人人都会数据采集- Scrapy 爬虫框架入门 | 岂安低调分享
Posted bigsec岂安科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人人都会数据采集- Scrapy 爬虫框架入门 | 岂安低调分享相关的知识,希望对你有一定的参考价值。
干货
观点
案例
资讯
我们
Hekko 岂安科技研发工程师
喜欢(擅长)瞎折腾
在这个言必称“大数据”“人工智能”的时代,数据分析与挖掘逐渐成为互联网从业者必备的技能。本文介绍了利用轻量级爬虫框架 scrapy 来进行数据采集的基本方法。
一、scrapy简介
scrapy 是一套用 Python 编写的异步爬虫框架,基于 Twisted 实现,运行于 Linux/Windows/MacOS 等多种环境,具有速度快、扩展性强、使用简便等特点。即便是新手也能迅速掌握并编写出所需要的爬虫程序。scrapy 可以在本地运行,也能部署到云端(scrapyd)实现真正的生产级数据采集系统。
我们通过一个实例来学习如何利用 scrapy 从网络上采集数据。“博客园”是一个技术类的综合资讯网站,本次我们的任务是采集该网站 mysql 类别 https://www.cnblogs.com/cate/mysql/ 下所有文章的标题、摘要、发布日期、阅读数量,共4个字段。最终的成果是一个包含了所有4个字段的文本文件。如图所示:
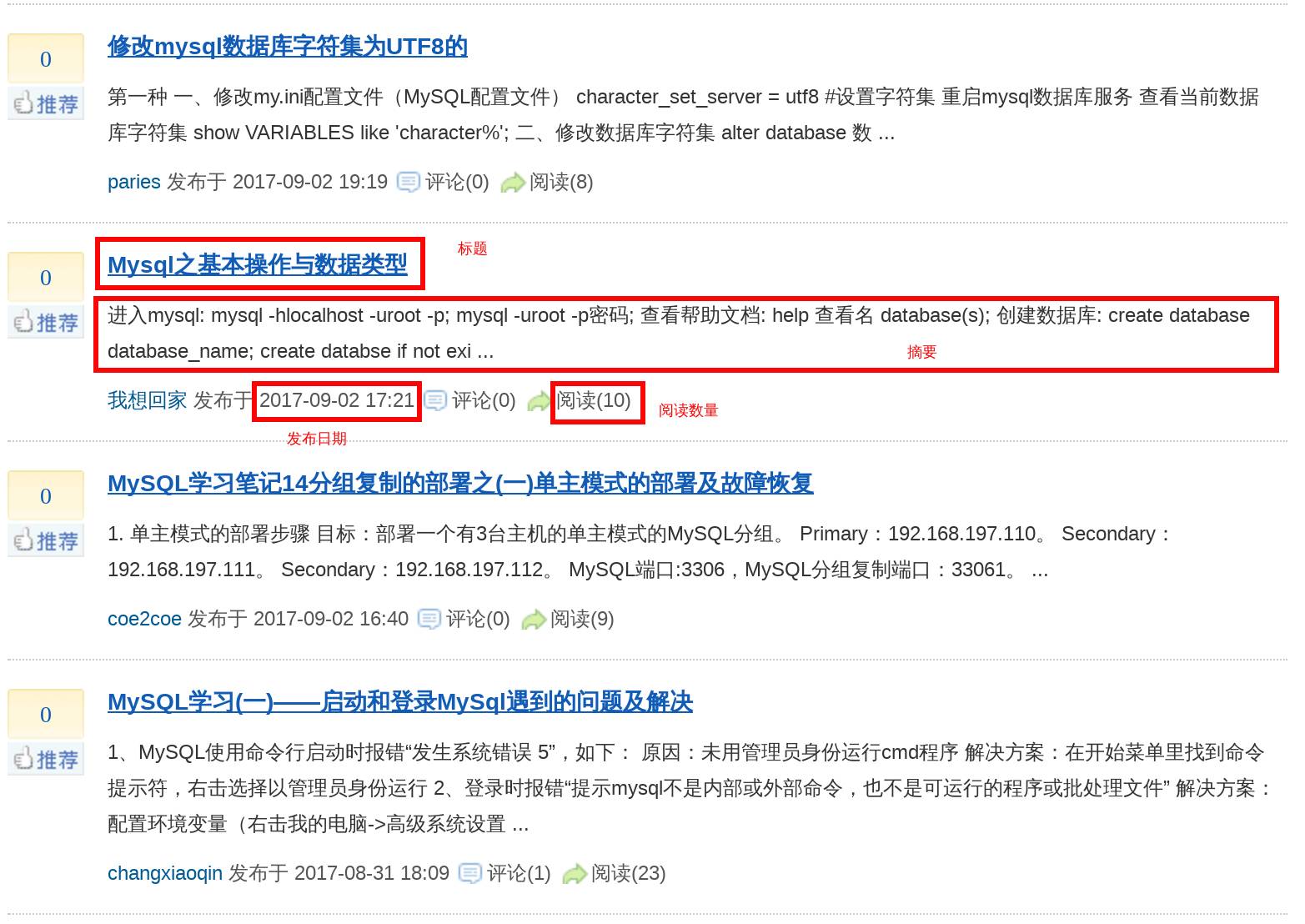
最终拿到的数据如下所示,每条记录有四行,分别是标题、阅读数量、发布时间、文章摘要:

二、安装scrapy
下面来看看怎么安装 scrapy。首先你的系统里必须得有 Python 和 pip,本文以最常见的 Python2.7.5 版本为例。pip 是 Python 的包管理工具,一般来说 Linux 系统中都会默认安装。在命令行下输入如下命令并执行:
sudo pip install scrapy -i http://pypi.douban.com/simple –trusted-host=pypi.douban.com
pip 会从豆瓣网的软件源下载并安装 scrapy,所有依赖的包都会被自动下载安装。”sudo”的意思是以超级用户的权限执行这条命令。所有的进度条都走完之后,如果提示类似”Successfully installed Twisted, scrapy … “,则说明安装成功。
三、scrapy交互环境
scrapy 同时也提供了一个可交互运行的 Shell,能够供我们方便地测试解析规则。scrapy 安装成功之后,在命令行输入 scrapy shell 即可启动 scrapy 的交互环境。scrapy shell 的提示符是三个大于号>>>,表示可以接收命令了。我们先用 fetch() 方法来获取首页内容:
>>> fetch( “https://www.cnblogs.com/cate/mysql/” )
如果屏幕上有如下输出,则说明网页内容已经获取到了。
2017-09-04 07:46:55 [scrapy.core.engine] INFO: Spider opened
