图解希尔排序
Posted 算法与数据结构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解希尔排序相关的知识,希望对你有一定的参考价值。
希尔排序(ShellSort)是以它的发明者Donald Shell名字命名的,希尔排序是插入排序的改进版,实现简单,对于中等规模数据的性能表现还不错。
排序思想
前情回顾:(对插入排序不熟悉的强烈建议先阅读此文)
一天,一尘拿着扑克自己在那玩,刚被师傅看见了

上次的插入排序掌握了没
恩恩,基本掌握了

 一尘
一尘
 慧能
慧能
那你说说插入排序什么时候使用高效?
小规模数据数据或者基本有序或者时十分高效。
一尘
数据有序程度越高,越高效(移动少)
慧能
恩恩,不错,基本有序或规模较小都不常见,你能不能改进一下插入排序,使得它对较大规模并且无序的数据也非常有效率
这个......,弟子不才
一尘
慧能
其实希尔排序就可以实现这个效果
希尔排序是怎么做的呢?
一尘
慧能
它的思路是这样的:
首先它把较大的数据集合分割成若干个小组(逻辑上分组),然后对每一个小组分别进行插入排序,此时,插入排序所作用的数据量比较小(每一个小组),插入的效率比较高
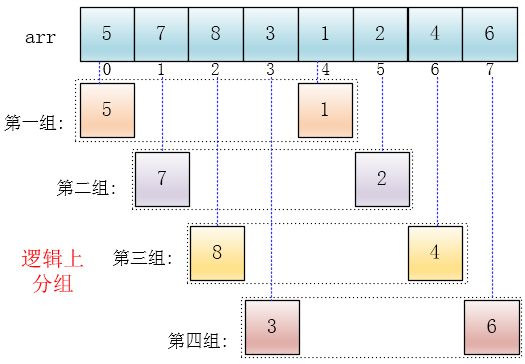
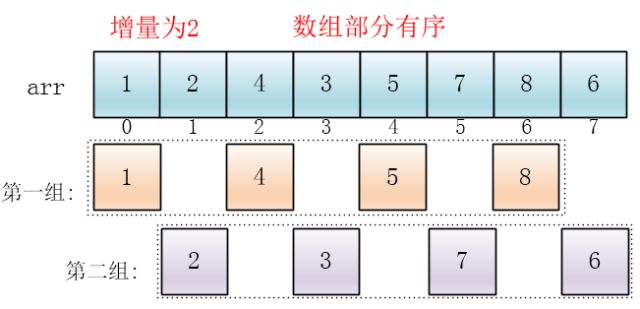
下面有颜色的是逻辑上的分组,并没有实际地进行分组操作,在数组中的位置还是原来的样子,只是将他们看成这么几个分组(逻辑上分组)
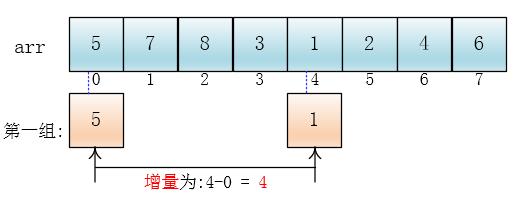
可以看出,他是按下标相隔距离为4分的组,也就是说把下标相差4的分到一组,比如这个例子中a[0]与a[4]是一组、a[1]与a[5]是一组...,这里的差值(距离)被称为增量
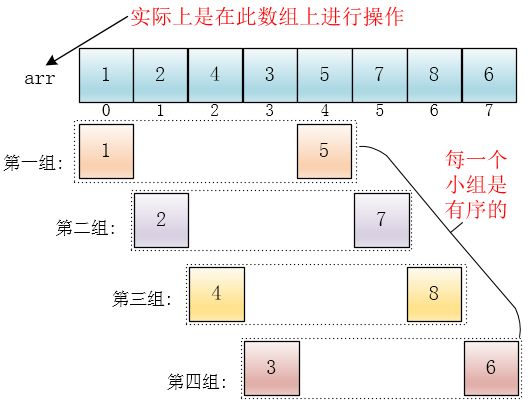
每个分组进行插入排序后,各个分组就变成了有序的了(整体不一定有序)
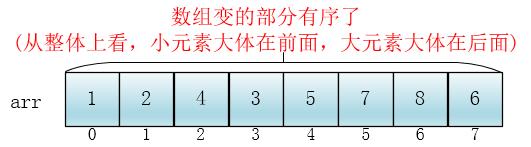
此时,整个数组变的部分有序了(有序程度可能不是很高)
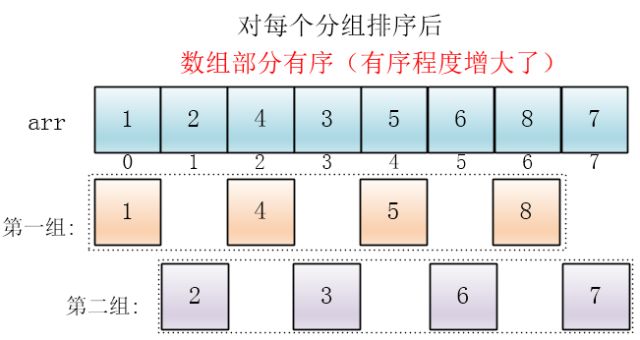
然后缩小增量为上个增量的一半:2,继续划分分组,此时,每个分组元素个数多了,但是,数组变的部分有序了,插入排序效率同样比较高
同理对每个分组进行排序(插入排序),使其每个分组各自有序
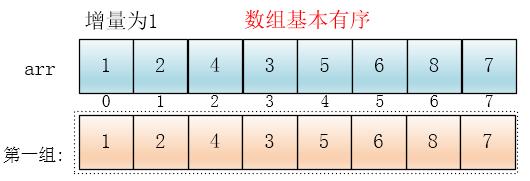
最后设置增量为上一个增量的一半:1,则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高
同理,对这仅有的一组数据进行排序,排序完成
希尔排序真厉害啊,同时构造出两个特殊条件以达到高效插入
一尘
慧能
恩恩,这就是希尔排序的精华所在
排序代码
慧能
既然知道了思想,那你写一写代码吧
对于已经熟悉插入排序的一尘来说这并不是什么难事,很快,一尘写出了希尔排序的代码

