Java数据结构与算法解析—表
Posted 太原中软卓越EEC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java数据结构与算法解析—表相关的知识,希望对你有一定的参考价值。
再不点蓝字关注,机会就要飞走了哦
如果要通俗简单的说什么是表,那我们可以这样说: 按顺序排好的元素集合就是表。
今天小卓与大家来一起讨论常见常用的数据结构——表。

表的概述
抽象数据类型是带有一组操作的一些对象的结合
抽象数据类型是带有一组操作的一些对象的结合
1、定义:
线性表是一个线性结构,它是一个含有n≥0个结点的有限序列,对于其中的结点,有且仅有一个开始结点没有前驱但有一个后继结点,有且仅有一个终端结点没有后继但有一个前驱结点,其它的结点都有且仅有一个前驱和一个后继结点。
2、特征/性质
1)集合中必存在唯一的一个第一个元素
2)集合中必存在唯一的一个最后元素
3)除最后一个元素之外,均有唯一的后继
4)除第一个元素之外,均有唯一的前驱
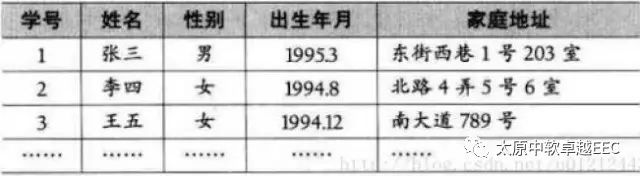
在上图中,a1是a2的前驱,ai+1 是ai的后继,a1没有前驱,an没有后继 ,n为线性表的长度 ,若n==0时,线性表为空表 ,下图就是一个标准的线性表:
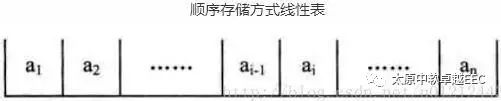
3、线性表分为如下几种
顺序存储方式线性表
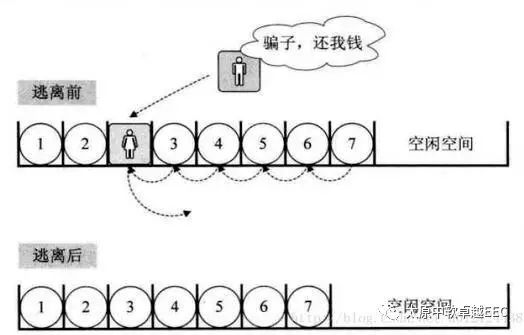
如每个元素占C个存储单元,那么有: Loc(An) = Loc(An-1) + C,于是有: Loc(An) = Loc(A1)+(i-1)*C;
优点:查询很快
缺点:插入和删除效率慢
下图很形象的表现了,插入和删除慢的特点
表的简单数组实现顺序存储方式线性的典型就是数组,对于表的所有操作都可以通过使用数组来实现。虽然数组创建时就已经是固定大小,但在需要的使用可以用双倍的容量创建一个不同的数组。下面是扩容的伪代码:
int[] aar = new int[10];
//扩大aar
int[] newArr = new int[aar.length * 2];
for (int i = 0; i < aar.length; i++) {
newArr[i] = aar[i];
}
aar = newArr;
数组的实现使得printList以线性时间被执行,而findKth(返回特定位置上的元素)则花费常数的时间。
最坏的情形是,在位置0插入一个元素,需要将数组中所有元素向后移动一个位置,而删除一个元素,则需要将所有元素向前移动一个位置,两种情况复杂度都是O(n)。平均来看,两种操作都需要移动表一半的元素,因此需要线性时间,但是如果插入和删除都发生在数组的最尾,则插入和删除都只需要花费O(1)的时间。
如果频繁的插入和删除发生在表的最前端,则使用链表会更好。
链式存储方式线性表
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的
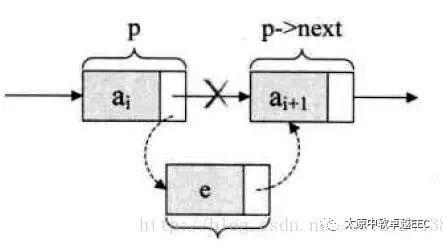
优点:相对于数组,删除还插入效率高
缺点:相对于数组,查询效率低
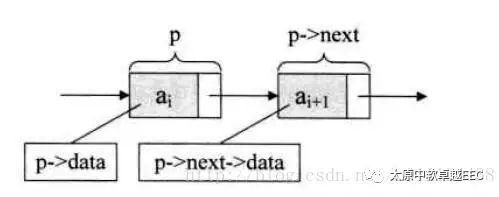
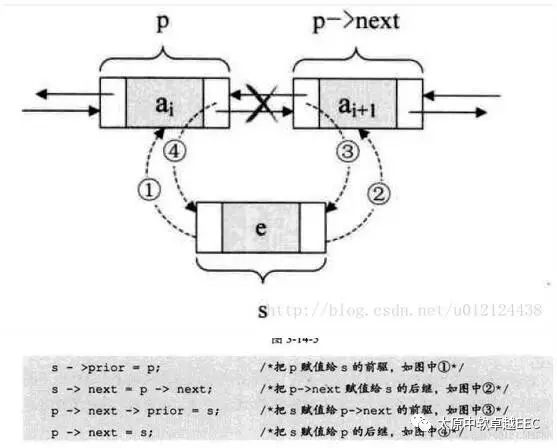
要执行插入操作,只需要如下的代码:
s->next = p->next
p-next = s ;
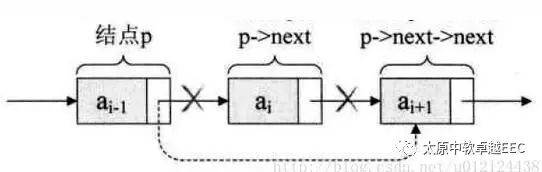
执行删除操作,只需要如下的代码:
p->next = p->next->next
循环链表将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相连的单链表称为单循环链表,简称循环链表。

双向循环链表
双向循环链表是单向循环链表的每个结点中,再设置一个指向其前驱结点的指针域
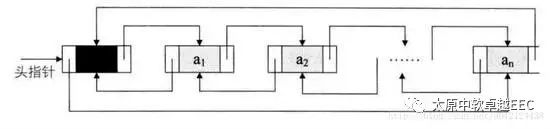
对于空的双向循环链表
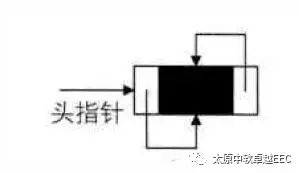
双向循环链表插入
4、Java Collection Api中的表
1.IteratorIterator接口的思路,通过Iterator方法,每个集合均创建并返回给客户一个实现Iterator接口的对象,并将当前位置的概念在对象内部存储下来。
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
}
Iterator中的方法有限,因此,很难使用Iterator做遍历Collection意外的任何工作。Iterator还包含一个remove()方法。该方法的作用是删除next()最新返回的项(此后不能再调用remove(),直到你下一次调用next())。
如果对正在被迭代的集合进行结构上的改变(即对该集合使用add,remove或clear),那么迭代器将不再合法(并且在其后使用该迭代器将出现Concurrent Modification Exception异常被抛出),为了避免迭代器准备给出某一项作为下一项而该项此后或者被删除,所以只有在需要立即使用一个迭代器的时候,我们才应该获取迭代器。然而,如果迭代器调用了它自己的remove方法,那么这个迭代器就仍然合法的。
2.List接口
public interface List<E> extends Collection<E> {
int size();
boolean isEmpty();
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean addAll(int index, Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
void clear();
boolean equals(Object o);