2017-09-04 07:46:55 [scrapy.core.engine] DEBUG: Crawled (200)
<GET https://www.cnblogs.com/cate/mysql/> (referer: None)
获取到的响应会保存在 response 对象中。该对象的 status 属性表示 HTTP 响应状态,正常情况为 200。
>>> print response.status
200
text 属性表示返回的内容数据,从这些数据中可以解析出需要的内容。
>>> print response.text
u'<!DOCTYPE html>\r\n<html lang=”zh-cn”>\r\n<head>\r\n
<meta charset=”utf-8″ />\r\n
<meta name=”viewport” content=”width=device-width, initial-scale=1″ />\r\n
<meta name=”referrer” content=”always” />\r\n
<title>MySQL – \u7f51\u7ad9\u5206\u7c7b – \u535a\u5ba2\u56ed</title>\r\n
<link rel=”shortcut icon” href=”//common.cnblogs.com/favicon.ico” type=”image/x-icon” />’
可以看到是一堆很乱的 HTML 代码,没法直观地找到我们需要的数据。这个时候我们可以通过浏览器的“开发者工具”来获取指定数据的 DOM 路径。用浏览器打开网页 https://www.cnblogs.com/cate/mysql/ 之后,按下 F12 键即可启动开发者工具,并迅速定位指定的内容。
可以看到我们需要的4个字段都在 / body / div(id=”wrapper”) / div(id=”main”) / div(id=”post_list”) / div(class=”post_item”) / div(class=”post_item_body”) / 下,每一个”post_item_body”都包含一篇文章的标题、摘要、发布日期、阅读数量。我们先获取所有的”post_item_body”,然后再从里面分别解析出每篇文章的4个字段。
>>> post_item_body = response.xpath( “//div[@id=’wrapper’]/div[@id=’main’]/div[@id=’post_list’]/div[@class=’post_item’]/div[@class=’post_item_body’]” )
>>> len( post_item_body )
20
response 的 xpath 方法能够利用 xpath 解析器获取 DOM 数据,xpath 的语法请参考官网文档。可以看到我们拿到了首页所有 20 篇文章的 post_item_body。那么如何将每篇文章的这4个字段提取出来呢?
