从零学习OpenCV 4深度神经网络应用实例
Posted 小白学视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零学习OpenCV 4深度神经网络应用实例相关的知识,希望对你有一定的参考价值。
| 经过几个月的努力,小白终于完成了市面上第一本OpenCV 4入门书籍《OpenCV 4开发详解》。为了更让小伙伴更早的了解最新版的OpenCV 4,小白与出版社沟通,提前在公众号上连载部分内容,请持续关注小白。 |
随着深度神经网络的发展,OpenCV中已经有独立的模块专门用于实现各种深度学习的相关算法。本节中将以介绍如何使用OpenCV 4中的相关函数实现深度学习算法,重点介绍示例程序和处理效果,目的是为了增加读者对深度学习在图像处理中的应用的了解,提高读者对图像处理的兴趣。
加载深度学习模型
深度学习中最重要的部分就是对模型的训练,模型训练完成后就可以使用模型对新数据进行处理,例如识别图像中的物体、对图像中的人脸进行识别等。由于训练模型既耗费时间又容易失败,因此在实际使用过程中可以直接已有的模型,没必要每次都重新训练模型。OpenCV 4中提供了dnn::readNet()函数用于加载已经训练完成的模型,该函数的函数原型在代码清单12-17中给出。
代码清单12-17 dnn::readNet()函数原型Net cv::dnn::readNet(const String & model,const String & config = "",const String & framework = "")
-
model:模型文件名称。 -
config:配置文件名称。 -
framework:框架种类。
该函数可以加载已经完成训练的深度学习网络模型,返回一个Net类型的变量。函数第一个参数是模型文件的名称,文件以二进制的形式保存着网络模型中权重系数。不同框架的模型具有不同的扩展名,该函数能够加载的框架、框架文件扩展名以及框架的网站在表12-7给出。函数第二个参数是网络模型的配置文件,不同框架的模型具有不同的扩展名,具体内容也在表12-7给出,参数默认值表示不需要读取配置文件。最后一个参数是框架的种类,该函数可以根据文件的格式判断框架的种类,但是也可以通过第三个参数显示的给出框架的种类,参数默认值为空,表示根据文件格式判断框架种类。
| 框架种类 | 模型文件格式 | 配置文件格式 | 框架官网 |
|---|---|---|---|
| Caffe | *.caffemodel | *.prototxt | http://caffe.berkeleyvision.org/ |
| TensorFlow | *.pb | *.pbtxt | https://www.tensorflow.org/ |
| Torch | *.t7 *.net | -- | http://torch.ch/ |
| Darknet | *.weights | *.cfg | https://pjreddie.com/darknet/ |
| DLDT | *.bin | *.xml | https://software.intel.com/openvino-toolkit |
dnn::readNet()函数返回的Net类型是一个神经网络模型的类,OpenCV 4在Net类中提供了多个函数用于处理神经网络的模型,例如得到网络的层数、每层网络的权重、通过网络预测结果等,在表12-8给出了常用函数的含义及其使用方式。
| 函数名称 | 含义及使用方式 |
|---|---|
| empty() | 判断模型是否为空,不需要输入参数,模型为空返回true,否则返回false。 |
| getLayerNames() | 得到每层网络的名称,不需要输入参数,返回值为vector
|
| getLayerId() | 得到某层网络的ID,输入参数为网络的名称,返回值为int类型变量 |
| getLayer() | 得到指向具指定ID或名称的网络层的指针,输入参数为网络层ID,返回值为Ptr类型变量。 |
| forward() | 执行前向传输,输入参数为需要输出的网络层的名称,返回值为Mat类型数据。 |
| setInput() | 设置网络新的输入数据,具体参数在代码清单12-18中给出。 |
代码清单12-18 setInput()函数原型void cv::dnn::Net::setInput(InputArray blob,const String & name = "",double scalefactor = 1.0,const Scalar & mean = Scalar())
-
blob:新的输入数据,数据类型为CV_32F或CV_8U。 -
name:输入网络层的名称。 -
scalefactor:可选的标准化比例 -
mean:可选的减数数值。
该函数可以重新设置网络的输入值,函数第一个参数为新的输入数据,数据类型必须是CV_32F或CV_8U。第二个参数是输入网络层的名称,该参数可以使用默认值。第三个参数是可选的标准化比例,默认值为1。第四个参数是可选的减数数值,默认值为Scalar(),表示缺省该参数。
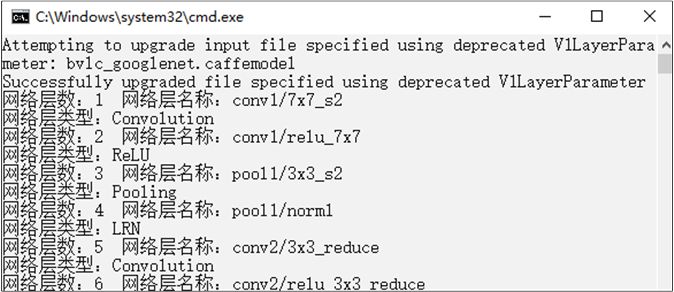
