基于图注意力时空神经网络的在线内容流行度预测
Posted MOOC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于图注意力时空神经网络的在线内容流行度预测相关的知识,希望对你有一定的参考价值。
现有在线内容流行度预测方法忽略对传播级联演化过程中的结构和时序特征的捕获.针对此问题,文中提出基于图注意力时空神经网络的在线内容流行度预测模型.利用图注意力机制学习在线内容的级联结构表示,利用时序卷积网络捕获传播级联的时序特征,通过全卷积层映射在线内容的流行度.在新浪微博和美国物理学会引文两个不同场景的数据集上的实验表明,文中方法的流行度预测性能较优.

鲍鹏(1987—),男,安徽六安人,2015年于中国科学院计算技术研究所获得博士学位,现为北京交通大学副教授、博士生导师,主要研究领域为社会媒体分析,信息传播,网络科学。主持包括国家自然科学基金在内的多项课题,作为科研骨干参与了863课题、973课题等重要科研任务。

社交网站和社会媒体等在线社会关系网络逐渐成为互联网服务和应用的主流,人人参与信息的产生和传播,获得前所未有的信息自主权.同时,在线社会关系网络的快速发展使信息产生社会化、信息内容碎片化和信息传播网络化等问题,给网络空间的科学管理和有效利用带来新的挑战.因此,深入分析在线社会关系网络,揭示网络信息传播的基本模式和内在规律,预测在线内容的未来传播态势,具有重要的学术意义和广泛的应用前景.
在线社会关系网络中的在线内容是一个广义的概念,通常指用户产生信息(User Generated Content,UGC).顾名思义,在线内容的流行度指在线内容的流行程度,量化方式有多种,如一条微博被转发的次数、一篇论文被引用的次数等,均可用于量化不同场景下的在线内容流行度.早期研究发现,由于用户有限的时间和注意力,在线内容的最终流行度呈现幂率分布[1].有效建模和预测在线内容的流行度,对于国家的政策制定、企业的商业活动和个人的网络使用都具有重要意义[2,3].
现有的流行度预测方法大致可分为3类:基于特征提取的方法[4,5,6,7,8]、生成式模型[9,10,11,12,13,14,15,16,17]和基于深度学习的方法[18,19].
基于特征提取的方法通过人工定义并获取的结构、时序、内容及用户等特征,将流行度预测问题形式化为一个回归或分类问题[4,5,6,7],然后利用机器学习模型对其进行建模和预测.Ugander等[4]研究Facebook网络中局部结构特征,发现用户邻居的结构多样性对信息传播具有重要影响.Pinto等[5]研究新浪微博上的信息传播,以流行度的增长序列作为特征,使用多元线性回归模型预测单条微博的流行度.Cheng等[6]将流行度预测问题形式化为二分类问题,并发现时序特征对预测准确率的贡献最大.这类方法揭示影响流行度预测的有效因素,具有一定的预测能力.
然而,基于特征提取的方法往往需要较强的领域经验,耗时耗力.随后,研究者们采用基于点过程的生成式模型,通过学习观测窗口内信息传播过程随时间变化的规律,刻画在线内容流行度的动态增长过程,实现对信息未来流行度增长的预测[9,10,11,12,13,14,15,16,17].Shen等[12]将信息传播过程建模为增强泊松过程,建模信息自身的吸引力、时间衰减效应及富者愈富机制.Gao等[13]使用不同的时间衰减函数,扩展增强泊松过程.Crane等[9]研究个体用户活动的等待时间分布,将每次信息传播看作一次激励,使用自激励Hawkes过程建模YouTube中视频的浏览量.这类方法能较好地解释信息传播过程.然而,由于对信息传播过程做出的一些强假设,并且只利用观测窗口内的信息对每条在线内容单独建模,该类方法预测结果并不理想.Mishra等[16]融合上述两类方法,使用自激励过程建模信息传播过程,然后合并学到的参数和手工提取的特征,使用回归模型预测在线内容的流行度,取得不错的预测效果.
