伯克利人工智能研究院开源深度学习数据压缩方法Bit-Swap,性能创新高
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了伯克利人工智能研究院开源深度学习数据压缩方法Bit-Swap,性能创新高相关的知识,希望对你有一定的参考价值。
出品 | AI科技大本营(ID: rgznai100)
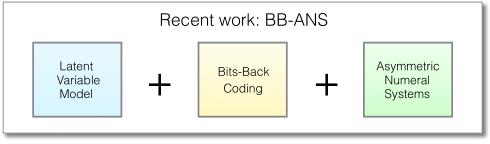
【导读】在本篇文章中,伯克利人工智能研究院(BAIR)介绍了一种可扩展的、基于深度学习的高效无损数据压缩技术。该技术基于之前的 bits-back 编码和非对称数字系统,对隐变量模型进行压缩的方法进行了扩展。在实验中,Bit-Swap 在高度多样化的图集的表现上超过了压缩器中的 benchmark。BAIR 开源了该方法的代码,对模型进行了优化,并提供了 demo 和预训练好的 Bit-Swap 模型,可以用来对任何图片进行压缩和解压缩。欢迎观看文末链接里的视频,其中包含对 bits-back 编码和 Bit-Swap 原理的解释。
高维数据的无损压缩
该研究的目标是,设计一种可用于图像等高维数据的高效无损压缩方法。实现这一目标,要同时解决两个问题:
-
-
开发一种可扩展的压缩算法,它可以充分发掘模型的压缩潜能

任何压缩方法的压缩比都严重依赖于一个因素:模型的容量。而近年来深度学习的飞速发展,使得我们可以对基于复杂高维数据的概率模型进行有效的优化。这些进步为无损压缩技术的发展提供了更多可能性。如今有一些先进的技术结合了自回归模型和熵编码,如算术编码和非对称数字系统(ANS, asymmetric numeral systems),都具有很不错的压缩比。然而,自回归结构使解压过程比压缩过程慢了几个数量级。
幸运的是,ANS 具有并行计算的能力。为了充分利用这一特性,我们将注意力放在了全因子分布的建模上。由于这个限制,我们不得不基于此进行模型的选择,并构建新的编码方案。
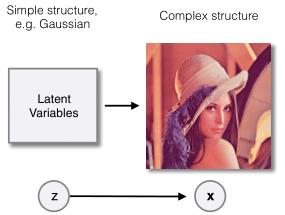
最近提出的基于非对称数字系统的 Bits-Back(BB-ANS, Bits-Back with Asymmetric Numeral Systems)方法,通过将潜变量模型与 ANS 结合来缓解了这个问题。潜变量模型定义了未被观察的随机变量,但这些变量的值影响了数据的分布。例如,如果我们所观察的数据包含图像,图像的构成可能依赖于边的位置和纹理,这些特征都属于隐变量。这类模型可以使用全因子分布,并通过 VAE 框架进行有效的优化。
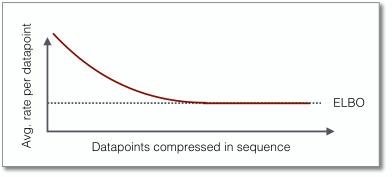
使得 BB-ANS 可以基于隐变量模型进行压缩的关键要素是 bits-back 编码,事实证明这种方法天生适用于 ANS。Bits-back 编码可以保证压缩结果接近于负的 ELBO(Evidence Lower Bound),只有初始化的时候需要一点额外的开销。当一次性压缩较长的序列时,这种额外的开销就显得很微不足道了。
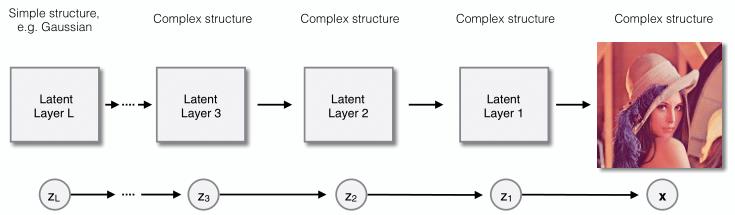
当我们把隐变量模型设计成复杂的高密度估计器时,模型被限制在全因子分布上,这会影响模型的灵活性。因此,我们采用分层隐变量模型来解决这个问题,该模型相比于单个的隐变量模型具有更大的容量。我们通过递归的方式对隐变量模型进行扩展,将全因子先验分布替换为第二个隐变量模型,将其先验替换为第三个隐变量模型,以此类推。
例如,如果所观察的数据是图像,图像的构成取决于边的位置和纹理的分布,这些特征又依赖于物体的位置,而物体的位置又依赖于场景的构成,等等。因此,如果我们让每一层都只依赖于它的上一层,这个模型可能要设计成多层嵌套的隐变量模型:所观察数据的分布受第一个隐变量层控制,第一个隐变量层的分布受第二个隐变量层控制,以此类推直到最上面一层,而这层具有无条件先验分布。
基于这个想法,我们开发了全新的编码技术,名为递归式 bits-back 编码。正如这个方法的名字,我们在每一层上递归地使用 bits-back 编码,从底层到顶层依次处理嵌套隐变量模型。我们将递归式 bits-back 编码和特定的分层隐变量模型相结合,得到了 Bit-Swap 模型。Bit-Swap 有以下几个优势:
