基于支持向量机(SVM)进行人脸识别
Posted 名字都被取光了T T
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于支持向量机(SVM)进行人脸识别相关的知识,希望对你有一定的参考价值。
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)
这次采用的人脸识别方式并没有调用摄像头来采集人脸信息,原因是因为只是简单的使用一下sklearn的机器学习库(其实是觉得麻烦,至少面向百度一天...),所以,主要采用的流程是:
网络采集图片 --> 识别人脸信息 --> 数据处理 --> 训练测试集分离 --> 模型训练 预测
很简单 网络上采集30张彭于晏的照片,30张迪丽热巴的照片,30张陈冠希的照片 ... 然后利用20张进行训练,10张进行预测,来进行准确率的判别。
Step1 --> 网络采集图片
import aiohttpimport asyncioimport reimport randomstart_url = "https://image.baidu.com/search/index?tn=baiduimage&word=彭于晏大头照(或者是某人的大头照)"async def init_urls(url,p):async with aiohttp.ClientSession() as session:async with session.get(url) as resp:if resp.status in [200, 201]:if p:data = await resp.text()image_url = re.findall('hoverURL":"(.*?)"', data)return image_urlelse:content = await resp.read()path = r'C:\Users\lvhaitao\Desktop\Primitive_face\chenguanxi' + '/' + str(random.randint(100, 1000)) + '.jpg'with open(path, 'wb') as f:f.write(content)if __name__ == "__main__":loop = asyncio.get_event_loop()future_image_list = asyncio.ensure_future(init_urls(start_url,True))loop.run_until_complete(future_image_list)tasks=[]for url in future_image_list.result():future = asyncio.ensure_future(init_urls(url,False))tasks.append(future)loop.run_until_complete(asyncio.wait(tasks))loop.close()
爬取网址是百度图片搜索某某人的大头照
爬取图片使用的是协程,在python3.4版本后引入,与以往的requests不同,它采用的是高并发的模式,由于GIL锁的问题,协程变得很难以理解,所以async 是不可以和requests联用的(因为requests是单线程),但他可以和 aiohttp联用,效果与Scrapy框架大同,运行时间可以大幅度的减小。举个例子
假设访问一个网页需要2秒 ,那么request访问100个页面需要 200秒左右,而使用协程 只需要2.004秒左右,假设访问10000次 需要2.2108秒,此结果由测试得知。
所以,协程的重要性就很明了了。
在程序中,把采集的照片存入到Primitive_face文件夹中,所以step1到此完成。
爬取图片后的结果
Step2 --> 识别人脸信息
什么是识别人脸信息呢,也就是说,我们要将一张图片里有没有人脸识别出来,如果能识别到人脸,那么就扣出人脸这一块,其他的舍去,这样做的目的是去除无用的照片,同时在有人脸的图片上除去不相关的元素,能大大提高预测的准确率
python的opencv-python库上有CascadeClassifier 也就是级联分类器 简而言之是滑动窗口机制+级联分类器的方式,很多时候都被这种高深的名字给吓到,但是我们不必去探究他的实现原理,底层代码,这太难了,简单的,我们知道他如何使用就行了。
关于opencv_python 库 只需要简单的 pip install opencv-python就行了 但是导入的时候他的名字叫cv2。