近年来,基于深度学习的流行度预测方法逐渐兴起,这类方法使用端到端的方式,从数据中自动学习特征,预测在线内容的未来流行度.Li等[18]提出DeepCas(An End-to-End Predictor of Information Cas-cades),在信息级联结构上以随机游走的方式得到多条序列,对其进行有监督学习,得到流行度增量与随机游走序列之间的映射函数.Cao等[19]使用转发路径构建传播序列,通过深度学习刻画信息传播过程中的用户影响力、自激励机制及时间衰减效应等影响因子,提出DeepHawkes模型.上述两种方法均利用多条序列表示信息传播级联,忽略级联的结构特征.
本文提出基于图注意力时空神经网络(Graph Attention Based Spatial-Temporal Neural Network,GAST-Net)的流行度预测方法.自动学习不同转发对最终流行度的影响,使用图注意力机制,通过图卷积的方式学习观测窗口内不同阶段的传播级联的表示.然后,将这些不同阶段的级联特征放入时序卷积网络,获取信息传播的时序特征.最后,通过全连接层映射到在线内容的流行度增量.在新浪微博和美国物理学会(American Physical Society,ASP)数据集上的实验表明,本文方法对流行度预测的性能较优.
1
基于图注意力时空神经网络
的流行度预测方法
1.1问题定义
传播级联是以有向图的形式表示在线内容的扩散过程,其中,节点表示参与该传播过程的用户,有向边表示用户间对该在线内容的一次传播行为.本文研究在线内容对象为新浪微博中的微博和引文网络中的论文,它们均以传播级联的方式进行流行度增长.分别使用微博的转发数和论文的引用量刻画流行度.使用M表示在线内容集合: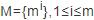 ,其中数据集中在线内容的数量为m.
,其中数据集中在线内容的数量为m.
对于在线内容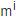 ,传播级联可表示成三元组集合的形式:
,传播级联可表示成三元组集合的形式:
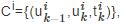
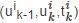 表示从在线内容发布开始的第k次转发或引用,即用户
表示从在线内容发布开始的第k次转发或引用,即用户
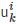 在
在
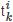 时刻继用户
时刻继用户
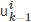 之后转发或引用在线内容
之后转发或引用在线内容
给定在线内容在观测窗口[0,T)内的传播级联,当前观测到的流行度为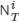 ,在线内容最终的流行度定义为
,在线内容最终的流行度定义为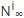 .流行度预测问题就是预测在线内容的流行度增量:
.流行度预测问题就是预测在线内容的流行度增量:
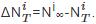
1.2模型框架
当前基于深度学习的流行度预测模型如DeepCas和DeepHawkes,均通过采样多条序列表示传播级联结构.这种方式受限于级联尺度的变化范围(大小从个位数到百万量级)[6],难以获得信息传播级联的整体结构信息.为了解决上述问题,本文提出对整个传播级联图进行表示学习的方法.使用图注意力网络(Graph Attention Network,GAT)[20]对级联中相邻节点进行卷积操作,充分考虑相邻节点之间的局部结构关系,以及不同节点对于级联传播发挥的不同作用.将观测窗口内的级联结构按时间划分成不同阶段的演化序列,通过时序卷积网络(Temporal Convolutional Network,TCN)[21]获取级联演化的时序动态过程,充分考虑级联结构演化的先后时序依赖关系,从而能够准确提取传播级联演化过程中的结构特征和时序特征.
模型的整体框架结构如图1所示.首先,将观测窗口内的在线内容传播级联(有向无环图)表示成邻接矩阵形式,并为每个节点加入自环,如图2所示.然后,根据传播级联中节点的到达时刻,对其特征表示进行初始化,并将邻接矩阵和节点的特征表示投入到图注意力卷积层中进行图卷积操作,提取传播级联的结构特征,更新各节点的特征表示.在最后一层图注意力卷积层,通过注意力机制整合不同阶段的到达节点,形成多个阶段的级联结构的向量表示.再使用时序卷积网络捕获不同阶段级联的时序依赖,更好地刻画级联的动态演化过程,从而得到传播级联的多通道向量表示.最后,通过全卷积层对得到的级联表示进行一维全卷积操作,并映射到在线内容最终的流行度增量.
