爬虫篇 | 高级爬虫( 二):Scrapy爬虫框架初探
Posted Python绿色通道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫篇 | 高级爬虫( 二):Scrapy爬虫框架初探相关的知识,希望对你有一定的参考价值。
先确保你已经在电脑上安装好了Scrapy模块,说一下Scrapy安装的问题,网上大部分安装办法已经失效了,主要是因为 网站:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 中 twised资源已经被移除 这导致安装scrapy不能愉快的时行了. 好在我已经给了scrapy 安装的办法
当然如果你想用Anaconda 方式来安装也行,只是个人觉得杀鸡用牛刀,哈哈,随意吧!
创建爬虫项目
简单介绍一下各文件的功能
scrapy.cfg 项目部署文件
csdnSpider/:
csdnSpider/:items.py 这里主要是做爬虫提取字段
csdnSpider/:pipelines.py 对爬虫字段的进一步处理,如去重,清洗,入库
csdnSpider/:settings.py 项目的配置文件
csdnSpider/:spiders.py 这里主要做爬虫操作
创建爬虫模块
爬虫模块的代码都放置于spiders文件夹中,用于从单个或者多个网站爬取数据的类,其应该包含初始页面的URL,以及跟进网页的链接,分析页内容与提取数据的函数,创建一个Spider类,需要继承scrapy.Spider类,并且定义三个属性:
name: 用于区别Spider,必须是唯一的
start_urls: 启动时爬取入口的URL列表,后续的URL则从初始的URL的响应中主动提取
parse(): 这是Spider的一个方法,被调用时,每个初始URL响应后返回的Response对象,会作为唯一的参数传递给该方法,该方法负责解析返回的数据(reponse data),提取数据(生成item) 以及生成需要进一步处理的URL的Request对象
用Pycharm打开我们刚创建的csdnspider项目,编写爬虫模块代码:
import scrapy
class csdnspider(scrapy.Spider): # 必须继承scrapy.Spider
name = "csdn" #爬虫名称,这个名称必须是唯一的
allowed_domains=["csdn.net"] #允许的域名
start_urls = [
"https://www.csdn.net/nav/ai"
]
def parse(self, response):
# 实现网页的解析
pass
然后调用 在命令行中 进入目录csdnspider中,注意这里目录应该是于scrapy.cfg 同级, 运行命令: scrapy cralw csdn 其中csdn是我刚刚在爬虫模块定义的name.
效果图:
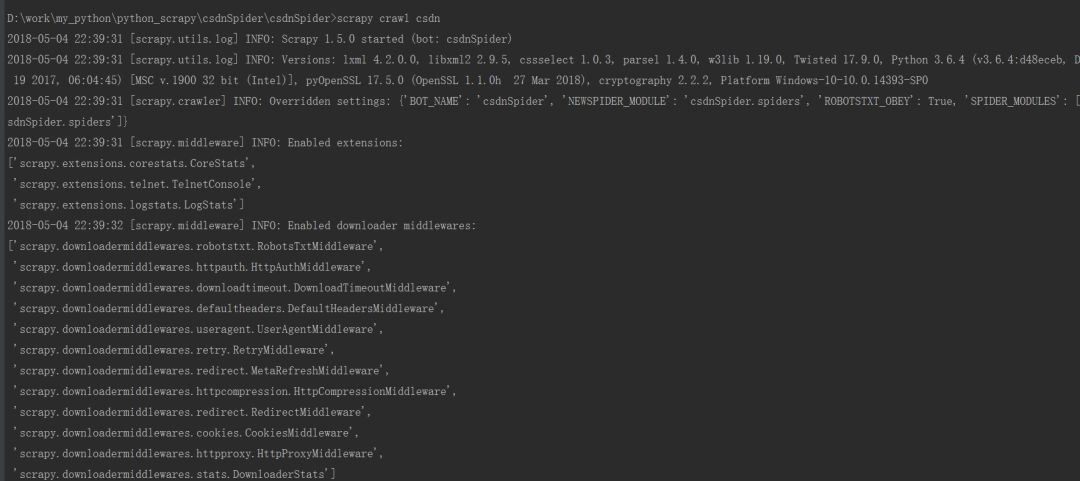
这样就创建成功了!
