利用OpenCV DNN模块进行深度学习:一个最好使用指导书
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用OpenCV DNN模块进行深度学习:一个最好使用指导书相关的知识,希望对你有一定的参考价值。

本文根据 Deep Learning with OpenCV DNN Module: A Definitive Guide 中相关内容进行整理而得,用于今后的学习和工程。
§00 前 言
机器视觉研究领域从上个世纪六十年后期就已创立。图像分类和物体检测是计算机视觉领域中的一些最古老的的问题,研究者为解决它进行了几十年的努力。基于神经网络和深度学习计算机在某些领域中对图像的认识和理解已经达到了很高的精度,谁知在一些场合超过了人类。OpenCV中的DNN是学习神经网络和深度学校的非常棒的起点。由于OpenCV针对CPU进行算法性能上的提升,计时用户没有强大的GPU 也能够非常容易的开始。
希望这个博文能够成为你学习深度学习算法的好的起点。

▲ 图1 使用OpenCV中的DNN模块基于深度学习实现图像分类和目标检测的示例图像
除了理论部分,我们还提供了基于OpenCV DNN的动手实验经验。下面会讨论图片以及实时视频中的分类、物体检测算法细节。
下面让我们进入OpenCV DNN模块实现深度学习解决机器视觉问题。
§01 OpenCVDNN模块
我们知道OpenCV 是机器视觉最好的算法库。此外它还能够运行深度学习推理的功能。最棒的部分就是可以从不同的学习框架中加载不同的模型,通过它可以实现多个深度学习功能。 从OpenCV 3.3版本之后就提供了加载不同学习框架模型的支持。当然现在还有很多新的用户并没有注意到OpenCV这个超级棒的特性,这样就可能丢失很多有趣和良好的学习机遇。
1.1 为什么选择OpenCV DNN模块?
OpenCV只是支持图片和视频的深度学习推理,它并不只是模型的细调和训练。尽管如此,OpenCV DNN模块仍然可以作为初学者涉足机器视觉深度学习的非常快的起始点,进行鼓捣相关的算法。
OpenCV 的DNN模块中的 一个非常厉害之处就是针对Intel处理器进行了高度优化。在目标检测和图像分割应用中,对于实时视频图像进行模型推理的过程中可以获得很好的处理帧速(FPS)。通过DNN模块使用特定框架下预训练模型经常会得到更高的FPS。比如我们可以对比不同框架下的图像分类处理速度。
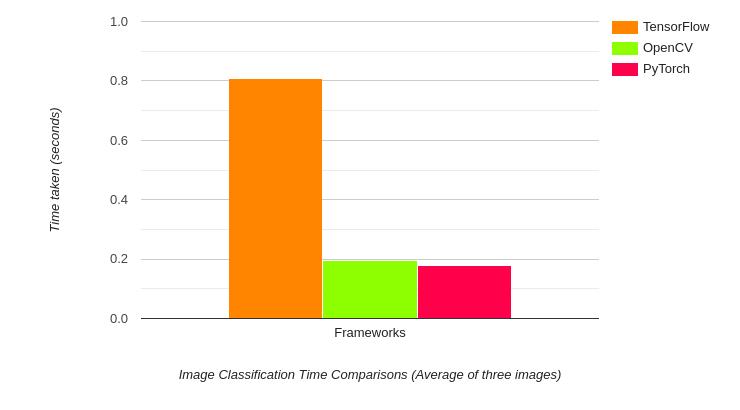
▲ 图1.1.1 图像分类处理速度(三幅图像的平均速度)
上面就是对比了三中不同的框架下图像分类的推理速度。
上面的结果就是对于DenseNet121模型的推理时间的对比。令人惊讶的是 OpenCV比起在TensorFlow下的最初实现速度高了一大截,只是比Pytorch模型慢了那么一点点。实际操作中, Tensorflow推理时间大约1秒钟,使用OpenCV的推理时间则小于200ms。
上述对比结果使用了博文写作时最新的OpenCV版本进行测量的。他们是:
-
对比结果软件版本:
-
PyTorch:1.8.0
OpenCV:4.5.1
TensorFlow:2.4
所有的测试都是在Google Colab中完成的,所使用的是Intel Xeon 2.3GHz处理器。
在物体检测中对比也是这样。
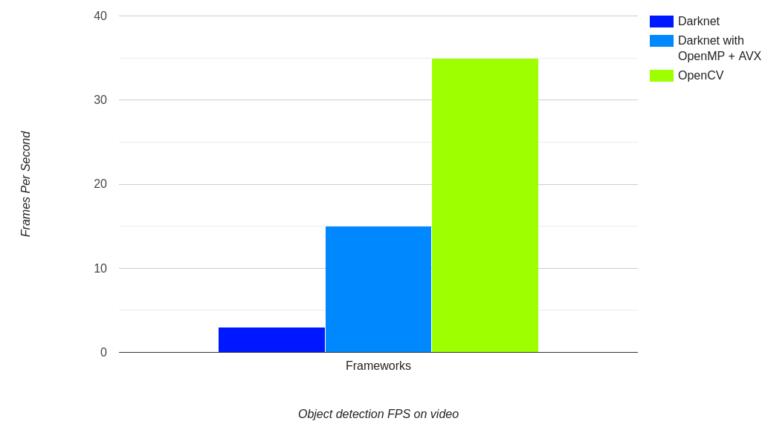
▲ 图1.1.2 视频中物体检测帧速对比
基于CPU对比不同学习框架模型在物体检测中的速度。