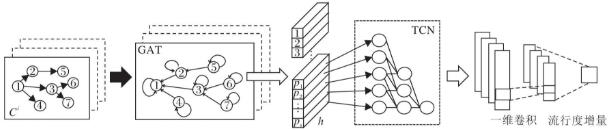
图1 GAST-Net模型架构图
Fig.1 Framework of GAST-Net model
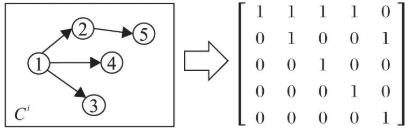
图2级联的邻接矩阵表示
Fig.2 Adjacency matrix form of cascade graph
1.3观测窗口数据表示
目前,基于深度学习的流行度预测方法主要借鉴自然语言处理的方式,使用多条序列(类似句子)表示级联结构(类似文档).这种表示方式有2个缺点:1)不同的在线内容流行度相差很大,结构变化多样,很难使用固定个数、固定长度的序列表示,如流行度较大的在线内容通常难以表示;2)使用序列表示图结构,通常会忽略图的全局结构和部分局部结构.级联的形成不是基于单条路径序列,而是以一个整体在演化,单纯使用一组序列表示级联结构不能捕获级联的全局特征,以致损失全局信息.另外,这种表示方式只能表示级联的深度优先的局部结构,忽略广度优先的局部结构.
本文提出数据表示方式,直接对整个传播级联结构进行特征表示学习.这种数据表示方式能完整地保留传播级联的结构特征及各个节点的到达时序特征.
根据级联中每个节点的到达时刻进行独热编码(One-Hot Code),初始化节点的特征表示.为了计算方便,将观测窗口划分成更细粒度的时间间隔,用于刻画传播级联结构的演化和各个节点加入级联的时间特征.尽管这种表示方式是离散的,无法刻画每个节点具体的到达时刻,但本文使用更小的时间粒度,较准确地保留每个节点到达的时间特征,具体做法如下.将观测窗口[0,T)划分成d个不相交的细粒度时间间隔:
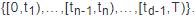
节点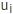 到达
到达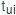 时刻所在的时间间隔编码为1,其余为0,即当
时刻所在的时间间隔编码为1,其余为0,即当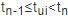 时,
时,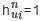 ,其中,节点ui的特征表示为
,其中,节点ui的特征表示为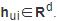
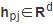 为该阶段内到达节点的独热编码求和,即
为该阶段内到达节点的独热编码求和,即
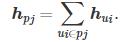
拼接级联中各节点的到达特征和s个阶段的级联特征,得到特征矩阵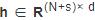 .最后,使用邻接矩阵A表示观测窗口内的级联图结构和s个阶段的级联结构,A∈R
.最后,使用邻接矩阵A表示观测窗口内的级联图结构和s个阶段的级联结构,A∈R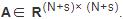
当1≤i≤N,1≤j≤N时,级联的邻接矩阵表示如下:
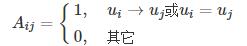
当1≤i≤N,N<j≤N+s时,级联的邻接矩阵表示如下:
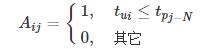
其中, 表示节点
表示节点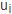 加入级联的时刻,
加入级联的时刻,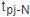 表示第j-N阶段的起始时刻.同理可得当1≤j≤N,N<i≤N+s时的邻接矩阵表示.
表示第j-N阶段的起始时刻.同理可得当1≤j≤N,N<i≤N+s时的邻接矩阵表示.
在新浪微博场景下,刻画节点到达时刻特征的时间间隔设为2 min,刻画传播级联结构动态演化的时间间隔设为10 min;APS论文引用场景下,分别设为1个月和6个月.
