第3章 第1节 处理分类问题常用算法
Posted Bugly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第3章 第1节 处理分类问题常用算法相关的知识,希望对你有一定的参考价值。
● 交叉熵公式
参考回答:
交叉熵:设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示: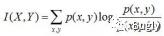
且有I(X,Y)=D(P(X,Y)||P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
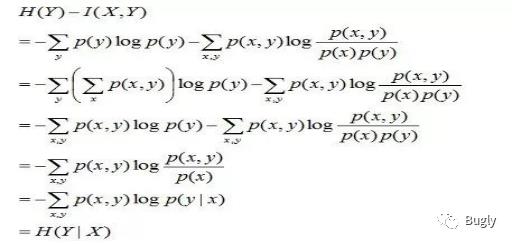
● LR公式
参考回答:
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。g(z)为sigmoid function.
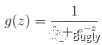
则
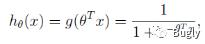
sigmoid function 的导数如下:
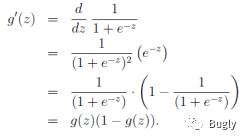
逻辑回归用来分类0/1 问题,也就是预测结果属于0 或者1 的二值分类问题。这里假设了二值满足伯努利分布,也就是
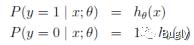
其也可以写成如下的形式:
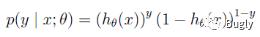
对于训练数据集,特征数据x={x1, x2, … , xm}和对应的分类标签y={y1, y2, … , ym},假设m个样本是相互独立的,那么,极大似然函数为:
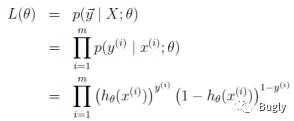
log似然为:
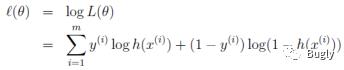
如何使其最大呢?与线性回归类似,我们使用梯度上升的方法(求最小使用梯度下降),那么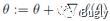
。
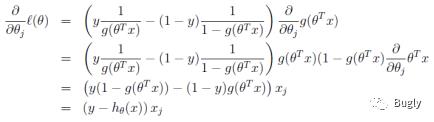
如果只用一个训练样例(x,y),采用随机梯度上升规则,那么随机梯度上升更新规则为:
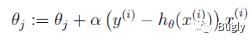
● LR的推导,损失函数
参考回答:
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。g(z)为sigmoid function.
则
sigmoid function 的导数如下:
逻辑回归用来分类0/1 问题,也就是预测结果属于0 或者1 的二值分类问题。这里假设了二值满足伯努利分布,也就是
其也可以写成如下的形式:
对于训练数据集,特征数据x={x1, x2, … , xm}和对应的分类标签y={y1, y2, … , ym},假设m个样本是相互独立的,那么,极大似然函数为:
log似然为:
如何使其最大呢?与线性回归类似,我们使用梯度上升的方法(求最小使用梯度下降),那么
。
如果只用一个训练样例(x,y),采用随机梯度上升规则,那么随机梯度上升更新规则为:
损失函数:
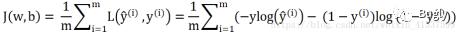
● 逻辑回归怎么实现多分类
参考回答:
方式一:修改逻辑回归的损失函数,使用softmax函数构造模型解决多分类问题,softmax分类模型会有相同于类别数的输出,输出的值为对于样本属于各个类别的概率,最后对于样本进行预测的类型为概率值最高的那个类别。
方式二:根据每个类别都建立一个二分类器,本类别的样本标签定义为0,其它分类样本标签定义为1,则有多少个类别就构造多少个逻辑回归分类器
若所有类别之间有明显的互斥则使用softmax分类器,若所有类别不互斥有交叉的情况则构造相应类别个数的逻辑回归分类器。
● SVM中什么时候用线性核什么时候用高斯核?
参考回答:
当数据的特征提取的较好,所包含的信息量足够大,很多问题是线性可分的那么可以采用线性核。若特征数较少,样本数适中,对于时间不敏感,遇到的问题是线性不可分的时候可以使用高斯核来达到更好的效果。
● 什么是支持向量机,SVM与LR的区别?