解析html字段(提取爬虫字段)
之前的xpath与css已经讲过,这里说一下Selector用法,Selector对象有四个基本方法 :
xpath(query) 返回表达式所对应的所有人节点的selector list列表
css(query) 返回表达式所对应的所有人节点的selector list列表
extract() 序列化该节点为Unicode字符串并返回列表
re(regex) 根据传入的正则表达式对数据进行提取,返回一个unicode字符串列表。
在csdnspider类的parse()方法中,其中一个参数是response,将response传入的Selector(response)中就可以构造出一个Selector对象。
小技巧: 我们在爬虫的时候,更多的是对爬取字段的表达式构造。Scrapy提供了一种简便的方式来查看表达式是否正确有效.
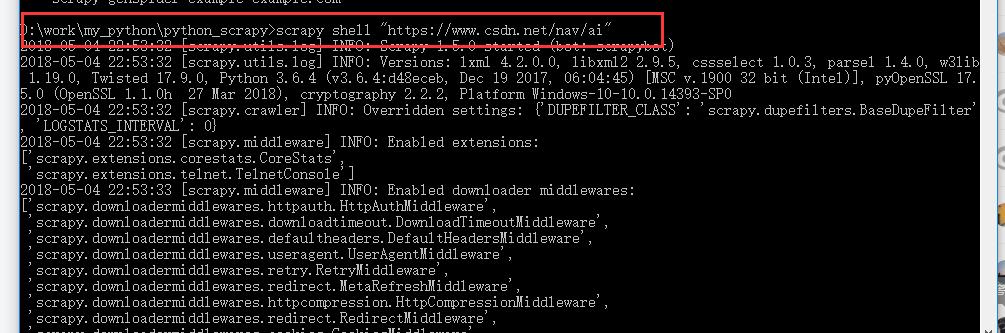
新打开一个命令窗口:输入D:\work\my_python\python_scrapy>scrapy shell "https://www.csdn.net/nav/ai"
效果图:
接着直接输入:response.xpath("//*[@id='feedlist_id']/li[1]/div/div[2]/h2/a/text()").extract() 可以查看自己提取的字段是否正确:
效果图如下:
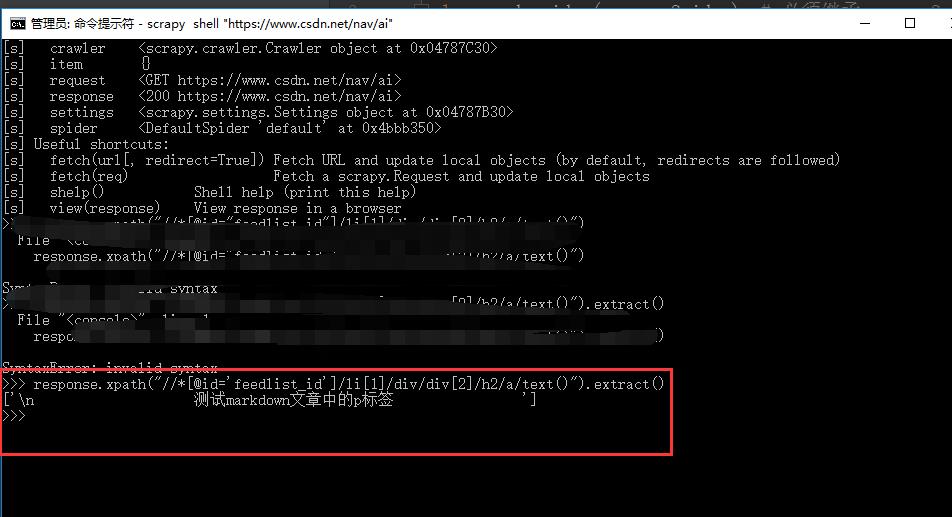
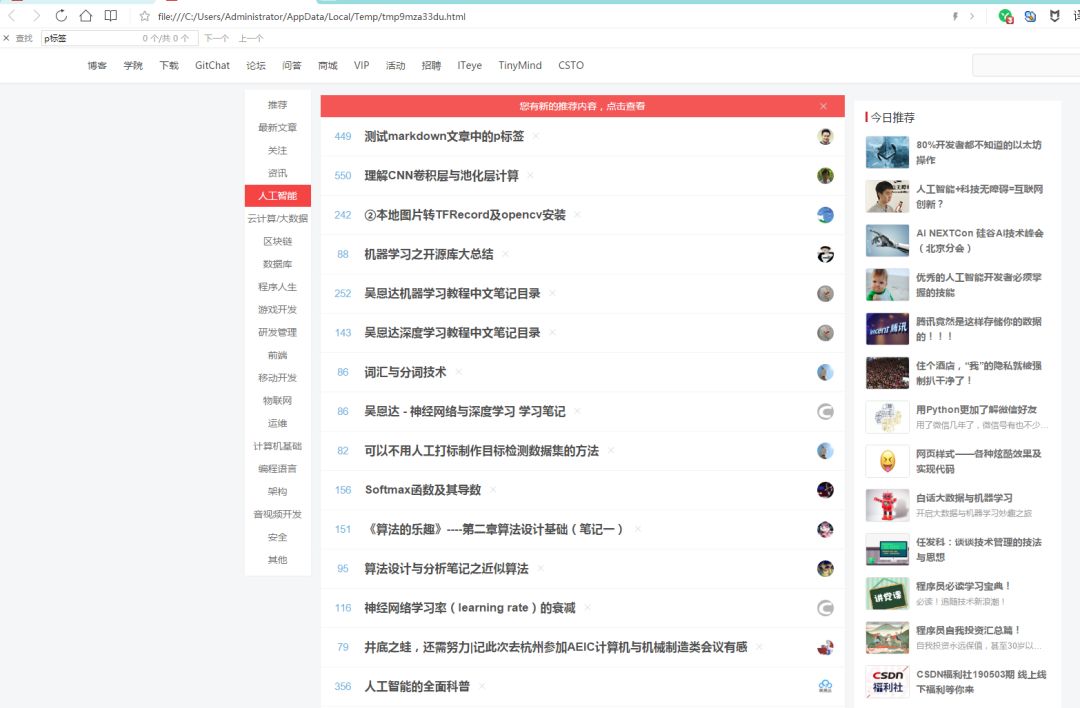