int hashCode();
E get(int index);
E set(int index, E element);
void add(int index, E element);
E remove(int index);
int indexOf(Object o);
int lastIndexOf(Object o);
ListIterator<E> listIterator();
}
List ATD有两种流行的实现方式,ArrayList和LinkedList。
ArrayList的优点是,get和set调用花费常数时间。缺点是新项的插入和现有项的删除代价昂贵,除非变动的是ArrayList的末端。
LinkedList优点是,在表的前端添加和删除都是常数时间,缺点是不容易作索引,get的调用是昂贵的,除非是接近表的端点
public static void makeList1(List<Integer> lst,int n){
lst.clear();
for (int I = 0; I < n; i++) {
lst.add(i);
}
}
不管ArrayList还是LinkedList作为参数被传递,makeList1的运行时间都是O(N),因为对add的每次调用都是在表的末端进行从而花费常数时间(可以忽略对ArrayList偶尔扩展)。另一方面,如果我们通过在表的前端添加一些项来构造一个List:
public static void makeList2(List<Integer> lst,int n){
lst.clear();
for (int I = 0; I < n; i++) {
lst.add(i);
}
}
对于LinkedList它的运行时间是O(N),但是对于ArrayList其运行时间则是O(n^2),因为在ArrayList中,在前端进行添加是一个O(N)操作。
Public static int sum(List<Integer> lst){
int total = 0;
for (int I = 0; I < n; i++) {
total+=lst.get(i);
}
return total;
}
这里,ArrayList的运行时间是O(N),但对于LinkedList来说,其运行时间则是O(n^2),因为LinkedList中,对get的调用为O(N)操作。可是,要是使用一个增强的for循环,那么它对任意List的运行时间都是O(N),因为迭代器将有效地从一项到下一项推进。
对搜索而言,ArrayList和LinkedList都是低效,对Collection的contains和remove方法调用均花费线性时间。
例子:remove方法对LinkedList类的使用例子1:假设现在有6,5,1,4,2五个数,需要在方法调用之后去除所有的偶数。
思路:
1.创建一张包含所有奇数的新表,清除原表,再将奇数拷贝回去。
2.直接在原表中进行遍历,遇到偶数时直接进行移除。
ArrayList和LinkedList针对于remove都是低效的,在LinkedList中,到达i位置的代价是昂贵的。
public static void removEventVer1(List<Integer> lst) {
int i = 0;
while (i < lst.size()) {
if (lst.get(i) % 2 == 0) {
lst.remove(i);
} else {
i++;
}
}
}
对于LinkedList来说,上面的解法运行时间则是O(n^2),使用迭代器的效率会更好,当然在使用迭代器时,我们不能直接使用List的remove,否则会抛出异常,就像下面的写法(增强for循环底层还是用的迭代器)
public static void removEventVer2(List<Integer> lst) {
for (Integer x : lst) {
if (x % 2 == 0) {
lst.remove(x);
}
}
}
为了解决上面的问题,我们可以直接使用迭代器的remove方法,这样做是合法的
public static void removEventVer3(List<Integer> lst) {
Iterator<Integer> itr = lst.iterator();
while (itr.hasNext()){
if (itr.next()%2==0){
itr.remove();
}
}
}
使用了Iterator以后,LinkedList的remove操作消耗的就是O(n)时间,因为Iterator已经位于需要被删除的节点上。
而即使使用Iterator,ArrayList的remove方法还是O(n^2),因为删除,数组的数还是需要进行移动。
ListIterator接口ListIterator接口扩展了Iterator,hasNext和hasPrevious方法,使得既可以从前遍历也可以从尾巴进行遍历,add在当前位置插入一个新的项,set方法改变Iterator调用hasNext或hasPrevious返回的当前值。
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
boolean hasPrevious();
void remove();
void set(E e);
void add(E e);
实现一个ArrayList
下面,我们自己手写一个ArrayList,且支持泛型,代码如下:
public class MyArrayList<T> implements Iterable<T> {
private static final int DEFAULT_CAPACITY = 10;
private T[] mArray;
private int mArraySize;
@Override
public Iterator<T> iterator() {
return new ArrayIterator();
}
private class ArrayIterator implements Iterator<T> {
