数据结构与算法–关键路径
Posted 36大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法–关键路径相关的知识,希望对你有一定的参考价值。
关键路径与无环加权有向图的最长路径
现在考虑一个这样的问题:你今天事情比较多,要洗衣服、做作业还要烧水洗澡,之后出去找朋友玩。假设洗衣服要20分钟,烧水要30分钟,做作业的话你把朋友做好的带回来抄,只需要10分钟。你想能早些去找朋友,但在那之前又必须将那些事做完,你要怎么安排呢?很容易想到,这三者同时进行:打好水开始烧水,衣服扔进洗衣机,回书桌抄作业…20分钟后作业写完了,衣服也洗好了,水还有10分钟水才烧开,利用这时间把洗好的衣服晾晒好,差不多水也烧开了,好了最后去洗澡。简直一气呵成,这是我们能花费的最少时间了,在这个例子中刚好等于所有任务中持续时间最长的那个。(你做完了作业才想起来去烧水,花费不止半小时吧)
由此引申出一个更为广泛的问题,给定一组需要完成的任务和每个任务所需的时间,以及一组关于任务完成的先后次序的优先级限制。在满足限制条件的前提下应该如何在若干相同的处理器上(数量不限,可并行处理多个任务)安排任务并在最短的时间内完成所有的任务?
此问题的提出主要是为了解决并行任务调度,使得完成所有任务的总时间最短。待处理的任务总数可能成百上千,因此需要一个算法帮我们快速规划一个调度方案:按照怎样的顺序执行这些任务,哪些任务可以同时处理,如何使得耗费的总时间最短?正好存在一种叫做“关键路径”的方法可以证明这个问题与无环加权有向图的最长路径问题等价。
关键路径:把路径上各个任务所持续的时间之和称为路径长度,从起点到终点的所有路径中,具有最长路径长度的路径称为关键路径,关键路径中的各个任务称为关键任务。上面的例子中,烧水就是个关键任务。
首先,按照关键路径的顺序执行任务,一定能保证所有的任务都能完成,且此时花费的总时间最短。有些活动顺序进行,有些活动并行进行。从起点到各个顶点,以至从起点到终点的有向路径可能不止一条,这些路径的长度也不尽相同。这若干条从起点到终点的路径可以看做一个生产过程的几条不同的生产线,必须每条生产线都完工,整个生产过程才算结束,也就是不论如何你都得等那条花费时间最长的流水线做完,整个生产才可能完工。现在由于可以同时处理多个任务,在花费时间最长的流水线工作过程中,其他流水线一定会提前完工,因此花费时间最长的流水线做完后,整个工程也随之竣工了。假设花费时间最长的那条流水线所用的时间是M,这就是说,不管怎么安排,都需要至少M的时间才能竣工,而这已经是最短时间了。
再举个例子,你和朋友们约好去某个地方聚餐。有些朋友到的比较早,有些朋友到得比较晚,但是不管怎么样,我们都要等到最后一个朋友到目的地,这样大家才算是聚齐了。
说了半天,求并行任务调度中的关键路径,实际上就是求从起点到终点的最长路径。
通过求解最长路径得到关键路径
通过上面的讨论,现在只需求最长路径,就能得到关键路径。我们知道任务调度必须要求图是无环的,因此可以使用求无环加权有向图的最短路径的方法求最长路径。
具体方法是:复制原图得到一个副本,将副本的所有边的权重取相反数,求副本的最短路径实际上就是原图的最长路径。
或者一个更为简单的方法:修改边的放松方法。改为distTo[v] + edge.weight() > distTo[w](求最短路径的不等号是<),即:有比原来到w更长的路径就更新。同时初始化的时候,distTo[i]从原来的正无穷改成负无穷。
求无环加权有向图的最短路径,可以按照拓补排序依次放松顶点。详细的见我上一遍文章,只需改前述两个地方,就能求得最长路径。
package Chap7;
import java.util.LinkedList;
/**
* 求无环有向图的最长路径
*/
public class AcycliLP {
private DiEdge[] edgeTo;
private double[] distTo;
public AcycliLP(EdgeWeightedDiGraph<?> graph, int s) {
edgeTo = new DiEdge[graph.vertexNum()];
distTo = new double[graph.vertexNum()];
for (int i = 0; i < graph.vertexNum(); i++) {
// 1. 改成了负无穷
distTo[i] = Double.NEGATIVE_INFINITY;
}
distTo[s] = 0.0;