1.4网络结构
得到传播级联的邻接矩阵和特征矩阵表示后,将其投入到图注意力卷积层中,对整个传播级联结构进行图卷积操作.
传播级联结构中的每个节点对整个流行度增量的贡献不同.例如:级联形成早期到达的节点可能对最终流行度的影响更大;邻居多的节点更有可能促进级联的增长.对图中节点进行卷积操作能有效提取级联的结构特征,捕获不同节点在图中扮演的角色.但是,不同于非欧几里得空间的网格结构,传播级联图中每个节点的邻居个数不固定,变化范围较大,无法使用一般的卷积神经网络对图结构进行卷积.
针对上述问题,使用文献[20]提出的图注意力卷积网络,改进节点间的注意力矩阵的计算.首先,对输入的特征矩阵进行线性变换,计算级联各个节点之间的权重矩阵e,改进后的计算公式如下:
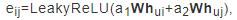
其中,LeakeyReLU为激活函数,hui和huj为节点ui和节点uj的特征表示,W为特征转换矩阵,a1和a2分别表示节点ui和节点uj的特征权重参数.W、a1和a2均通过学习得到.
将权重矩阵e中无连边的位置赋值为0,并对权重矩阵按行进行归一化,得到注意力矩阵α:
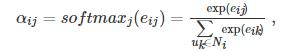
其中,元素αij表示节点ui到节点uj的注意力权重,Ni表示节点ui的邻居节点.
通过注意力矩阵可以对节点的邻居进行一维卷积操作,更新节点的特征表示.为了保证模型的稳定性和最终效果,使用多头注意力机制:
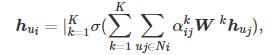
其中,hui为节点ui特征表示,K为多头注意力的头数,σ(⋅)为激活函数,W为特征转换矩阵.
使用图注意力网络学到的节点特征表示能更好地获取传播级联的局部结构信息.经过几层图注意力卷积后,得到级联的N个节点和s个阶段级联的抽象特征表示,最后一层图注意力层不再更新节点特征,只通过加和池化(Sum Pooling)整合各个节点,更新不同阶段的级联表示,得到一个长度为s的级联特征向量序列.将得到的序列投入到时序卷积网络中,提取级联演化的时序特征,通过一维全卷积层映射到最终的流行度增量.时序卷积网络中使用因果卷积提取时序特征,并利用空洞卷积提升感受野大小,降低卷积层,解决梯度消失、模型复杂、长序列依赖等问题.为了提升方法性能,在时序卷积网络的各个卷积层之间加入批规范化处理.
2
实验及结果分析
2.1实验数据集
本文使用如下2个不同的流行度预测场景数据集进行评估:新浪微博转发数据集和美国物理协会论文引用数据集(APS).
新浪微博数据集收集新浪微博2016年6月1日一天内所有的原发微博,以及每条微博从发布起24 h内的转发信息.微博的生存周期一般较短,如图3(a)所示.对每条微博而言,24 h内的转发量已经接近最终的流行度N∞.因此,将微博发出后24 h的转发数作为最终流行度.
实验中设置观测窗口分别为1 h、2 h和3 h,过滤观测窗口内转发数少于10条或多于1 000条的微博,并对观察窗口之外流行度增量为零的在线内容进行降采样.为了避免用户作息规律的影响,只保留发布时间在8∶00~18∶00的微博.将新浪微博数据集按70%、15%、15%的比例划分为训练集、验证集和测试集.
