走近代码之Python--爬虫框架Scrapy
Posted IT女Yooo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走近代码之Python--爬虫框架Scrapy相关的知识,希望对你有一定的参考价值。
Scrapy:一个为了爬取网站数据,提取结构性数据而编写的非堵塞异步应用框架
Django Dynamic Scraper:基于 Scrapy 内核由 Django Web 框架开发的扩展
Scrapy-Redis:基于 Scrapy 内核采用 Redis 组件开发的分布式扩展
Scrapy 基于 Twisted 事件(Twisted是一款高人气的异步Python开发框架)驱动网络框架,异步非阻塞爬取信息
html, XML源数据选择及提取的内置支持
通过 feed 导出提供了多格式(JSON、CSV、XML),多存储后端(FTP、S3、本地文件系统)的内置支持
提供了media pipeline,可以自动下载爬取到的数据中的图片(或者其他资源)。
高扩展性。您可以通过使用 signals ,设计好的API(中间件, extensions, pipelines)来定制实现您的功能。
内置的中间件及扩展为下列功能提供了支持:
cookies and session 处理
HTTP 压缩,认证,缓存
user-agent模拟
robots.txt
爬取深度限制
针对多爬虫下性能评估、失败检测,提供了可扩展的状态收集工具 。
提供交互式shell终端 , 为您测试XPath表达式,编写和调试爬虫提供了极大的方便
提供 System service, 简化在生产环境的部署及运行
具有缓存的DNS解析器
在 windows 上安装会出现
Microsoft Visual C++ 14.0 is required.需要安装 Visual C++ 2015 Build Tools