还可以查看自己爬取的网页,接着输入命令view(response) 可以查看整个网页,效果图如下:
提取爬虫字段:
import scrapy
class csdnspider(scrapy.Spider): # 必须继承scrapy.Spider
name = "csdn" #爬虫名称,这个名称必须是唯一的
allowed_domains=["csdn.net"] #允许的域名
start_urls = [
"https://www.csdn.net/nav/ai"
]
def parse(self, response):
# 实现网页的解析
datas = response.xpath('//*[@id="feedlist_id"]/li/div')
for data in datas:
read_count = data.xpath('./div[2]/h2/a/text()').extract()[0]
title = data.xpath('./div[1]/p/text()').extract()[0]
print(read_count,title)
pass
运行命令行: scrapy crawl csdn效果图如下: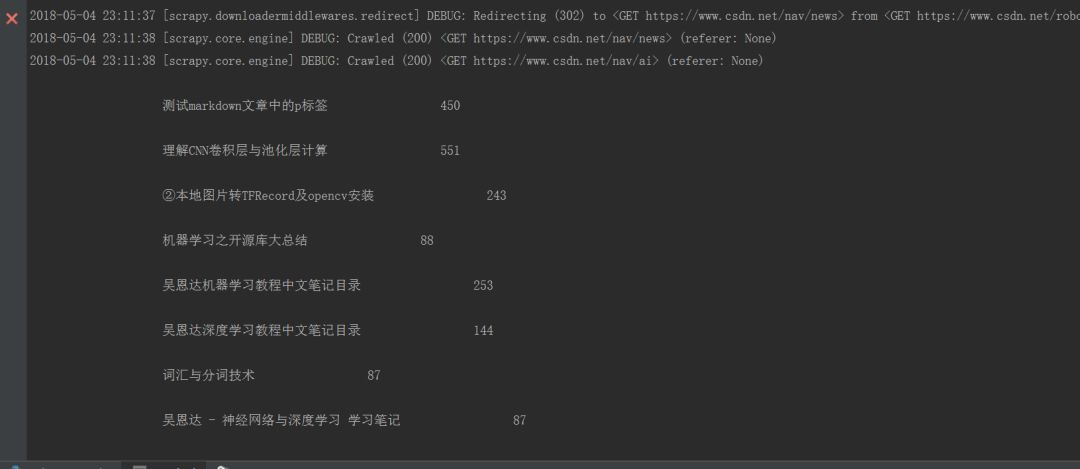
定义爬取字段(定义Item)
爬取的主要目标是从非结构性的数据源提取结构性数据. csdnspider类的parse()方法解析出了read_count,title等数据,但是如何将这些数据包装成结构化数据呢,scrapy提供了Item类来满足这样的需求. Item对象是一种简单的容器,用来保存爬取到的数据,Item使用简单的class定义语法以及Field对象来声明.
