第3章 第4节 处理聚类问题常用算法
Posted Bugly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第3章 第4节 处理聚类问题常用算法相关的知识,希望对你有一定的参考价值。
● 什么是DBSCAN
参考回答:
DBSCAN是一种基于密度的空间聚类算法,它不需要定义簇的个数,而是将具有足够高密度的区域划分为簇,并在有噪声的数据中发现任意形状的簇,在此算法中将簇定义为密度相连的点的最大集合。
● k-means算法流程
参考回答:
从数据集中随机选择k个聚类样本作为初始的聚类中心,然后计算数据集中每个样本到这k个聚类中心的距离,并将此样本分到距离最小的聚类中心所对应的类中。将所有样本归类后,对于每个类别重新计算每个类别的聚类中心即每个类中所有样本的质心,重复以上操作直到聚类中心不变为止。
● LDA的原理
参考回答:
LDA是一种基于有监督学习的降维方式,将数据集在低维度的空间进行投影,要使得投影后的同类别的数据点间的距离尽可能的靠近,而不同类别间的数据点的距离尽可能的远。
● 介绍几种机器学习的算法,我就结合我的项目经理介绍了些RF, Kmeans等算法。
参考回答:
常见的机器学习算法:
1). 回归算法:回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。常见的回归算法包括:最小二乘法(Ordinary Least Square),逻辑回归(Logistic Regression),逐步式回归(Stepwise Regression),多元自适应回归样条(Multivariate Adaptive Regression Splines)以及本地散点平滑估计(Locally Estimated Scatterplot Smoothing)。
2). 基于实例的算法:基于实例的算法常常用来对决策问题建立模型,这样的模型常常先选取一批样本数据,然后根据某些近似性把新数据与样本数据进行比较。通过这种方式来寻找最佳的匹配。因此,基于实例的算法常常也被称为“赢家通吃”学习或者“基于记忆的学习”。常见的算法包括 k-Nearest Neighbor(KNN), 学习矢量量化(Learning Vector Quantization, LVQ),以及自组织映射算法(Self-Organizing Map,SOM)。深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
3). 决策树学习:决策树算法根据数据的属性采用树状结构建立决策模型, 决策树模型常常用来解决分类和回归问题。常见的算法包括:分类及回归树(Classification And Regression Tree,CART),ID3 (Iterative Dichotomiser 3),C4.5,Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 随机森林(Random Forest),多元自适应回归样条(MARS)以及梯度推进机(Gradient Boosting Machine,GBM)。
4). 贝叶斯方法:贝叶斯方法算法是基于贝叶斯定理的一类算法,主要用来解决分类和回归问题。常见算法包括:朴素贝叶斯算法,平均单依赖估计(Averaged One-Dependence Estimators,AODE),以及Bayesian Belief Network(BBN)。
5). 基于核的算法:基于核的算法中最著名的莫过于支持向量机(SVM)了。基于核的算法把输入数据映射到一个高阶的向量空间,在这些高阶向量空间里,有些分类或者回归问题能够更容易的解决。常见的基于核的算法包括:支持向量机(Support Vector Machine,SVM), 径向基函数(Radial Basis Function,RBF),以及线性判别分析(Linear Discriminate Analysis,LDA)等。
6). 聚类算法:聚类,就像回归一样,有时候人们描述的是一类问题,有时候描述的是一类算法。聚类算法通常按照中心点或者分层的方式对输入数据进行归并。所以的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 k-Means算法以及期望最大化算法(Expectation Maximization,EM)。
