基本概念 深度神经网络压缩与优化研究_王征韬
Posted cc-xiao5
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基本概念 深度神经网络压缩与优化研究_王征韬相关的知识,希望对你有一定的参考价值。
深度神经网络压缩与优化研究
文献来源:王征韬. 深度神经网络压缩与优化研究[D].电子科技大学,2017.
摘要:深度学习是近年来机器学习领域最有影响力的研究方向,在计算机视觉、自然语言处理的许多问题上都取得了突出的效果。深度学习的本质是大数据支撑下,由多层人工神经网络堆叠形成的信号处理系统,具有参数数目多,计算复杂度高等特点。深度学习的训练和运行都需要大量的运行空间与并行计算设备,这些需求阻碍了深度学习在资源有限的设备,如手机、平板电脑和嵌入式设备上的应用。另一方面,神经网络中普遍存在过参数化的问题,对于一个具体任务而言,网络的参数存在着极大的冗余。深度网络压缩是解决此类问题的关键技术。本文属于深度网络压缩的研究方向,其主要工作有:神经网络压缩方法归纳总结、神经元贡献评价与消偏、渐次全局神经元裁剪框架与实现
一、 绪论
1.1 研究背景与意义
??深度学习是近年来机器学习中最具有代表性的技术,在图片识别,自然语言处理,语音识别,机器人技术等许多模式识别的关键领域均取得了突破性的成就。因为深度学习具有体积庞大,计算规模大的特点,使得深度神经网络的训练和使用常常要在高性能的并行设备上运行,例如高性能的GPU或专门为深度学习开发的运算设备,如TPU。这些设备往往价格昂贵,体积庞大,功耗惊人。这无疑是深度学习从实验室走向应用的一道障碍。深度学习强大的模式识别能力与巨量的计算开销推动了对深度神经网络进行压缩和加速方面的研究。通过将深度神经网络进行压缩,我们可以缩小运行深度神经网络所需的计算开销,从而使得深度神经网络可以部署在计算资源有限的设备上,如智能手机、平板电脑或其他嵌入式设备。
1.2 国内外现状
1.2.1 深度学习研究现状
- BP算法。深层网络具有梯度消失,容易陷入局部最优的问题。
- CNN类卷积神经网络。CNN主要处理局部相关性的问题,如图片分类,文本分类。具有代表性的网络有LeNet,AlexNet,VGG网络,ResNet,Inception网络。
- RNN循环神经网络。RNN是具有记忆性的网络。主要处理具有时序特征的问题,如语音识别等。
- 全连接网络。神经网络基本结构由神经元的全连接构成。这类研究主要集中在自动编码器上。自动编码器最早用于深度网络的预训练,随着提高深度网络训练效率的新方法的提出,目前自动编码器主要用于无监督学习数据集的特征,比较有代表性的研究有去噪自动编码器,稀疏自动编码器,变分自动编码器等。
1.2.2 网络压缩研究现状
??深度学习的本质是大数据支持下的多层人工神经网络系统,一个深度学习模型通常包含数以百万甚至千万计的参数和十几层甚至几十层的网络。例如,AlexNet网络的参数数目约为6000万个,而VGG网络拥有1.4亿参数。巨量的参数带来性能提升的同时,也带来网络体量巨大、运算缓慢等缺点,不利于深度学习模型向运算资源有限的设备和应用中嵌入。另一方面,深度神经网络又常常是过参数化的。
- 为权重参数施加了衰减项,在克服过拟合的同时迫使小权重接近于0[1]。
- 利用参数关于损失函数的二阶导数[2-3],即Hessian矩阵确定网络的冗余连接并进行剪枝。在进入深度学习的时代以后,Hessian矩阵因其巨大计算量已经不再适用。