在我们创建Scrapy项目的时候,这个类已经给我们创建好了. 在项目中找到items文件 可以看到 CsdnspiderItem
类,在这里我们声明两个字段 read_count,title
class CsdnspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
read_count = scrapy.Field()
title = scrapy.Field()
pass
在csdnspider中使用,注意需要导入CsdnspiderItem
def parse(self, response):
# 实现网页的解析
datas = response.xpath('//*[@id="feedlist_id"]/li/div')
for data in datas:
read_count = data.xpath('./div[2]/h2/a/text()').extract()[0]
title = data.xpath('./div[1]/p/text()').extract()[0]
print(read_count, title)
item = CsdnspiderItem(read_count=read_count, title=title) # 封装成Item对象
yield item
代码最后使用了yield关键字来提交item ,将parse方法打造成一个生成器.
构建 Item Pipeline
前面说了网页的下载,解析和数据item,现在我们需要把数据进行持久化存储,这就要用到Item Pipeline,当Item在Spider中被收集之后,它就会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item处理.
Item pipeline主要有以下应用
清理HTML数据
验证爬取数据的合法性,检查Item是否包含某些字段
查重并丢弃
将爬取的结果保存到文件或数据库中.
定制Item Pipeline
每个Item Pipeline 组件是一个独立的Python类,必须实现process_item方法,方法原型如下:
process_item(self,item,spider)
每个Item Pipelime组件都需要调用这个方法,这个方法必须返回一一个Item对象,或者抛出DropItem异常,被抛弃的Item将不会被之后的Pipeline组件所处理.
参数说明:
Item对象是被爬取的对象
Spider对象代表着爬取该Item的Spider
我们需要将ccsdn爬虫爬取的Item存储到本地,定制的Item Pipeline位于csdnspider/pipelimes.py 声明csdnspiderPipeline类,完整内容如下:
import json
from scrapy.exceptions import DropItem
class CsdnspiderPipeline(object):
def __init__(self):
self.file = open('data.json','wb')
def process_item(self, item, spider):
if item['title']:
line = json.dumps(dict(item))+"\n"
self.file.write(line)
return item
else:
raise DropItem("Missing title in %s" %item)
process_item方法中,先判断title,如果存在就存下来,否则就抛弃。这里有多种存储方式,你也可以把数据处处到execl,数据库中.
