论文分享ACL 2020 神经网络的可解释性
Posted 深度学习自然语言处理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文分享ACL 2020 神经网络的可解释性相关的知识,希望对你有一定的参考价值。
引言

引言
尽管近些年来深度神经网络取得了广泛的成功,在预测上取得了不错的精度,但是要使得神经网络能够更加让人信服,人们需要能够解释神经网络能够运行的原理,网络参数的意义。但是现今人们对神经网络背后的原理知之甚少,因此会有人怀疑神经网络预测得到的结果是否是可以被相信的,尤其是在一些关键的领域,比如自动驾驶、法律、医疗领域,我们对于错误的容忍度很低,这时候更加需要能够解释神经网络得到结果的依据。今天给大家分享ACL中神经网络的可解释性的三篇最新的工作。

文章概览
文章概览
1. Understanding Attention for Text Classification
注意力(attention)机制在NLP任务中得到了广泛的应用。最近,很多研究者开始关注NLP任务中注意力的可解释性。目前很多的研究局限于研究是否注意力权重反映了输入表示的重要程度。而这篇文章通过深入研究梯度更新过程来理解注意力机制的内在规律。
2. Towards Transparent and Explainable Attention Models
这篇文章给出了为何在 LSTM RNN 模型中注意力权重有时候解释性很差的一种解释,并且给出了两种改进模型,提高了注意力权重的可解释性。
3. Information-Theoretic Probing for Linguistic Structure
探测任务(Probing Task)是 NLP 可解释性研究中经常会使用的工具,其基本想法是,对于一个表示,以它为输入训练一个简单的语言学性质的分类模型,如果模型表现的比较好的话,就认为这种表示蕴含了相应的语言学性质信息。这篇文章从信息论的角度给探测任务提出了相应的解释,并且给出了如何设计探测任务的建议。
论文细节
论文细节
1

动机
这篇文章的动机是源于在NLP任务中,研究者一直试图寻找注意力权重(attention weight)和可解释性之间的关系,比如在情感分类任务中,一些常用的单词(尤其是形容词)相对于其他词而言被分配到了更大的注意力权重。但是另一些时候,这些对结果本来应该有较大影响的单词却不能得到较大的注意力权重,但是在这种情况下,分类任务依然有可能取得好的结果。
因此,这篇文章试图来解释,
-
什么是影响注意力权重的根本因素?
-
有没有与句子无关的可以衡量一个单词在整个单词集合中的重要程度的属性?
-
当注意力机制没有那么可解释性的时候,基本模型将如何受到影响?
