DurIAN:基于时序注意力神经网络的语音合成系统 | 腾讯AI Lab
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DurIAN:基于时序注意力神经网络的语音合成系统 | 腾讯AI Lab相关的知识,希望对你有一定的参考价值。
随着深度学习技术的兴起和快速发展,以语音识别和合成为代表的语音处理技术得到了极大的飞跃,语音交互逐渐成为人机交互中的一个主流方式。而作为人机语音交互的出口,语音合成的效果直接影响到人机交互到体验,一个高质量的、稳定的语音合成系统能够让机器更加地拟人化,使人机交互过程更加自然。近年来,相比于传统的帧级语音合成模型,基于注意力机制的序列到序列模型统一了时长模型和声学模型的建模过程,提升了合成语音的自然度,该方案逐渐成为主流的语音合成研究方向。然而,由于注意力机制的不可控问题,上述方案的稳定性相对较差,限制了其应用能力。
本文重点介绍 AI Lab 提出的高质量、稳定的序列到序列语音合成系统方案 DurIAN。一方面,为了解决传统序列到序列模型到稳定性问题,该方案在模型中加入显式的时长预测模块来代替传统的注意力机制,避免注意力机制的不可控所带来的生成误差。结果显示,DurIAN 方案将语音合成错误率从 state-of-the-art(SOTA)的 Tacotron2 模型的 2% 降低到了 0%,极大地提升了语音合成系统的稳定性。另一方面,为了加速语音的生成过程,该方案提出了一种基于子带的语音合成声码器,在不损失语音音质的同时将实时率提升了近 3 倍。
本论文已被 Interspeech 2020 接收,以下为方案详细解读。

语音合成的后端模型一般分为声学模型和声码器两个部分,这两个部分都直接影响到合成语音的稳定性、自然度和实时率等等。本次介绍的方案分别针对上述两个部分进行了改进。
最新的语音合成声学模型一样采用基于注意力机制的序列到序列框架,该框架能够直接建模文本序列到语音特征之间的映射关系,避免了传统方法中时长模型和声学模型串联所导致的累积误差,并提升了合成语音的自然度。
一个最经典的基于注意力机制的序列到序列声学模型 Tacotron 分为编码器、解码器和注意力机制三部分。其中,编码器的目的是学习文本输入序列间的依赖关系,解码器的目的是自回归地迭代生成语音特征序列。而注意力机制则是作为桥接单元来决定解码器的每一个时刻使用编码器文本输入的哪一部分信息,它承担了传统语音合成系统中时长模型的作用,也是完成不等长序列映射功能的核心单元。
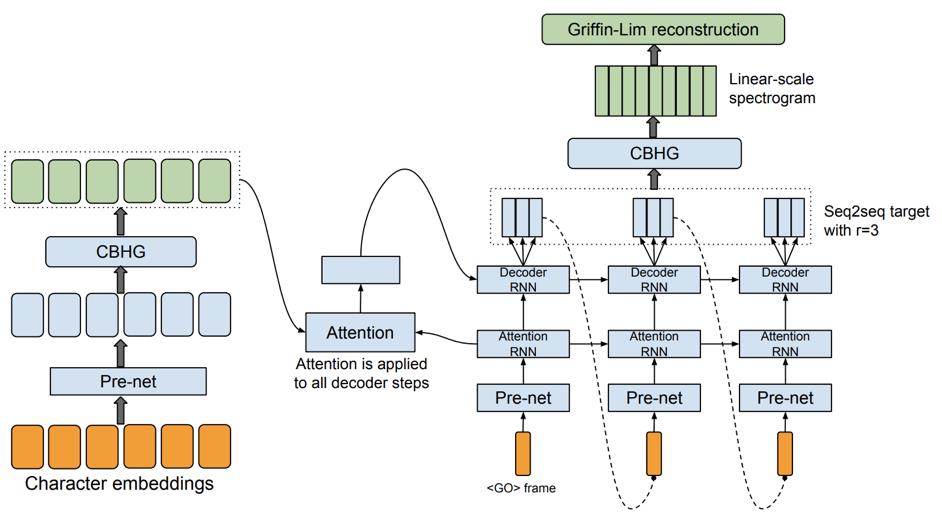 图 1 传统 Tacotron 模型
图 1 传统 Tacotron 模型
在上述基于注意力机制的框架中,由于注意力机制的学习过程是没有任何约束的,因此导致解码器生成的语音序列经常出现错读、漏读、重复读等问题。为了缓解该问题,研究人员提出了更适合语音合成任务的注意力机制,如 Tacotron2 框架等。但是,由于注意力机制本身所存在的问题,这些改进的序列到序列模型框架无法保证能够完全正确地生成特定的语音序列。
考虑到上述注意力机制本身所带来的稳定性问题,本文提出基于真实时长指导的对齐模型(Duration Informed Attention Network,DurIAN)来直接使用真实或预测的时长来指导语音特征的生成过程,从而在保证声学模型效果的同时提升了其稳定性,如图 2 所示。