上面图标显示了利用 Tiny YOLOv4 在原始Karknet框架以及OpenCV上处理视频中的目标检测速度。性能指标是在Gen Laptop CPU(2.6GHz 时钟频率)下进行测量的。可以看到对于相同的视频 OpenCV的DNN模块可以达到35FPS,但Darknet利用OpenMP和AVX编译后的模型只能达到15FPS。 如果DarkNet不使用OpenMP, AVX进行优化,运行Tiny YOLOv4只能达到3FPS。考虑到我们使用的原始Darknet Tiny YOLOv4模型在两种情况下的对比,这种差别是非常巨大的。
上图显示了OpenCV DNN模块在CPU工作环境下的实用性和强大能力。在CPU上的快速推理使其可以在算力受限的情况下作为边端设备部署网络模型的优异工具。 基于ARM处理器的边端设备就是一个最好的例证。下面的图表说明了这一切:
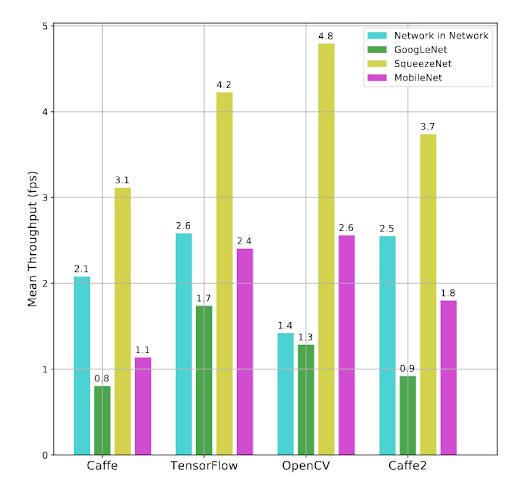
▲ 图1.1.3 在Raspberry Pi 3B运行的不同框架下不同模型的处理速度对比图
从上图可以看到不同的狂阶我和模型在Reapberry Pi 3B中运行速度的对比。对比结果非常显著。在SqueezeNet, MObileNet模型中, OpenCV比其他框架在处理速度上逗号。 对于GoogLeNet,OpenCV性能排在第二,TensorFlow的性能最好。 对于Network,OpenCV RasPBerryrFPS性能最差。
上面几个图标显示了优化后的OpenCV 对于神经网络推理的速度是多么的快。因此也说明了为什么学习OpenCV DNN的理由。
1.2 OpenCV NN提供的深度学习功能
我们知道利用OpenCV DNN模块我们可以对图像和视频完成基于深度学习的计算机视觉推理。下面看看OpenCV DNN所支持的功能列表。令人感兴趣的时候我们所有想到大多数的深度学习和计算机视觉任务OpenCV DNN都支持, 下面列表证明了这个想法:
1. 图像分类;
2. 目标检测;
3. 图像分割;
4. 文字检测和识别;
5. 姿态估计;
6. 深度估计
7. 人脸验证和检测;
8. 人体重新识别;
上面全面的列表给出了很多深度学习实际应用场景。可以通过访问 OpenCV 功能库 WiKi 网页 中相关信息了解更多内容。
重要的是很多模块的选择依赖于系统硬件,计算能力(后面我们将会讨论)。 对于每种应用,可以通过选择当今最好的但计算复杂模型 到 可以运行在边端(嵌入式)设备中的简易模型。
显然在一个博文中很难对上面所列写的各种模型都讨论到。因此,我们选择目标检测和人体姿态估计进行详细讨论,来初步了解在OpenCV DNN模块中如何进行模型选择。
1.2.1 OpenCV DNN支持的不同模型列表
为了支持上面讨论的应用,我们需要很多预先训练好的模型。而且的确存在着一些可供选择的SOTA 模型。下面表格列出了用于不同场合的深度学习模型。
| Image Classification | Object Detection | Image Segmentation | Text detection and recognition | Human Pose estimation | Person and face detection |
|---|---|---|---|---|---|
| Alexnet | MobileNet SSD | DeepLab | Easy OCR | Open Pose | Open Face |