激活Item Pipeline
定制完Item Pipeline,它是无法工作的,需要时行激活,要启动一个Item Pipeline组件,必须将它的类添加到settings.py中的ITEM_PIPELINES变量中,代码如下:
ITEM_PIPELINES = {
'csdnSpider.pipelines.CsdnspiderPipeline': 300,
}
ITEM_PIPELINES变量中可以配置很多个Item Pipeline组件,分配给每个类的整型值确定了它们运行的顺序,item按数字从低到高的顺序通过Item Pipeline,通常数字定义范围是0-1000
激活完成后,执行命令行scrapy crawl csdn, 就可以把数据存到data.json文件中
效果图:
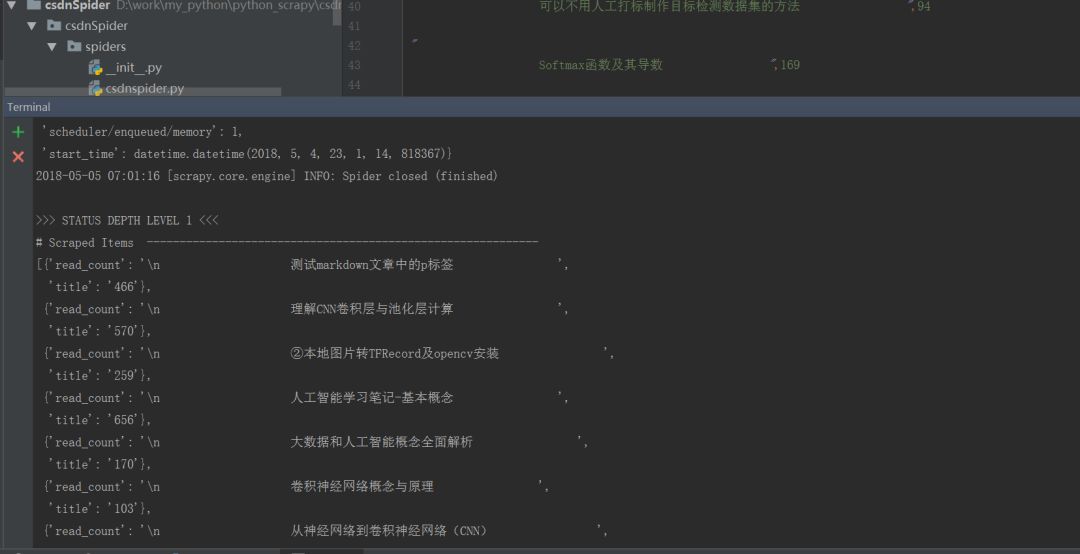
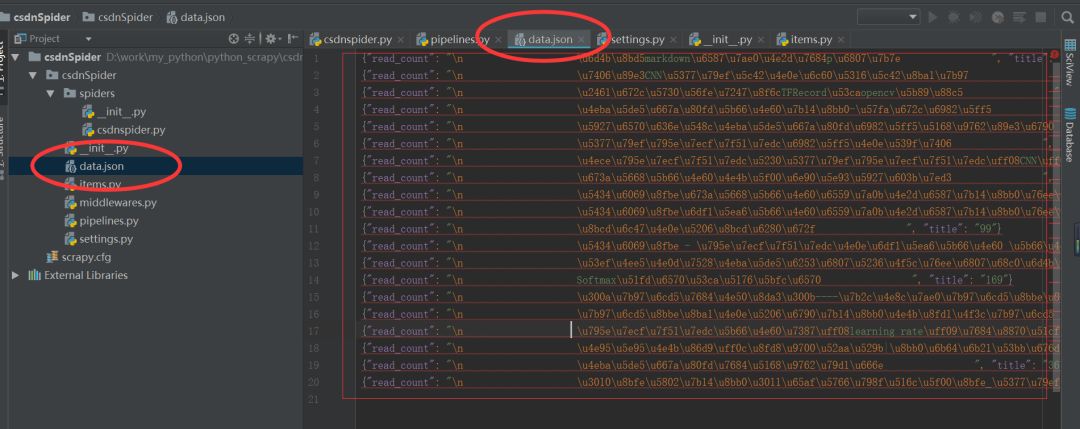
内置数据存储
除了使用Item Pipeline实现存储功能,Scrapy内置了一些简单的存储方式,生成一个带有爬取数据的输出文件,通过叫输出(feed),并支持多种序列化格式,自带的支持类型有
json
jsonlines
csv
xml
pickle
marsha1
调用的时候直接输入命令行 scrapy crawl csdn -o data.csv 注意后面的文件类型csv可以变化的,你也可以输入json,jsonlines等不同格式,可以得到不同文件.
