OpenCV中那些深度学习模块
Posted LiveVideoStack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV中那些深度学习模块相关的知识,希望对你有一定的参考价值。
OpenCV是计算机视觉领域使用最为广泛的开源库,以功能全面使用方便著称。自3.3版本开始,OpenCV加入了对深度神经网络(DNN)推理运算的支持。在LiveVideoStack线上交流分享中英特尔亚太研发有限公司开源技术中心软件工程师 吴至文详细介绍了OpenCV DNN模块的现状,架构,以及加速技术。
文 / 吴至文
整理 / LiveVideoStack
直播回放
https://www2.tutormeetplus.com/v2/render/playback?mode=playback&token=846e0ba66b954f43834086dec24ae492
注:文中的ppt是作者在Embedded Linux Conference 2018上的演讲“Deep Learning in OpenCV”的ppt
大家好,我是吴至文,目前就职于英特尔开源技术中心,主要从事图形、图像深度学习算法方面的开发和优化工作。很高兴有机会和大家分享一下关于OpenCV深度学习模块的内容,同时,也会介绍一下我们团队在OpenCV深度学习方面所做的一些工作。
本次分享的主要内容包含以下几个方面:

首先,我会介绍一下OpenCV和深度学习的背景知识;然后,介绍今天的主题——OpenCV深度学习模块;接下来,会简单介绍我们团队在OpenCL加速方面所做的工作,以及开发的一个Vulkan后端;最后,会以一个例子的形式来展示如何使用DNN模块开发深度神经网络的应用。
一, OpenCV背景介绍

首先,什么是OpenCV呢?我相信做过图形图像、计算机视觉应用开发的同学可能对OpenCV都不会陌生。OpenCV是一个包含了2500多个经过优化的计算机视觉和机器学习算法的开源计算机视觉库。换句话说,目前主流的、比较知名的计算机视觉算法和论文在OpenVC里都能找到相应的实现。OpenCV不仅仅是一个很好用的开发工具集,它同时对有志于学习计算机视觉开发的学生也是一个宝库。OpenVC支持C、C++和Python语言,但是从OpenCV 4.0开始,C语言的API就逐渐被清除出去了,现在比较常用的API是C++和Python语言的。此外,OpenCV也是一个很活跃的开源项目,到目前为止它在Github上有两万多个Forks。

2018年11月份,OpenCV发布了4.0的版本。在这个版本有了比较大的变化,大概有以下这几点:首先,它使用了C++11标准编译器,并且移除了大多数的C 语言的API接口;另外,它不再对之前的版本有二进制的兼容,同时它使用了大量AVX2的指令集优化,从而大大提高了一些算法在CPU上的运行效率;再者就是,它具有更小的内存占用以及支持OpenVINO作为DNN模块的后端。OpenVINO对于有的同学可能比较陌生,它是英特尔发布的一个针对深度学习视觉应用的SDK。OpenVINO支持各种设备上的加速,包括CPU、GPU和VPU上面的加速,我们在后面还会提及这个内容。
二, 深度神经网络的关键概念
接下来,我将介绍一些深度神经网络的关键概念。
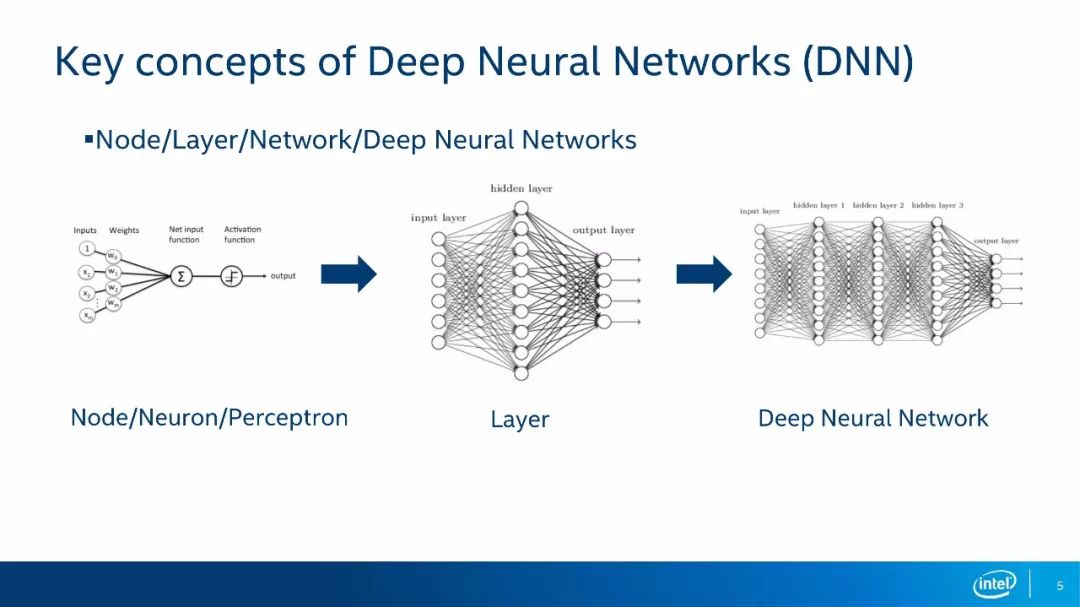
深度神经网络最基本的组成单元是神经元,我们在文献中一般称作Node、 Neuron或Perceptron。一个神经元会对多个输入进行加权和的运算,然后经过一个激活函数,最后输出一个响应结果。多个神经元就组成了网络的层,我们将神经网络的第一层称为输入层,一般用来加载输入数据,如一幅图像。我们将神经网络的最后一层称为输出层,根据具体网络结构的不同,输出层的含义也会不同。以分类网络为例,输出层的每个节点表示属于某个类别的概率大小。我们将在输入层和输出层之间的层称为隐层,所谓的深度神经网络就是隐层数大于1的神经网络。