| GoogLeNet | VGG SSD | UNet | CRNN | Alpha Pose | Torchreid |
| VGG | Faster R-CNN | FCN | Mobile FaceNet | ||
| ResNet | EfficientDet | OpenCV FaceDetector | |||
| SqueezeNet | |||||
| DenseNet | |||||
| ShuffleNet | |||||
| EfficientNet |
上面的表格虽然给出的模型很多但并未穷尽OpenCV DNN模块中所有的模型。仍然还有很多网络模型上述表格中并没有给出。就像前面所示,列出所有模型并进行讨论在一个博文中无法完成。上述表格只是告诉我们一个可行的方法去何选择计算机视觉中不同的深度学习模型。
1.3 OpenCVDNN 支持的深度学习框架
看到上面各种模型,脑子突然蹦出一个问题:是不是这些模型都可以由一个单一框架支持?实际上,并不是这样。
OpenCV DNN支持很多流行的深度学习框架。下面锯齿OpenCV DNN中所支持的深度学习框架。
1.3.1 Caffe
在利用OpenCV DNN 调用Caffe中的预训练模型是,我们需要狂歌事情。一个就是 model.caffemodel 文件,其中包含了预训练权重。 另外一个就是模型架构稳健,后缀为 。prototxt。 这是一个JSON结构类似的问呗文件,包含了所有的网络层的定义。如果想得到这个文件清晰的结构,可以访问 这个链接 。
1.3.2 TensorFlow
使用基于TensorFlow预训练的模型,我们需要两个文件。 一个是模型权重参数文件,另一个是定义有模型配置的protobuf文件。权重参数文件的后缀为 .pd,也就是protobuf文件,存储有所有预训练的网络参数。 如果之前你使用过TensorFlow,你知道 .pb 文件就是模型的检查点,即 在模型存储以及权系数固定之后存储的文件。 模型配置在 protobuf文件中,具有 .pbtxt 文件后缀。
注意:在Tensorflow的新的版本中,网络参数文件不再使用 .pb的文件格式。如果你使用自己存储的模型的话,文件的格式可能是 .ckpt 或者 .h5 格式,此时在使用OpenCV DNN之前需要一些中间步骤进行处理。这种情况下,帅看到模型转换成 ONNX格式,然后在转换成 .pb格式,这样可以保证所有结果都和所期望的那样。
1.3.3 Torch和PyTorch
为了载入Torch 模型文件,我们需要包含有预训练权重参数的文件。通常这个文件具有 .t7 或者 .net的文件后缀。最新的Torch版本的网络模型具有 .pth 的文件后缀。将这些文件首先转换成 ONNX是最好的处理方法。转换成ONNX文件之后,你可以直接通过OpenCV DNN所支持的ONNX模型方式载入网络。
1.3.4 Darknet
OpenCV DNN 也支持著名的 DarkNet学习框架。 如果你使用过官方的基于Darknet学习框架的YOLO模型就可以了解这一点。
通常,我们通过具有 .weights 后缀的文件来载入 Darknet模型。Darknet模型的网络配置文件的后缀是 .cfg。
1.3.5 转换成ONNX格式
可以通过软件工具将来自于 Keras 或者Pytorch的网络模型转换成 ONNX 格式文件。在OpenCV DNN 中不能够直接使用来自于Keras, Pytorch学习框架中的网络模型。通常将这些模型转换成ONNX的格式(Open Neural Network Exchange),这样可以使用他们,甚至将它们转换成其他学习框架中的模型,比如 TensorFlow, PyTorch。