7). 降低维度算法:像聚类算法一样,降低维度算法试图分析数据的内在结构,不过降低维度算法是以非监督学习的方式试图利用较少的信息来归纳或者解释数据。这类算法可以用于高维数据的可视化或者用来简化数据以便监督式学习使用。常见的算法包括:主成份分析(Principle Component Analysis,PCA),偏最小二乘回归(Partial Least Square Regression,PLS),Sammon映射,多维尺度(Multi-Dimensional Scaling, MDS), 投影追踪(Projection Pursuit)等。
8). 关联规则学习:关联规则学习通过寻找最能够解释数据变量之间关系的规则,来找出大量多元数据集中有用的关联规则。常见算法包括 Apriori算法和Eclat算法等。
9). 集成算法:集成算法用一些相对较弱的学习模型独立地就同样的样本进行训练,然后把结果整合起来进行整体预测。集成算法的主要难点在于究竟集成哪些独立的较弱的学习模型以及如何把学习结果整合起来。这是一类非常强大的算法,同时也非常流行。常见的算法包括:Boosting,Bootstrapped Aggregation(Bagging),AdaBoost,堆叠泛化(Stacked Generalization,Blending),梯度推进机(Gradient Boosting Machine, GBM),随机森林(Random Forest)。
10). 人工神经网络:人工神经网络算法模拟生物神经网络,是一类模式匹配算法。通常用于解决分类和回归问题。人工神经网络是机器学习的一个庞大的分支,有几百种不同的算法。(其中深度学习就是其中的一类算法,我们会单独讨论),重要的人工神经网络算法包括:感知器神经网络(Perceptron Neural Network), 反向传递(Back Propagation),Hopfield网络,自组织映射(Self-Organizing Map, SOM)。学习矢量量化(Learning Vector Quantization, LVQ)。
RF:通过对训练数据样本以及属性进行有放回的抽样(针对某一个属性随机选择样本)这里有两种,一种是每次都是有放回的采样,有些样本是重复的,组成和原始数据集样本个数一样的数据集;另外一种是不放回的抽样,抽取出大约60%的训练信息。由此生成一颗CART树,剩下的样本信息作为袋外数据,用来当作验证集计算袋外误差测试模型;把抽取出的样本信息再放回到原数据集中,再重新抽取一组训练信息,再以此训练数据集生成一颗CART树。这样依次生成多颗CART树,多颗树组成森林,并且他们的生成都是通过随机采样的训练数据生成,因此叫随机森林。RF可以用于数据的回归,也可以用于数据的分类。回归时是由多颗树的预测结果求均值;分类是由多棵树的预测结果进行投票。正式由于它的随机性,RF有极强的防止过拟合的特性。由于他是由CART组成,因此它的训练数据不需要进行归一化,因为每课的建立过程都是通过选择一个能最好的对数据样本进行选择的属性来建立分叉,因此有以上好处的同时也带来了一个缺点,那就是忽略了属性与属性之间的关系。
K-meas:基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,知道质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
初始化常数K,随机选取初始点为质心
重复计算一下过程,直到质心不再改变
计算样本与每个质心之间的相似度,将样本归类到最相似的类中
重新计算质心
输出最终的质心以及每个类
● KMeans讲讲,KMeans有什么缺点,K怎么确定
参考回答:
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;重新计算k个cluser对应的质心;
until 质心不再发生变化
k-means存在缺点:
1)k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果。
2)同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
K值得确定:
法1:(轮廓系数)在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分聚类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