加载模型后可以通过Net类中的相关函数获取模型中的信息,代码清单12-19中给出利用dnn::readNet()函数加载以有模型,并获取模型中网络信息的示例程序。程序中加载的模型是谷歌提供的caffe框架的googlenet模型,模型文件名为bvlc_googlenet.caffemodel,配置文件名为bvlc_googlenet.prototxt。这两个文件在本书资源的data文件夹中。程序输出了每层网络的ID、名称以及类型,结果在图12-11中给出。
代码清单12-19 myRendNet.cpp加载深度神经网络模型#include <opencv2/opencv.hpp>#include <iostream>using namespace cv;using namespace cv::dnn;using namespace std;int main(){system("color F0");string model = "bvlc_googlenet.caffemodel";string config = "bvlc_googlenet.prototxt";//加载模型Net net = dnn::readNet(model, config);if (net.empty()){cout << "请确认是否输入空的模型文件" << endl;return -1;}// 获取各层信息vector<String> layerNames = net.getLayerNames();for (int i = 0; i < layerNames.size(); i++){//读取每层网络的IDint ID = net.getLayerId(layerNames[i]);//读取每层网络的信息Ptr<Layer> layer = net.getLayer(ID);//输出网络信息cout << "网络层数:" << ID << " 网络层名称:" << layerNames[i] << endl<< "网络层类型:" << layer->type.c_str() << endl;}return 0;}
图像识别
深度学习在图像识别分支中取得了惊艳的成果,部分图像识别模型对某些物体的识别可以达到非常高的识别识别率。本小节将介绍如何利用已有的深度学习模型实现对图像中物体的识别。由于训练一个泛化能力较强的模型需要大量的数据、时间以及较高配置的设备,因此一般情况下,我们直接使用已经训练完成的模型即可。本小节中我们将使用谷歌训练完成的图像物体识别的模型,该模型由tensorflow搭建,模型文件名称为tensorflow_inception_graph.pb。该模型识别图像后会出处一系列表示识别结果的数字和概率,识别结果的数字是在分类表中寻找具体分类物体的索引,分类表名为magenet_comp_graph_label_strings.txt。这两个文件都可以在本书资源的data文件夹中找到。通过readNet()函数加载模型,之后将需要识别的图像输入到网络中,然后在所有识别结果中寻找概率最大的结果,最后在分类表中找到结果对应的种类。
当我们在使用任何一个深度学习网络模型时都需要了解该模型输入数据的尺寸。一般来说,训练深度学习网络时所有的数据需要具有相同的尺寸,而且深度学习网络模型训练完成后只能处理与训练数据相同尺寸的数据。本小节中使用的网络模型输入图像的尺寸为224×224,我们需要将所有的图像尺寸都转换成224×224。OpenCV 4在dnn模块中提供了blobFromImages()函数专门用于转换需要输入到深度学习网络中的图像的尺寸,该函数的函数原型在代码清单12-20中给出。
代码清单12-20 dnn::blobFromImages()函数原型Mat cv::dnn::blobFromImages(InputArrayOfArrays images,double scalefactor = 1.0,Size size = Size(),const Scalar & mean = Scalar(),bool swapRB = false,bool crop = false,int ddepth = CV_32F)
-
images:输入图像,图像可以是单通道、三通道或者四通道。 -
scalefactor:图像像素缩放系数。 -
size:输出图像的尺寸 -
mean:像素值去均值化的数值。 -
swapRB:是否交换三通道图像的第一个通道和最后一个通道的标志。 -
crop:调整大小后是否对图像进行剪切的标志。 -
ddepth:输出图像的数据类型,可选参数为CV_32F或CV_8U。
该函数能够将任意尺寸和数据类型的图像转换成指定尺寸和数据类型。该函数第一个参数是原始图像,图像可以是单通道、三通道或者四通道。第二个参数是图像像素的缩放系数,是一个double类型的数据,参数默认是为1.0,表示不进行任何缩放。第三个参数是输出图像的尺寸,一般为模型输入需要的尺寸。第四个参数是像素值去均值化的数值,去均值化的目的是为了减少关照变化对图像中内容的影响,参数默认值为空,可以不输入任何参数。第五个参数为是否交换三通道图像的第一个通道和最后一个通道的标志,由于RGB颜色空间图像在OpenCV中有两种颜色通道顺序,该参数可以实现RGB通道顺序和BGR通道顺序间的转换,参数默认是为false,表示不进行交换。第六个参数是图像调整尺寸时是否剪切的标志,当该参数为true时,调整图像的尺寸使得图像的行(或者列)等于需要输出的尺寸,而图像的列(或者行)大于需要输出的尺寸,之后从图像的中心剪切出需要的尺寸作为结果输出;当该参数为false时,直接调整图像的行和列满足尺寸要求,不保证图像原始的横纵比,参数默认值为false。最后一个参数是输出图像的数据类型,可选参数为CV_32F或CV_8U,参数默认值为CV_32F。