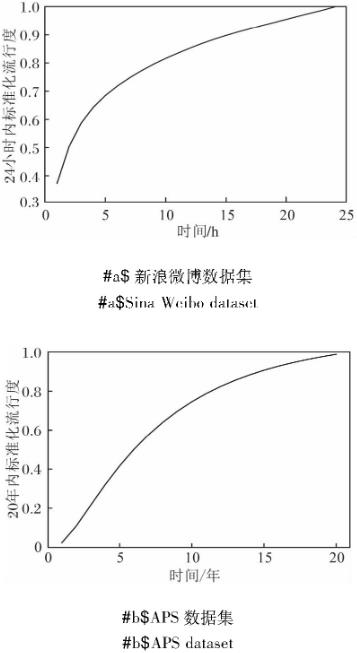
图3 2个数据集流行度标准化表示
Fig.3 Normalized popularity on 2 datasets
APS论文引用数据集包含1893年至2009年美国物理学会11种期刊上的论文及其引用关系.为了方便表示,采用和DeepHawkes相同的处理方式,将每篇文章的合作作者看作一个整体,即在传播级联结构中表示为一个节点,如图3(b)所示.对于每篇论文,发表后20年的引用量已接近最终的流行度N∞.因此,将论文发表后20年的引用数作为最终流行度,只使用发表于1893年至1989年的论文.实验中设置观测窗口分别为3年、6年和9年,过滤观测窗口内引用量小于10的论文.类似地,将APS论文引用数据集按70%、15%、15%的比例划分为训练集、验证集和测试集.
2.2对比方法
为了评估本文方法预测的有效性,选取目前最具代表性的流行度预测方法进行对比实验.
近期的研究表明,利用结构特征和时序特征能有效预测在线内容的流行度.提取:1)每条在线内容观测窗口内的级联结构特征,包括第一层节点数、最后一层节点数、转发或引用的平均路径长度和最大路径长度;2)时序特征,包括最后一次的转发或引用时间、转发或引用的平均时间间隔及固定时间阶段的流行度增量.这里设置新浪微博数据的时间阶段为10 min,APS论文引用数据的时间阶段为1年.
获取到在线内容的特征后,分别使用线性回归模型和多层感知机模型有监督地将这些特征映射到在线内容的流行度增量.此外,还选取1个生成式模型和2个基于深度学习的流行度预测模型.具体对比方法如下.
1)SEISMIC(Self-exciting Model of Information Cascades)[15].使用Hawkes自激励点过程刻画信息传播过程,利用用户粉丝数作为用户影响力,建模每次转发的自激励过程,并使用幂率函数刻画信息传播过程中的时间衰减模式.
2)DeepCas[18].利用随机游走策略从级联结构中提取多条节点序列,使用注意力机制为各条序列分配权重,得到级联的特征表示,最后映射到最终的流行度增量.自动学习每条在线内容的级联表示并预测最终的流行度增量.
3)DeepHawkes[19].利用端到端的深度学习刻画信息传播过程中的可解释性影响因素,包括用户影响力、自激励机制和时间衰减效应,具备良好的可解释性和较好的预测能力.
2.3消融实验设置
为了验证方法的有效性,设计消融实验.构建2个删减版本的GAST-Net,分别表示为GAST-TCN和GAST-GAT.
GAST-TCN去除原模型中的时序卷积网络,通过图注意力网络学习得到各个阶段的级联表示后,直接对它们加和池化,通过一维全卷积层映射到最终的流行度增量.
GAST-GAT去除原模型中的图注意力网络,不再对级联结构图进行卷积操作.将级联中各个节点的特征向量进行一次线性变换后,对各个阶段内到达的节点加和池化,得到各个阶段的向量表示,再通过时序卷积网络和一维全卷积层,预测级联的流行度增量.
与对比方法一致,使用均方对数误差(Mean Square Log-Transformed Error,MSLE)衡量方法的预测能力.MSLE的定义如下:
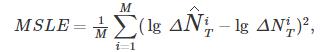
其中,M表示数据集的大小,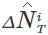 表示方法预测在线内容的流行度增量,
表示方法预测在线内容的流行度增量,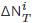 表示实际观测到的流行度增量.
表示实际观测到的流行度增量.
另外,还使用平方对数误差的中位数(median of Square Log-transformed Error,mSLE)度量方法预测误差的中间趋势.