法2:(Calinski-Harabasz准则)
其中SSB是类间方差,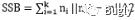 ,m为所有点的中心点,mi为某类的中心点;
,m为所有点的中心点,mi为某类的中心点;
SSW是类内方差,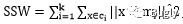 ;
;
(N-k)/(k-1)是复杂度;
比率越大,数据分离度越大。
● Kmeans
参考回答:
基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,知道质心不再改变,最终就确定了每个样本所属的类别以及每个类的质心。由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
初始化常数K,随机选取初始点为质心
重复计算一下过程,直到质心不再改变
计算样本与每个质心之间的相似度,将样本归类到最相似的类中
重新计算质心
输出最终的质心以及每个类
● DBSCAN原理和算法伪代码,与kmeans,OPTICS区别
参考回答:
DBSCAN聚类算法原理
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法,它是一种基于高密度连通区域的、基于密度的聚类算法,能够将具有足够高密度的区域划分为簇,并在具有噪声的数据中发现任意形状的簇。我们总结一下DBSCAN聚类算法原理的基本要点:
DBSCAN算法需要选择一种距离度量,对于待聚类的数据集中,任意两个点之间的距离,反映了点之间的密度,说明了点与点是否能够聚到同一类中。由于DBSCAN算法对高维数据定义密度很困难,所以对于二维空间中的点,可以使用欧几里德距离来进行度量。
DBSCAN算法需要用户输入2个参数:一个参数是半径(Eps),表示以给定点P为中心的圆形邻域的范围;另一个参数是以点P为中心的邻域内最少点的数量(MinPts)。如果满足:以点P为中心、半径为Eps的邻域内的点的个数不少于MinPts,则称点P为核心点。
DBSCAN聚类使用到一个k-距离的概念,k-距离是指:给定数据集P={p(i); i=0,1,…n},对于任意点P(i),计算点P(i)到集合D的子集S={p(1), p(2), …, p(i-1), p(i+1), …, p(n)}中所有点之间的距离,距离按照从小到大的顺序排序,假设排序后的距离集合为D={d(1), d(2), …, d(k-1), d(k), d(k+1), …,d(n)},则d(k)就被称为k-距离。也就是说,k-距离是点p(i)到所有点(除了p(i)点)之间距离第k近的距离。对待聚类集合中每个点p(i)都计算k-距离,最后得到所有点的k-距离集合E={e(1), e(2), …, e(n)}。
根据经验计算半径Eps:根据得到的所有点的k-距离集合E,对集合E进行升序排序后得到k-距离集合E’,需要拟合一条排序后的E’集合中k-距离的变化曲线图,然后绘出曲线,通过观察,将急剧发生变化的位置所对应的k-距离的值,确定为半径Eps的值。
根据经验计算最少点的数量MinPts:确定MinPts的大小,实际上也是确定k-距离中k的值,DBSCAN算法取k=4,则MinPts=4。
另外,如果觉得经验值聚类的结果不满意,可以适当调整Eps和MinPts的值,经过多次迭代计算对比,选择最合适的参数值。可以看出,如果MinPts不变,Eps取得值过大,会导致大多数点都聚到同一个簇中,Eps过小,会导致已一个簇的分裂;如果Eps不变,MinPts的值取得过大,会导致同一个簇中点被标记为噪声点,MinPts过小,会导致发现大量的核心点。
我们需要知道的是,DBSCAN算法,需要输入2个参数,这两个参数的计算都来自经验知识。半径Eps的计算依赖于计算k-距离,DBSCAN取k=4,也就是设置MinPts=4,然后需要根据k-距离曲线,根据经验观察找到合适的半径Eps的值,下面的算法实现过程中,我们会详细说明。对于算法的实现,首先我们概要地描述一下实现的过程:
