基于 Azure 的认知服务将文本合成语音
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于 Azure 的认知服务将文本合成语音相关的知识,希望对你有一定的参考价值。
基于 Azure 的认知服务将文本合成语音
Intro
前几天发了一个 .NET 20 周年祝福视频,语音是通过 Azure 的认知服务合成的,
下面就来介绍一下如何将使用 Azure 的认识服务实现将文本合成为语音
Prepare
你可以在 Azure Portal 上创建一个免费的语音服务,搜索 Speech 即可,在创建的时候可以 Pricing tier 可以选择 Free F0 就是对应的免费版本,免费版有调用次数限制,但是对于测试应该足够了,详细可以参考:
https://azure.microsoft.com/zh-cn/pricing/details/cognitive-services/speech-services/

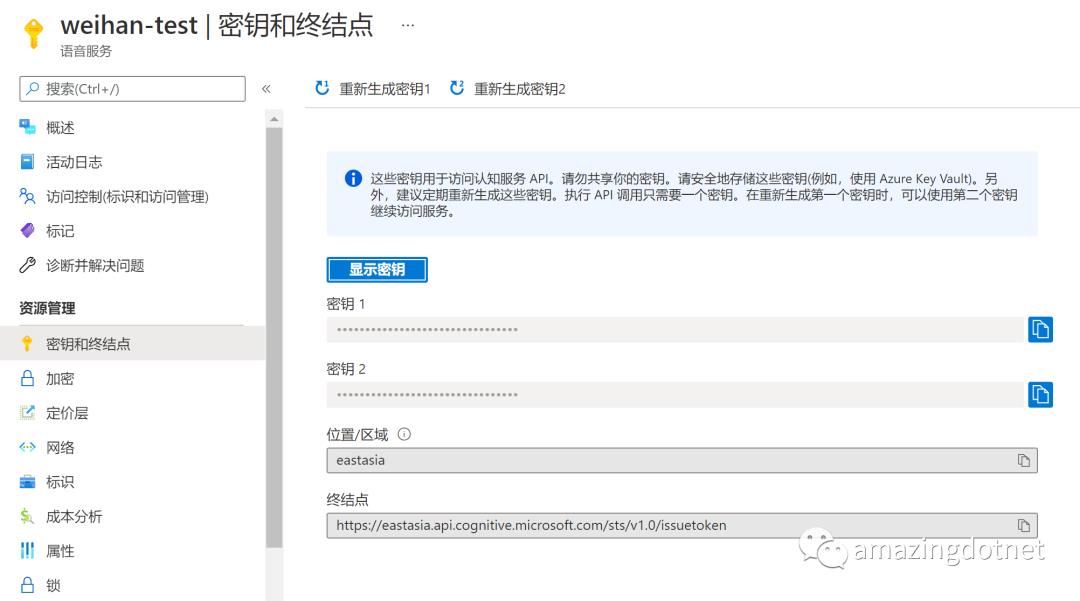
在创建成功之后可以在对应的资源界面中 “密钥和终结点” 页面里找到调用 API 需要的密钥
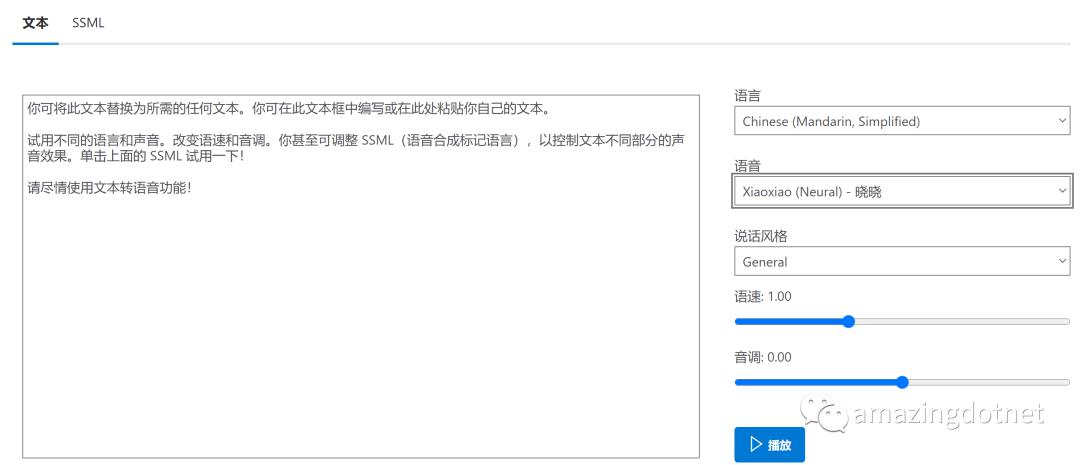
微软的语音服务支持很多不同的语言,不同的语音类型,我们可以根据需要进行选择,你可以在这个页面试用,来选择合适的语音
https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/#features
Sample
首先我们需要使用到语音服务的 SDK ,引用 NuGet 包Microsoft.CognitiveServices.Speech
文本合成语音首先需要指定一个语音类型,语音类型是分语言的,我们可以指定语言直接合成:
const string locale = "zh-CN";
// 将 key 直接替换为自己的密钥或者设置环境变量值为自己的密钥
var key = Environment.GetEnvironmentVariable("SpeechSubscriptionKey");
var config = SpeechConfig.FromSubscription(key, "eastasia");
// 支持的语言列表:https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
config.SpeechSynthesisLanguage = locale;
using var synthesizer = new SpeechSynthesizer(config);
await synthesizer.SpeakTextAsync(text);除了指定的语言,我们也可以指定语言对应的语音类型,可以通过 SDK 获取指定语言的语音类型,支持的语言列表可以参考:https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
// Creates a speech synthesizer
using var synthesizer = new SpeechSynthesizer(config);
using var voicesResult = await synthesizer.GetVoicesAsync(locale);
var voices = voicesResult.Voices;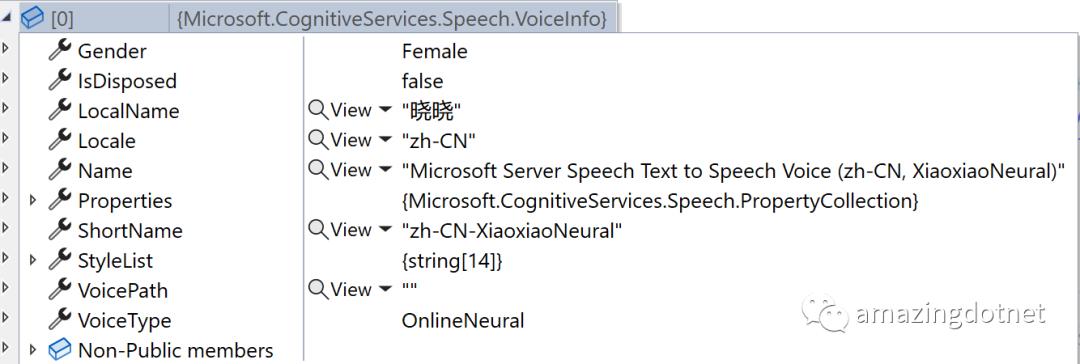
每个语音类型支持不同的语音风格
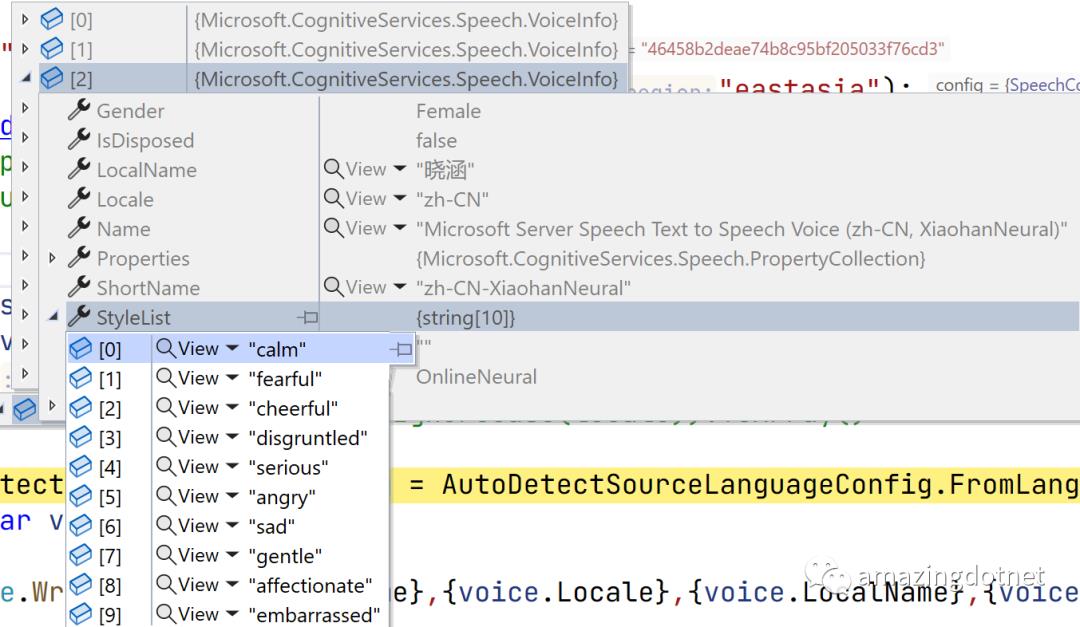
可以在微软的线上示例 https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/#features 尝试不同的语音类型,选择合适的语音类型,然后就可以进行下一步的语音合成

语音对应的 value 就是对应的语音类型,配置 config 的 SpeechSynthesisVoiceName,也可以使用上面获取到的语音对应的 ShortName
var text = @".NET 20 周年生日快乐";
var voiceName = "zh-CN-XiaoxiaoNeural";