模型
为了解决上述问题,这篇文章考虑了一个简单的的模型:
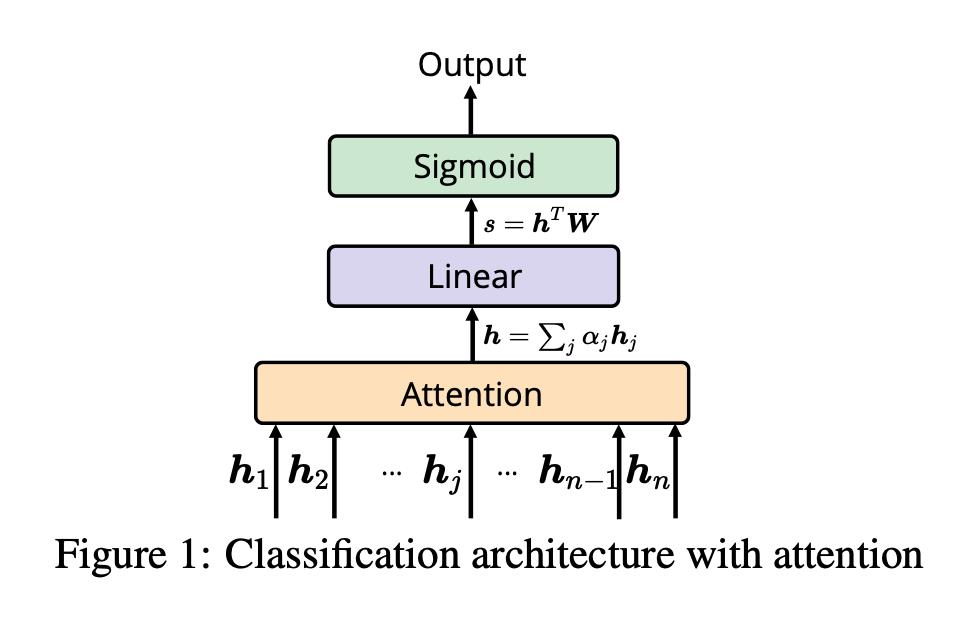
这个模型是个NLP分类问题,为了简单起见,考虑二分类问题,输入是单词的表示(embedding),并且使用尺度化内积注意力机制(scaled dot-product attention),具体公式如下:
使用的损失函数是负对数似然函数。
首先我们将单词分为三类:
-
第一种是 Positive token,指的是经常出现在正样本中的单词
-
第二种是 Negative token,指的是经常出现在负样本中的单词
-
第三种是 Neutral token,指的是在正负样本中同样出现的单词
我们统称 Positive token 和 Negative token 为 Polarity Token
举一个例子,比如我们的正样本包含两句话:“The book is good!” 和 “The boy is smart.“,负样本包含两句话 “The dish is awful” 和 “The dog is vicious!”,在这个例子中,Positive token 包含 good 和 smart,Negative token 包含 awful 和 vicious,Neutral token 包含 the 和 is。
为了进行理论上的分析,我们首先定义一些变量,分别是:
-
Token-level attention score:
-
Instance-level polarity score:
-
Token-level polarity score:
那么 instance-level polarity score 就是 h 与 w 的内积, 我们对其做 sigmoid 操作可以得到模型的估计值。而token-level polarity score 是每个token 的 embedding 和 W的内积,很容易可以看到,instance-level polarity score 是 token-level polarity score 基于注意力权重的加权平均。这篇文章试图说明, token-level polarity score 和 token-level attention score 和 这个token的属性之间究竟有什么样的关系。
为了研究这个问题,我们考虑在梯度下降训练过程中,梯度下降的方向是损失函数对这个变量的梯度的负方向,因此一个变量关于时间的导数也沿着这个负方向。为了简单起见,我们在这里略去了learning rate。
这样,对于一个单词 , 它的 polarity score 是 和 的内积。根据链式法则,我们可以知道:
经过一些数学推导,我们可以最终得到这样的表达式,token-level polarity score 对时间的导数是ABC三个部分的求和。
其中: 。
首先我们考虑 比较大的情况,这时候我们近似认为 A 约等于 0,对于 B 和 C 这两项, 我们可以分析得到对于 Positive token,B和C都为正;对于Negative token,B 和 C 都为负;而对于Neural token,由于有正有负相互抵消,B 和 C 可以认为都为 0。
在这种情况下,我们可以知道,当接近局部最小值点时,Positive token 的 polarity score 更倾向于增加,最终到达比较大的数值,Negative token 的 polarity score 更倾向于减小,最终到达比较小的数值,Neural token 的 polarity score 并不会有明显的改变,最终的结果值会居中。这种情况下,Polarity Score就具有了一定的可解释性,它反应了一个 token 是否更加经常的出现在正样本中,或者负样本中。
但是,上述分析的假设是基于 A 约等于 0,也就是 的数值要很小。在这一个性质不满足的情况下,我们注意到不管对于 Positive token 还是 Negative token,A中求和这一项都是正的,而对于Neural token, A 中求和这一项依然约等于0,这样 A 这一项对于 Positive token 和 Negative token 是同号的,符号取决于 和 内积的符号。如果这一内积为正,对于 Negative token 而言 A 为正,BC 为负,就有可能出现, Negative token 的 polarity score最终大于 Neural token 的 polarity score的情况出现。这时候模型的可解释性就被削弱了。同样的么,如果这一内积为负,对于Positive token 而言 A为负, BC为正,就有可能出现 Positive token 和 Negative token 的 polarity score 都低于 Neural token 的情况。
而对于 Token-level attention score 关于时间的梯度,通过数学计算,我们同样也可以将其分为三项,DEF:
首先可以分析出当接近局部最小值点时的时候 , ,并且可以证明, , 但是对于 D 这一项,Positive token 和 Negative token 的符号恰恰相反。