import cv2import numpy as npimport osface_extraction_train_path = r"C:\Users\lvhaitao\Desktop\face_extraction_train"#指定裁剪后图片的存放地址size_m = 300size_n = 300target=[]def detect_face(img):gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)face_cascade = cv2.CascadeClassifier(r"C:\Users\lvhaitao\Anaconda3\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml")faces = face_cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5)if (len(faces) == 0):return None, None(x, y, w, h) = faces[0]return gray[y:y + w, x:x + h], faces[0]def prepare_training_data(data_folder_path):dirs = os.listdir(data_folder_path)faces = []for dir_name in dirs:dir_name_path = data_folder_path + '/' + dir_nameimages = os.listdir(dir_name_path)s=0for image_name in images:s+=1image_path = dir_name_path + '/' + image_nameimage = cv2.imread(image_path)face, rect = detect_face(image)if face is not None:res=cv2.resize(face,(64,64),interpolation=cv2.INTER_CUBIC)faces.append(res)face_path = face_extraction_train_path + '/' + dir_nameif not os.path.exists(face_path):os.mkdir(face_path)image_face_path = face_path + '/' + str(s) + '.jpg'cv2.imwrite(image_face_path, res)target.append(dir_name)return faces,targetfaces,target=prepare_training_data(r"C:\Users\lvhaitao\Desktop\Primitive_face")
别看代码很长 其实关键代码就是 detect_face 这个方法里的代码
face_cascade = cv2.CascadeClassifier(r"C:\Users\lvhaitao\Anaconda3\Lib\site-packages\cv2\data\haarcascade_frontalface_alt2.xml")这行代码就是创建了我们的级联分类器,只需要调用他的xml文件就行,安装过cv2后,他的级联分类器就在我们的cv2包中的data目录下面,如果你尝试了你会看到很多的级联分类器,有眼睛的,脸的,鼻子,嘴巴,以及其他的等等,选你自己需要的就行。
所以很简单的 如果有脸 我们就返回识别出来的脸的那一块区域,如果没有我们就返回None
prepare_training_data这个方法虽然代码很长,其实它实际上就是将识别出来的脸存放在不同的文件夹里而已,也就是创建文件夹,创建子文件夹 ,然后将图片写进去,就这么简单的,没有多余的内容,由于图片大小不一,所以统一将大小都变成了64x64像素图片。
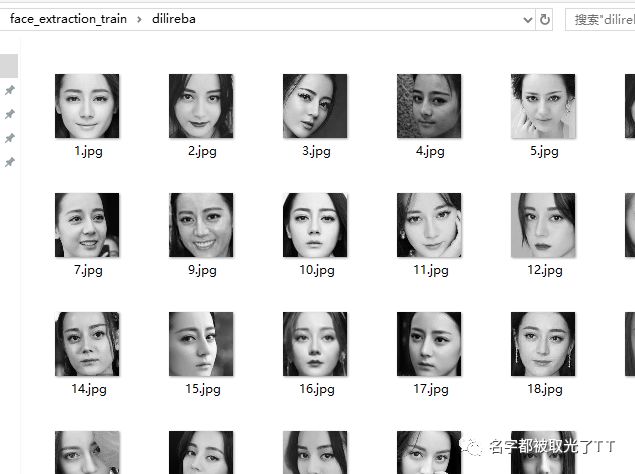
迪丽热巴识别图
彭于晏识别图
通过简单的代码我们将Primitive_face原始人脸图中的人脸进行提取,存放到face_extraction_train文件夹中
step2到此结束
Step3 --> 数据处理
其实从上step2的代码中,我们将提取出的人脸信息进行了收集,也就是faces列表 他存放的是二维矩阵 也就是 64*64 维的矩阵 ,那么target就是对应的标签,也就是某某某,那么为什么要做数据处理呢?
第一步 将64*64 转换为(1,4096) 的形状 ,为什么这么做呢,因为传入训练的时候需要这样的规定
代码很简单 也就是将第一个维度 × 第二个维度
Step4 -->训练测试集分离
为什么要有训练集和测试集?很简单,我们训练一个模型后,当然要用测试集去测试他的效果好不好,准确率高不高,其实判断模型的好坏远不止说说的这么简单,由于知识有限,这里简单的提一提。
值得一提的是sklearn中专门封装了训练测试集的分离
from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,target,random_state=66,test_size=0.2)
其中X是我们在step3中处理的faces矩阵,将他转换为numpy的array数组,sklearn大大支持numpy数组的传入。random_state是随机种子,test_size是测试集占的比例,由于爬取的图片不多,一共就30张,所以训练集占的比例多一点,由于是网络图片,你给的训练图片越多,实际上预测的准确率要越好,当然,如果你的训练集样本足够多,可以调大测试集所占的比例。
这里还要说的是 我们还要对 X_train 和X_test 的数据进行处理 也就是数据的归一化
