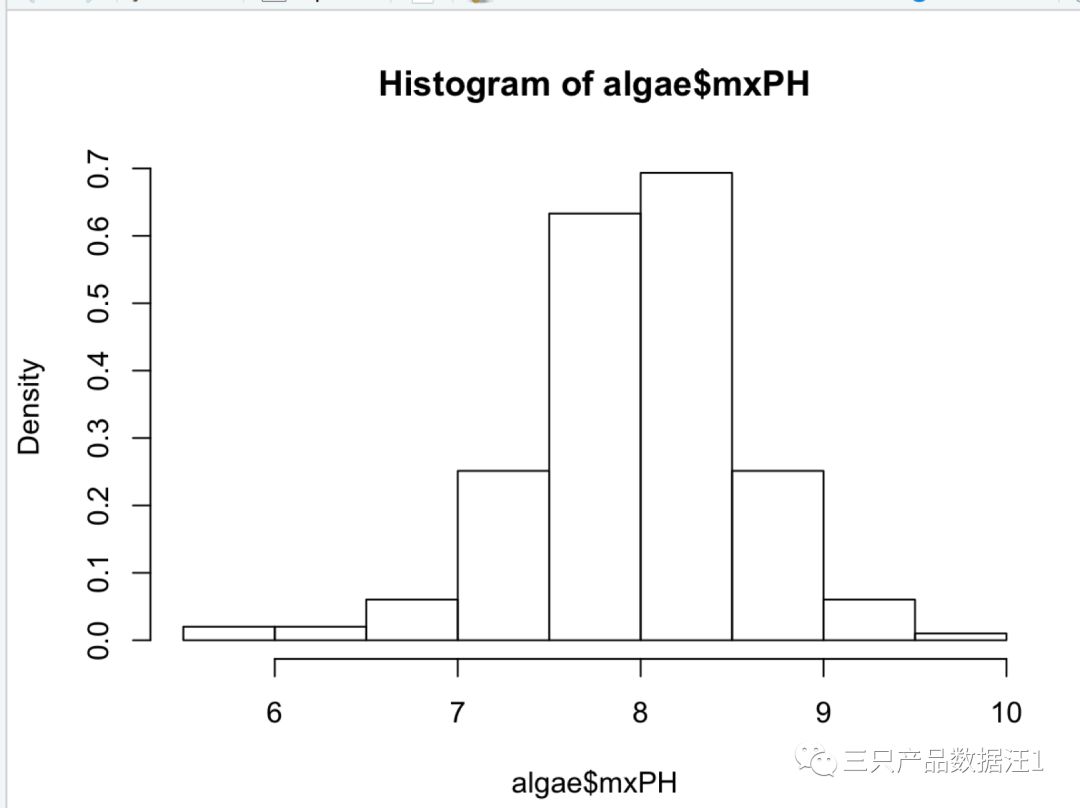
该指令是绘制变量mxPH的直方图,设置prob=T ,可以得知每个取值区间的概率(直方图的面积之和为1),如果prob= FALSE,或者忽略该参数,他将给出频数图。
如果可知,mxPH的分布非常接近正态分布。现在通过Q-Q图检验该变量是否为正态分布,输入如下命令:
Q-Q图,他绘制变量值和正态分布的理论分位数(实线)的散点图。同时给出正态分布95%置信区间的带状图(虚线),由图可知,变量有几个小的值明显在95%置信区间之外,他们不服从正态分布。
知识点:
函数rug()执行绘制,
函数jitter()对要绘制的原始值略微进行随机排列
正态分布,95%置信区间
函数head()
函数summary()【Hmisc(),describe()同样作用】
hist();设置prob= T ,可以得知每个取值区间的概率(直方图的面积之和为1),如果prob = FALSE,或者忽略该参数,他将给出频数图。
Q-Q图
以上为本次更新内容~
数据检验还有其他方法,如箱线图,分为箱图,下期更新~~
以上是关于R语言—数据分析1的主要内容,如果未能解决你的问题,请参考以下文章