这就使得,当 D 这一项可以忽略的时候,也就是 不能太大的时候,当接近局部最小值点的时候,Polarity token 的 attention score 倾向于上升,最终停留在一个比较大的数值,而Neural token的 attention score 没有明显变化,最终停留在相对较低的数值。这就使得,attention score 存在了刻画一个 token 的 polarity 程度的解释。
但是,当 比较大的时候,D无法被忽略,这个时候或者是 Positive token,或者是 Negative token 的 attention score 会存在下降的趋势,最终表现出的也就是很低的注意力权重,这时候模型的可解释性就不强。
实验
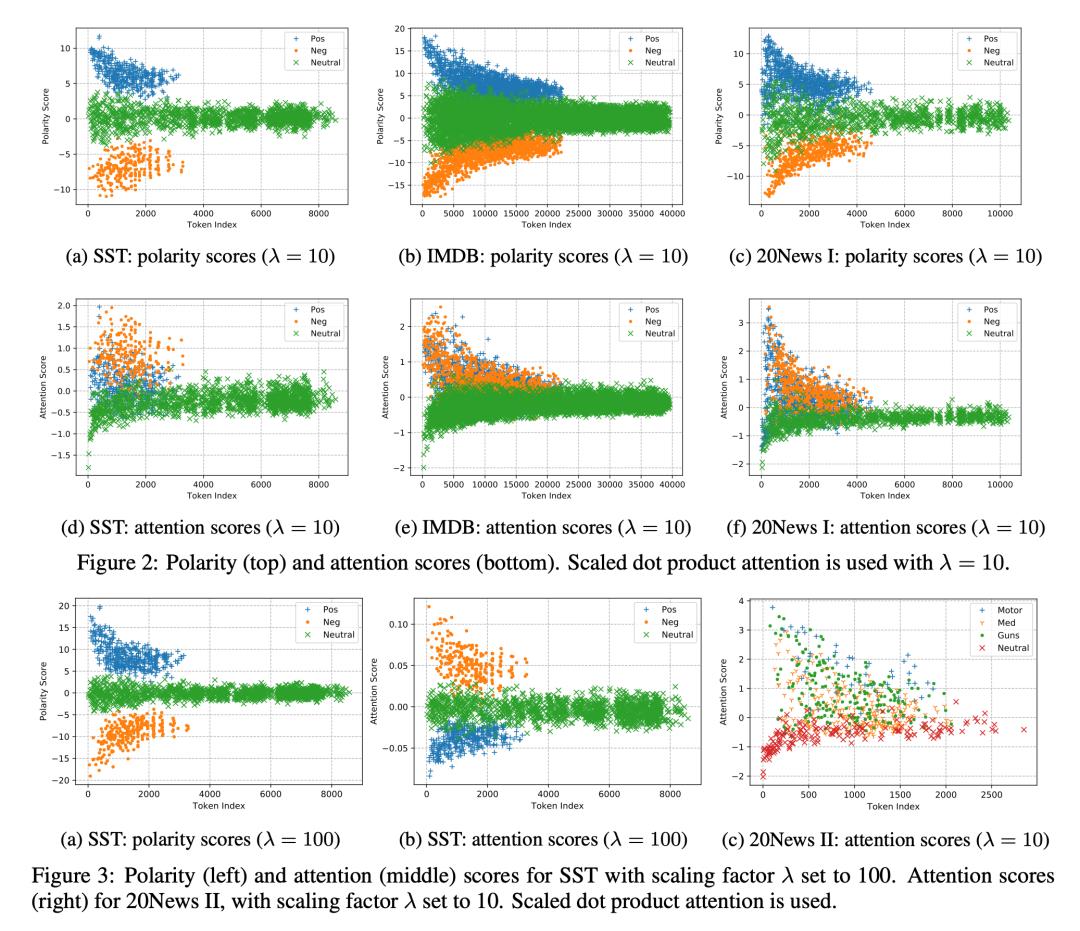
这篇文章在四个数据集合上给出了试验结果,它们分别是:
-
Standford Sentiment Treebank(SST):原始的数据集合中有10662个实例,每一个有一个1(最负面)到5(最正面)的标号。这篇文章移除了标号为3的实例,把标号4、5看作正样本,标号1、2看作负样本 -
IMDB:50000个带有正负编号的电影评价 -
20Newsgroup I(20News I):原始的样本有大约20000个新闻组通信稿,这篇文章取其中的两个分类:"res.sport.hockey" 和 "rec.sport.baseball",把前者看作正样本,后者看作负样本 -
20Newsgroup II(20News II)
在这些数据集合上进行实验我们可以看到,当正确设置了 的数值后,考虑 poarity score,可以明显的看到 positive token 的大于零,negative token 的小于零,neural token 的大概等于零;考虑 attention score,polarity token 的都大于零,而 neural token 的小于等于零。但是当 设置的偏大的时候,反而出现了positive token 的 attention score 小于 neural token 的情况,这时候反映到注意力权重就是 positive token 的注意力权重小于 neural token 的注意力权重(比如情感分类任务中,good、nice 这样的词的注意力权重小于 the、is 这样的词的注意力权重),此时注意力的可解释性就变差了。
2

动机
注意力机制在现代神经网络设计中成为一个不可缺少的组成部分。注意力机制除了可以提高模型的精度之外,人们经常用注意力权重来理解模型内部的工作机制。但是,近些年来的研究 [4,5] 发现高的注意力权重并不一定对应着对模型预测结果有更大的影响,因此注意力机制并不能给模型的预测提供一个忠实的解释。这篇文章发现注意力机制解释性不强可能跟LSTM中隐藏状态之间差异性过小有关系,因此针对提出了两种改进模型来提高模型的可解释性。