接下来是网络训练。我们可以把神经网络看成一个复杂的函数,在这个函数里有许多参数是未知的,因此我们需要通过训练来确定这些参数。为了方便理解,我把训练大体分为四个步骤:第一步,选定训练参数,如学习比例、批次大小、损失函数类型,初始化网络权重;第二步、设置输入数据,然后进行前向的网络运算;第三步、比较运算结果和真实结果的差异;第四步、进行反向传播运算,然后修改网络参数,再回到第二步直到差异足够小,或者人为终止训练过程。虽然整个训练过程看起来比较复杂,但是深度学习框架会帮我们把这些事完成的,深度学习框架有Tensorflow、Caffe和Torch等。因此,我们只需要设计好网络结构、选定训练参数,剩下的事就可以交给框架去做。

在通过足够的训练之后,我们就可以确定所有的网络参数,那么这个复杂的函数就可以确定了。然后,我们输入数据来通过深度学习库计算函数结果的过程就叫推理。与训练相比,推理过程简单的多。上图罗列了几个使用了深度神经网络的计算机视觉应用场景,如人脸识别、对象语义分割以及目标检测的应用。
三, OpenCV深度学习模块

从OpenCV 3.3版本开始,OpenCV加入了深度学习模块,但这个模块它只提供推理功能,而不涉及训练,与此同时它支持多种深度学习框架,比如Tensorflow,Caffe,Torch和Darknet。

听到这里,可能有的同学会问:“既然我们已经有了Tensorflow、Caffe、Torch这些深度学习框架,为什么还要在OpenCV中再实现一个呢?这是不是在重复造轮子呢?”其实不是的,有下面几个理由:第一、轻量,由于DNN模块只实现了推理功能,它的代码量、编译运行开销与其他深度学习框架比起来会少很多;第二、方便使用,DNN模块提供了内建的CPU和GPU加速且无须依赖第三方库,如果在之前项目使用了OpenCV,那么通过DNN模块可以很方便的无缝的为原项目添加神经网络推理能力;第三、通用性,DNN模块支持多种网络模型格式,因此用户无须额外进行网络模型的转换就可以直接使用,同时它还支持多种运算设备和操作系统,比如CPU、GPU、VPU等,操作系统包括Linux、Windows、安卓和MacOS。

