论文解读系列NER方向:SoftLexicon(ACL 2020)
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读系列NER方向:SoftLexicon(ACL 2020)相关的知识,希望对你有一定的参考价值。
文章目录
背景
SoftLexicon 出自ACL 2020的Simplify the Usage of Lexicon in Chinese NER
官方代码:
https://github.com/v-mipeng/LexiconAugmentedNER
论文:
https://arxiv.org/abs/1908.05969
模型结构
近年来学者试图利用词典(词汇信息)来提高中文命名实体识别(NER)的性能如Lattice LSTM等,但其模型架构十分复杂限制了其计算速度,从而限制了它在许多需要实时NER响应的工业领域中的应用。
SoftLexicon是一种简单而有效的将词汇信息纳入字符表示的方法。这种方法避免设计复杂的序列建模结构,并且对于任何NER模型,它只需要细微地调整字符表示层来引入词典信息。在4个中文NER基准数据集上的实验结果表明,该方法的推理速度比现有SOTA方法快6.15倍,性能更好。实验结果还表明,该方法可以很容易地与BERT等预训练模型相结合。实验表明当采用单层的Bi-LSTM实现序列建模层时,本文的方法在推理速度和序列标注性能上都比现有方法有了很大的提高。
SoftLexicon 算法流程大致如下:

大致有以下3个步骤:
- 输入序列的每个字符映射到一个密集向量中
- 构建软词典特征并将其添加到每个字符的表示中
- 将这些增强的字符表示输入到序列建模层和CRF层,以获得最终的预测结果。
字符表示层
输入文本字符序列记为
s
=
s=
s=
c
1
,
c
2
,
⋯
,
c
n
∈
V
c
\\left\\c_1, c_2, \\cdots, c_n\\right\\ \\in \\mathcalV_c
c1,c2,⋯,cn∈Vc, 其中
V
c
\\mathcalV_c
Vc是字符表,每个字符
c
i
c_i
ci用一个稠密向量表示(即embedding):
x
i
c
=
e
c
(
c
i
)
x_i^c=e^c\\left(c_i\\right)
xic=ec(ci)
其中
e
c
e^c
ec 是字符表示向量的查找表。
同时使用char+bichar的联合表示增强字符embedding:
x
i
c
=
[
e
c
(
c
i
)
;
e
b
(
c
i
,
c
i
+
1
)
]
x_i^c=\\left[e^c\\left(c_i\\right) ; e^b\\left(c_i, c_i+1\\right)\\right]
xic=[ec(ci);eb(ci,ci+1)]
其中
e
b
e^b
eb是bigram的embedding的查找表。
引入词汇信息
单纯使用字符信息的NER模型存在不能利用单词信息这个不足。为此,SoftLexicon提出两种方法:ExSoftword Feature 和 SoftLexicon 以在字符表示中引入词信息。对于字符序列 s = s= s= c 1 , c 2 , ⋯ , c n \\left\\c_1, c_2, \\cdots, c_n\\right\\ c1,c2,⋯,cn其中存在的单词记为 w i , j = c i , c i + 1 , ⋯ , c j w_i,j=c_i, c_i+1, \\cdots, c_j wi,j=ci,ci+1,⋯,cj
ExSoftword Feature:
ExSoftword是对Softword的拓展,与Softword不同,它不再只保留每个字符进行分词后的一个分词结果,而是使用词典获得所有可能的分词结果:
x
j
c
←
[
x
j
c
;
e
s
e
g
(
segs
(
c
j
)
]
,
x_j^c \\leftarrow\\left[x_j^c ; e^s e g\\left(\\operatornamesegs\\left(c_j\\right)\\right],\\right.