细节
我们考虑一个注意力机制编码器,输入的表示是每个隐藏状态带注意力权重的求和:
一般而言,如果某个 数值较大的话,我们可以认为第 个 token重要程度越高。但是如果每个 的差异性不大,甚至在极端情况下每个 都是完全相同的,这时候 的取值分布对结果不会有任何的影响。就比如下图中 三个向量非常的接近,因此我们对于三个注意力权重作出置换之后得到的表示跟原表示几乎没有什么区别。这时候注意力权重的可解释性就很弱。
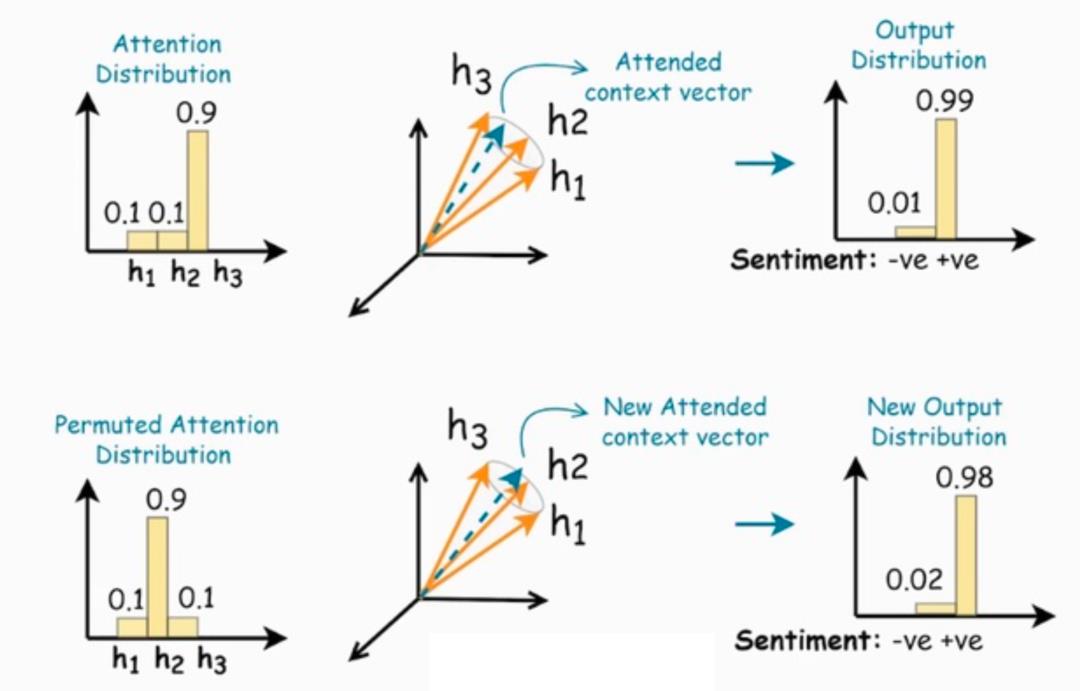
上述是直观的解释,我们需要量化一组向量非常接近这个属性。对于一组向量 ,我们使用锥度(conicity measure)来刻画它们之间的相似程度:
这篇文章发现,对于各种语言学任务,如果使用LSTM的编码器的话,锥度都是比较大的:
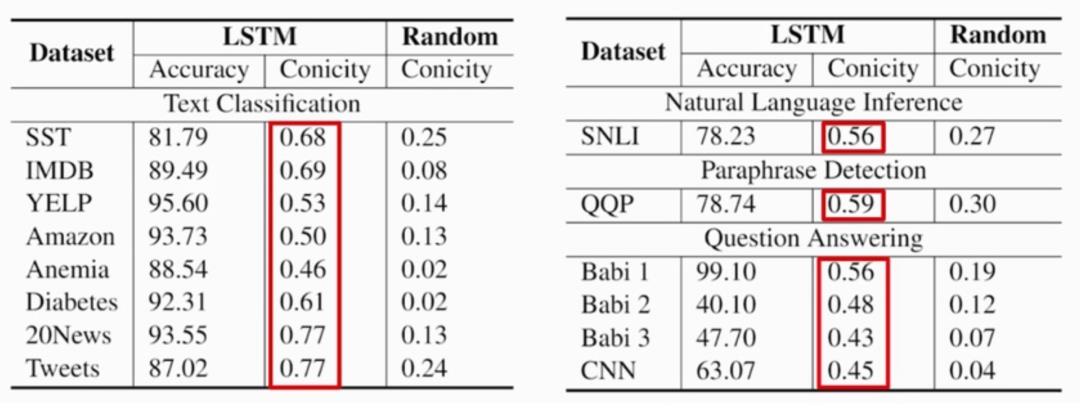
这就意味着编码器中的每个隐藏状态之间是非常的接近的,这就造成了注意力权重的解释性不强。
模型
为了克服这个缺点,这篇文章提出了两种改进模型。它们的想法都是尽量的使得隐藏状态之间的差异性尽可能的大。
第一种改进模型(Orthogonal LSTM)是强行的使隐藏状态之间相互正交,为了简化计算,这篇文章使用的方法是使 和之前所有隐藏状态的平均向量相互正交:
第二种改进模型(Diversity LSTM)是将锥度加入模型的损失函数中。也就是模型训练的目标既要考虑提高预测精度,也要考虑降低隐藏状态的锥度。
实验
最终的试验结果显示,两种改进模型都能有效的降低编码器隐藏状态的锥度,并且对模型的精度不会产生太大的影响,这时候注意力权重的影响能够大大提高。
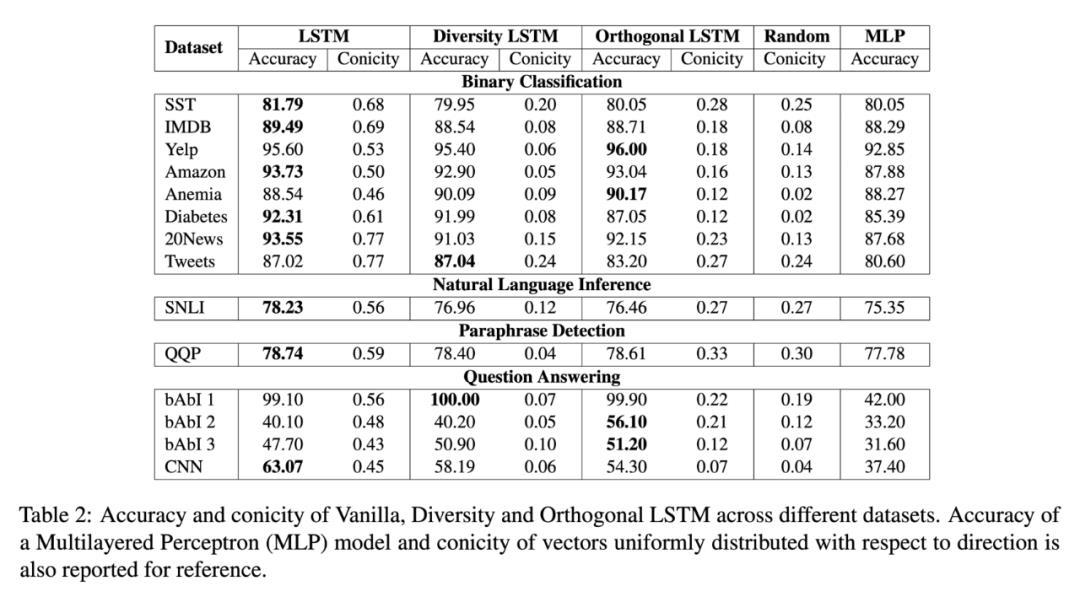
文章展示了传统LSTM和他们提出的 Diversity LSTM 的注意力权重的两个例子,新模型能够有效的减小无关单词上的权重(比如标点符号),而重要的单词上的权重相对较大。人工评测表明,相对于传统的 LSTM,在 Yelp,SNLI,Quora Question Paraphrase,Babi 1数据集合上,分别有 72.3%,62.2%,88.4%,99.0%的例子中 Diversity LSTM 的注意力权重提供了更好地表示。

3

动机
这篇文章的动机是试图从信息论的角度来定义探测任务。首先介绍什么叫探测任务。在NLP模型中,我们通常认为词语或者句子的表示蕴含了一定的语言学性质,比如句法信息或者语义信息。为了证明这一点,人们设置了探测任务,它是关注于简单的语言学性质的分类任务。比如对于一个LSTM encoder,我们使用句子 embedding 来训练一个时态分类器,如果能够得到正确的分类,我们认为这个 embedding 包含了一定的时态信息。
