深度学习中的微分
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习中的微分相关的知识,希望对你有一定的参考价值。
整理:Hoh Xil
来源:http://wd1900.github.io/#blog
https://www.zhihu.com/people/wang-ming-hui-38/posts
导读:我们在研究与应用深度学习时,会碰到一个无法绕过的内容,就是微分求导,再具体点其实就是反向传播。如果我们只是简单地应用深度学习、搭搭模型,那么可以不用深究。但是如果想深入的从工程上了解深度学习及对应框架的实现,那么了解程序是如何进行反向传播,自动微分就十分重要了。本文将一步步的从简单的手动求导一直谈到自动微分。
我们目前可以将微分划分为四大类:Manual Differentiation、Symbolic Differentiation、Numeric Differentiation、Automatic Differentiation。
▌Manual Differentiation
Manual Differentiation正如字面意思所写,就是手动对函数求导。
比如下式就是个简单的函数。
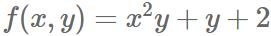
对x求导可得:
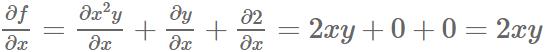
对y求导可得:
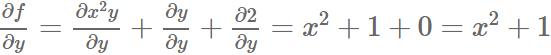
这个例子很见到,只要了解基本的求导公式,都可以很迅速的解决。但是当我们面临的是一个极其复杂的公式时,整个过程将会非常繁琐,而且容易出错。
▌Symbolic Differentiation
为了避免人力的介入,首先提出了 Symbolic Differentiation 即符号微分。
下面也是个简单的例子:
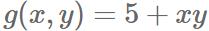
符号微分方式如下图:
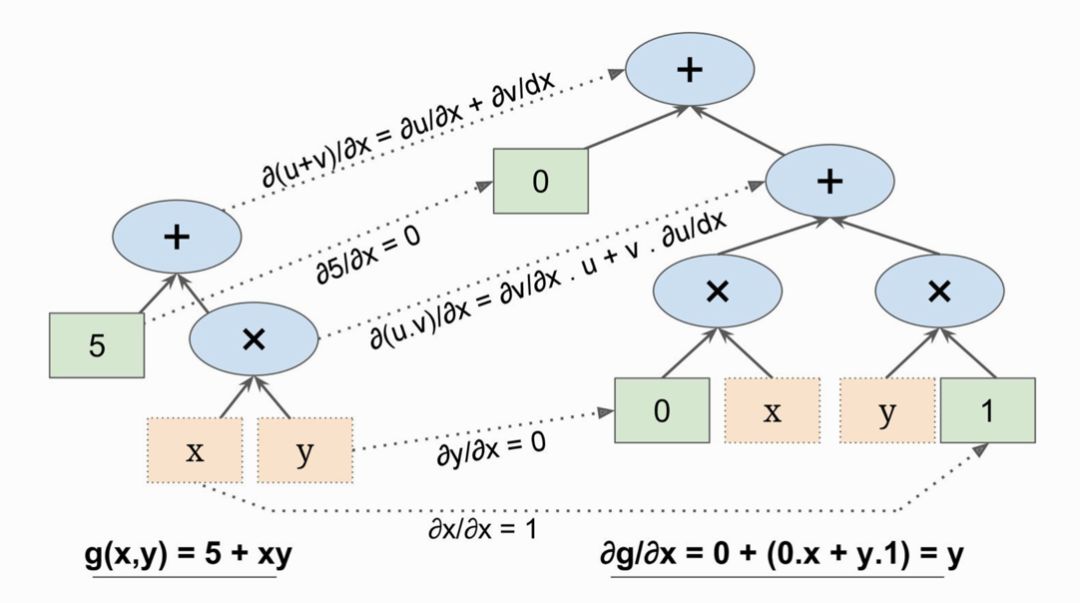
这个例子很简单,但是对于复杂函数会生成非常大的图,很难简化,有一定的性能问题。
更重要的是,符号微分无法对任意代码定义的函数进行求导,如下:
def my_func(a, b):z = 0for i in range(1000):z = a * np.cos(z + i) + z * nreturn z
▌Numeric Differentiation
那怎样才能对任意函数进行求导呢,于是引出了Numeric Differentiation,顾名思义就是用数值去近似计算,求微分。
我们知道:
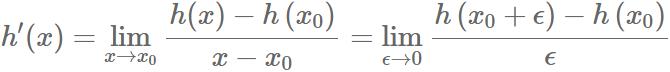