为什么要将数据进行归一化呢,深奥的来讲,就是让算法寻找最优解变得容易,更容易正确的收敛得到最优解,通俗的来说就是消除量纲,把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。由于像素是有边界的,所以运用了MinMax这种归一化的方式。
from sklearn.preprocessing import MinMaxScalerminmaxScaler = MinMaxScaler()minmaxScaler.fit(X_train)X_tandart_train = minmaxScaler.transform(X_train)X_tandart_test = minmaxScaler.transform(X_test)
从sklearn中导入我们的MinMaxScaler的处理器
同样的我们利用X_train进行标准来训练,将处理后的数据保存成X_tandart_train,X_tandart_test
至此 Step4结束
Step5 -->模型训练
其实在模型训练前,还有一个很重要的话题就是模型的选择,在使用SVM前,我尝试使用了KNN模型,逻辑回归模型,但KNN的效果并不理想,逻辑回归解决的是二分类问题,但也可以解决多分类,但这样就增加了难度,所以SVM就成了比较好的选择。
其实对于模型来说,要理解他的模型机制,需要很强大的数学功底,其实归根结底来说,模型就是一个算法,是推导出来的,算法也就是数学的式子,所以数学不好的人,根本看不懂,也很难理解他的含义,要想理解,数学基础功底是必须要很强大的。
这里选择了SVM,并不是说SVM就是最好的选择,当然还有卷积神经网络等等... 由于只是一时兴起,所以就很简单的实现了一下。
from sklearn.svm import LinearSVCsvc = LinearSVC(C=1e10)svc.fit(X_tandart_train,y_train)
创建LinearSVC模型其中有一个超参数C ,他的意思是容错率,越高他的容错率越低
然后使用我们的训练集进行训练
训练完后 我们用测试集去看看他的效果,别急,在此之前,我们看看他的训练集准确率
模型里sklearn专门封装了一个score函数
svc.score(X_tandart_train,y_train)我们将训练的数据和训练的结果传入来看看他的准确率
结果为1.0 也就是百分百准确 , 准确率还挺高,但这并不能代表我们的模型就是很好了,还要看我们的测试集,也就是未被模型接触过的照片,看看通过这些未知的照片,他的识别率有多好
svc.score(X_tandart_test,y_test)他的识别率为:0.8666666667 也就是87%
如果我们将 拆分训练测试集的test_size 调整为0.1 那么他的测试集识别率也为 1 ,也就是百分之百,所以这里猜测一个结论,也就是喂给模型的训练集照片越多,模型的泛化能力可能也就越好,就是说 在我这里用来训练的有56张照片,其实是很少的,至少一个人60张,预测的照片只有15张,但是这边的预测准确率也还是可观的。
所以,数据量要大,很关键。
至此 Step5也就结束了。 我们来看看到底是谁识别错了。
绘制代码:
name_dict = {'dilireba':'迪丽热巴',"chenguanxi":'陈冠希',"pengyuyan":'彭于晏'}import matplotlib as mplimport matplotlib.pyplot as pltmpl.rcParams["font.sans-serif"] = ["SimHei"]mpl.rcParams["axes.unicode_minus"] = Falsefig, ax = plt.subplots(3, 5)for i, axi in enumerate(ax.flat):axi.imshow(X_test[i].reshape(64, 64), cmap='bone')axi.set(xticks=[], yticks=[])axi.set_xlabel(name_dict[y_predict[i]],size=15,color='black' if y_test[i] == y_predict[i] else 'red')fig.suptitle('预测错误的名字被红色标注', size=14)plt.show()
绘制结果:
造成准确率低的原因一大部分可以是因为训练的样本数量太少,其实,通过特征提取后,他们的样子其实差不多,都有眼睛嘴巴鼻子等,当然,还有很多的超参数,以及各种方法,例如PCA主成分分析法,多项式回归等各种处理手段,由于水平有限,不能很好的运用在这里面,不然准确率一定会大大的提高,如果你想,也可以打开摄像头的方式进行自己的人脸输入,那样你的预测准确率会大大提高,只不过这里就不进行。
这样一个人脸识别就做好了,你可以传入一张你自己的照片,来看看他是谁,如果你测试集的样本数足够多,我想他会给你很准确的算出你是谁。
值得一提的是,这样的准确率并不能代表他的准确率,因为不同的人脸,会出现不同的效果,关于这方面的知识,以及判断模型的好坏,如何调整参数使得模型更好,内涵的知识实在太过丰富,由于水平有限,目前只能做到如此了。
现在已经是凌晨2点了,搞点夜点心778,搞点夜点心778,嫩啊,宣盘封顶
以上是关于基于支持向量机(SVM)进行人脸识别的主要内容,如果未能解决你的问题,请参考以下文章