xjc←[xjc;eseg(segs(cj)],
其中
segs
(
c
j
)
\\operatornamesegs\\left(c_j\\right)
segs(cj) 表示字符
c
j
c_j
cj所有可能的分词结果,
e
s
e
g
(
seg
(
c
j
)
)
e^s e g\\left(\\operatornameseg\\left(c_j\\right)\\right)
eseg(seg(cj))是一个5维的multi-hot向量,各个维度分别对应:
B
,
M
,
E
,
S
,
O
\\\\mathrmB, \\mathrmM, \\mathrmE, \\mathrmS, \\mathrmO\\
B,M,E,S,O。
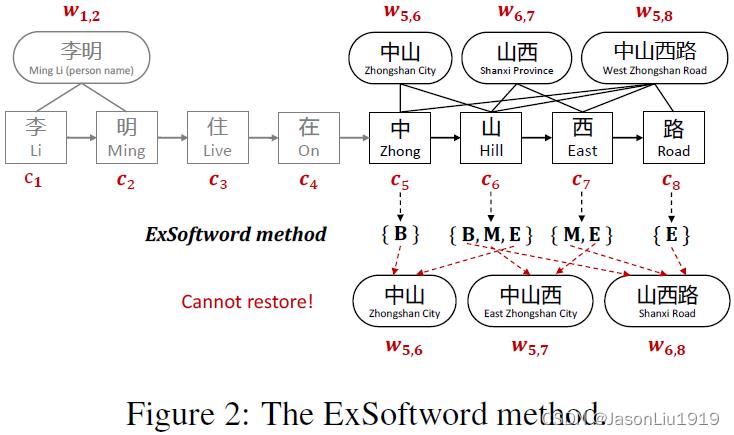
比如Figure 2中的“西”
c
7
(
“西”
)
c_7(“西”)
c7(“西”)出现在两个词中:
w
5
,
8
(
"
中山西路
"
)
w_5,8("中山西路")
w5,8("中山西路")和
w
6
,
7
(
"
山西
"
)
w_6,7 ("山西")
w6,7("山西")。因此,其对应的分割结果是
M
,
E
M,E
M,E,分别表示中间位置和结尾位置,可以看出第2和第3个维度对应的位置置为1,其他维度值为0。"西"这个字符的字符表示可以用以下方式进一步丰富:
x
7
c
←
[
x
7
c
;
e
s
e
g
(
M
,
E
)
]
x_7^c \\leftarrow[x_7^c ; e^s e g(\\M,E\\)]
x7c←[x7c;eseg(M,E)]
该方法有两个问题:
- 相比于 Lattice LSTM,该方法没有引入预先训练好的词汇embedding
- 仍然丢失匹配结果的信息。
Figure2中的示例
c
5
,
c
6
,
c
7
,
c
8
c_5,c_6,c_7,c_8
c5,c6,c7,c8字符序列的的ExSoftword feature结果是
B, B,M,E, M,E, E。但是对于这样一种给定的构建序列,存在多种可能的匹配结果。比如
w
5
,
6
\\left\\w_5,6\\right.
w5,6 (“中山”),
w
5
,
7
w_5,7
w5,7 (“中山西”),
w
6
,
8
w_6,8
w6,8 (“山西路”)
\\
和
w
5
,
6
\\left\\w_5,6\\right.
w5,6 (“中山”),
w
6
,
7
(
w_6,7\\left(\\right.
w6,7( “山西”),
w
5
,
8
w_5,8
w5,8 (“中山西 路”)。为此,无法知晓哪个才是正确的结果。
SoftLexicon:
作为对ExSoftword的改进,该方法由3个步骤组成:
(1) 对匹配到的单词进行分类:
为了保留分词信息,匹配到的词中的每个字符都被分类到 B,M,E,S中。对于每个字符
c
i
c_i
ci,这四个集合被认为为:
B
(
c
i
)
=
w
i
,
k
,
∀
w
i
,
k
∈
L
,
i
<
k
≤
n
M
(
c
i
)
=
w
j
,
k
以上是关于论文解读系列NER方向:SoftLexicon(ACL 2020)的主要内容,如果未能解决你的问题,请参考以下文章