效果如图: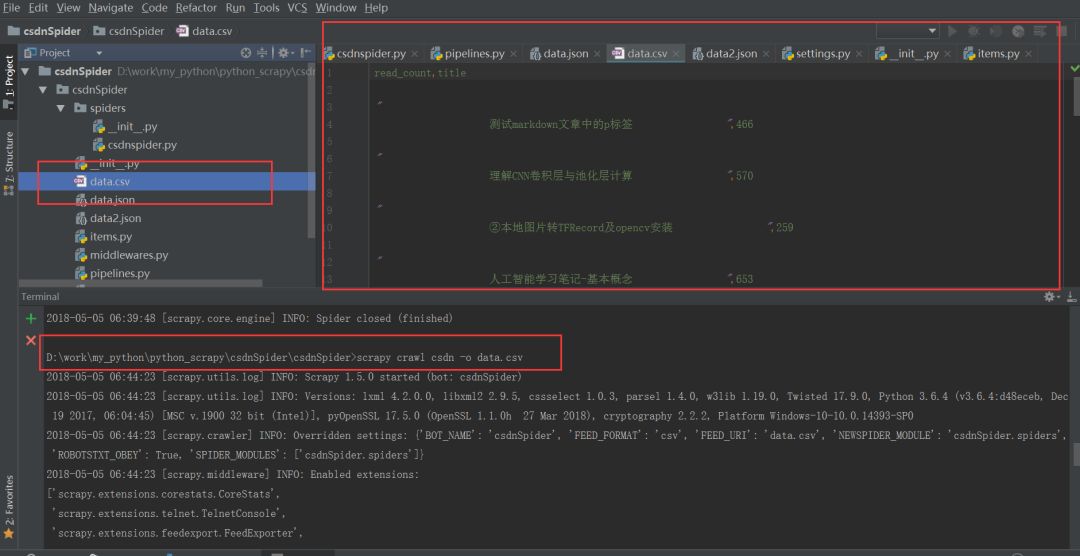
Scrapy爬虫调试
调试方法
scrapy有三种比较常用的调试方式:Parse命令,Scrapy Shell和Logging(使用起来不方便,不介绍)
Parse命令
检查spider输出的最基本方法是使用Parse命令,这能让你在函数层检查Spider各个部分效果,其十分灵活且易用
查看特定url爬取到的item 命令格式为
scrapy parse --spider=<spidername> -c <parse> -d 2 <item_url>
在命令行中切换到项目目录下输入
scrapy parse --spider=csdn -c parse -d 2 "https://www.csdn.net/nav/ai"
注意:spider=
得到效果图如下:
Scrapy shell
尽管使用Parse命令对检查spider的效果十分有用,但除了显示收到的response及输出外,期对检查回调函数内部的过程并没有什么便利,这个时候可以通过scrapy.shell.inspect_response方法来查看spider的某个位置中被处理的response,以确认期望的response是否到达特定位置,需要在csdnspider 中 parse方法里添加代码 :
def parse(self, response):
# 实现网页的解析
datas = response.xpath('//*[@id="feedlist_id"]/li/div')
# 检查代码是否达到特定位置
from scrapy.shell import inspect_response
inspect_response(response,self)
for data in datas:
read_count = data.xpath('./div[2]/h2/a/text()').extract()
title = data.xpath('./div[1]/p/text()').extract()
read_count = read_count[0] if len(read_count) > 0 else ''
title = title[0] if len(title) > 0 else ''
print(read_count, title)
item = CsdnspiderItem(read_count=read_count, title=title) # 封装成Item对象
yield item
pass
这里我们可以使用xpath来检验我们的提取方式是否正确,如果调试完了,可以使用输入exit()退出终端,恢复爬取,当程序再次运行到inspect_response方法时再次暂停,这样可以帮助我们了解每一个响应细节
效果图:
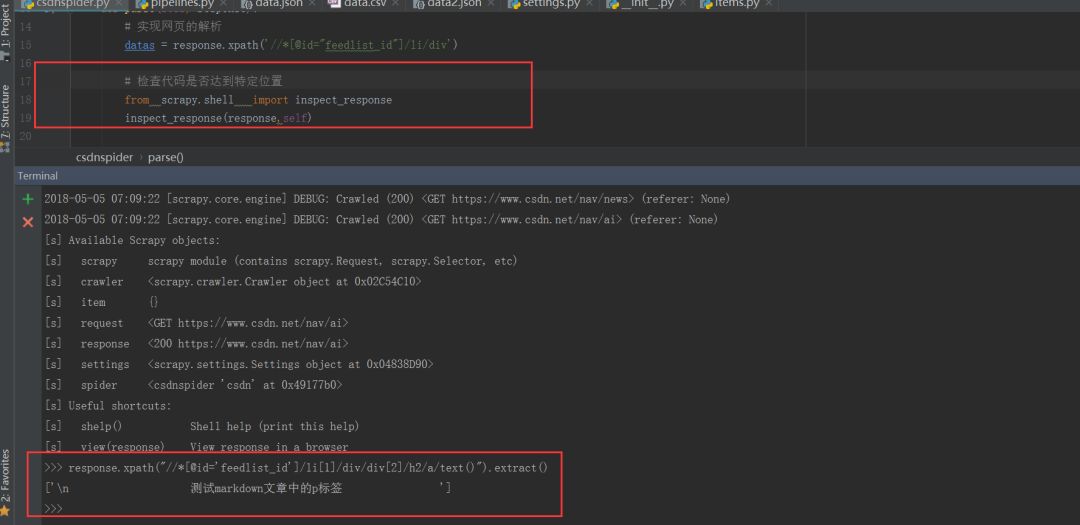
Pycharm中调试Scrapy
因为使用Pycharm我们可以更清楚的设置断点来爬虫,所以我比较推荐在Pycharm来调试.Scrapy提供了API让我们在程序中启动爬虫
下面给csdn爬虫添加启动脚本.在我们的爬虫模块类中添加代码, 为了让大家看得清楚一些,我放了完整代码,主要看最下面的main方法, 然后在代码中打断点,和我们平台调试代码一样就行,可以清晰看到我们的调试情况