config.SpeechSynthesisVoiceName = voiceName;
using var speechSynthesizer = new SpeechSynthesizer(config);
await speechSynthesizer.SpeakTextAsync(text);我们可以使用多种方式进行合成语音,前面使用是默认方式,默认方式语音会直接通过本地的麦克风直接播放
我们也可以输出语音到指定文件,示例如下:
var text = @".NET 20 周年生日快乐";
var voiceName = voices[0].ShortName;
config.SpeechSynthesisVoiceName = voiceName;
var outputFileName = $"output-voice.ShortName.wav";
using (var output = AudioConfig.FromWavFileOutput(outputFileName))
using var speechSynthesizer = new SpeechSynthesizer(config, output);
using var speechSynthesisResult = await speechSynthesizer.SpeakTextAsync(text);
Console.WriteLine($"Result: speechSynthesisResult.Reason");
除此之外我们还可以输出到一个数据流中,我们可以使用 AuditDataStream 来实现:
using var streamSynthesizer = new SpeechSynthesizer(config, null);
var streamResult = await streamSynthesizer.SpeakTextAsync(text);
using var audioDataStream = AudioDataStream.FromResult(streamResult);
// SaveToFile
//await audioDataStream.SaveToWaveFileAsync(outputFileName);
// Reads data from the stream
using var ms = new MemoryStream();
var buffer = new byte[32000];
uint filledSize;
while ((filledSize = audioDataStream.ReadData(buffer)) > 0)
ms.Write(buffer, 0, (int)filledSize);
Console.WriteLine($"Totally ms.Length bytes received.");除了前面之前使用一段文本,我们还可以使用 SSML 来定制语音
语音合成标记语言 (SSML) 是一种基于 XML 的标记语言,可让开发人员指定如何使用文本转语音服务将输入文本转换为合成语音。与纯文本相比,SSML 可让开发人员微调音节、发音、语速、音量以及文本转语音输出的其他属性。SSML 可自动处理正常的停顿(例如,在句号后面暂停片刻),或者在以问号结尾的句子中使用正确的音调。
使用 SSML 时请注意,特殊字符必须要转义
var ssml = $@"<speak xmlns=""http://www.w3.org/2001/10/synthesis"" xmlns:mstts=""http://www.w3.org/2001/mstts"" xmlns:emo=""http://www.w3.org/2009/10/emotionml"" version=""1.0"" xml:lang=""en-US""><voice name=""zh-CN-XiaoxiaoNeural""><prosody rate=""0%"" pitch=""50%"">
text
</prosody></voice></speak>";
using var ssmlSynthesisResult = await synthesizer.SpeakSsmlAsync(ssml);