DurIAN 模型使用一个对齐模型(Alignment Model)来替代传统序列到序列模型中的注意力机制,该对齐模型直接使用音素级的文本序列作为输入来预测每一个音素所对应的语音单元所持续的时间。在模型训练和解码过程中,给定文本输入 X,对齐模型会利用音素级的时长信息对编码器的输出进行扩帧,从而保证对齐模型输出序列的长度与声学模型最终输出的语音特征长度一致,从而实现不等长序列映射。而在扩帧过程中,为了区分同一个音素中的不同帧,对齐模型额外加入了位置信息编码来进行建模。为了保证声学模型的效果,DurIAN 同样采用了自回归解码器来生成最终的语音特征序列。
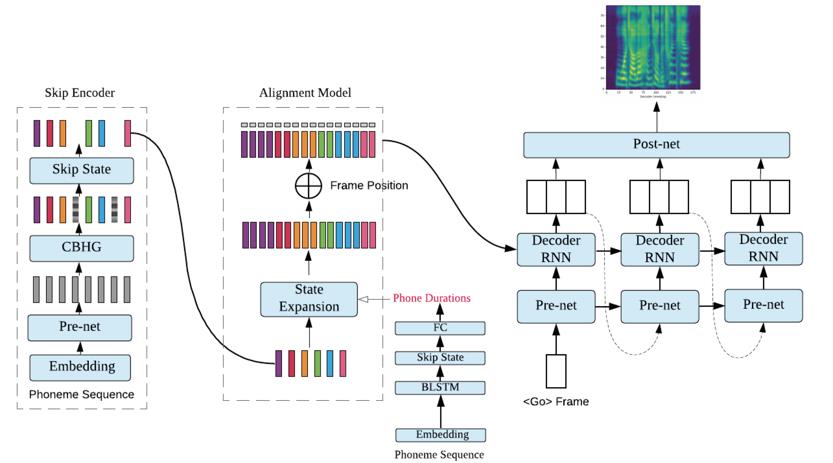 图 2 DurIAN 模型
图 2 DurIAN 模型
为了验证 DurIAN 模型的效果,我们首先比较了其与传统的帧级声学模型 Parametric、基于注意力机制的序列到序列模型 Tacotron2 的差异:
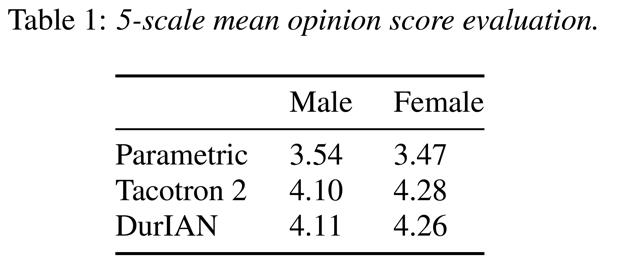
从上表中结果可以发现,DurIAN 模型在合成语音的自然度方面和 state-of-the-art (SOTA)的 Tacotron2 模型一样。而前文提到 DurIAN 的主要目的是解决基于注意力机制的声学模型稳定性问题,因此我们分别使用 DurIAN 和另外两种主流的基于注意力机制的序列到序列模型合成了同样的 1000 句文本,并分别统计了他们生成过程中的错误率:
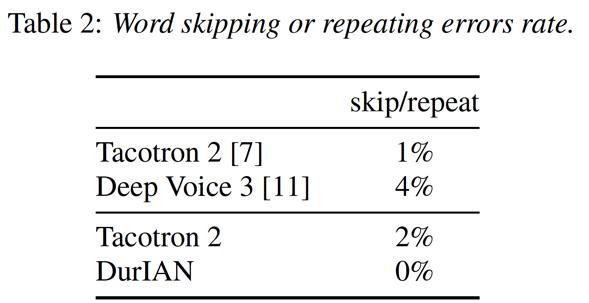
从表中结果可以发现,本文提出的 DurIAN 模型没有出现任何的生成错误,而其他的模型都会存在漏读、重复读等错误。这意味着,本文提出的基于时长模型指导的声学模型能够显著地提升序列到序列声学模型的稳定性。
上述声学模型的作用是从文本中预测其对应的语音特征,而最终我们需要将该语音特征还原为人类可听懂的语音信号,声码器的作用即为从语音特征中还原语音信号。传统的声码器一般基于信号处理的方式,此类声码器虽然还原效率很高,但是无法很好地还原出语音信号,会损伤合成语音的音质。而基于神经网络的声码器能够从语音特征中还原出高质量的语音信号,从而提升了合成语音的音质,但是该类声码器的运算量也相对较大,也即实时率较差。
对于语音信号来讲,如果将一维语音信号划分为 N 个子带,那么我们可以在每一个子带将原始信号降采样 N 次,并且这些子带能一起保留原始信号中的所有信息。基于此原理,我们可以使用不同的模型来分别建模不同的自带,并且在解码阶段使用多个 CPU 或者 GPU 进行并行解码从而提升语音合成的效率。但是这种方法其实并没有本质上降低语音生成过程中的计算量。因此,为了高效地从语音特征中还原出高质量的语音信号,本文提出了一种多子带的 WaveRNN 模型。如图 3 所示,该模型的大部分参数都由所有子带共享,而在运算过程中,我们直接使用上一个时刻所有子带的输出来预测下一个时刻所有子带的输出。通过这种方式,我们理论上能够将原始声码器的计算量降低近 N 倍,大大提升了语音合成的生产效率。
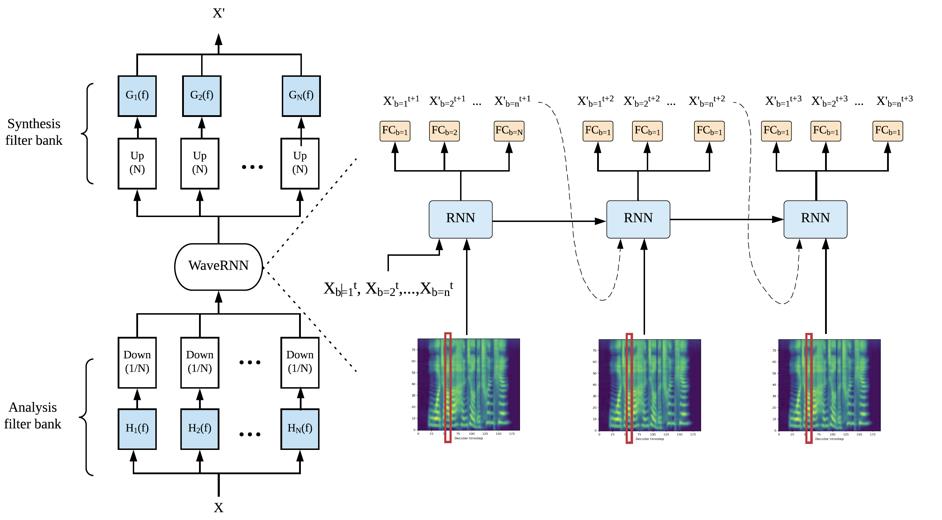 图 3 多子带 WaveRNN 模型
图 3 多子带 WaveRNN 模型
