朴素贝叶斯模型——文本情感分类
Posted IT肥宅那些事儿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯模型——文本情感分类相关的知识,希望对你有一定的参考价值。
贝叶斯定理是概率论中应用最为广泛的理论之一,在数据分类、属性预测等方面应用较多。
贝叶斯定理的实质是基于概率的推理,即在随机事件A的条件下,B发生的条件概率(或边缘概率),即P(B|A)。
其基本计算公式如下所示:
贝叶斯公式:
贝叶斯定理在分类中的应用
对于任意的分类问题,给定样本
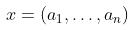
其中, 括号内的是样本的各个属性,比如西瓜,就有很多属性,皮是什么颜色的、拍击西瓜的声音是否浊音等,这些属性分别构成了样本的一个特征,也称之为一个维度,通常一个样本的维度是多维的。
那问题来了,该如何应用贝叶斯公式进行分类呢?
回到贝叶斯定理,在随机事件A的条件下,B发生的条件概率(或边缘概率),即P(B|A),对于分类问题来说,我们所知的是一个样本以及该样本的各个维度特征,这个就是随机事件A,接下来要做的就是根据这个随机事件来预测样本到底是好的还是坏的,或者对应多分类问题就是对应哪一个类别。
我以西瓜书上的数据为例:
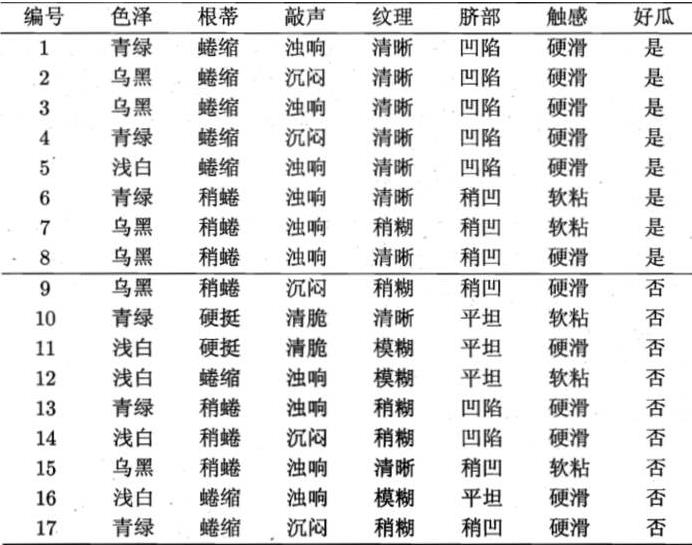
图1. 西瓜数据集。注:数据来源周志华老师的《机器学习》
对于编号为1的样本,有6个属性,当然通常在训练过程中,样本的标签或者说类别是已知的,基于贝叶斯定理进行分类就是在这6个属性的条件下,来预测该样本是好瓜还是坏瓜的概率,即:
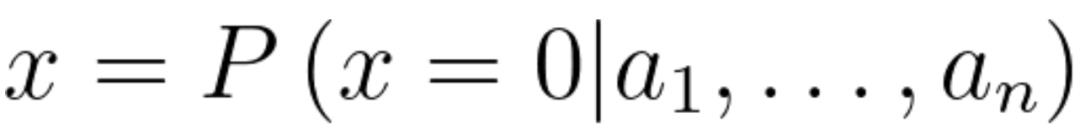
或
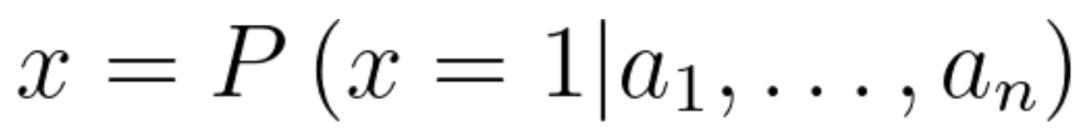
其中,0和1分别表示好瓜和坏瓜。这和我们生活中买瓜有点类似,看中一个西瓜,我们先看看成色,然后再拍一拍西瓜,听一听声音是怎么样的,在这些条件下,然后综合判断这是不是一个好瓜,最后决定买不买。
朴素贝叶斯模型
根据前文所说,利用贝叶斯定理进行分类,通常是根据样本各个维度的数据作为条件进行分类的,我们知道,条件概率公式满足:
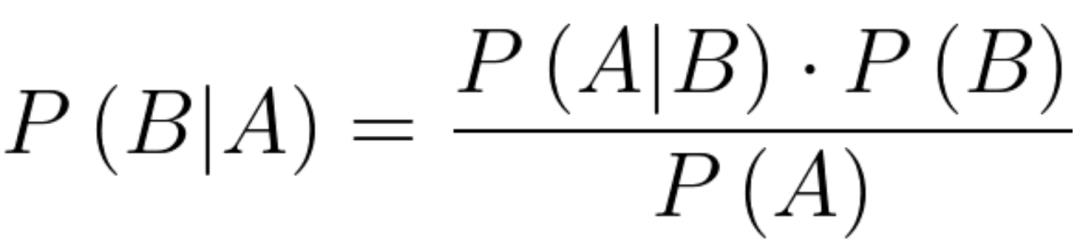
假设A代表分类结果,P(A)就称为先验概率,P(A|B)就称为后验概率,分类问题实际上就是在求这个后验概率。显然B包含多个特征,全考虑进去要怎么计算这个后验概率呢?显然直接计算是比较困难的,因为各个维度之间的数据可能存在相关性,还是买瓜的例子,我们在买瓜的时候,敲一敲,听声音下判断这是不是一个好瓜,或者再根据瓜的成色判断是不是一个好瓜,根据这两个综合判断这个瓜是不是一个好瓜,这实际上遵循了独立同分布的假设,也就是朴素贝叶斯模型所遵循的假设:各维度特征相互独立,各个样本之间相互独立。
在这个假设下,求解后验的概率公式就变成了:
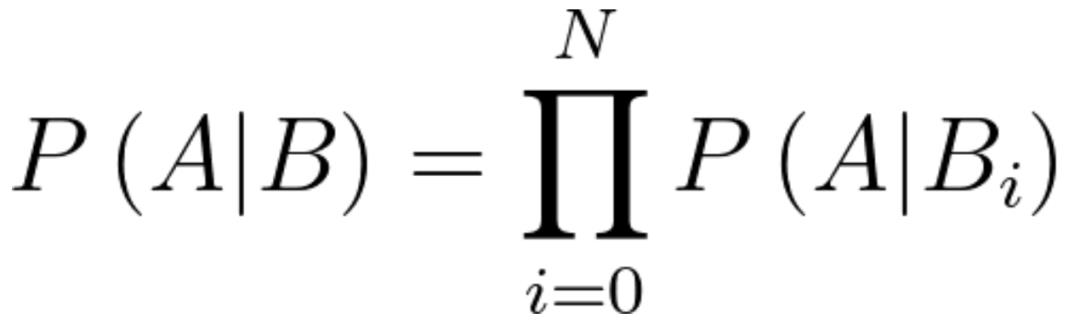
这样就大大简化了计算的方式。
基于朴素贝叶斯模型的文本情感分类
这部分介绍具体应用,我用python将朴素贝叶斯模型应用到了文本情感分类上。
