支持向量机+sklearn绘制超平面
Posted 江大白玩AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了支持向量机+sklearn绘制超平面相关的知识,希望对你有一定的参考价值。
1.快速了解SVM
2.SVM定义与公式建立
3. 核函数
3.1 常用的核函数(kernel functions)
4.SVM 应用实例
1.快速了解SVM
支持向量机(support vector machines,SVM)是一种二类分类模型。它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;而且SVM还支持核技巧,能够对非线形的数据进行分类,其实就是将非线形问题变换为线性问题,通过解变换后的线性问题来得到原来非线形问题的解。
举个例子来说明支持向量机是来干什么的吧!
将实例的特征向量(以二维为例)映射为空间中的一些点,就是如下图的圆心点和‘x’,它们属于不同的两类。那么SVM的目的就是想要画出一条线,以“最好地”区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
从图中我们可以看出能够画出多条线对样本点进行区分,区别就在于效果好不好。比如粉色线就不好,绿色还凑合,黑色的线看起来就比较好。我们希望找到这条效果最好的线叫作划分超平面。
看官老爷们可能会问画这条线的标准是什么?
SVM将会寻找可以区分两个类别并且能够使间隔(margin)最大的超平面,即划分超平面。
注:间隔就是某一条线距离它两侧最近的点的距离之和。
2.SVM定义与公式建立
在样本空间中,划分超平面可以定义为:
+ b = 0 ( 2.1)
其中 = ( )为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。很明显划分超平面是可被法向量 和位移 b 确定。
将超平面记为( , b),样本空间中任意点 到超平面( , b)的距离可写为:
= ( 2.2)
假设超平面( , b)能够将训练样本正确分类,即对于任何样本,若 = +1,则有 ,若 = -1,则有 . 令
;
; ( 2.3 )
如下图所示,距离超平面最近的几个样本点使得公式(2.3)的等号成立,这个个样本点被称为 “支持向量”(support vector),两个异类支持向量到超平面的距离之和为
( 2.4 )
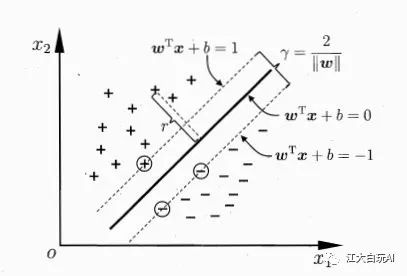
第一小节我们讲到 SVM 就是要找到区分两个类别并使两个异类支持向量到超平面的距离之和最大,也就是要找到满足式(2.3)中约束的参数 和 b ,使得 最大,即
. ( 2.5 )
s.t.
为了使 最大,这等价于最小化 ,于是式(2.5)可以重写为
. ( 2.6 )
s.t.
这就是支持向量机(Support Vector Machine,SVM)的基本型.
3. 核函数
支持向量机通过某非线性变换 ∂( x ),将输入空间映射到高维特征空间。特征空间的维数可能非常高。如果支持向量机的求解只用到内积运算,而在低维输入空间又存在某个函数 ,它恰好等于在高维空间中这个内积,K( x, x′) =<φ( x) ⋅φ( x′) >。那么支持向量机就不用计算复杂的非线性变换,而由这个函数 K(x, x′) 直接得到非线性变换的内积,使大大简化了计算。这样的函数 K(x, x′) 称为核函数。
3.1 常用的核函数(kernel functions)
线性核
多项式核
d ≥ 1为多项式的次数
高斯核
> 0为高斯核的带宽(width)
拉普拉斯核
> 0
Sigmoid 核
tanh为双曲线正切函数,
核函数那么多,那么一般如何选择?
-
尝试不同的 kernel ,根据结果准确度而定,尝试不同的 kernel。
-
根据先验知识,比如图像分类,通常用RBF(高斯核),文字不使用RBF。
举个小例子来说明核函数吧!
假设两个向量 ,
可以定义方程(Grim矩阵):
设函数为 $K(x,y)=(
假设
如果不使用核函数,直接求内积:
$
使用核函数:
两种方法都可以得到同样的结果,但是使用kernel方法计算容易很多,在样本维度很高时这种方法会更加显示其优势。
4.SVM 应用实例
由于 SVM 算法本身的实现较为复杂,所以这里就不给出如何实现SVM的代码,采用 sklearn库来帮助我们学习SVM 的应用例子。
这里对sklearn画出超平面步骤做个说明
1)首先获取权重矩阵
weight = model.coef_[0]
打印结果如下
有两个值,分别是 ,sklearn中对超平面的表示并不是 y = kx +b 这样的,而是把 x作为第一个特征 x0, y作为另一个特征x1,表示为:
这样的好处在于如果有多组特征,方便扩展。在预测时,将待测的(x0,x1)带入上式,根据大于或者小于0即可判断类别。
2)bias的值可以使用model.intercept_即可获取
为了方便画图,我们可以通过移项转换为我们熟悉的斜截式:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.svm import SVC
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0, 1, -1]])
# 将label==0的实例赋值为-1
for i in range(len(data)):
if data[i, -1] == 0:
data[i, -1] = -1
return data[:, :-1], data[:, -1]
def SVM():
x, y = create_data()
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
model = SVC(kernel="linear")
model.fit(x_train, y_train)
precise = model.score(x_test, y_test)
print(precise)
# 画出散点图
plt.scatter(x[:50, 0], x[:50, 1], label='0')
plt.scatter(x[50:100, 0], x[50:100, 1], label='1')
# 查看权重矩阵
weight = model.coef_[0]
#print(model.coef_)
# 取出截距
bias = model.intercept_[0]
k = -weight[0] / weight[1]
b = -bias / weight[1]
# 获取支持向量
support_vector = model.support_vectors_
# 画出支持向量
for i in support_vector:
plt.scatter(i[0], i[1], marker=',', c='b')
# 画出超平面
xx = np.linspace(4, 7, 10)
yy = k * xx + b
plt.plot(xx, yy)
plt.legend()
plt.show()
if __name__ == '__main__':
SVM()
sklearn.svm.SVC
(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
参数:
C:C-SVC的惩罚参数C?默认值是1.0
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
– 线性:u'v
– 多项式:(gammau'v + coef0)^degree
– RBF函数:exp(-gamma|u-v|^2)
– sigmoid:tanh(gammau'v + coef0)
degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
probability :是否采用概率估计?.默认为False
shrinking :是否采用shrinking heuristic方法,默认为true
tol :停止训练的误差值大小,默认为1e-3
cache_size :核函数cache缓存大小,默认为200
class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
verbose :允许冗余输出?
max_iter :最大迭代次数。-1为无限制。
decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
random_state :数据洗牌时的种子值,int值
主要调节的参数有:C、kernel、degree、gamma、coef0。
以上是关于支持向量机+sklearn绘制超平面的主要内容,如果未能解决你的问题,请参考以下文章
详解支持向量机-支持向量机分类器原理菜菜的sklearn课堂笔记