1)解析样本数据文件。2)计算每个点与其他所有点之间的欧几里德距离。3)计算每个点的k-距离值,并对所有点的k-距离集合进行升序排序,输出的排序后的k-距离值。4)将所有点的k-距离值,在Excel中用散点图显示k-距离变化趋势。5)根据散点图确定半径Eps的值。)根据给定MinPts=4,以及半径Eps的值,计算所有核心点,并建立核心点与到核心点距离小于半径Eps的点的映射。7)根据得到的核心点集合,以及半径Eps的值,计算能够连通的核心点,得到噪声点。8)将能够连通的每一组核心点,以及到核心点距离小于半径Eps的点,都放到一起,形成一个簇。9)选择不同的半径Eps,使用DBSCAN算法聚类得到的一组簇及其噪声点,使用散点图对比聚类效果。
算法伪代码:
算法描述:
算法:DBSCAN
输入:E——半径
MinPts——给定点在E邻域内成为核心对象的最小邻域点数。
D——集合。
输出:目标类簇集合
方法:Repeat
1)判断输入点是否为核心对象
2)找出核心对象的E邻域中的所有直接密度可达点。
Until 所有输入点都判断完毕
Repeat
针对所有核心对象的E邻域内所有直接密度可达点找到最大密度相连对象集合,中间涉及到一些密度可达对象的合并。Until 所有核心对象的E领域都遍历完毕
DBSCAN和Kmeans的区别:
1)K均值和DBSCAN都是将每个对象指派到单个簇的划分聚类算法,但是K均值一般聚类所有对象,而DBSCAN丢弃被它识别为噪声的对象。
2)K均值使用簇的基于原型的概念,而DBSCAN使用基于密度的概念。
3)K均值很难处理非球形的簇和不同大小的簇。DBSCAN可以处理不同大小或形状的簇,并且不太受噪声和离群点的影响。当簇具有很不相同的密度时,两种算法的性能都很差。
4)K均值只能用于具有明确定义的质心(比如均值或中位数)的数据。DBSCAN要求密度定义(基于传统的欧几里得密度概念)对于数据是有意义的。
5)K均值可以用于稀疏的高维数据,如文档数据。DBSCAN通常在这类数据上的性能很差,因为对于高维数据,传统的欧几里得密度定义不能很好处理它们。
6)K均值和DBSCAN的最初版本都是针对欧几里得数据设计的,但是它们都被扩展,以便处理其他类型的数据。
7)基本K均值算法等价于一种统计聚类方法(混合模型),假定所有的簇都来自球形高斯分布,具有不同的均值,但具有相同的协方差矩阵。DBSCAN不对数据的分布做任何假定。
8)K均值DBSCAN和都寻找使用所有属性的簇,即它们都不寻找可能只涉及某个属性子集的簇。
9)K均值可以发现不是明显分离的簇,即便簇有重叠也可以发现,但是DBSCAN会合并有重叠的簇。
10)K均值算法的时间复杂度是O(m),而DBSCAN的时间复杂度是O(m^2),除非用于诸如低维欧几里得数据这样的特殊情况。
11)DBSCAN多次运行产生相同的结果,而K均值通常使用随机初始化质心,不会产生相同的结果。
12)DBSCAN自动地确定簇个数,对于K均值,簇个数需要作为参数指定。然而,DBSCAN必须指定另外两个参数:Eps(邻域半径)和MinPts(最少点数)。
13)K均值聚类可以看作优化问题,即最小化每个点到最近质心的误差平方和,并且可以看作一种统计聚类(混合模型)的特例。DBSCAN不基于任何形式化模型。
DBSCAN与OPTICS的区别:
DBSCAN算法,有两个初始参数E(邻域半径)和minPts(E邻域最小点数)需要用户手动设置输入,并且聚类的类簇结果对这两个参数的取值非常敏感,不同的取值将产生不同的聚类结果,其实这也是大多数其他需要初始化参数聚类算法的弊端。
为了克服DBSCAN算法这一缺点,提出了OPTICS算法(Ordering Points to identify the clustering structure)。OPTICS并 不显示的产生结果类簇,而是为聚类分析生成一个增广的簇排序(比如,以可达距离为纵轴,样本点输出次序为横轴的坐标图),这个排序代表了各样本点基于密度 的聚类结构。它包含的信息等价于从一个广泛的参数设置所获得的基于密度的聚类,换句话说,从这个排序中可以得到基于任何参数E和minPts的DBSCAN算法的聚类结果。
OPTICS两个概念:
核心距离:对象p的核心距离是指是p成为核心对象的最小E’。如果p不是核心对象,那么p的核心距离没有任何意义。
可达距离:对象q到对象p的可达距离是指p的核心距离和p与q之间欧几里得距离之间的较大值。如果p不是核心对象,p和q之间的可达距离没有意义。
算法描述:OPTICS算法额外存储了每个对象的核心距离和可达距离。基于OPTICS产生的排序信息来提取类簇。
以上是关于第3章 第4节 处理聚类问题常用算法的主要内容,如果未能解决你的问题,请参考以下文章