在 windows 上基于 python3 的版本会出现
No module named 'win32api'需要安装
pip install pypiwin32
架构
ABOUT
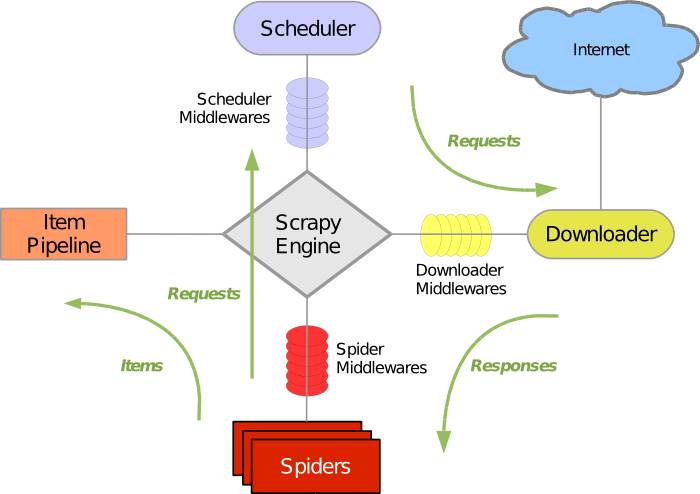
引擎(Scrapy Engine):
用来处理整个系统的数据流处理,触发事务,是整个框架的核心
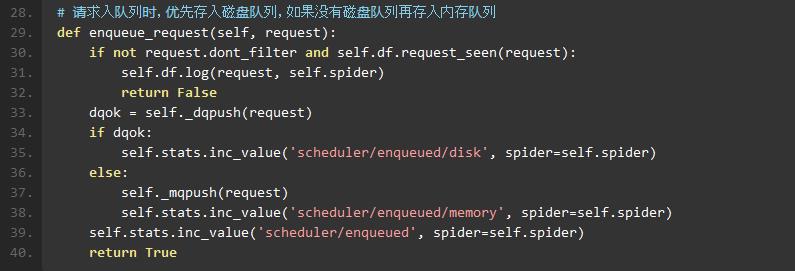
调度器(Scheduler):
用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。由它来决定下一个要抓取的请求是什么, 同时去除重复的请求
下载器(Downloader):
用于下载网页内容,并将网页内容返回给 Spiders
爬虫(Spiders):
存放业务逻辑的地方。用于从特定的网页中提取自己需要的信息(Item)。用户也可以从中提取出链接,让 Scrapy 继续抓取下一个页面
项目管道(Item Pipeline):
负责处理爬虫从网页中抽取的 Item,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息
当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据(中间件都可自定义):
下载器中间件(Downloader Middlewares): 位于 Scrapy Engine 和 Downloader 之间,主要是处理于 Scrapy Engine 和 Downloader 之间的请求及响应
爬虫中间件(Spider Middlewares): 介于于 Scrapy Engine 和 Spider 之间,主要工作是处理 Spider 的响应输入和请求输出。