我们以第一篇文章为例。先取第一个 post_item_body:
>>> first_article = post_item_body[ 0 ]
标题在 post_item_body 节点下的 h3 / a 中,xpath 方法中text()的作用是取当前节点的文字,extract_first() 和 strip() 则是将 xpath 表达式中的节点提取出来并过滤掉前后的空格和回车符:
>>> article_title = first_article.xpath( “h3/a/text()” ).extract_first().strip()
>>> print article_title
Mysql之表的操作与索引操作
然后用类似的方式提取出文章摘要:
>>> article_summary = first_article.xpath( “p[@class=’post_item_summary’]/text()” ).extract_first().strip()
>>> print article_summary
表的操作: 1.表的创建: create table if not exists table_name(字段定义); 例子: create table if not exists user(id int auto_increment, uname varchar(20), address varch …
在提取 post_item_foot 的时候,发现提取出了两组内容,第一组是空内容,第二组才是“发布于 XXX”的文字。我们将第二组内容提取出来,并过滤掉“发布于”三个字:
>>> post_date = first_article.xpath( “div[@class=’post_item_foot’]/text()” ).extract()[ 1 ].split( “发布于” )[ 1 ].strip()
>>> print post_date
2017-09-03 18:13
最后将阅读数量提取出来:
>>> article_view = first_article.xpath( “div[@class=’post_item_foot’]/span[@class=’article_view’]/a/text()” ).extract_first()
>>> print article_view
阅读(6)
很多人觉得 xpath 方法里的规则太过复杂。其实只要了解一点 HTML 文件的 DOM 结构,掌握 xpath 的提取规则还是比较轻松容易的。好在 scrapy shell 允许我们反复对 DOM 文件进行尝试解析。实验成功的 xpath 表达式就可以直接用在项目里了。
四、创建scrapy项目
scrapy shell 仅仅适用于测试目标网站是否可以正常采集以及采集之后如何解析,真正做项目的时候还需要从头建立一个 scrapy 项目。 输入以下命令退出 scrapy shell 并返回 Linux 命令行:
>>> exit()
假设我们的项目名称叫 cnblogs_scrapy ,则可通过下面的命令来创建一个 scrapy 项目:
scrapy startproject cnblogs_scrapy
会自动生成如下结构的目录与文件:
|– cnblogs_scrapy
| |– __init__.py
| |– items.py
| |– middlewares.py
| |– pipelines.py
| |– settings.py
| `– spiders
| `– __init__.py
`– scrapy.cfg
五、解析与存储
我们需要改三个地方:
内容如下:
# -*- coding: utf-8 -*-
import scrapy
import sys
reload( sys )
sys.setdefaultencoding( "utf8" )
class CnblogsMySQL(scrapy.Spider):
# 爬虫的名字,必须有这个变量
name = 'cnblogs_mysql'
page_index = 1
start_urls = [
'https://www.cnblogs.com/cate/mysql/' + str( page_index ),
]
def parse(self, response):
post_items = response.xpath(
"//div[@id='wrapper']/div[@id='main']/div[@id='post_list']/div[@class='post_item']/div[@class='post_item_body']"
)
for post_item_body in post_items:
yield {
'article_title':
post_item_body.xpath( "h3/a/text()" ).extract_first().strip(),
'article_summary':