对于方法参数:从{5e-4,1e-4,5e-5,1e-5,5e-6,1e-6}中选择初始的学习率;从{5e-4,1e-4,5e-5,1e-5,5e-6,1e-6}选择权重衰减因子(Weight Decay);从{16,32,64,128,256}中选择训练的批大小;从{0.2,0.4,0.6,0.8}中选择随机失活因子(Dropout);从{4,6,8,10}中选择多头注意力的头数;从{32,64,128,256,512}中选择图注意力网络的隐藏层和输出层单元数.最终,设置学习率为5e-6,衰减因子为5e-6,批大小为32,随机失活因子为0.6,多头注意力头数为8,隐藏层单元数为256,输出层单元数为128.
2.4实验结果
在新浪微博数据集和ASP数据集上的实验结果如表1和表2所示.
表1各方法在新浪微博数据集上的实验结果
Table 1 Experimental results of different methods on Sina Weibo dataset
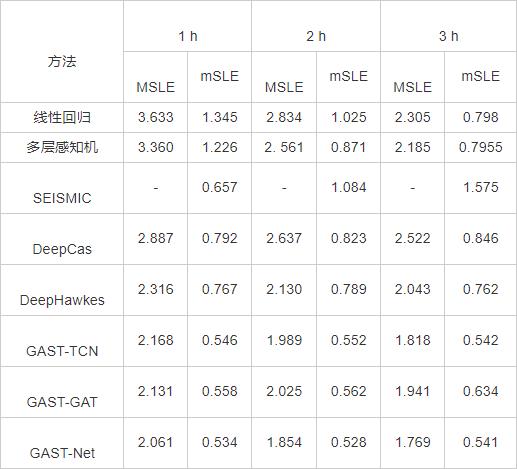
GAST-Net的预测结果明显优于其它4种对比方法.具体地,在新浪微博数据集上,当观测窗口分别为1 h、2 h和3 h时,相比Deep-Hawkes,GAST-Net的预测性能在MSLE指标上分别提升11.0%、13.0%和13.4%,在mSLE指标上分别提升30.4%、33.1%和29.0%.
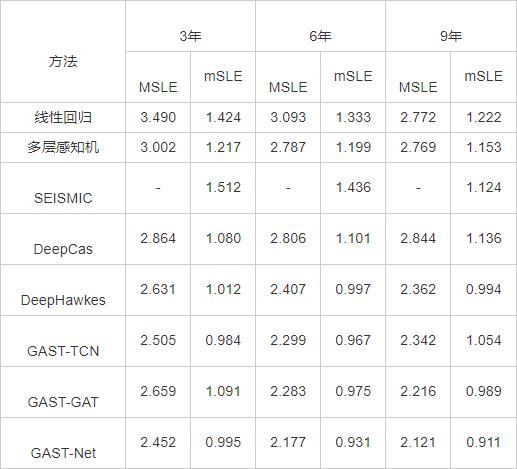
在APS数据集上,当观测窗口分别为3年、6年和9年时,相比DeepHawkes,GAST-Net的预测性能在MSLE指标上的分别提升6.8%、9.5%和10.2%,在mSLE指标上的分别提升1.7%、6.6%和8.4%.值得注意的是,当前的流行度增量已转为对数形式,因此,在实际值尺度上的性能提升会更大.
由表1和表2可看出,线性回归模型和多层感知机的预测表现都不理想.这是因为手工提取特征的方式很难获得传播级联结构的有效特征,此外,使用这些精心挑选的特征训练方法时,容易陷入过拟合.参照DeepHawkes,只展示SEISMIC在mSLE指标下的结果.由于SEISMIC训练时未利用最终的流行度增量作为监督,因此预测性能较差.
此外,实验结果还表明,当观测窗口较短时,DeepCas的表现优于另外2种基于人工特征的模型.随着观测窗口的增长,流行度的预测越容易,预测误差也越小,这是因为越长的观测窗口提供的传播级联演化信息越多.但是,随着观测窗口的增长,DeepCas的性能提升不多,反而差于基于特征提取的两种方法.当对观测窗口为3 h的新浪微博数据集或观测窗口为9年的ASP数据集进行预测时,线性回归和多层感知机的预测误差都低于DeepCas.一个可能的解释是:DeepCas直接对观测窗口内最终形成的级联结构进行随机游走,获取传播序列,忽略各个节点的到达顺序.所以当观测窗口越长,忽略节点先后顺序带来的影响就越大.此外,还发现DeepHawkes的预测性能优于DeepCas,因为DeepHawkes使用转发/引用路径序列,考虑各个节点之间的到达顺序.然而,仅使用多条序列表示传播级联会忽略传播级联的全局结构,因此在预测性能上差于GAST-Net.