- 文献[4]最早指出深度网络中可能存在的过参数化现象,即网络模型包含的参数数目远远多于实际需求的参数数目。此后的一大工作都致力于如何将权重矩阵或权重张量进行分解和重建。文献[4]过对权重矩阵进行低秩分解,并通过控制秩的大小来决定网络压缩的力度。
- 文献[5]从另一个方面对权重矩阵进行处理,通过应用向量量化算法,在准确率损失不到1%的条件下获得了16 24倍的压缩率。
- 文献[6]将哈希的方法应用到网络压缩中,权重被随机分到若干哈希桶中,同一个哈希桶权重共享,迫使网络的权重集中到有限的若干个值上。
- 文献[7]是近年来神经网络压缩方面重要的工作,作者提出了一种学习连接,裁剪连接和重训练权重的三步训练框架,能够同时学习到网络的连接与对应的连接权重。在VGG-16网络上,作者在不显著减少性能的前提下将网络压缩了13倍。
- 文献[8]针对移动设备对网络进行裁剪和压缩,通过对网络参数的张量进行Tucker分解,并用贝叶斯方法自动确定张量重建的秩,成功将网络移植到移动设备上。
- 文献[9]将网络参数的浮点数表示量化为8位定点数表示,这种表示在缩小了网络规模的同时,有效提高了网络的运算速度。
- 文献[10]通过对卷积操作的优化,将卷积层运算速度增加两倍的同时保持准确率下降不到1%。
- 文献[11]考虑了非线性单元的运算,通过最小化非线性重构误差和低秩约束减少了滤波器复杂度,在将计算增加4倍的同时,保持准确率下降不到1%。
- 文献[12]试图对网络进行二值化,在极大压缩网络的同时提供了硬件实现网络的可能。
- 文献[13]研究了在内存资源有限情况下的深度神经网络,通过稀疏正则项使神经网络学习到稀疏的连接权。
- 文献[14]基于粒子滤波的方法确定连接权的重要程度,并通过适当的量化对网络进行裁剪和压缩。
- 文献[15]和文献[16]均是基于三元量化的思想对网络参数进行量化,区别在于文献[16]中将权值规定为+1,-1和0三种情况,而文献[15]的三元权值则是通过训练而来。
- 文献[17]通过一种逐层稀疏优化的方式,在保持网络每层变换近似相同的条件下将网络稀疏化。
- 文献[18]则以卷积网络滤波器的权值和为滤波器的重要性依据,对卷积神经网络进行裁剪。
1.3 研究内容
1.3.1 神经网络裁剪
?当前神经网络的压缩大体上可以分为近似,量化和裁剪三类方法。
-
近似。近似类方法主要利用矩阵或张量分解的思想,通过少量参数重构原始网络参数矩阵或参数张量,以达到减少网络存储开销的目的。通常,在网络运行时,这些参数将会被适当重建,网络的运行时开销并没有得到有效减少。
-
量化。量化方法的主要思想是将网络参数的可能值从实数域映射到有限数集,或将网络参数用更少的比特数来表示。量化的方法将原本具有无限种可能的参数约束到少数几种参数中,再对这些参数进行重用,就可以减少网络存储开销。通过改变参数的数据类型,如将原本的64位浮点型量化为整形甚至布尔型,网络的运行时开销也将得到大幅度减少。
-
裁剪。网络裁剪的主要特点是会直接改变网络的结构。网络裁剪可以按粒度分为层级裁剪,神经元级裁剪和神经连接级裁剪。层级裁剪的裁减对象是网络层,裁剪的结果是获得更浅的网络。通常,神经网络想要达到良好的模式识别效果,必须具有较深的深度,但对具体问题而言,深度太深也会带来过拟合风险增高,训练难度加大等问题,且过深的网络对提高具体场景下模式识别的性能帮助有限,因此有时会对网络进行层级的裁剪。神经元级的裁剪对象是一层中的神经元或滤波器,裁剪的结果是获得更“瘦”的神经网络,瘦长的神经网络不但能够减少网络存储开销,还能提高网络运算速度。经过层级或神经元级裁剪的神经网络,仍然保持了原本神经网络的正规性,即网络的存储和运算规则仍然保持不变,只是规模变小。神经连接级的裁剪对象是一条具体的网络连接,或一个具体的参数,裁剪的结果通常是获得更为稀疏的网络。神经连接级的裁剪往往更加精细可控,对网络性能的影响最小。但神经连接级的裁剪会导致网络失去正规性,经过裁剪的网络权值张量变的稀疏,因此在存储和运算时需要采用稀疏张量的存储和运算规则,不利于并行。