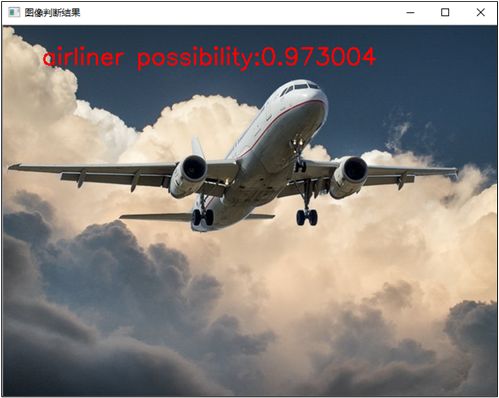
为了了解利用已有模型对图像进行识别的步骤和方法,在代码清单12-21中给出利用谷歌已有的tensorflow框架的图像识别模型对图像中物体进行识别的示例程序。程序首先利用readNet()函数加载模型文件tensorflow_inception_graph.pb,同时读取保存有识别结果列表的imagenet_comp_graph_label_strings.txt文件,之后利用blobFromImages()函数将需要识别的图像的尺寸调整为224×224,然后将图像数据通过setInput()函数输入给网络模型,并利用forward()完成神经网络前向计算,得到预测结果。在预测结果中选取概率最大的一项作为最终结果,使用概率最大的一项的索引在识别结果列表中寻找对应的物体种类。最后将图像中物体种类和可能是该物体的概率等相关信息在图像中输出,整个程序的运行结果在图12-12给出,通过结果可以知道,该模型预测图像中有97.3004%的可能性是一架飞机,预测结果与真实结果相同。
代码清单12-21 myImagePattern.cpp图像识别#include <opencv2/opencv.hpp>#include <iostream>#include <fstream>using namespace cv;using namespace cv::dnn;using namespace std;int main(){Mat img = imread("airplane.jpg");if (img.empty()){printf("could not load image...\n");return -1;}//读取分类种类名称String typeListFile = "imagenet_comp_graph_label_strings.txt";vector<String> typeList;ifstream file(typeListFile);if (!file.is_open()){printf("请确认分类种类名称是否正确");return -1;}std::string type;while (!file.eof()){//读取名称getline(file, type);if (type.length())typeList.push_back(type);}file.close();// 加载网络String tf_pb_file = "tensorflow_inception_graph.pb";Net net = readNet(tf_pb_file);if (net.empty()){printf("请确认模型文件是否为空文件");return -1;}//对输入图像数据进行处理Mat blob = blobFromImage(img, 1.0f, Size(224, 224), Scalar(), true, false);//进行图像种类预测Mat prob;net.setInput(blob, "input");prob = net.forward("softmax2");// 得到最可能分类输出Mat probMat = prob.reshape(1, 1);Point classNumber;double classProb; //最大可能性minMaxLoc(probMat, NULL, &classProb, NULL, &classNumber);string typeName = typeList.at(classNumber.x).c_str();cout << "图像中物体可能为:" << typeName << " 可能性为:" << classProb;//检测内容string str = typeName + " possibility:" + to_string(classProb);putText(img, str, Point(50, 50), FONT_HERSHEY_SIMPLEX, 1.0, Scalar(0, 0, 255), 2, 8);imshow("图像判断结果", img);waitKey(0);return 0;}
……
| 经过几个月的努力,市面上第一本OpenCV 4入门书籍《OpenCV 4开发详解》将春节后由人民邮电出版社发行。如果小伙伴觉得内容有帮助,希望到时候多多支持! |
| 关注小白的小伙伴可以提前看到书中的内容,我们创建了学习交流群,欢迎各位小伙伴添加小白微信加入交流群,添加小白时请备注“学习OpenCV 4”。 |
以上是关于从零学习OpenCV 4深度神经网络应用实例的主要内容,如果未能解决你的问题,请参考以下文章