目前,OpenCV的DNN模块支持40多种层的类型,基本涵盖了常见的网络运算需求,而且新的类型也在不断的加入当中。

如上图所示,这里列出的网络架构都是经过了很好的测试。它们在OpenCV中能很好支持的,基本涵盖了常用的对象检测和语义分割的类别,我们可以直接拿来使用。
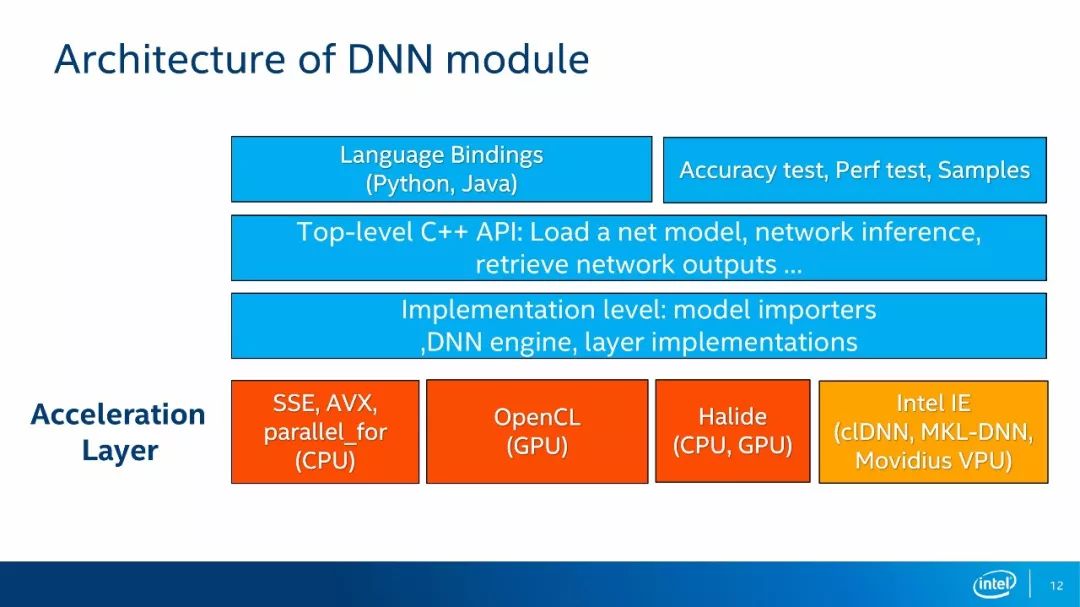
接下来给大家介绍DNN模块的架构。如上图所示,从而往下,第一层是语言绑定,它支持Python和Java,其中Python用的比较多,因为开发起来会比较方便。此外,在第一层中还包括准确度测试、性能测试以及一些示例程序。第二层是C++的API层,这属于是原生的API,它的功能包括加载网络模型、推理运算以及获取网络输出。第三层是实现层,它包括模型转换器、DNN引擎、层实现等。模型转换器负责将各种网络模型格式转换成DNN模块内部的表示,DNN引擎负责内部网络的组织和优化,层实现是各种层运算的具体实现过程。第四层是加速层,它包括CPU加速、GPU加速、Halide加速和新加入的Intel推理引擎加速。前三个均是DNN模块的内建实现,无须外部依赖就直接可以使用。CPU加速用到了SSE和AVX指令以及大量的多线程元语,而OpenCL加速是针对GPU进行并行运算的加速,这也是我们团队工作的主要内容。Halide是一个实验性的实现,并且性能一般,因此不建议使用。Intel推理引擎加速需要安装OpenVINO库,它可以实现在CPU、GPU和VPU上的加速,在GPU上内部会调用clDNN库来做GPU上的加速,在CPU上内部会调用MKL-DNN来做CPU加速,而Movidius主要是在VPU上使用的专用库来进行加速。
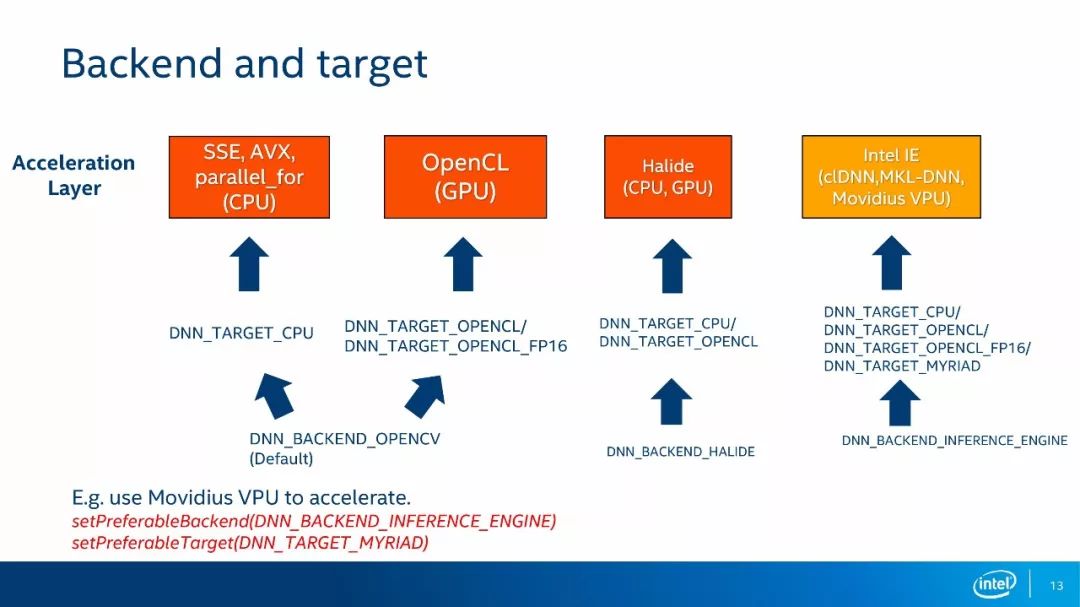
DNN模块采用Backend和Target来管理各种加速方法。Backend分为三种类型:第一种是OpenCV Backend,这是OpenCV默认的Backend;第二种是Halide Backend,第三种是推理引擎Backend。Target指的是最终的运算设备,它包括四种类型,分别是CPU设备、OpenCL设备、OpenCL_FP16设备以及MYRIAD设备。强调一下,OpenCL和OpenCL_FP16实际上都是GPU设备,OpenCL_FP16设备指的是权重值的数据格式为16位浮点数,OpenCL设备指的是权重值的数据格式为32位浮点数。MYRIAD设备是Movidius公司提供的VPU设备。我们通过Backend和Target的不同组合可以来决定具体的加速方法。举个例子,如果你有Movidius的运算棒,则可以通过SetPreferobleBackend API将Backend设置成Inference-NEGINE,通过SetPreferobleTarget API将Target设置成MYRIAD,然后你的网络运算将会在MYRIAD设备上进行,而不再用任何的CPU资源。