对比在新浪微博数据集和APS数据集上的实验结果发现,所有方法在新浪微博数据集上的流行度预测误差更小.一种可能的解释是:新浪微博数据集使用同一天的数据,各条微博之间的流行度增长模式具有一定的规律.而APS数据集的时间跨度较大,不同时期的论文引用的增长模式存在一定的差异.因此,ASP数据集上的预测结果差于新浪微博数据集.
此外,表1和表2也展现消融实验的结果,当分别去除GAST-Net中的GAT部分和TCN部分后,方法的预测性能均有不同程度的下降,表明本文方法中各个部分的有效性.值得注意的是,当观测时间较长时,GAST-TCN在新浪微博数据集上的预测性能优于GAST-GAT,而在APS数据集上,结论恰好相反.一个可能的解释是:微博和论文的生命周期存在显著差异,对于一篇论文,其引用通常在发表后较长时间才逐渐增长,所以当观测时间较长时,才能捕获更多的时序演化信息.
GAST-Net的训练过程较高效.本文实验环境配置是一台3.60 GHz、32 GB RAM、GTX 1080 GPU的台式机,方法训练2 h~3 h即可收敛.如果硬件配置提高,将会进一步提升方法效率.由于GAST-Net是针对单个传播级联进行建模,无需考虑潜在的全局网络结构,因此能够适用于大规模网络.
3
结束语
本文提出基于图注意力时空神经网络的流行度预测模型,能准确提取传播级联演化过程中的结构特征和时序特征.利用图注意力机制,通过图卷积的方式对在线内容传播过程不同阶段的级联结构进行表示学习,利用时序卷积网络获取传播级联的时序特征,通过全连接层映射在线内容的流行度.在新浪微博和APS两个不同场景的数据集上的实验表明,GAST-Net的流行度预测性能较优.
今后将进一步探索如何利用图表示学习对信息传播过程进行建模,分别从节点、基序(Motif)和传播图3个层面展开,进一步辅助构建在线内容流行度预测模型,从而提升预测性能.此外,还将致力于研究不同场景中信息传播的统一性和差异性问题,构建一个统一的流行度预测框架.
参考文献:
[1]BARABÁSI A L.The Origin of Bursts and Heavy Tails in Human Dynamics.Nature,2005,435:207-211.
[2]LESKOVEC J,ADAMIC L A,HUBERMAN B A.The Dynamics of Viral Marketing[J/OL].[2019-07-15].https://www.csNaNu.edu/~jure/pubs/viral-tweb.pdf.
[3]WATTS D J,DODDS P S.Influentials,Networks,and Public Opi-nion Formation.Journal of Consumer Research,2007,34(4):441-458.
[4]UGANDER J,BACKSTROM L,MARLOW C,et al.Structural Diversity in Social Contagion.Proceedings of the National Academy of Sciences of the United States of America,2012,109(16):5962-5966.
[5]PINTO H,ALMEIDA J M,GONCALVES M A.Using Early View Patterns to Predict the Popularity of Youtube Videos//Proc of the 6th ACM International Conference on Web Search and Data Mining.New York,USA:ACM,2013:365-374.
[6]CHENG J,ADAMIC L A,DOW P A,et al.Can Cascades Be Predicted?//Proc of the 23rd International Conference on World Wide Web.New York,USA:ACM,2014:925-936.
[7]ANDERSON A,HUTTENLOCHER D,KLEINBERG J,et al.Glo-bal Diffusion via Cascading Invitations:Structure,Growth,and Homophily//Proc of the 24th International Conference on World Wide Web.New York,USA:ACM,2015:66-76.