在OpenCV DNN中我们需要后缀为 .onnx 的权重参数文件来载入 ONNX 模型。
通过访问 OpenCV 官方文件 来了解不同的学习框架,他们权重阐述文件以及配置文件。
最有可能的是,上面所列举的包括有所有著名深度学习框架。通过访问 官方Wiki网页 了解OpenCV DNN所支持的完整学习框架思想。
这里所见到的所有模型都是经过OpenCV DNN 模块完美测试过的。理论上,前面所有学习框架下的网络都可以在DNN模块中工作。我们只需要找到正确的权重参数文件以及相应的神经网络结构文件即可。通过本教程的代码部分就可以清楚所有的事情了。
我们将会覆盖足够的理论。下面进入博文的代码部分。首先我们需要一个图像分类的完整OpenCV DNN的使用过程。接着就是基于DNN模块的目标检测。
§02 图像分类
这是一个基于OpenCV DNN软件模块的图像分类的完整指导书。
2.1 网络模型
在这部分,我们将使用OpenCV DNN 模块完成图像的分类。对于每一部将会讲解,完成整个程序之后你就会对所有的过程了如指掌。
我们将使用在Caffe学习框架中的神经网络模型,它在著名数据集 ImageNet上经过预训练。使用 NeseNet121神经网络完成分类任务。 这个模型的优势在于它经过了包含有1000中物品的ImageNet数据集合训练,所以不管我们想要分类什么物品,它早已包含在模型中了。这让我们可以在更大的范围内选择图像。
我们将使用下面的图像进行分类。

▲ 图2.1 将用于OpenCV DNN 模型进行图像分类的样例图像
2.2 实现步骤
简单来讲,我们将采用以下步骤完成图像分类。
1. 从磁盘读入文件的名称,获取所需标签;
2. 从磁盘读入预训练的神经网络;
3. 但图片读入并转换成深度学习网络所需要的正确格式;
4. 把输入图像在网络中前向传递获得网络的输出结果;
下面我们通过代码来演示每一步的操作
2.2.1 导入模型并加载类别文本文件
对于Python编程,我们需要载入OpenCV 和Numpy模块。对于C++来说,我们需要包括 OpenCV, OpenCV DNN 的静态库。
- Python
import cv2
import numpy as np
- C++
#include <iostream>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/dnn/all_layers.hpp>
using namespace std;
using namespace cv;
using namespace dnn;
记住,所使用的 DenseNet21 模型已经在1000中类别的ImageNet数据集合进行预训练过。所以需要将这1000中物品调入内存这样便于访问它们,通常这些类别信息存储在TEXT文件中。 其中一个这种文件为:classification_classes_ILSVRC2012.txt 文件。包含有所有的类别名称,格式如下:
tench, Tinca tinca
goldfish, Carassius auratus
great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
tiger shark, Galeocerdo cuvieri
hammerhead, hammerhead shark
...