除了上述的加速后端外,DNN模块还做了一些网络层面的优化。由于在内部使用了统一的网络表示,网络层级的优化对DNN支持的所有格式的网络模型都有好处。下面介绍两种网络层级的优化方法:
一)层融合
第一种优化方法是层融合的优化。它是通过对网络结构的分析,把多个层合并到一起,从而降低网络复杂度和减少运算量。下面举几个具体的例子:
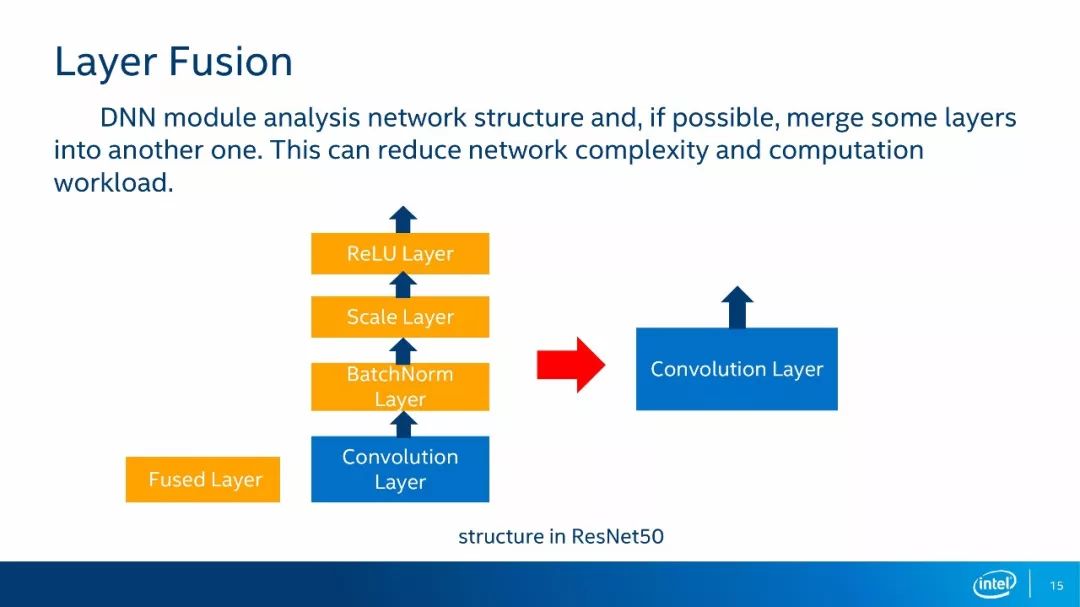
如上图所示,在本例中黄色方框代表的是最终被融合掉的网络层,在这种情况下,卷积层后面的BatchNorm层、Scale层和RelU层都被合并到了卷积层当中。这样一来,四个层运算最终变成了一个层运算,这种结构多出现在ResNet50的网络架构当中。
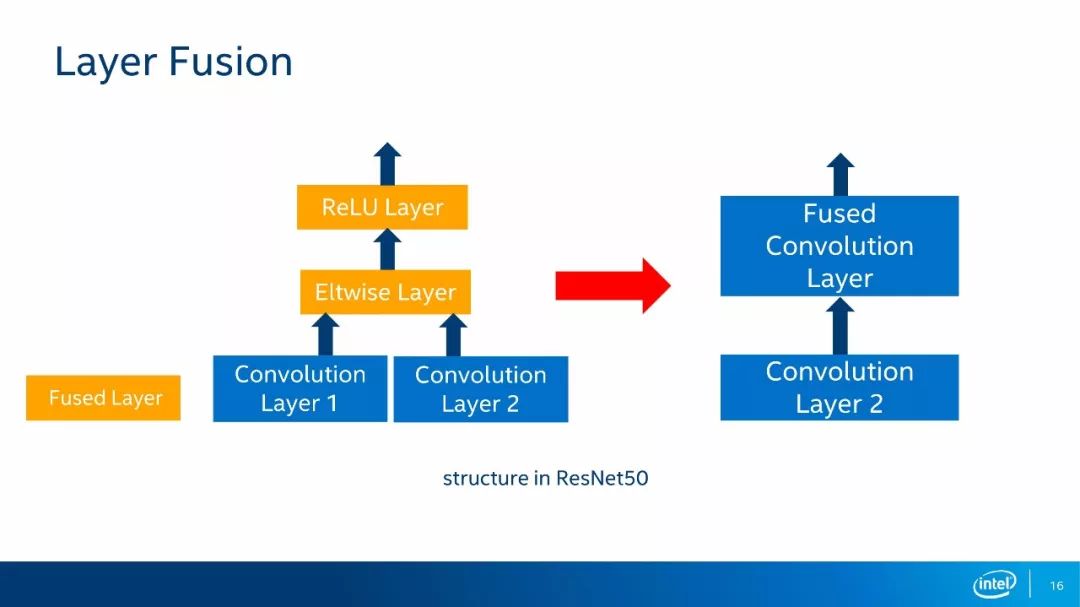