// 以上是初始化
TopoSort topo = new TopoSort(graph);
if (!topo.isDAG()) {
throw new RuntimeException("该图存在有向环,本算法无法处理!");
}
for (int v : topo.order()) {
relax(graph, v);
}
}
private void relax(EdgeWeightedDiGraph<?> graph, int v) {
for (DiEdge edge : graph.adj(v)) {
int w = edge.to();
// 2、若路径更长就更新
if (distTo[v] + edge.weight() > distTo[w]) {
distTo[w] = distTo[v] + edge.weight();
edgeTo[w] = edge;
}
}
}
public double distTo(int v) {
return distTo[v];
}
public boolean hasPathTo(int v) {
return distTo[v] != Double.POSITIVE_INFINITY;
}
public Iterable<DiEdge> pathTo(int v) {
if (hasPathTo(v)) {
LinkedList<DiEdge> path = new LinkedList<>();
for (DiEdge edge = edgeTo[v]; edge != null; edge = edgeTo[edge.from()]) {
path.push(edge);
}
return path;
}
return null;
}
}
好,可以求得关键路径了。现在来看一个任务调度的例子,如何利用上面的实现来安排任务。
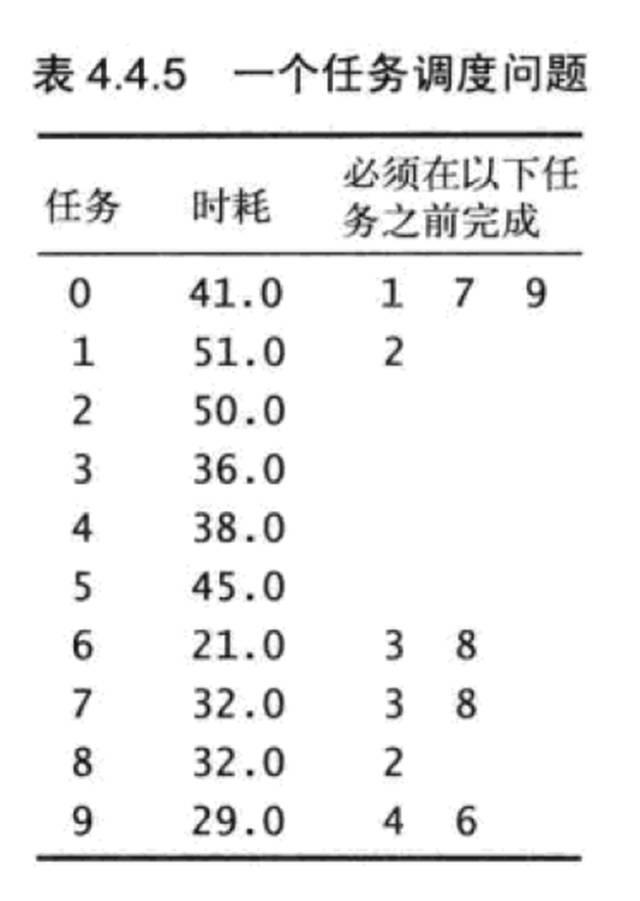
现在要先将其转换为图。由于有些工程不好看出哪个任务是最先开工的,哪个是收尾的任务(比如上图)。在不同的任务表中,每个任务都可能成为起点或终点。为了可以应付各种任务表,不妨设置虚拟的起点和终点。因为每个任务都可能最先开工,所以设置一个虚拟起点可以指向图中所有顶点,且权值都为0;因为每个顶点都可能作为收尾任务,因此所有顶点指向一个虚拟的终点,权值是这些顶点代表的任务所持续的时间。这样我们也不用在乎任务表中哪个任务最先开工、最后收尾的关系够不够明确了,设置了虚拟起点和终点后,只要求得从起点到终点的最长路径,中间走过的路径的就是各个任务执行的顺序。
加入虚拟顶点后,上面的任务表其实就是下图。
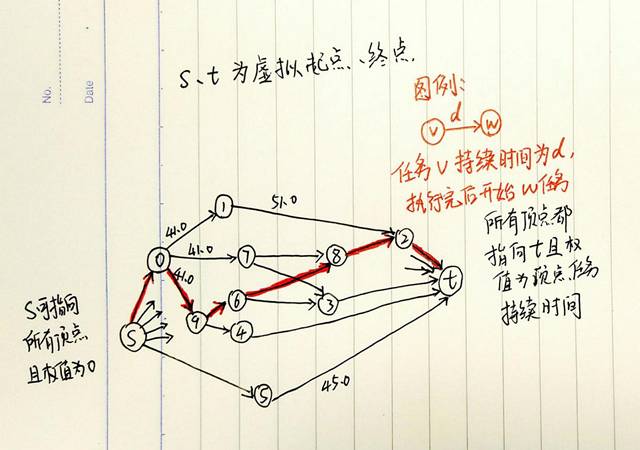
各条从s到t的路径中(想象成各条生产线),找出最长的那条(费时最长的那条生产线),这条0 -> 9 -> 6 -> 8 -> 2就是关键路径,按照这个顺序执行任务就能使得完成整个工程总时间最短。
我们用代码测试一下。
package Chap7;
public class CPM {
private AcycliLP lp;
private int s; // 虚拟的起点
private int t; // 虚拟的终点
private int jobsNum; // 任务个数
public CPM(double[] jobDuration, int[][] mustCompletedBefore) {
jobsNum = jobDuration.length;
// 设置两个虚拟顶点,代表起点和终点
EdgeWeightedDiGraph<?> graph = new EdgeWeightedDiGraph<>(jobsNum + 2);
s = jobDuration.length; // 起点
t = s + 1; // 终点
for (int i = 0; i < jobsNum; i++) {
// 每个顶点都可能成为最先开工的,所以虚拟起点指向所有顶点,且费时都为0
graph.addDiEdge(new DiEdge(s, i, 0.0));
// 每个顶点都可能成为工程收尾的活动,所有顶点都指向该虚拟终点,费时自然是每个活动所持续的时间
graph.addDiEdge(new DiEdge(i, t, jobDuration[i]));
// 任务i必须在任务j之前完成, 即加入i -> j的有向边
for (int j = 0; j < mustCompletedBefore[i].length; j++) {