在实验中,我们衡量了多子带 WaveRNN 模型和全频带 WaveRNN 模型生成语音信号的实时率(Real Time Factor,RTF):

从表中第一行结果可以看出,全频带的 WaveRNN 模型的实时率为 1.33,而使用 4 个子带的 WaveRNN 声码器的实时率只有 0.5,其生成效率提高了近 3 倍。而为了进一步提升声码器的合成效率,我们将语音信号使用 8-bit 量化,此时声码器的实时率又能获得 3 倍的提升。
此外,由于声码器的效果直接影响到合成语音的音质,因此我们还衡量了多子带 WaveRNN 还原语音信号的质量:
从上表结果可以看出,8-bit 量化的 4 个子带的 WaveRNN 模型所生成语音的音质和全频带的 WaveRNN 并没有本质差别,但是实时率从原本的 1.337 提升到了 0.171,大幅提升了语音合成系统的生成效率。
本方案能够生成高质量的合成语音,解决了传统序列到序列声学模型的合成稳定性问题,并且显著提升了语音合成系统的生成效率。未来将进一步探索 DurIAN 模型的个性化应用,例如歌唱、音色定制等等,还将尝试针对低资源数据构建稳定的语音合成系统。此外仍将进一步探索新的声学模型和声码器,从而提升整个语音合成系统的性能。
Yu, Chengzhu, Heng Lu, Na Hu, Meng Yu, Chao Weng, Kun Xu, Peng Liu et al. "DurIAN: Duration Informed Attention Network For Speech Synthesis." Proc. Interspeech 2020 (2020): 2027-2031.
Wang, Yuxuan, R. J. Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang et al. "Tacotron: Towards end-to-end speech synthesis." arXiv preprint arXiv:1703.10135 (2017).
Shen, Jonathan, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen et al. "Natural tts synthesis by conditioning wavenet on mel spectrogram predictions." In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4779-4783. IEEE, 2018.
Kalchbrenner, Nal, Erich Elsen, Karen Simonyan, Seb Noury, Norman Casagrande, Edward Lockhart, Florian Stimberg, Aaron van den Oord, Sander Dieleman, and Koray Kavukcuoglu. "Efficient neural audio synthesis." arXiv preprint arXiv:1802.08435 (2018).
你也「在看」吗? 以上是关于DurIAN:基于时序注意力神经网络的语音合成系统 | 腾讯AI Lab的主要内容,如果未能解决你的问题,请参考以下文章