import scrapy
from csdnSpider.items import CsdnspiderItem
from scrapy.crawler import CrawlerProcess
class csdnspider(scrapy.Spider): # 必须继承scrapy.Spider
name = "csdn" # 爬虫名称,这个名称必须是唯一的
allowed_domains = ["csdn.net"] # 允许的域名
start_urls = [
"https://www.csdn.net/nav/ai"
]
def parse(self, response):
# 实现网页的解析
datas = response.xpath('//*[@id="feedlist_id"]/li/div')
# # 检查代码是否达到特定位置
# from scrapy.shell import inspect_response
# inspect_response(response,self)
for data in datas:
read_count = data.xpath('./div[2]/h2/a/text()').extract()
title = data.xpath('./div[1]/p/text()').extract()
read_count = read_count[0] if len(read_count) > 0 else ''
title = title[0] if len(title) > 0 else ''
print(read_count, title)
item = CsdnspiderItem(read_count=read_count, title=title) # 封装成Item对象
yield item
pass
if __name__ == '__main__':
process = CrawlerProcess({
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.4620.400 QQBrowser/9.7.13014.400'
})
process.crawl(csdnspider)
process.start()
Scrapy工作流程
我故意把这个架构图放在最后来说,因为刚开始看这个架构图,我也是一头雾水,随着深入了解,逐渐理解了这个架构图.
架构图如下:
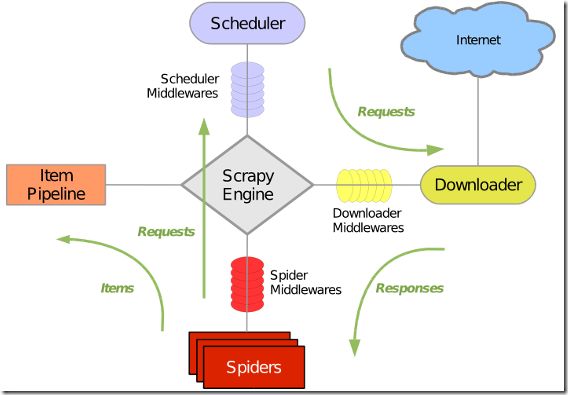
再回头看:
首先在Spiders中进行调度Scheduler请求,
然后发起一系列请求Requests 到Downloader中,
然后再是Downloder响应 Response到Spiders中,
接着就是数据采集到Items中
然后Item Pipeline来处理数据,
接着再进行下一轮请求,直到没有更多的请求,引擎关闭该网站
这就是整个Scrapy的工作流程.
如果觉得有料,来个在看,让朋友知道你越来越优秀了

扫码添加,备注:公号铁粉
以上是关于爬虫篇 | 高级爬虫( 二):Scrapy爬虫框架初探的主要内容,如果未能解决你的问题,请参考以下文章