初探异步爬虫框架 Scrapy 及其衍生产物
Posted 研发云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初探异步爬虫框架 Scrapy 及其衍生产物相关的知识,希望对你有一定的参考价值。
对于一些规模小、爬取数据量小、
且对爬取速度不敏感的爬虫程序来说
使用 Python 的爬虫利器 requests
就能轻松对其进行管控
但如果希望爬虫能具备
爬取失败可复盘、爬取速度较高等功能
就需要 Scrapy 来帮忙了

Scrapy 是一套用 Python 所编写的非常完善的异步爬虫框架,它基于 Twisted 实现,能运行于 Linux/Windows/MacOS 等多种环境,并对爬虫进行管理、部署和监控,且具有速度快、扩展性强、使用简便等特点。Scrapy 所能实现的功能包括内存检测、对象引用查看、命令行、shell 终端,还有各种中间件和扩展等。
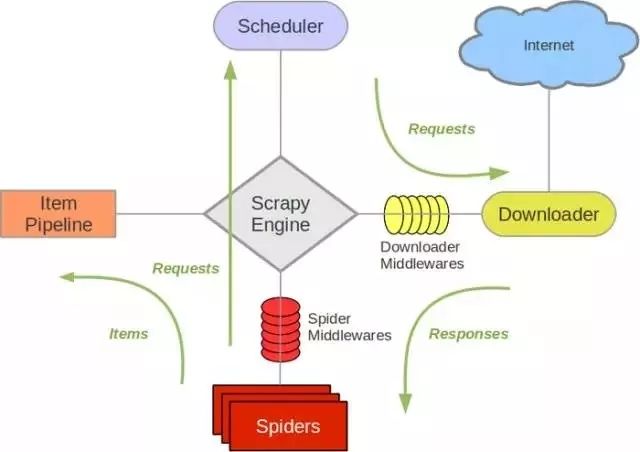
Scrapy 各架构组件的作用
Scheduler:调度器。负责接受 Engine 发送过来的 requests 请求,并将其队列化;
Item Pipeline:Item Pipeline负责处理被 Spider 提取出来的 item,如清理 html 数据、验证爬取的数据(检查 item 包含哪些字段)、查重(并丢弃)、爬取数据持久化(存入数据库、写入文件等);
Scrapy Engine:引擎是 Scrapy 的中枢。它负责控制数据流在系统所有组件中流动,并在相应动作发生时触发事件;
Downloader Middlewares:下载中间件是 Engine 和下载器的枢纽。负责处理下载器传递给 Engine 的 responses,它支持自定义扩展;
Downloader:下载器。负责下载 Engine 发送的所有 requests 请求,并将其获取到的 responses 回传给 Scrapy Engine;
Spider middlewares:Spider 中间件是 Engine 和 Spider 的连接桥梁;它支持自定义扩展来处理 Spider 的输入(responses)以及输出 item 和 requests 给 Engine ;
Spiders:负责解析 responses 并提取 Item 字段需要的数据,再将需要跟进的 URL 提交给引擎,再次进入调度器。
Scrapy 可以在本地运行,也能部署到云端
以实现真正的生产级数据采集系统
Scrapyd 就是个部署和运行 Scrapy 的应用程序
它运行在服务器端
可以非常方便地运用 JSON API来
部署爬虫、控制爬虫以及查看运行日志
Scrapyd 会以守护进程的方式存在系统中
监听爬虫地运行与请求
然后启动进程来执行爬虫程序

原生 Scrapy 的一个缺点是不支持分布式
为了克服这一局限性
它需要增加一些以 redis 为基础的组件
从而成为具备分布式爬取能力的 Scrapy_redis

Scrapy_redis 的工作原理
1、Spider 解析下载器下载下来的 response 并返回相应的 item 或 links;
2、item 或 links 经过 spider middleware 传递给 Engine;
3、Engine 将 item 交给 Item Pipeline,将 links 交给 Scrapy-redis 的专用 Scheduler;
4、在 Scrapy-redis 的专用 Scheduler 中,先将 request 对象利用 scrapy 内置的指纹函数,生成一个指纹对象;
5、如果 request 对象中的 dont_filter 参数被设置为 False,并且该 request 对象的指纹不在信息指纹的队列中,那么就把该 request 对象放到优先级的队列中,在这里Scrapy-redis 使用了 redis 数据库来存放队列。
6、从优先级队列中获取 request 对象,交给 Engine;
7、Engine 将 request 对象交给下载器下载;
8、下载器完成下载,获得 response 对象,将该对象交给 Engine;
9、Engine 将获得的 response 对象交给 Spider 进行解析。
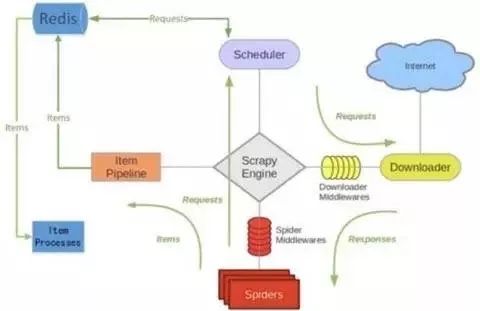
重复循环上述步骤
就实现了 Scrapy-redis 的整体框架流程
与 Scrapy 不同的地方在于
Scrapy-redis 使用了 redis 数据库
替换 Scrapy 原本使用的队列结构(deque)
因此改变了 Scrapy 的爬虫调度部分
使其让可以实现分布式运作
Scheduler 以及 Scrapy 的内置去重队列
和待抓取的 request 队列
都被换成了 redis 的集合

长|按|二|维|码|关|注
获取更多产品介绍及业界动态
 研发云微信公众号
研发云微信公众号
研·发·云
以上是关于初探异步爬虫框架 Scrapy 及其衍生产物的主要内容,如果未能解决你的问题,请参考以下文章