private int currentPositon;
@Override
public boolean hasNext() {
return currentPositon < mArraySize;
}
@Override
public T next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
return mArray[currentPositon++];
}
@Override
public void remove() {
MyArrayList.this.remove(--currentPositon);
}
}
public void trimTosize() {
ensureCapacity(size());
}
public int size() {
return mArraySize;
}
public boolean isEmpty() {
return mArraySize == 0;
}
public MyArrayList(int size) {
if (size < DEFAULT_CAPACITY) {
mArraySize = size;
} else {
ensureCapacity(DEFAULT_CAPACITY);
}
}
private void ensureCapacity(int newCapacity) {
T[] newArray = (T[]) new Object[newCapacity];
for (int i = 0; i < mArray.length; i++) {
newArray[i] = mArray[i];
}
mArray = newArray;
}
public boolean add(T t) {
add(t, mArraySize);
return true;
}
public void add(T t, int position) {
if (mArraySize == mArray.length) {
ensureCapacity(mArraySize * 2 + 1);
}
for (int i = position; i < mArraySize - 1; i++) {
mArray[i + 1] = mArray[i];
}
mArray[position] = t;
++mArraySize;
}
public T reomve() {
return remove(mArraySize);
}
private T remove(int position) {
T t = mArray[position];
for (int i = position; i < mArraySize - 1; i++) {
mArray[i] = mArray[i + 1];
}
--mArraySize;
return t;
}
public T get(int position) {
if (position < 0 || position > mArraySize) {
throw new ArrayIndexOutOfBoundsException();
}
return mArray[position];
}
public T set(T t) {
return set(t, mArraySize - 1);
}
public T set(T t, int position) {
if (position < 0 || position > mArraySize) {
throw new ArrayIndexOutOfBoundsException();
}
T old = mArray[position];
mArray[position] = t;
return old;
}
}
值得一提的是,我们不能直接new T[],而是需要通过下面的代码创建一个泛型的数组
T[] newArray = (T[]) new Object[newCapacity];
还有一点值得说明的是,在ArrayIterator中使用MyArrayList.this.remove是为了避免和迭代器自身的remove冲突
@Override
public void remove() {
MyArrayList.this.remove(--currentPositon);
}
实现LinkedList
在LinkedList中,最前端的节点叫做头节点,最末端的节点叫做尾节点。这两个额外的节点的存在,排除许多特殊情况,极大简化了编码。例如:如果不使用头节点,那么删除第一个节点就是特殊情况,因为在删除时需要重新调整链表到第一个节点的链,还因为删除算法一般还要访问被删除节点前面的那个节点(如果没有头节点的话,第一个节点就会出现前面没有节点的特殊情况)。
public class MyLinkedList<T> implements Iterable<T> {
private Node<T> headNote;
private Node<T> endNote;
private int mSize;
private int modCount;
public MyLinkedList() {
init();
}
private void init() {
headNote = new Node<>(null, null, null);
endNote = new Node<>(null, headNote, null);
headNote.mNext = endNote;
mSize = 0;
modCount++;
}
public int size() {
return mSize;
}
public boolean isEmpty() {
return mSize == 0;
}
public boolean add(T t) {
addBefore(t, size());
return true;
}
public T get(int index) {
Node<T> temp = getNode(index, 0, size());