调度中间件(Scheduler Middewares): 介于于 Scrapy Engine 和 Scheduler 之间,处理从 Scrapy Engine发送到 Scheduler 的请求和响应
Scrapy 的整个数据处理流程由 Scrapy Engine 控制
Scrapy Engine 从 Spiders 中获取第一个需要爬取的 URL,放入 Scheduler 中调度
Scrapy Engine 从 Scheduler 中取出一个 URL 用于接下来的抓取。Scrapy Engine 把 URL 封装成一个 Request 传给 Downloader,Downloader 把资源下载下来,并封装成 Response
Spiders 解析 Response
若是解析出实体 Item,则交给 Item Pipeline 进行进一步的处理
若是解析出的是 URL,则把 URL 交给 Scheduler 等待抓取,重复 2 ~ 5 的过程
数据存储容器 Scrapy.Item
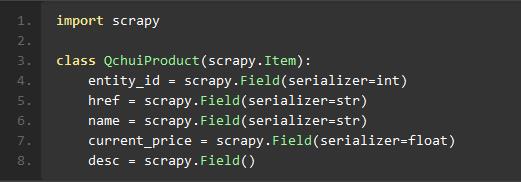
Item 提供了类字典的API,可以很方便的声明字段
Field 可以为每个字段指明任何类型的元数据,对象对接受的值没有任何限制
还可以动态创建Item类
Spider 类 scrapy.Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)
需要继承 scrapy.Spider 类,并实现 parse 方法
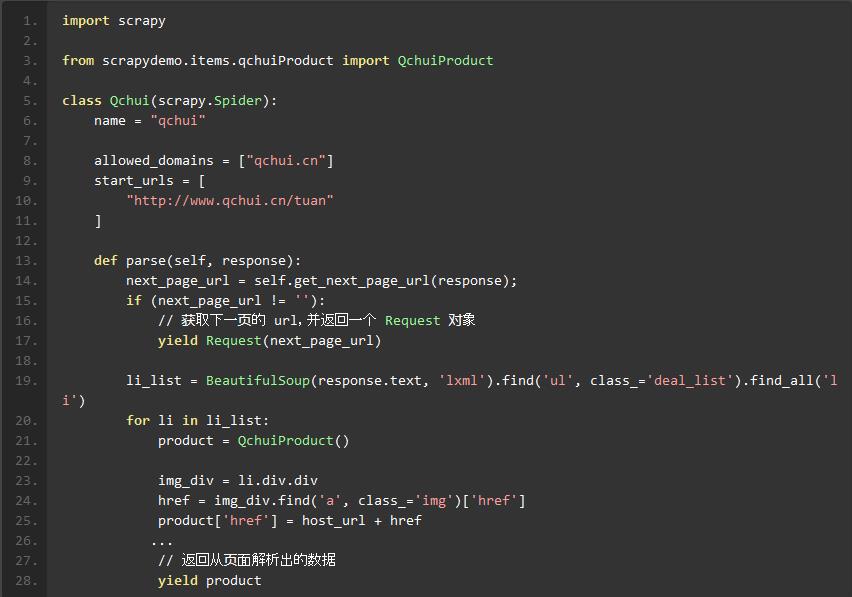
从页面提取数据
解析 xml: scrapy框架中,可以使用多种选择器来寻找信息,内置使用的是xpath,同时我们也可以使用BeautifulSoup,lxml等扩展来选择,而且框架本身还提供了一套自己的机制来帮助用户获取信息,就是Selectors。