post_item_body.xpath( "p[@class='post_item_summary']/text()" ).extract_first().strip(),
'post_date':
post_item_body.xpath( "div[@class='post_item_foot']/text()" ).extract()[ 1 ].strip(),
'article_view' :
post_item_body.xpath(
"div[@class='post_item_foot']/span[@class='article_view']/a/text()"
).extract_first().strip()
}
next_page_url = None
self.page_index += 1
if self.page_index <= 20:
next_page_url = "https://www.cnblogs.com/cate/mysql/" + str( self.page_index )
else:
next_page_url = None
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url))
这个就是我们的爬虫,其中 name 和 start_urls 两个变量必须存在。parse 方法的作用是将响应内容解析为我们需要的数据。parse 中的 for 循环就是在提取每一页中的 20 篇文章。解析并提取完成后,通过 yield 将结果抛到 pipeline 进行存储。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
class CnblogsScrapyPipeline(object):
def open_spider( self, spider ):
self.fp = open( "data.list", "w" )
def close_spider( self, spider ):
self.fp.close()
def process_item(self, item, spider):
self.fp.write( item[ "article_title" ] + "\n" )
self.fp.write( item[ "article_view" ] + "\n" )
self.fp.write( item[ "post_date" ] + "\n" )
self.fp.write( item[ "article_summary" ] + "\n\n" )
return item
可以看到有三个方法。这三个方法是从基类中继承而来。open_spider/close_spider 分别在爬虫启动和结束的时候执行,一般用作初始化及收尾。process_item 会在每一次 spider 解析出数据后 yield 的时候执行,用来处理解析的结果。上面这个 pipeline 的作用是将每一条记录都存储到文件中。当然也可以通过 pipeline 将内容存储到数据库或其它地方。
注意仅仅有这个 pipeline 文件还不能工作,需要在配置文件中向 scrapy 声明 pipeline。同目录下有个 settings.py 文件,加入如下内容:
ITEM_PIPELINES = {
'cnblogs_scrapy.pipelines.CnblogsScrapyPipeline': 300,
}
后面的数字是 pipeline 的权重,如果一个爬虫有多个 pipeline,各个 pipeline 的执行顺序由这个权重来决定。
修改完成并保存之后,退到 cnblogs_scrapy 的上层目录,并输入以下命令启动爬虫:
scrapy crawl cnblogs_mysql
所有经过处理的信息都会输出到屏幕上。结束之后,当前目录中会生成名为 data.list 的文件,里面存储了本次采集的所有数据。
六、翻页
cnblogs_mysql.py 的 parse 方法中有个 next_page_url 变量,一般情况下这个变量的内容应当是当前页面的下一页 URL,该 URL 当然也可以通过解析页面来获取。获得下一页的URL之后,用 scrapy.Request 来发起新一次的请求。 简单起见本文通过直接拼接 URL 的形式来指定仅采集前 20 页的数据。
七、其它
用 scrapy 发请求之前,也可以自己构造 Request,这样就能伪装为真实访问来避免被封。一般情况下有修改 User-Agent、随机采集时间、随机代理 IP 等方法。 scrapy 项目可以直接运行,也可以部署在云端进行批量采集和监控。云端部署需要用到 scrapyd,操作起来也很简单,有需要的话可自行参考官网文档。
你会感兴趣的内容:
【热帖】
【反爬虫】
常见的反爬虫和应对方法【岂安低调分享】
【产品经理】
【反欺诈】
以上是关于人人都会数据采集- Scrapy 爬虫框架入门 | 岂安低调分享的主要内容,如果未能解决你的问题,请参考以下文章
小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础对接 Selenium 实战