如上图所示,在本例中,网络结构将卷积层1和Eltwise Layer和RelU Layer合并成一个卷积层,将卷积层2作为第一个卷积层新增的一个输入。这样一来,原先的四个网络层变成了两个网络层运算,这种结构也多出现于ResNet50的网络架构当中。
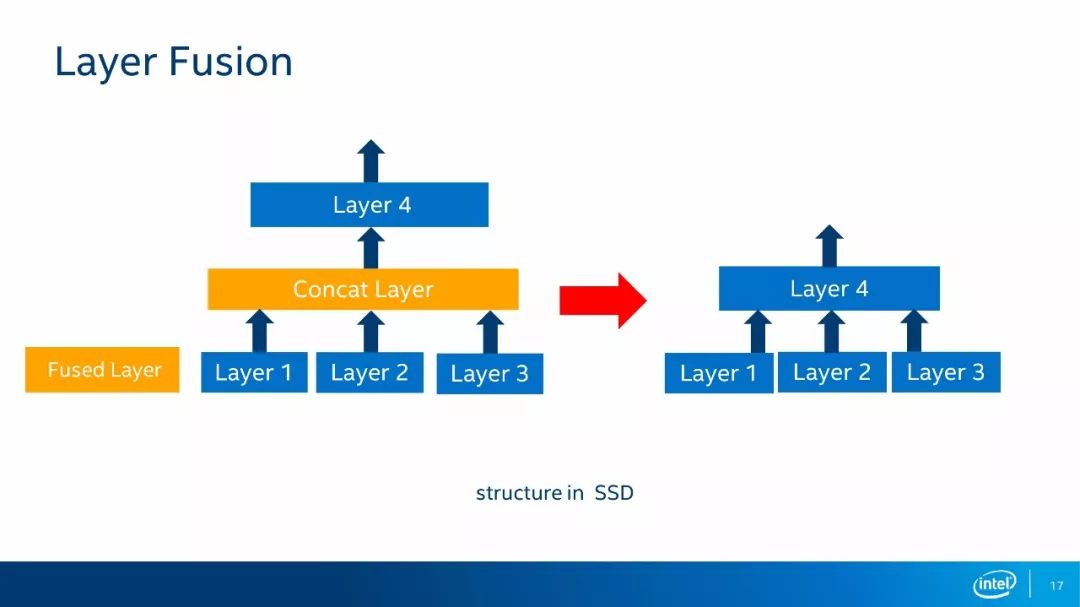
如上图所示,在本例中,这种网络结构是把三个层的输出通过连接层连接之后输入到后续层,这种情况可以把中间的连接层直接去掉,将三个网络层输出直接接到第四层的输入上面,这种网络结构多出现SSD类型的网络架构当中。
二)内存复用
第二种优化方式是内存复用的优化。深度神经网络运算过程当中会占用非常大量的内存资源,一部分是用来存储权重值,另一部分是用来存储中间层的运算结果。我们考虑到网络运算是一层一层按顺序进行的,因此后面的层可以复用前面的层分配的内存。