采用的数据集:online_shopping_10_cats。这是个商品购物评论的数据集,包含了10个大类的数据,并对正负类进行了标注。

数据集是一个csv文件, saved_dict目录保存的是训练好的模型,stopwords.txt是停用词文件。
对于一个机器学习项目来说,大致分为四个部分模块:数据预处理、模型构建、模型训练、模型测试。
数据预处理
数据预处理大致分为以下步骤:读取数据、对数据进行分词、划分数据集、去除停用词。
下面给出读取数据的代码:
import pandas as pdfile_path = "your online_shopping_10_cats.csv file path"df = pd.read_csv(file_path)
我利用pandas读取csv文件数据,可以调用来查看:
print(df.head())运行后的结果如下所示:

接下来要对数据进行分词操作,因为是中文文本,所以要用到中文的分词器jieba库:
import jiebadef cn_tokenizer(text):'''cn_tokenizer方法, 中文分词器, 基于jieba分词:param text: 文本数据, type: string:return:分词后的结果, 词与词之间用空格分隔, type: string'''return " ".join(jieba.lcut(text))
这样只要调用pandas的apply方法就可以进行分词了。
X = pd.DataFrame(df['review'].astype(str)) # 提取df中的样本数据y = pd.DataFrame(df['label'].astype(str)) # 提取df中的标签数据# 分词操作X['cutted_review'] = X.review.apply(cn_tokenizer) # 分词后的样本数据
这部分也可以输出以下看一下:
print(X.head())对应结果如下所示:

这样就多了一列分词后的结果。
很多人到这一步可能会问,为什么要分词,因为对中文文本数据来说,每一个词对应样本的一个维度,如果追求更细的细粒度,那就是字级别。
然后就是划分数据集了,这里调用sklearn的train_test_split方法进行划分。
from sklearn.model_selection import train_test_split# 划分数据集X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
这样就得到了所需要的训练集和测试集。然后要去除文本中的停用词,为什么要去除停用词呢?因为输入的数据通常是冗余的,比如中文中的语气词等这些并不会是关键特征。这里使用https://github.com/goto456/stopwords中的哈工大的中文停用词。
# 加载停用词file_path = "your stopwords.txt file path"with open(file_path, 'r', encoding='utf-8') as f:stopwords = f.readlines()
此外还要知道,计算机比较容易处理数值型数据,对于文本数据,我们要对其进行向量化,这里用sklearn的CountVectorizer方法处理文本数据,这一步同时用上面加载的停用词数据去除了样本中的停用词。