很多文章认为探测任务应该使用比较简单的模型,比如使用浅层感知机。这篇文章通过从信息论的角度来分析探测任务的原理,并反驳了这一观点。
细节
探测任务试图来回答一个embedding 在一个特定的语言学性质上 究竟蕴含了多少信息,理论上,我们可以用信息论的概念来刻画这一个数值。更加正式的,这篇文章定义,探测任务是衡量了一个 embedding 随机变量和语言学性质的随机变量之间的互信息。
我们用 T 表示探测任务的目标随机变量, R 表示 embedding 随机变量。那么T和R的互信息等于T的熵(也就是T的不确定性) 减去T和R的相对熵,也就是(当知道R之后,T的不确定性)。如果T完全的是由R决定的,这时候 T和R之间的相对熵等于0,互信息最大。如果T和R完全独立,互信息为0.
对于一个具体任务而言 是一个常数。我们来分析 ,由于我们不知道具体的概率分布,所以无法求出它的理论数值,但是,我们可以给出它的一个上界估计。当我们有了一个Probing model 之后,这时候可以知道, 是小于等于这个模型的交叉熵的。而这个交叉熵我们可以使用蒙特卡洛方法进行估计。
通过上述分析,我们可以得到下述结论:从信息论的角度出发,我们永远倾向于选择在探测任务上表现更好的模型,而不用担心过于复杂的模型暴力的学习了这个任务。从这个角度而言,学习探测任务和 embedding 蕴含了语言信息之间是没有区别的。
接下来,这篇论文试图分析上下文信息蕴含了多少额外的语言学信息。为此,引入了控制函数的概念,首选假设,每一个上下文的表示是独一无二的,也就是只要上下文不同,或者是词语不同,得到的表示是不一样的。在这种假设下,我们可以得到从上下文的 embedding 到 具体是哪个单词的一个对应关系,称作 id 函数,当得到单词之后,我们可以进一步的得到这个单词的 word-embedding。这两个过程的复合就是控制函数。
理论上,当一个随机变量经过变换之后,信息一定是减少的,因此有这个不等式。
我们考虑使用上下文 embedding 相对于非上下文 embedding 得到了多少额外信息。它就等于,当知道 之后,T 和 R之间的互信息
这篇文章认为,理论上,在独特性的假设下,因为上下文embedding和一个具体的句子之间存在着一一对应,所以上下文embedding蕴含了和原始句子一样多的信息,因此,从这一个角度出发,上下文 embedding(比如 BERT)并没有发掘更多语言信息。
实验
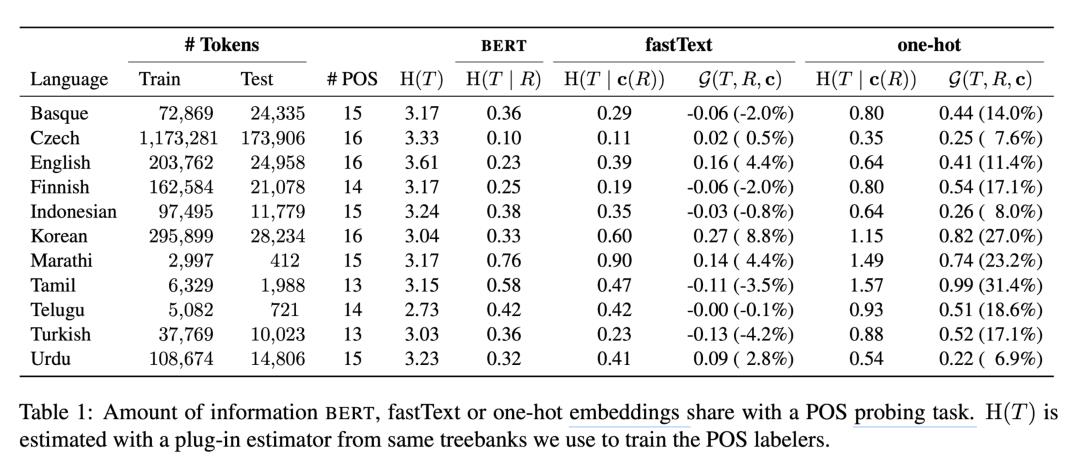
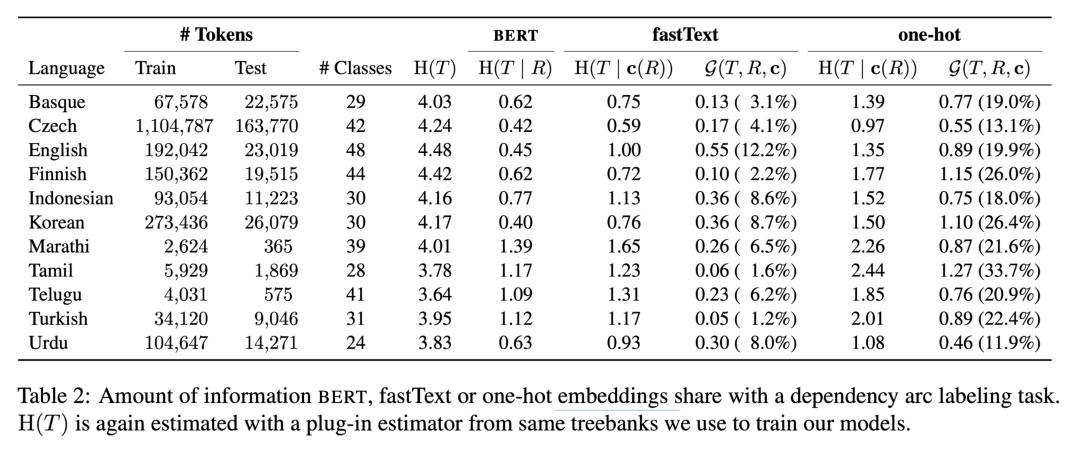