上图是一个没有经过优化的内存重用的运行时的存储结构,红色块代表的是分配出来的内存,绿色块代表的是一个引用内存,蓝色箭头代表的是引用方向。数据流是自下而上流动的,层的计算顺序也是自下而上进行运算。每一层都会分配自己的输出内存,这个输出被后续层引用为输入。对内存复用也有两种方法:
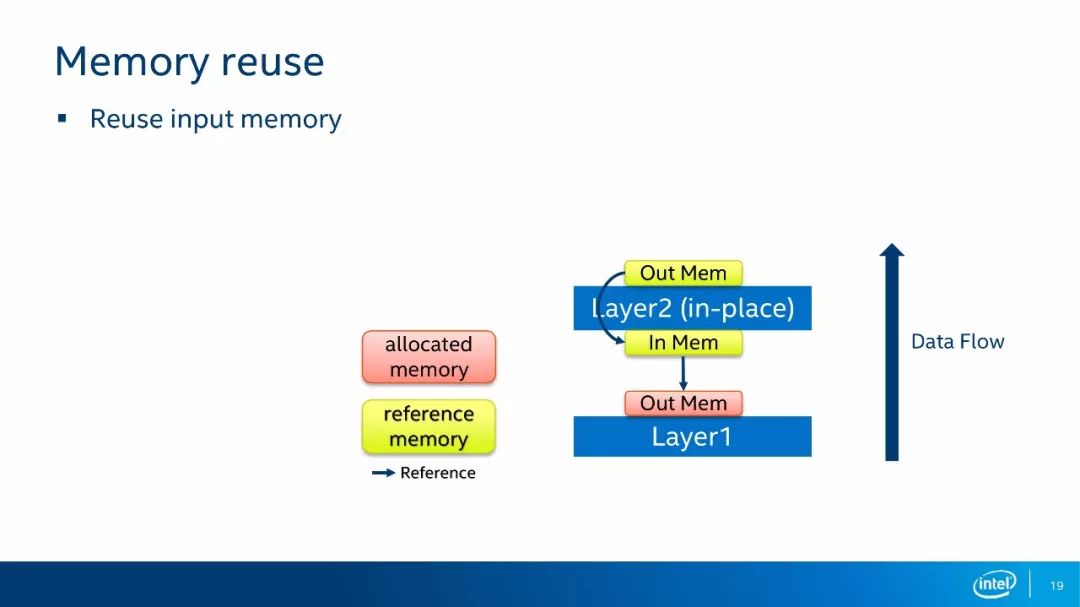
第一种内存复用的方法是输入内存复用。如上图所示,如果我们的层运算是一个in-place模式,那么我们无须为输出分配内存,直接把输出结果写到输入的内存当中即可。in-place模式指的是运算结果可以直接写回到输入而不影响其他位置的运算,如每个像素点做一次Scale的运算。类似于in-place模式的情况,就可以使用输入内存复用的方式。
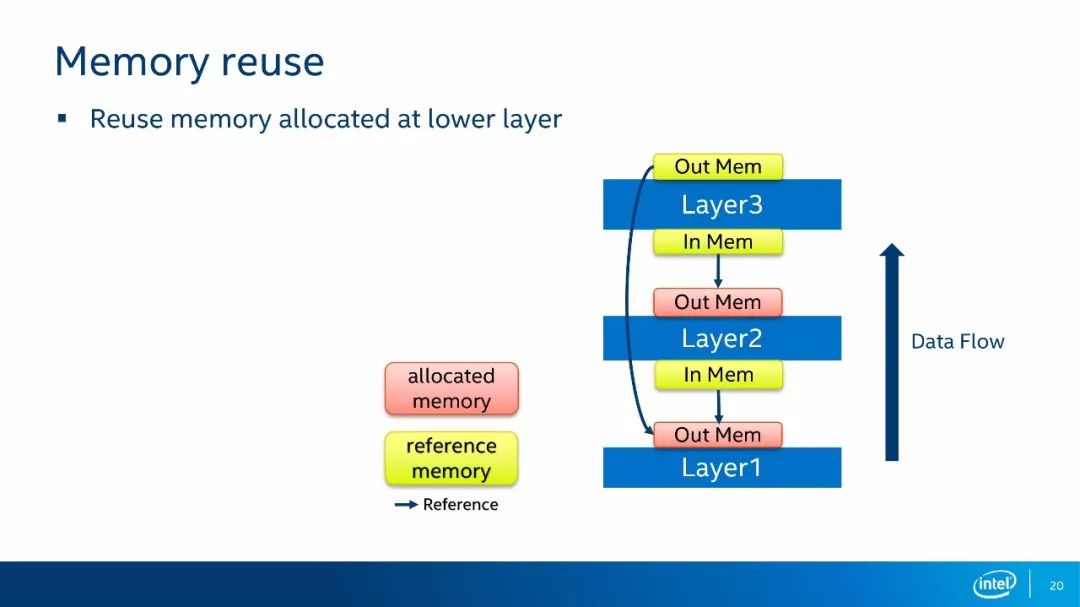
第二种内存复用的方法是后续层复用前面层的输出。如上图所示,在这个例子中,Layer3在运算时,Layer1和Layer2已经完成了运算。此时,Layer1的输出内存已经空闲下来,因此,Layer3不需要再分配自己的内存,直接引用Layer1的输出内存即可。由于深度神经网络的层数可以非常多,这种复用情景会大量的出现,使用这种复用方式之后,网络运算的内存占用量会下降30%~70%。
接下来,我会为大家介绍一下我们团队在深度学习模块中做的一些工作。
四, OpenCL加速