def f(x, y):return x**2*y + y + 2def derivative(f, x, y, x_eps, y_eps):return (f(x + x_eps, y + y_eps) - f(x, y)) / (x_eps + y_eps)df_dx = derivative(f, 3, 4, 0.00001, 0) # 24.000039999805264df_dy = derivative(f, 3, 4, 0, 0.00001) # 10.000000000331966
数值微分里边,如上边的代码,我们至少需要执行三次f(x,y),当我们的参数有1000个时就至少要执行1001次,在大规模的神经网络模型中,这样的做法是很低效的。不过数值微分比较简单,可以用来对手动求导的值进行验证。
▌Automatic Differentiation
Autodiff算是在之前提到的这些方案基础之上得到的一个兼具性能和数值稳定的方案。
1. Forward-Mode Autodiff
Forward-Mode是数值微分和符号微分的结合
引入二元数ε, ϵ**2 = 0 ( ϵ ≠ 0)
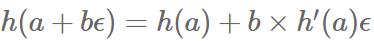
所以f(x,y) 在(3,4)点对x的导数为ϵ前面的系数
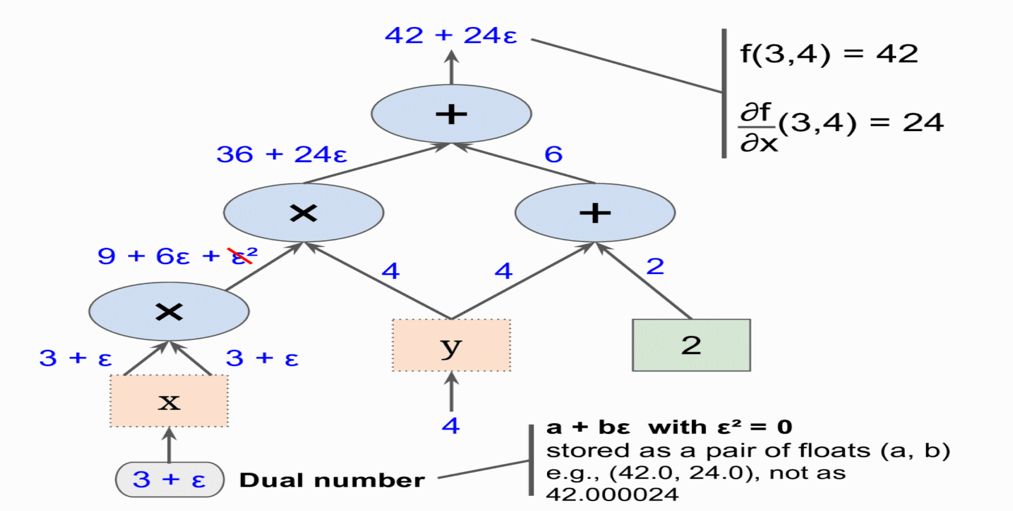
forward-mode autodiff 比数值微分更准确,但是也有同样的问题,就是有n个参数要走n次图
2. Reverse-Mode Autodiff
为了解决Forward-Mode中需要根据参数进行图遍历的问题,提出了Reverse-Mode Autodiff方案。这也就是我们常说的链式法则、反向传播算法(machine learning中我们常常将其等价)。
第一遍,先从输入到输出,进行前向计算
第二遍,从输出到输入,进行反向计算求偏导
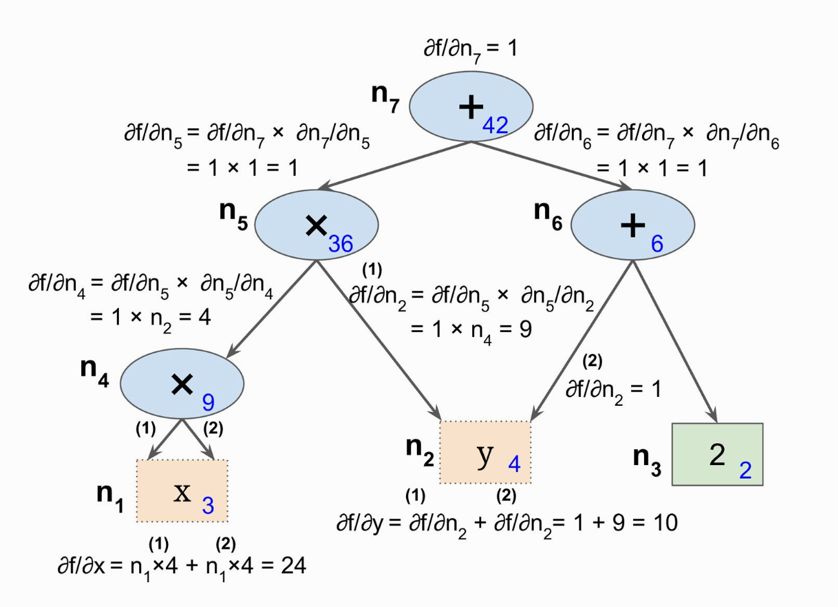
Reverse-Mode Autodiff在有大量输入,少量输出时是非常有力的方案
一次正向,一次反向可以计算所有输入的偏导
一个简易教学版的Autograd的实现:
https://github.com/mattjj/autodidact
3. 相关工程实现
Autograd将numpy包了一层,提供与numpy相同的基础ops,但自己内部创建了计算图
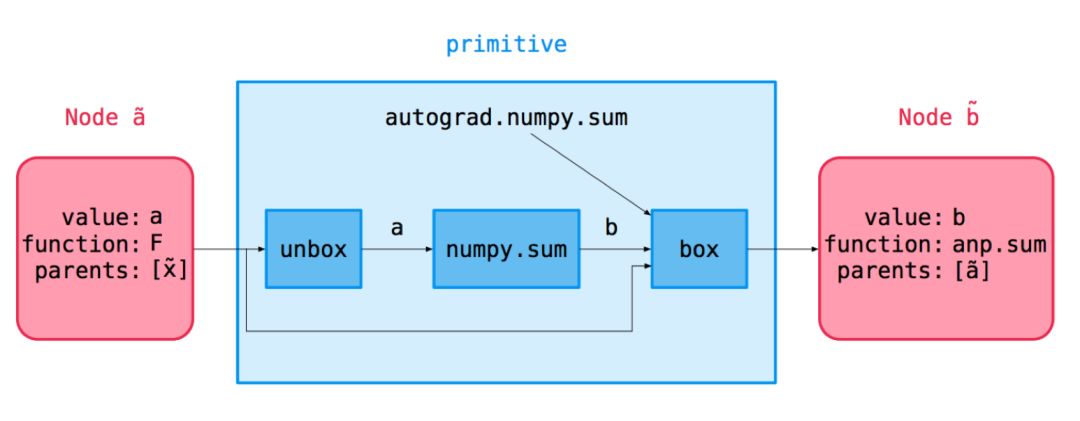
import autograd.numpy as npfrom autograd import graddef logistic(z):# 等价形式# np.reciprocal(np.add(1, np.exp(np.negative(z))))return 1. / (1. + np.exp(-z))print(logistic(1.5)) # 0.8175744761936437print(grad(logistic)(1.5)) # 0.14914645207033284
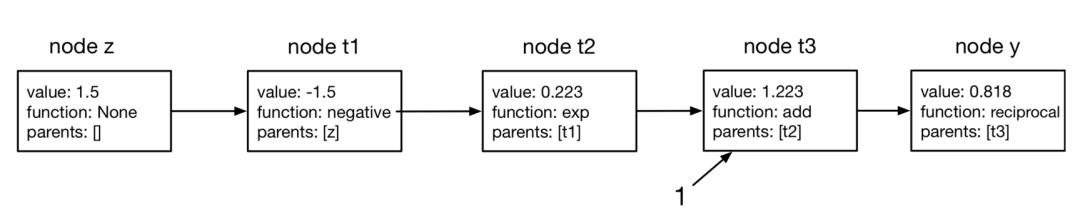