对各个组进行插入的时候并不是先对一个组进行排序完再对另一个组进行排序,而是轮流对每个组进行插入排序
一尘
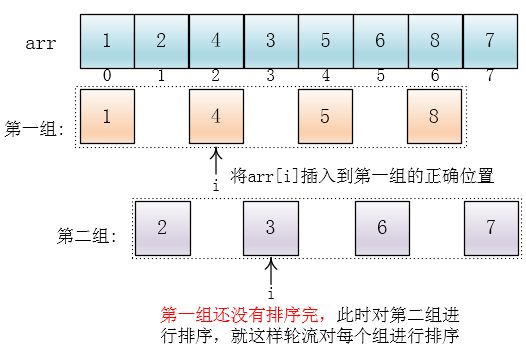
随后一尘写出了插入arr[i]到所在组正确位置的代码(insertI)
insertI和里的插入代码几乎完全一样
 慧能
慧能
恩恩,不错,插入排序会,这个代码就简单许多,只是在外层多加了一个控制增量(gap)的循环罢了
时间复杂度
接下来又是分析时间复杂度吧,一尘心里想
慧能
这次的时间复杂度你不用分析了,你只需记住结论就行了,因为希尔排序的时间度分析极其复杂,有的增量序列的复杂度至今还没人能够证明出来
增量序列?
一尘
慧能
就是你刚才使用的增量的集合,刚才用的序列就是{1, 2, 4, ...},每次都通过减半来得到新的增量
希尔排序的复杂度和增量序列是相关的
{1,2,4,8,...}这种序列并不是很好的增量序列,使用这个增量序列的时间复杂度(最坏情形)是O(n^2)
Hibbard提出了另一个增量序列{1,3,7,...,2^k-1},这种序列的时间复杂度(最坏情形)为O(n^1.5)
Sedgewick提出了几种增量序列,其最坏情形运行时间为O(n^1.3),其中最好的一个序列是{1,5,19,41,109,...}
对不同增量的复杂度感性趣可以参考《数据结构与算法分析》一书或其他相关论文
想不到算法简单排序时间复杂度却如此困难
一尘
慧能
是啊,有的东西看起来简单,其实里面却很复杂
关于时间复杂度可看:
稳定性
慧能
最后说一下稳定性吧
不是稳定的,虽然插入排序是稳定的,但是希尔排序在插入的时候是跳跃性插入的,有可能破坏稳定性
一尘
关于稳定性可看:
说完,一尘继续玩起了扑克
-END-
●编号638,输入编号直达本文
●输入m获取文章目录
Java编程
更多推荐《》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、ios开发、C/C++、.NET、Linux、数据库、运维等。
以上是关于图解希尔排序的主要内容,如果未能解决你的问题,请参考以下文章