OpenCL的加速是一个内建的加速实现,它是可以直接使用而不依赖与外部加速库的,只需安装有OpenCL的运行时环境即可。此外,它还支持32位浮点数据格式和16位浮点数据格式。如果我们想要使用OpenCL加速,只需要把Backend设置成OpenCV,把Target设置成OpenCL或者OpenCL_FP16即可。

在OpenCL的加速方案中,我们提供了一组经过高度优化的卷积运算和auto-tuning方案,来为特定的GPU和卷积运算找到最佳的卷积核。简单地说,auto-tuning方案针对每个卷积任务,会选择不同的子块大小进行运算,然后选出用时最短的子块大小来作为卷积和的配置。DNN模块中内置了一些已经设好的卷积和配置,用户也可以为自己的网络和GPU重新运行一次auto-tuning,从而找到最佳的卷积核。如果想要设置auto-tuning,则需要设置环境变量OpenCV_OCL4DNN_CONFIG_PATH,让它指向一个可写的目录。这样一来,DNN模块就会把最佳的卷积核配置存储在这个目录下。注意,如果打开了auto-tuing,那么第一次运行某个网络模型的时间就会比较长。

对于OpenCL的驱动,我们建议使用Neo。Neo是开源Intel GPU的OpenCL驱动,它支持Gen 8以及Gen 8之后的英特尔GPU。我们建议尽量使用最新的版本,根据我们的调试经验,越新的版本性能越好。
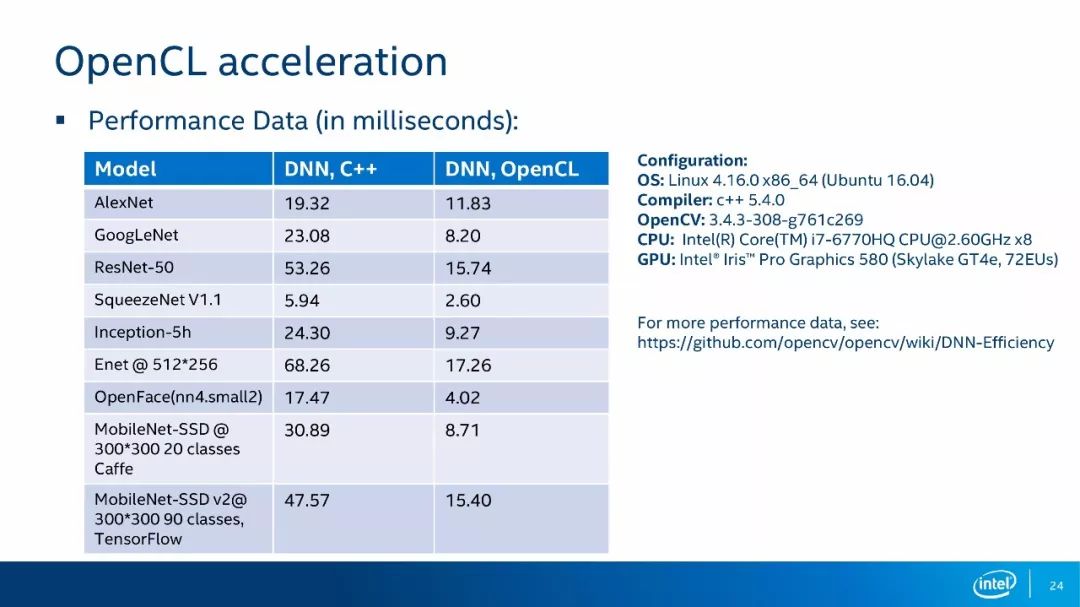
最后,上图是一个CPU和GPU加速的对比图,其中一列是OpenCL的加速,其中另一列是C++的加速。CPU是i7-6770、8核、2.6G,GPU是Iris Pro Graphics 580的,这种CPU和GPU都算是比较强劲的配置。 我们可以看到,OpenCL加速之后的运算时间比CPU会短很多,但也不是所有的情况都是这样的。对于不同的CPU,这个数据有所不同,大家可以通过上面的网站链接查看到在其他CPU配置下的CPU和GPU运算时间的对比。
五, Vulkan后端
Vulkan后端是由我开发的一个基于Vulkan Computer Shade的 DNN加速方案,目前已经合并到OpenCV的主分支,OpenCV 4.0里就包含有Vulkan backend,感兴趣的同学可以通过上图的链接了解一下技术细节。