① Vector-Jacobian Products
雅克比矩阵:
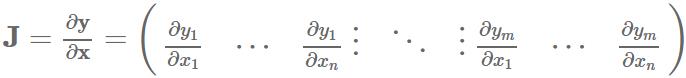
vector-Jacobian product (VJP):
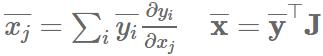
对于每一个基本操作都需要定义一个VJP。
primitive_vjps = defaultdict(dict)def defvjp(fun, *vjps, **kwargs):argnums = kwargs.get('argnums', count())for argnum, vjp in zip(argnums, vjps):primitive_vjps[fun][argnum] = vjpdefvjp(anp.negative, lambda g, ans, x: -g)defvjp(anp.exp, lambda g, ans, x: ans * g)defvjp(anp.log, lambda g, ans, x: g / x)defvjp(anp.tanh, lambda g, ans, x: g / anp.cosh(x) **2)defvjp(anp.sinh, lambda g, ans, x: g * anp.cosh(x))defvjp(anp.cosh, lambda g, ans, x: g * anp.sinh(x))
tracing the forward pass to build the computation graph上边的代码是截取了autodidact的部分代码,像negative基本操作,求出倒数就是原来基础上取负。整个过程可以划分为三块。
vector-Jacobian products for primitive ops
backwards pass
再具体的细节就不粘贴了,有兴趣的同学可以访问我之前贴出的链接,几百行代码,麻雀虽小五脏俱全,非常适合学习。
▌Reference
1. Géron, Aurélien. “Hands-On Machine Learning with Scikit-Learn and TensorFlow”
https://www.cs.toronto.edu/~rgrosse/courses/csc321_2018/slides/lec10.pdf
2. Autograd的实现:
https://github.com/mattjj/autodidact
文章推荐:
DataFun:
专注于大数据、人工智能领域的知识分享平台。
一个「在看」,一段时光! 以上是关于深度学习中的微分的主要内容,如果未能解决你的问题,请参考以下文章 Pytorch深度学习实战3-5:详解计算图与自动微分机(附实例) [人工智能-数学基础-1]:深度学习中的数学地图:计算机数学数值计算数值分析数值计算微分积分概率统计..... PyTorch深度学习60分钟快速入门 Part2:Autograd自动化微分