return temp.mData;
}
public T remove(int position) {
Node<T> tempNode = getNode(position);
return remove(tempNode);
}
private T remove(Node<T> tempNode) {
tempNode.mPre.mNext = tempNode.mNext;
tempNode.mNext.mPre = tempNode.mPre;
mSize--;
modCount++;
return tempNode.mData;
}
public T set(int index, T t) {
Node<T> tempNode = getNode(index);
T old = tempNode.mData;
tempNode.mData = t;
return old;
}
private Node<T> getNode(int index) {
return getNode(index, 0, size() - 1);
}
private Node<T> getNode(int index, int lower, int upper) {
Node<T> tempNode;
if (lower < 0 || upper > mSize) {
throw new IndexOutOfBoundsException();
}
if (index < mSize / 2) {
tempNode = headNote.mNext;
for (int i = 0; i < index; i++) {
tempNode = tempNode.mNext;
}
} else {
tempNode = endNote;
for (int i = mSize; i > index; i--) {
tempNode = tempNode.mPre;
}
}
return tempNode;
}
private static class Node<T> {
private Node<T> mNext;
private T mData;
private Node<T> mPre;
public Node(T data, Node<T> pre, Node<T> next) {
mData = data;
mPre = pre;
mNext = next;
}
}
private class LinkedListIterator implements Iterator<T> {
private Node<T> currentNode = headNote.mNext;
private int expectedModCount = modCount;
private boolean okToMove;
@Override
public boolean hasNext() {
return currentNode != endNote;
}
@Override
public T next() {
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
if (!hasNext()) {
throw new NoSuchElementException();
}
T t = currentNode.mData;
currentNode = currentNode.mNext;
okToMove = true;
return t;
}
@Override
public void remove() {
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
if (!okToMove) {
throw new IllegalStateException();
}
MyLinkedList.this.remove(currentNode.mPre);
expectedModCount++;
okToMove = false;
}
@Override
public Iterator<T> iterator() {
return new LinkedListIterator();
}
}
1.modCount代表自从构造以来对链表所做改变的次数。每次对add或remove的调用都将更新modCount。想法在于,当一个迭代器被建立时,他将存储集合的modCount。每次个迭代器方法(next或remove)的调用都将该链表内的当前modCount检测在迭代器内存储的modCount,并且当两个计数不匹配时,抛出一个ConcurrentModificationException异常。
2.在LinkedListIterator中,currentNode表示包含由调用next所返回的项的节点。注意,当currentNode被定位在endNote,对next调用是非法的。
在LinkedListIterator的remove方法中,currentNode是保持不变的,因为currentNode节点不受前面节点被删除的影响,与ArrayIterator不同,(在ArrayIterator中,项被移动,要求更新current)
(来源:51CTO)
12
太原中软卓越
太原中软卓越根植于中软强大的软件基因和背景,服务于超一流互联网企业,掌握最前沿的IT技术(Java、UI设计、web前端、ios、android、php、嵌入式、软件测试等),拥有实力雄厚、大型实战项目经验丰富的技术团队。坚持5R教学原则,以中软准员工的要求约束学员,用真实的工作体验让学员提前适应职场,4个月后直接走向工作岗位,避免工作后的水土不服。
如果你身边的小伙伴还在为找工作发愁,或者想转行,赶快将他的姓名和联系方式发给小卓(18734824119),小卓会与他(她)致电并给他(她)最合适的学习建议并免费邀请他试听5天的课程,座位有限,抓紧时间哦。
QQ:2847567102
以上是关于Java数据结构与算法解析—表的主要内容,如果未能解决你的问题,请参考以下文章