如果要使用Vulkan backend,将backend类型设置成VKCOM,将target设置成Vulkan即可。Vulkan后端可以让DNN模块在更多的平台上使用到GPU的加速。例如,安卓系统中是不支持OpenCL的,但是它支持Vulkan,这种情况就可以通过Vulkan backend来加速。
六, 应用实例

最后一部分,这是一个通过DNN开发的用于对象检测的端到端的应用,下面我会分部分来详细讲解这些代码段。

在这里使用的是Python的接口,采用Python语言来开发,模型使用的是MobileNetSSD模型。首先,引入OpenCV的Python包,代码第2行、第4行、第5行则是指定MobileNetSSD的模型以及它的Graph描述文件。然后,设置输入Image的大小为300*300,置信度阈值设置为0.5,第9行的均值是用来做图像域处理的一个数值。第10行是可分类的类别,说明我们的MobileNETSSD是一个可以对20个类别进行分类的模型,我们也可以有97或者1000个类别的模型,但是那样的模型会比较大。第16行则是打开一个Camera设备采集图像。

从第19行到第26行就是所有的DNN相关的代码段,可以看到使用起来是非常简单的。第19行是加载网络模型,并返回一个网络对象。从第20行开始进入一个while循环,逐帧处理摄像头读入的数据。第22行是读入的数据,第23行是对这个读入的Image做Resize,让它符合网络模型对输入数据的大小要求。第24行是调用DNN模块的BlobFromImage API对输入的Image做预处理,这里主要是对输入数据做规则化处理,即先减均值,再乘以一个Scale。这些都是MobileNETSSD网络在训练中引入的均值和Scale,在推理中也需要把它用作输入Image的预处理,我们将处理好的数据称为blob。在第25行把这个blob设置为网络的输入,第26行来调用网络的Forward做推理预算,然后得到最终的输出结果Detections,Detections记录了在这一帧图像中检测出来的所有对象,并且每个对象会以一个Vector的形式来描述。
接下来,在这个循环中对每一个对象进行可视化处理,也就是把检测出来的对象描绘在原图像上。在第47行是取出对象的置信值与之前设置的阈值进行比较,如果超过了阈值,我们就判定它是一个可信的对象,将其绘制到原图上面。接下来的代码段就是绘制对象的代码段以及绘制对象类别的代码段,最后是将绘制好对象方框的原图显示出来,随后整个程序结束。在OpenCV的代码库当中有许多基于DNN的示例程序,包括C++、Python,大家感兴趣则可以在上面的链接中去看一下。
点击【阅读原文】或扫描图中二维码了解更多LiveVideoStackCon 2019 上海 音视频技术大会 日程信息。
以上是关于OpenCV中那些深度学习模块的主要内容,如果未能解决你的问题,请参考以下文章
巨详细!使用OpenCV和OpenVINO轻松创建深度学习应用
使用OpenCV在图像和视频流中执行基于深度学习的超级分辨率