豆瓣电影TOP 250爬取-->>>数据保存到MongoDB
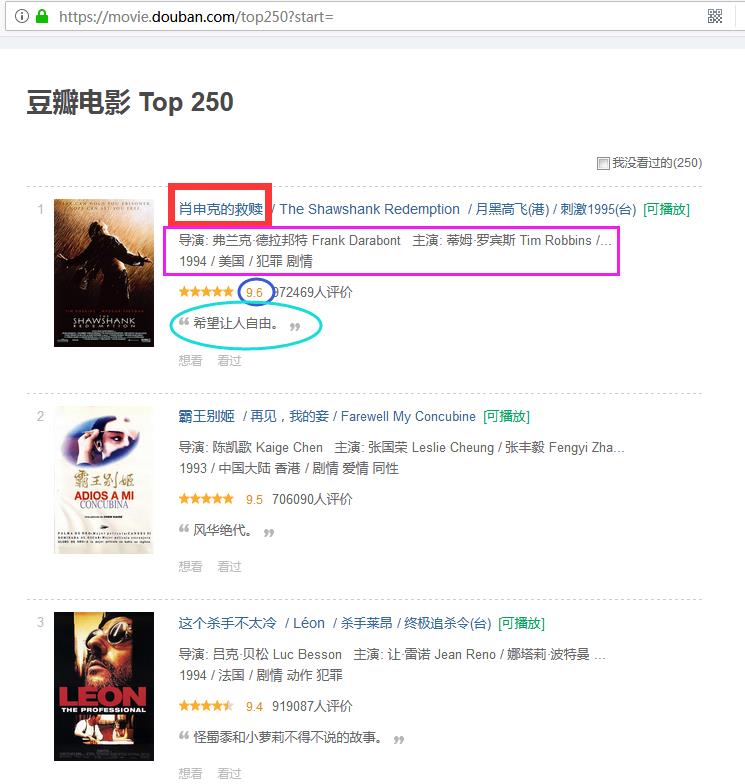
要求:
1.爬取豆瓣top 250电影名字、演员列表、评分和简介
2.设置随机UserAgent和Proxy
3.爬取到的数据保存到MongoDB数据库
items.py
# -*- coding: utf-8 -*- import scrapy class DoubanItem(scrapy.Item): # define the fields for your item here like: # 标题 title = scrapy.Field() # 信息 bd = scrapy.Field() # 评分 star = scrapy.Field() # 简介 quote = scrapy.Field()
doubanmovie.py
# -*- coding: utf-8 -*- import scrapy from douban.items import DoubanItem class DoubamovieSpider(scrapy.Spider): name = "doubanmovie" allowed_domains = ["movie.douban.com"] offset = 0 url = "https://movie.douban.com/top250?start=" start_urls = ( url+str(offset), ) def parse(self, response): item = DoubanItem() movies = response.xpath("//div[@class=\'info\']") for each in movies: # 标题 item[\'title\'] = each.xpath(".//span[@class=\'title\'][1]/text()").extract()[0] # 信息 item[\'bd\'] = each.xpath(".//div[@class=\'bd\']/p/text()").extract()[0] # 评分 item[\'star\'] = each.xpath(".//div[@class=\'star\']/span[@class=\'rating_num\']/text()").extract()[0] # 简介 quote = each.xpath(".//p[@class=\'quote\']/span/text()").extract() if len(quote) != 0: item[\'quote\'] = quote[0] yield item if self.offset < 225: self.offset += 25 yield scrapy.Request(self.url + str(self.offset), callback = self.parse)
pipelines.py
# -*- coding: utf-8 -*- import pymongo from scrapy.conf import settings class DoubanPipeline(object): def __init__(self): host = settings["MONGODB_HOST"] port = settings["MONGODB_PORT"] dbname = settings["MONGODB_DBNAME"] sheetname= settings["MONGODB_SHEETNAME"] # 创建MONGODB数据库链接 client = pymongo.MongoClient(host = host, port = port) # 指定数据库 mydb = client[dbname] # 存放数据的数据库表名 self.sheet = mydb[sheetname] def process_item(self, item, spider): data = dict(item) self.sheet.insert(data) return item
settings.py
DOWNLOAD_DELAY = 2.5 COOKIES_ENABLED = False DOWNLOADER_MIDDLEWARES = { \'douban.middlewares.RandomUserAgent\': 100, \'douban.middlewares.RandomProxy\': 200, } USER_AGENTS = [ \'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)\', \'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)\', \'Opera/9.27 (Windows NT 5.2; U; zh-cn)\', \'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)\', \'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0\', \'Mozilla/5.0 (Linux; U; Android 4.0.3; zh-cn; M032 Build/IML74K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30\', \'Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13\' ] PROXIES = [ {"ip_port" :"121.42.140.113:16816", "user_passwd" : "****"}, #{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""} #{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""} #{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""} ] ITEM_PIPELINES = { \'douban.pipelines.DoubanPipeline\': 300, } # MONGODB 主机名 MONGODB_HOST = "127.0.0.1" # MONGODB 端口号 MONGODB_PORT = 27017 # 数据库名称 MONGODB_DBNAME = "Douban" # 存放数据的表名称 MONGODB_SHEETNAME = "doubanmovies"
middlewares.py
#!/usr/bin/env python # -*- coding:utf-8 -*- import random import base64 from settings import USER_AGENTS from settings import PROXIES # 随机的User-Agent class RandomUserAgent(object): def process_request(self, request, spider): useragent = random.choice(USER_AGENTS) #print useragent request.headers.setdefault("User-Agent", useragent) class RandomProxy(object): def process_request(self, request, spider): proxy = random.choice(PROXIES) if proxy[\'user_passwd\'] is None: # 没有代理账户验证的代理使用方式 request.meta[\'proxy\'] = "http://" + proxy[\'ip_port\'] else: # 对账户密码进行base64编码转换 base64_userpasswd = base64.b64encode(proxy[\'user_passwd\']) # 对应到代理服务器的信令格式里 request.headers[\'Proxy-Authorization\'] = \'Basic \' + base64_userpasswd request.meta[\'proxy\'] = "http://" + proxy[\'ip_port\']