参考回答:
支持向量机为一个二分类模型,它的基本模型定义为特征空间上的间隔最大的线性分类器。而它的学习策略为最大化分类间隔,最终可转化为凸二次规划问题求解。
LR是参数模型,SVM为非参数模型。LR采用的损失函数为logisticalloss,而SVM采用的是hingeloss。在学习分类器的时候,SVM只考虑与分类最相关的少数支持向量点。LR的模型相对简单,在进行大规模线性分类时比较方便。
● 监督学习和无监督学习的区别
参考回答:
输入的数据有标签则为监督学习,输入数据无标签为非监督学习。
● 机器学习中的距离计算方法?
参考回答:
设空间中两个点为

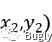
欧式距离:
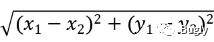
曼哈顿距离:
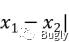
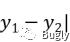
余弦距离:
cos=
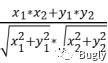
切比雪夫距离:max
● 问题:朴素贝叶斯(naive Bayes)法的要求是?
参考回答:
贝叶斯定理、特征条件独立假设
解析:朴素贝叶斯属于生成式模型,学习输入和输出的联合概率分布。给定输入x,利用贝叶斯概率定理求出最大的后验概率作为输出y。
● 问题:训练集中类别不均衡,哪个参数最不准确?
参考回答:
准确度(Accuracy)
解析:举例,对于二分类问题来说,正负样例比相差较大为99:1,模型更容易被训练成预测较大占比的类别。因为模型只需要对每个样例按照0.99的概率预测正类,该模型就能达到99%的准确率。
● 问题:你用的模型,最有挑战性的项目
参考回答:
在回答自己的模型时,必须要深入了解自己的模型细节以及其中用到知识(如:Bi-LSTM的优点以及与rnn和lstm的对比)的原理。
● 问题:SVM的作用,基本实现原理;
参考回答:
SVM可以用于解决二分类或者多分类问题,此处以二分类为例。SVM的目标是寻找一个最优化超平面在空间中分割两类数据,这个最优化超平面需要满足的条件是:离其最近的点到其的距离最大化,这些点被称为支持向量。
解析:建议练习推导SVM,从基本式的推导,到拉格朗日对偶问题。
● 问题:SVM的硬间隔,软间隔表达式;
参考回答:
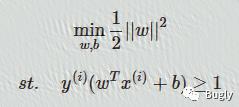
左边为硬间隔;右边为软间隔
解析:不同点在于有无引入松弛变量
● 问题:SVM使用对偶计算的目的是什么,如何推出来的,手写推导;
参考回答:
目的有两个:一是方便核函数的引入;二是原问题的求解复杂度与特征的维数相关,而转成对偶问题后只与问题的变量个数有关。由于SVM的变量个数为支持向量的个数,相较于特征位数较少,因此转对偶问题。通过拉格朗日算子发使带约束的优化目标转为不带约束的优化函数,使得W和b的偏导数等于零,带入原来的式子,再通过转成对偶问题。
● 问题:SVM的物理意义是什么;
参考回答:
构造一个最优化的超平面在空间中分割数据
● 问题:如果给你一些数据集,你会如何分类(我是分情况答的,从数据的大小,特征,是否有缺失,分情况分别答的);
参考回答:
根据数据类型选择不同的模型,如Lr或者SVM,决策树。假如特征维数较多,可以选择SVM模型,如果样本数量较大可以选择LR模型,但是LR模型需要进行数据预处理;假如缺失值较多可以选择决策树。选定完模型后,相应的目标函数就确定了。还可以在考虑正负样例比比,通过上下集采样平衡正负样例比。
解析:需要了解多种分类模型的优缺点,以及如何构造分类模型的步骤
● 问题:如果数据有问题,怎么处理;
参考回答:
1.上下采样平衡正负样例比;2.考虑缺失值;3.数据归一化
解析:发散问题需要自己展现自己的知识面
以上是关于第3章 第1节 处理分类问题常用算法的主要内容,如果未能解决你的问题,请参考以下文章