from sklearn.feature_extraction.text import CountVectorizer# 文本特征向量化max_df = 0.8 # 在超过这一比例的文档中出现的关键词(过于平凡),去除掉。min_df = 3 # 在低于这一数量的文档中出现的关键词(过于独特),去除掉。vect = CountVectorizer(max_df=max_df,min_df=min_df,token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b',stop_words=frozenset(stopwords))
然后我们可以看下词项矩阵:
term_matrix = pd.DataFrame(vect.fit_transform(self.X_data.cutted_review).toarray(),columns=vect.get_feature_names())
输出这个矩阵看下:
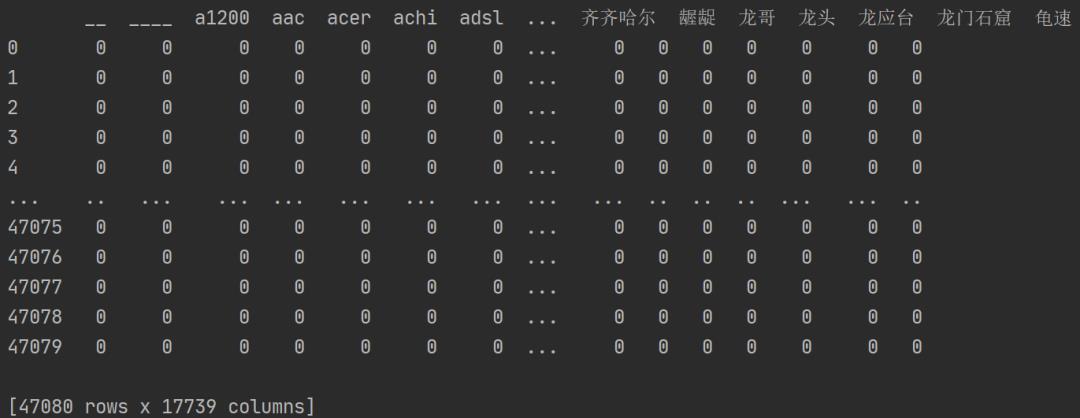
可以看到这个矩阵是一个很大的稀疏矩阵,每一列代表一个词,每一行对应一个样本,因为一个句子中,包含的词通常只有几十个的,相对于列维度的词袋来说,是很稀疏的,所以很多地方都是0,如果一个样本包含某个词,就对应1,这样就将字符型数据转换为了数值型,方便计算机计算处理,这种编码输入样本的方式称为one-hot编码。
我们也可以不用停用词,输出这个矩阵看下,对应代码:
可以看到列维度多了400左右的冗余词。
接下来就是构建模型了,根据朴素贝叶斯定理来自行构建该模型是比较简单的,只需要计算每个词下对应是正样本的概率和对应负样本的概率即可,python实现也只要几十行,这里用sklearn的朴素贝叶斯模型。
from sklearn.naive_bayes import MultinomialNBclf = MultinomialNB() # 实例化朴素贝叶斯模型pipe = make_pipeline(vect, clf) # 整合数据向量化和模型pipe.fit(X_train.cutted_review, y_train) # 训练或拟合数据
到此我们的模型构建和训练结束。接下来可以用测试集数据进行测试。
pred = pipe.predict(X_test.cutted_review)print("Acc: %.6f" % metrics.accuracy_score(y_pred, y_test))
然后我们可以统计下输出的结果准确率:
对于测试集数据达到了88.95%的分类准确率,也还是相当高的。
结语:
对于文本的处理采用的是one-hot编码,这种编码实际上将不同特征采用正交化考虑,不便于相似特征的计算,也是模型的一大缺陷之一,这一问题也由此引出了embedding这一重大工作,现在效果极好的分布式词嵌入方式就是embedding任务的成果。
以上是关于朴素贝叶斯模型——文本情感分类的主要内容,如果未能解决你的问题,请参考以下文章