tips:
scarpy shell [url]交互式shell终端 , 为您测试XPath表达式,编写和调试爬虫提供了极大的方便
Scrapy 核心模块解析
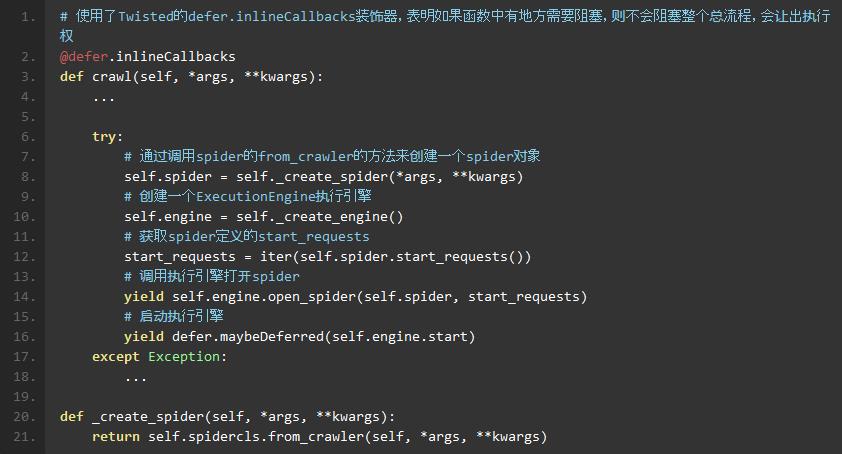
启动模块 scrapy/crawler.py 有三个类 Crawler,CrawlerRunner,CrawlerProcess
- Crawler 代表了一种爬取任务,里面使用一种 Spider
- CrawlerProcess 可以控制多个 Crawler 同时进行多种爬取任务。通过调用Crawler的crawl方法来进行爬取,并通过_active活动集合跟踪所有的Crawler
- CrawlerRunner 是 CrawlerProcess 的父类,CrawlerProcess 通过实现 start 方法来启动一个 Twisted 的 reactor,并控制 shutdown 信号,比如crtl-C。它还配置顶层的logging模块
关键代码 scrapy/crawler.py:
scrapy/spiders/_init_.py:
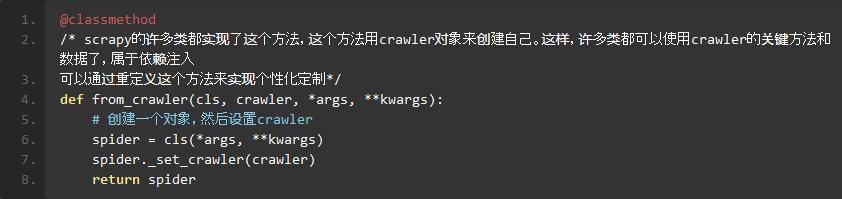
scrapy/core/engine.py
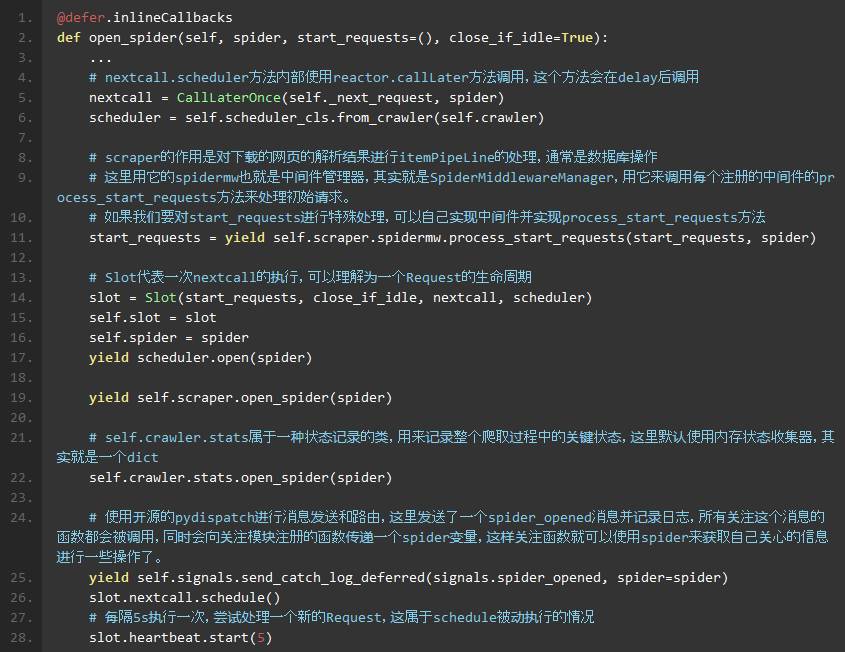
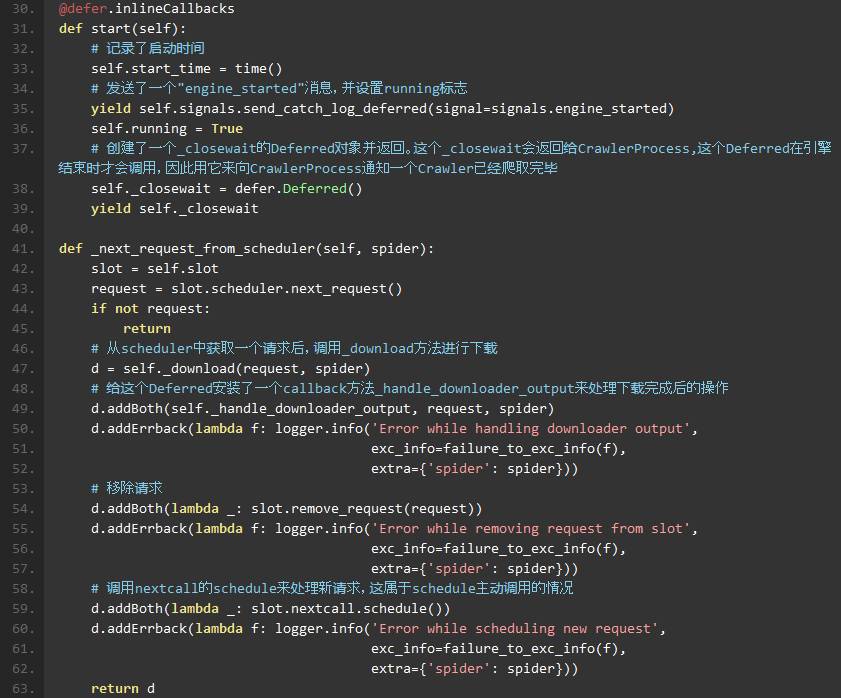
scrapy/core/scheduler.py
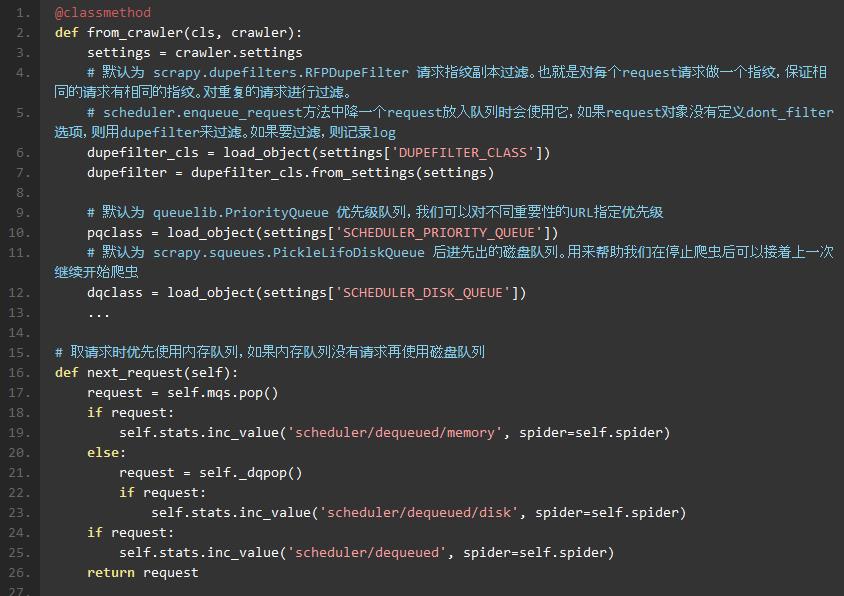
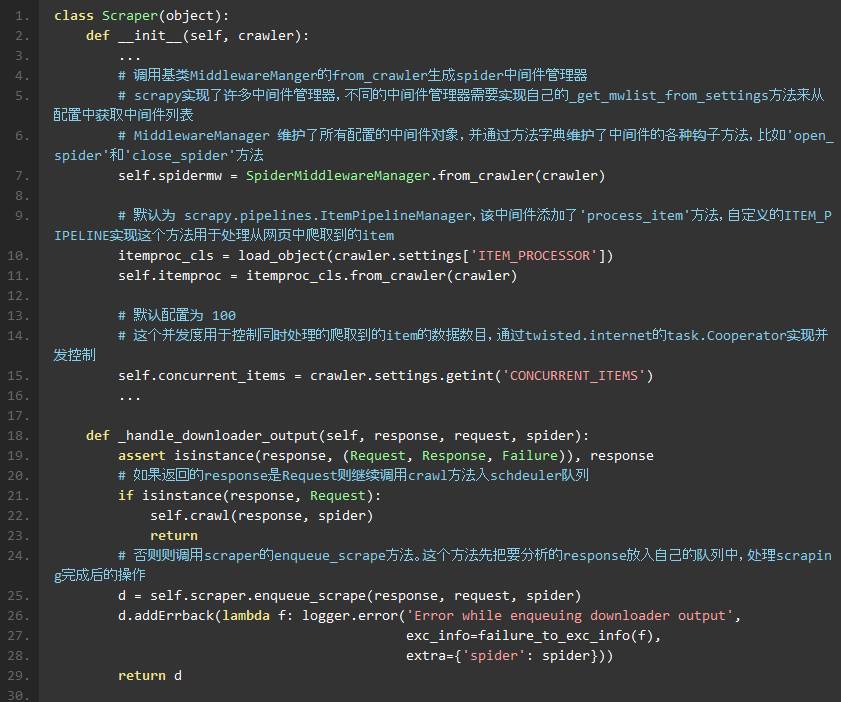
scrapy/core/scraper.py
作用是对网络蜘蛛中间件进行管理,通过中间件完成请求,响应,数据分析等工作。