-
用递归的形式使用 bits-back 编码可以节省模型的开销,而且不会随模型的深度增加而增加。这与直接在分层隐变量模型上使用 BB-ANS 有所不同,不会忽略隐变量的拓扑性,也不会将全部隐变量层当作单个向量处理,而导致模型的开销随着层次深度增加而增大。
-
Bit-Swap 还可以达到负 ELBO 的压缩水平,所需的开销也更小。
-
基于每层的先验分布进行隐变量层的嵌套叠加,除了最上面一层,使每一个隐变量层都拥有更复杂的分布。嵌套结构使 ELBO 更为紧凑,即更低的压缩比。
-
我们通过模型维持全因子分布,使得整个编码过程可以并行。基于 GPU 实现的 ANS 以及模型的并行,我们实现了高速的压缩和解压缩。该方法的瓶颈在于 ANS 的实际操作,但我们对此保持乐观,相信其固有的并行性可以解决这一问题。未来 Bit-Swap 将会有更大幅度的提升。
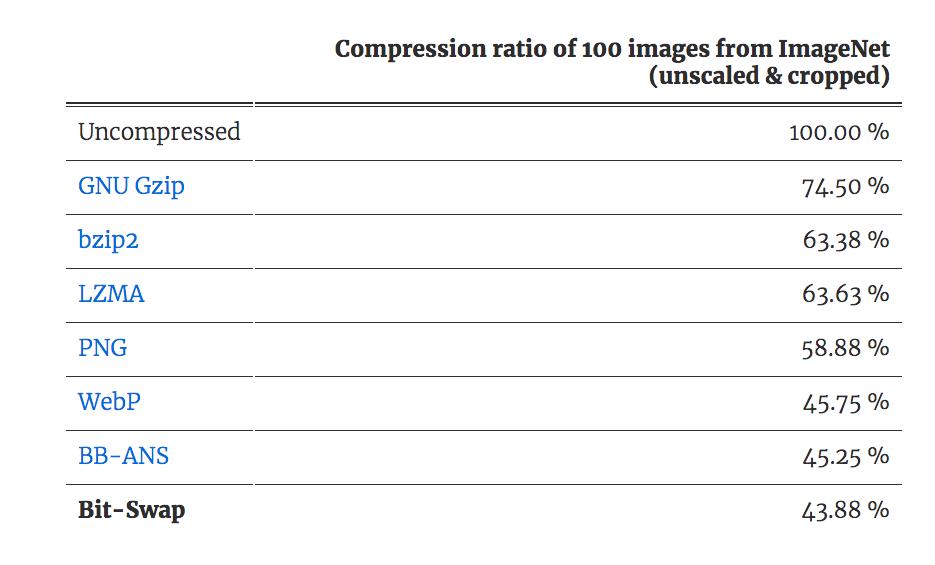
我们从 ImageNet 中随机选取 32x32 像素的图,进行分层隐变量模型的训练。我们又从测试集中选取另外 100 个图进行测试,这 100 个图同样被处理为 32x32 像素,这样就可以适用于由 32x32 像素块组成的网格了。该网格可以看作为一个数据集,使用 Bit-Swap 和 BB-ANS 以序列的形式进行处理。接下来,我们用 Bit-Swap 和 BB-ANS 处理单个序列,即每次压缩一张图片。我们使用相同的图片,与 baseline 进行对比。结果如上图所示。我们相信可以通过使用更高像素的图和更复杂的模型获得更好的结果。全部结果可参见论文。
来尝试用 Bit-Swap 压缩你自己的图片吧。把这个 GitHub 文件夹(https://github.com/fhkingma/bitswap)克隆到本地,运行脚本 demo_compress.py 和 demo_decompress.py,demo_compress.py 会使用 Bit-Swap 进行压缩处理,并与 GNU Gzip、bzip2、LZMA、PNG 和 WebP 等压缩方法进行对比。demo_decompress.py 会对 Bit-Swap 压缩文件进行解压缩。
注意:
如果输入的文件是已经被压缩的(JPEG、PNG 等),程序会先对文件进行解压缩,输出为 RGB 像素数据。接下来,RGB 像素数据就成了输入,Bit-Swap 会对其进行压缩,得到比 RGB 像素数据更小的结果。有人可能注意到了,原始的 RGB 像素数据比输入的文件包含了更多的信息量。在将 JPEG 文件转为 RGB 数据时,文件大小上的差异尤为明显。这是因为 JPEG 是一种有损的压缩形式,它包含一个量化步骤,该步骤会使原始图片丢失掉大部分信息。量化过程实现了可预测的模式,但也不得不使用了有损的压缩技术。然而当解压 JPEG 文件并将其转化为 RGB 时,无论是什么模式,我们都存储了每一个像素值,从而保留了更大的信息量。
https://bair.berkeley.edu/blog/2019/09/19/bit-swap/
(*本文为 AI科技大本营翻译文章,转
载请微
信联系1092722531)
2019 中国大数据技术大会(BDTC)历经十一载,再度火热来袭!
豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
【早鸟票】
与
【特惠学生票】
限时抢购,扫码了解详情!
推荐阅读
以上是关于伯克利人工智能研究院开源深度学习数据压缩方法Bit-Swap,性能创新高的主要内容,如果未能解决你的问题,请参考以下文章
细数当前几大深度学习框架
开源深度学习架构Caffe
基本概念 深度神经网络压缩与优化研究_王征韬
举办“Python人工智能之Pytorch深度学习高级实战”远程直播研修班的通知
奇虎360正式开源其深度学习调度平台,支持TensorFlowMXNet等框架
AI on Hadoop--开源AI基础架构