文件的每一行包含有所有针对一个图片的所有标签或者类别名称。比如,第一行包括有 tench, Tinca Tinca。对于这个同样的鱼它有两个名字。类似,第二行也是对应的金鱼有两个名称。 通常情况下第一个名称是被大多数人最常用到的名字。
下面我们展示如何将text文件读入内存,并将第一个名称抽取出来作为图像分类的标签。
- Python
# read the ImageNet class names
with open('../../input/classification_classes_ILSVRC2012.txt', 'r') as f:
image_net_names = f.read().split('\\n')
# final class names (just the first word of the many ImageNet names for one image)
class_names = [name.split(',')[0] for name in image_net_names]
- C++
std::vector<std::string> class_names;
ifstream ifs(string("../../input/classification_classes_ILSVRC2012.txt").c_str());
string line;
while (getline(ifs, line))
class_names.push_back(line);
首先,我们通过读入模式打开包含有所有类别名称的文件,将它们分割成新的一行行文本。现在将所有的类都安装下面的格式存储在 image_net_names 列表中。
[‘tench, Tinca tinca’, ‘goldfish, Carassius auratus’, ‘great white shark, white shark, man-eater, man-eating shark’, ...]
然而对于每一行,我们只需要第一个名称。这就是第二句代码的功能。对于 image_net_names列表中每个元素,将它们使用逗号(,)作为分隔符号进行分割,只保留第一个元素即可。这些名称存储在 class_names的列表中。至此,这个名称列表看起来为:
['tench', 'goldfish', 'great white shark', 'tiger shark', 'hammerhead', …]
2.2.2 从磁盘载入预训练的DenseNet121
正如前面所述,我们使用在Caffe学习框架中已经预训练好的DenseNet121网络。 我们需要相应的模型权重文件(.caffemodel)以及模型配置文件(.prototxt)。
下面看一下相应的代码并对载入模型的部分进行解释。
- Python
# load the neural network model
model = cv2.dnn.readNet(model='../../input/DenseNet_121.caffemodel', config='../../input/DenseNet_121.prototxt', framework='Caffe')
- C++
// load the neural network model
auto model = readNet("../../input/DenseNet_121.prototxt",
"../../input/DenseNet_121.caffemodel",
"Caffe");
你可以看到我们使用了OpenCV DNN中的 readNet() 函数,这个函数需要提供如下输入参数:
- odel: This is the path to the pre-trained weights file. In our case, it is the pre-trained Caffe model.
- config: This is the path to the model configuration file and it is the Caffe model’s .prototxt file in this case.
- framework: Finally, we need to provide the framework name that we are loading the models from. For us, it is the Caffe framework.
除了 readNet() 函数之外, DNN模块还提供了从特定学习框架中载入模型的函数。这些函数无需提供 framework 参数,下面给出了这些函数:
- readNetFromCaffe(): This is used to load pre-trained Caffe models and accepts two arguments. They are the path to the prototxt file and the path to the Caffe model file.
- readNetFromTensorflow(): We can use this function to directly load the TensorFlow pre-trained models. This also accepts two arguments. One is the path to the frozen model graph and the other is the path to the model architecture protobuf text file.
- readNetFromTorch(): We can use this to load Torch and PyTorch models which have been saved using the torch.save() function. We need to provide the model path as the argument.
- readNetFromDarknet(): This is used to load the models trained using the DarkNet framework. We need to provide two arguments here as well. One of the path to the model weights and the other is the path to the model configuration file.
- readNetFromONNX(): We can use this to load ONNX models and we only need to provide the path to the ONNX model file.
本文中使用 readNet() 来载入预训练好的模型。后面在目标检测中也是用readNet()函数。
2.2.3 读入图片并转换成网络输入格式
我们通过 OpenCV中的 imread() 函数读入图片。注意,有些细节需要我们关注。使用DNN 模块载入的预训练好的模型并不能够直接使用读入图像数据。需要预先进行预处理一下。
下面让我们先把代码码好,这样就比较容易讨论技术细节了。
- Python
# load the image from disk
image = cv2.imread('../../input/image_1.jpg')
# create blob from image
blob = cv2.dnn.blobFromImage(image以上是关于利用OpenCV DNN模块进行深度学习:一个最好使用指导书的主要内容,如果未能解决你的问题,请参考以下文章