最后,这篇文章进行了试验,试验的探测任务是单词属性预测(POS),和依赖边标注任务(Dependency arc labeling)。它使用了随即查找来寻找最优的超参数。探测模型是多层感知机。控制函数中的 word-embedding 使用了fastText 和 one-hot 两种方法。
对于词性标注任务,试验结果表明,BERT 和 fastText 蕴含了差不多的信息,而对于依赖边标注问题,Bert 相对而言提供了多一点的信息。
参考文献
-
Sun, Xiaobing, and Wei Lu. "Understanding Attention for Text Classification." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. -
Mohankumar, Akash Kumar, et al. "Towards Transparent and Explainable Attention Models." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. -
Pimentel, Tiago, et al. "Information-theoretic probing for linguistic structure." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. -
Serrano, Sofia, and Noah A. Smith. "Is attention interpretable?." arXiv preprint arXiv:1906.03731 (2019). -
Jain, Sarthak, and Byron C. Wallace. "Attention is not explanation." arXiv preprint arXiv:1902.10186 (2019).
供稿人:张翼腾丨研究生二年级丨研究方向:神经网络可解释性丨邮箱:19210980096@fudan.edu.cn
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!



后台回复【五件套】
下载二:南大模式识别PPT

后台回复【南大模式识别】
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
记得备注呦
整理不易,还望给个在看!
以上是关于论文分享ACL 2020 神经网络的可解释性的主要内容,如果未能解决你的问题,请参考以下文章
跟我读论文丨ACL2021 NER 模块化交互网络用于命名实体识别