int successor = mustCompletedBefore[i][j];
graph.addDiEdge(new DiEdge(i, successor, jobDuration[i]));
}
// 找到到每个活动的最长路径
lp = new AcycliLP(graph, s);
}
}
public void printJobExecuteOrder() {
System.out.println("各任务开始时间表:");
for (int i = 0; i < jobsNum; i++) {
System.out.println(i + ": " + lp.distTo(i));
}
System.out.println("\n按照以下顺序执行任务,开始时间相同的任务同时执行。");
for (DiEdge edge : lp.pathTo(t)) {
// 遇到起点不打印箭头
if (edge.from() == s) {
System.out.print(edge.to());
}
// 最后一个任务在前一个顶点的就打印过了,遇到最后一条边换行就行
else if (edge.to() == t) {
System.out.println();
} else {
System.out.print(" -> " + edge.to());
}
}
System.out.println("总共需要" + lp.distTo(t));
}
public static void main(String[] args) {
// 每个任务的持续时间
double[] duration = {41.0, 51.0, 50.0, 36.0, 38.0, 45.0, 21.0, 32.0, 32.0, 29.0};
int[][] before = {{1, 7, 9}, {2}, {}, {}, {}, {}, {3, 8}, {3, 8}, {2}, {4, 6}};
CPM cpm = new CPM(duration, before);
cpm.printJobExecuteOrder();
}
}
根据任务表,给图增加边。
虚拟起点到所有顶点的边,且权值为0;
所有顶点到虚拟终点的边,且权值为顶点任务持续时间。
某任务v必须在一些任务之前完成的边,且权值为任务v的持续时长。比如0必须在1、7、9之前,则增加0 -> 1,0 -> 7,0 -> 9边,且权值都为任务0的持续时长。
接下来通过AcycliLP类求得关键路径,distTo[i]就表示i任务的开始时间,distTo[t]表示做完整个工程需要的最短时间;pathTo[i]表示执行到任务i的关键路径,自然pathTo[t]就是整个工程的关键路径。
上面的代码会打印如下结果:
各任务开始时间表: 0: 0.0 1: 41.0 2: 123.0 3: 91.0 4: 70.0 5: 0.0 6: 70.0 7: 41.0 8: 91.0 9: 41.0 按照以下顺序执行任务,开始时间相同的任务同时执行。 0 -> 9 -> 6 -> 8 -> 2 总共需要173.0
可以清楚地看到每个任务应该在什么时刻开始动工,只要按照0 -> 9 -> 6 -> 8 -> 2这样顺序执行就好。而且,有些任务开始时间一样,表示我们应该同时执行它们以节省时间。所以最后的方案是:0、5最先并同时执行,只要0做完了,就开始同时执行1、7、9,只要9做完了立刻同时执行4、6,一旦6做完了同时执行3、8,8只要完工紧接着做2,最后等待2也终于做完,整个工程竣工!需要的最短时间为173.0。
关键路径中的任务都是做完后就立刻执行下一个的(比如0执行完立刻执行9,9完工立刻执行6…),不用等待和它一起开工的其他任务也做完,因为这些任务在花费最长时间的这条关键路径上,它们迟早都能做完的。因此关键路径中,各个关键任务是不会有空闲和等待时间。如下图是上面任务表的执行流程
0 -> 9 -> 6 -> 8 -> 2一气呵成,中间毫无停顿。而且其他任务在这条生产线执行过程中均已完成!
End
“讲述大数据在金融、电信、工业、商业、电子商务、网络游戏、移动互联网等多个领域的应用,以中立、客观、专业、可信赖的态度,多层次、多维度地影响着最广泛的大数据人群
36大数据
搜索「36大数据」或输入36dsj.com查看更多内容。
投稿/商务/合作:dashuju36@qq.com
↓↓↓
以上是关于数据结构与算法–关键路径的主要内容,如果未能解决你的问题,请参考以下文章