[8]BAO P,SHEN H W,HUANG J M,et al.Popularity Prediction in Microblogging Network:A Case Study on Sina Weibo//Proc of the 22nd International Conference on World Wide Web.New York,USA:ACM,2013:177-178.
[9]CRANE R,SORNETTE D.Robust Dynamic Classes Revealed by Measuring the Response Function of a Social System.Proceedings of the National Academy of Sciences of the United States of America,2008,105(41):15649-15653.
[10]MATSUBARA Y,SAKURAI Y,PRAKASH B A,et al.Rise and Fall Patterns of Information Diffusion:Model and Implications//Proc of the 18th ACM SIGKDD International Conference on Know-ledge Discovery and Data Mining.New York,USA:ACM,2012:6-14.
[11]WANG D S,SONG C M,BARABÁSI A L.Quantifying Long-Term Scientific Impact.Science,2013,342(6154):127-132.
[12]SHEN H W,WANG D S,SONG C M,et al.Modeling and Predicting Popularity Dynamics via Reinforced Poisson Processes//Proc of the 28th AAAI Conference on Artificial Intelligence.Palo Alto,USA:AAAI Press,2014:291-297.
[13]GAO S,MA J,CHEN Z M.Modeling and Predicting Retweeting Dynamics on Microblogging Platforms//Proc of the 8th ACM International Conference on Web Search and Data Mining.New York,USA:ACM,2015:107-116.
[14]BAO P,SHEN H W,JIN X L,et al.Modeling and Predicting Popu-larity Dynamics of Microblogs Using Self-Excited Hawkes Processes//Proc of the 24th International Conference on World Wide Web.New York,USA:ACM,2015:9-10.
[15]ZHAO Q Y,ERDOGDU M A,HE H Y,et al.SEISMIC:A Self-Exciting Point Process Model for Predicting Tweet Popularity//Proc of the 21st ACM SIGKDD International Conference on Know-ledge Discovery and Data Mining.New York,USA:ACM,2015:1513-1522.
[16]MISHRA S,RIZOIU M A,XIE L X.Feature Driven and Point Process Approaches for Popularity Prediction//Proc of the 25th ACM International Conference on Information and Knowledge Mana-gement.New York,USA:ACM,2015:1069-1078.
[17]BAO P,ZHANG X X.Uncovering and Predicting the Dynamic Process of Collective Attention with Survival Theory.Scientific Reports,2017,7(1).DOI:10.1007/s10115-016-0955-7.
[18]LI C,MA J Q,GUO X X,et al.DeepCas:An End-to-End Predictor of Information Cascades//Proc of the 26th International Conference on World Wide Web.New York,USA:ACM,2017:577-586.
[19]CAO Q,SHEN H W,CEN K T,et al.DeepHawkes:Bridging the Gap between Prediction and Understanding of Information Cascades//Proc of the 26th ACM International Conference on Information and Knowledge Management.New York,USA:ACM,2017:1149-1158.
[20]VELICKOVIC P,CUCURULL G,CASANOVA A,et al.Graph Attention Network[C/OL].[2019-07-15].https://arxiv.org/pdf/1710.10903.pdf.
[21]BAI S,KOLTER J Z,KOLTUN V.An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Mo-deling[C/OL].[2019-07-15].https://arxiv.org/pdf/1803.01271v1.pdf.
基金项目:
国家自然科学基金项目(No.61702031);
北京市优秀人才培养青年骨干个人项目(No.2017000020124G054);
中央高校基本科研业务费项目(No.2018JBM072);
中国科学院网络数据科学与技术重点实验室开放课题项目(No.CASNDST201702)。

扫码即可申请加入在线教育交流群
更多资讯
以上是关于基于图注意力时空神经网络的在线内容流行度预测的主要内容,如果未能解决你的问题,请参考以下文章
用于联合人群流动和转移预测的时空图注意嵌入:基于 Wi-Fi 的移动案例研究