Console.WriteLine($"Result: ssmlSynthesisResult.Reason");可以通过 <voice name="zh-CN-XiaoxiaoNeural">测试</voice> 来指定某一段文本要使用的语音类型,不同的文本可以使用不同的语音类型,语音可以通过 style 来配置,支持的 style 需要从前面的语音支持的 StyleList 中获取,如:
<voice name="zh-CN-XiaoxiaoNeural">
<mstts:express-as style="cheerful">
你可将此文本替换为所需的任何文本。你可在此文本框中编写或在此处粘贴你自己的文本
</mstts:express-as>
</voice>也可以配置语音的语速和音调,如下面的 prosody 中的 rate 就是语速,0是正常语速,rate="10%" 就是加快 10%,pitch 是音调的控制,pitch="10%" 就是音调提高 10%
<speak
xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="http://www.w3.org/2001/mstts"
xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US">
<voice name="zh-CN-XiaoxiaoNeural">
<mstts:express-as style="cheerful" >
<prosody rate="10%" pitch="10%">你可将此文本替换为所需的任何文本。你可在此文本框中编写或在此处粘贴你自己的文本。</prosody>
</mstts:express-as>
</voice>
</speak>使用 SSML 生成语音示例如下:
var ssml = $@"<speak xmlns=""http://www.w3.org/2001/10/synthesis"" xmlns:mstts=""http://www.w3.org/2001/mstts"" xmlns:emo=""http://www.w3.org/2009/10/emotionml"" version=""1.0"" xml:lang=""en-US""><voice name=""zh-CN-XiaoxiaoNeural""><prosody rate=""0%"" pitch=""50%"">
text
</prosody></voice></speak>";
using var ssmlSynthesisResult = await synthesizer.SpeakSsmlAsync(ssml);
Console.WriteLine($"Result: ssmlSynthesisResult.Reason");More
一般的我们基本可以使用普通的文本合成语音,如果要实现高级的语音服务,可以尝试一下 SSML 用法
使用 SSML 时,SSML 里定义的语音类型优先级最高,不会被 config 中的语音类型覆盖
更多用法可以自己再去发掘一下~~
References
https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/
https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
https://github.com/WeihanLi/SamplesInPractice/blob/master/AzureSamples/SpeechSample/Program.cs
https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/language-support
https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/speech-synthesis-markup?tabs=csharp
https://github.com/Azure-Samples/cognitive-services-speech-sdk
以上是关于基于 Azure 的认知服务将文本合成语音的主要内容,如果未能解决你的问题,请参考以下文章
我用3项微软 Azure人工智能认知服务打造定时语音提醒喝水助手
微软 Azure人工智能认知服务打造语音提醒喝水助手(带源码和演示地址)