设置download_delay:设置下载的等待时间,大规模集中的访问对服务器的影响最大。download_delay可以设置在settings.py中,也可以在spider中设置
禁止cookies(参考 COOKIES_ENABLED),有些站点会使用cookies来发现爬虫的轨迹。在settings.py中设置COOKIES_ENABLES=False
使用user agent池,轮流选择之一来作为user agent。需要编写自己的UserAgentMiddle中间件
使用IP池。Crawlera 第三方框架可以解决爬网站的ip限制问题,下载
scrapy-crawleraCrawlera 中间件可以轻松集成该功能分布式爬取。使用
Scrapy-Redis可以实现分布式爬取
Scrapyd 是scrapinghub官方提供的爬虫管理、部署、监控的方案之一。它使你能够通过 JSON API 部署/上传工程,并且控制工程中的爬虫。
比 PySpider(下次会讲到) 更底层一些,需要学习的相关知识比较多
Scrapy 基于 Twisted 事件驱动网络框架,实现非堵塞异步处理,爬取效率高,但是不利于调试
Scrapy 自定义程度高,非常灵活,可以很容易定制出自己的项目
Scrapy 没有提供内置的机制支持分布式,必须要自定义一个基于 redis 或其他支持分布式队列的 Scheduler
基于 Scrapy 内核开发的各种框架,扩展和丰富了 Scrapy 的功能。
scrapy-crawlera解决爬网站的ip限制问题Scrapy-Redis实现分布式爬取Django Dynamic Scraper集成 Django,通过 Web 后台界面,实现动态创建管理 Spiders
往期回顾:
IT女Yooo电台节目(荔枝FM&喜马拉雅FM):
以上是关于走近代码之Python--爬虫框架Scrapy的主要内容,如果未能解决你的问题,请参考以下文章