1.3.2 论文研究内容
- 对网络压缩和裁剪的方法进行广泛研究,形成关于神经网络压缩的研究报告。
- 本文针对神经元级的网络裁剪问题,使用特征图反转技术验证了网络中存在的神经元功能冗余问题。随后,我们对现存的部分神经元贡献度评分准则进行了扩展,提出了和验证了当前成果中普遍存在的层间神经元评 分不均衡问题。提出了一种简单的神经元评分消偏方法,使得神经元级的全局裁剪成为可能。
- 基于上述,我们提出了一种渐次全局神经元裁剪框架,在此框架下,每一轮的网络裁剪将同时考虑所有层的神经元,而不是单独某一层的神经元。该框架一方面避免了逐层裁剪法中难以确定各个层的裁减比例的问题,另一方面将裁剪的迭代次数与网络深度解耦,降低了裁减网络所需的时间复杂度。通过该方法,我们可以在给定的性能指标下自动的搜索出一个近似最优的网络结构。我们基于开源深度学习框架Keras实现了该算法并在多个神经网络评估了算法性能。本文提出的裁剪框架在运算效率和裁剪性能上均有较明显优势。
二、 深度学习基础
2.1 特点
- 计算密集。
- 特征的自动提取和分层处理,深度神经网络主要处理的问题是从数据中自动提取特征。
- 工程性强,可解释性弱。
2.2 神经网络层类型
- 全连接层
- 卷积层
- 池化层
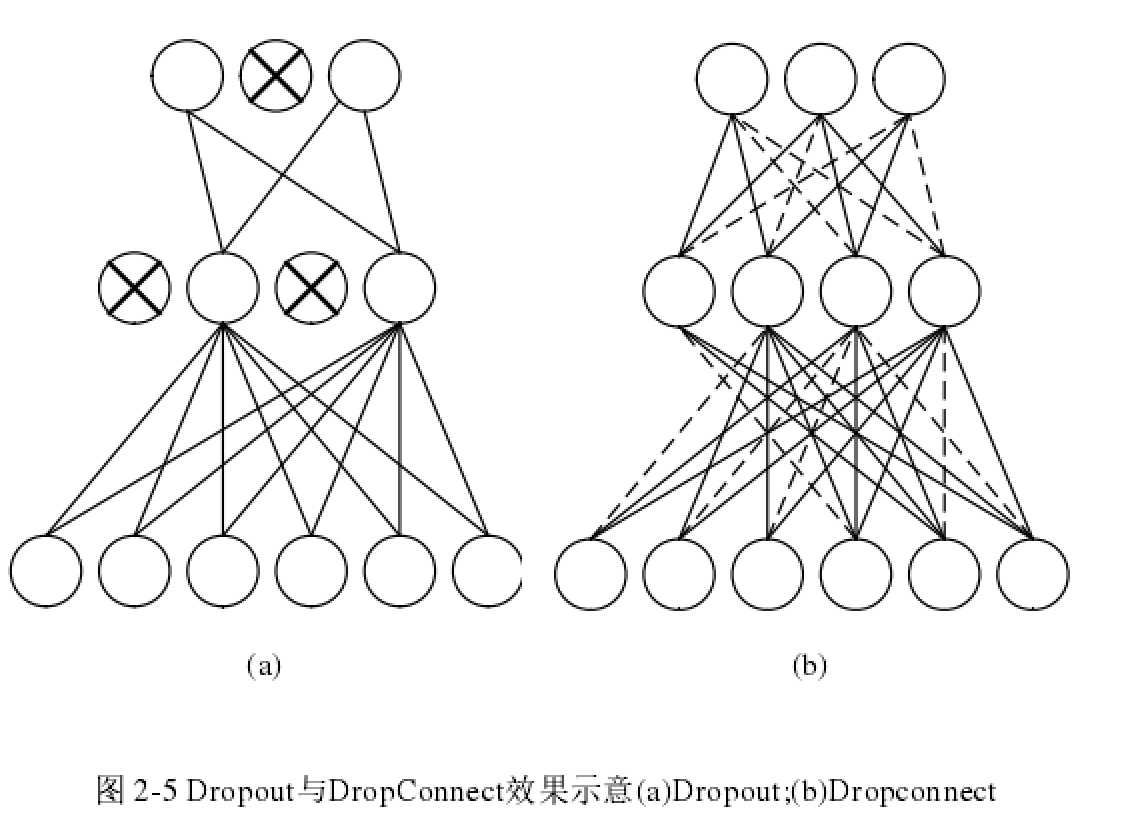
- Dropout层。Dropout是一项有效抑制网络过拟合的技术,Dropout层不含有任何可训练的参数并且仅在训练阶段起作用。在每一个Batch的数据进入网络后,Dropout将随机断开网络中的神经元,迫使网络用更少的参数拟合数据集,由于每个Batch断开的神经元都未必相同,Dropout实际上在模型局部构造了一种集成学习器。对与一个具有N个输出神经元的全连接,一共有(2^N)种可能的模型。多种实验证明,Dropout可以有效提高模型泛化能力,因此成为深度学习中最常用的层类型之一。另一种类似的技术是DropConnect,它断开的是单个神经连接,而不是神经元。下图分别展示了Dropout和DropConnect应用在全连接中产生的效果,虚线表示链接断开。Dropout也可以应用在更大尺度上,例如将一张特征图的连接整体断开,这类Dropout有时称为空域Dropout,常用于卷积层。
- 批规范化层。批规范化(Batch Normalization),下简称BN层是近年提出的一种用于加速训练的技术。由于其兼容性强,效果明显,在搭建神经网络模型时广为使用。BN的层的设计初衷是为了解决层间数据分布不一致的问题。当神经网络中各个层的输入分布不一致时,每一层都需要不断的为新的数据分布做出适应性调整,从而增加网络的训练困难。BN层的主要作用包括以下几点:(1)大大加速网络收敛。(2)降低网络对初始化权重的敏感度,初始化对网络性能的影响减小。(3)在训练时可以使用较大的学习率。(4)对网络进行正则,使得模型可以少用或不用Dropout。
2.3 CNN常见网络结构
- 序贯结构。序贯结构包含单输入与单输出,其神经网络由网络层堆叠而成。每一个网络层仅以上一层网络的输出为输入,并将经过处理后的输出送给下一层。序贯结构的典型代表模型是VGG系列网络。但过深的网络仍然会出现训练困难甚至是网络退化的问题。网络退化指的是随着网络层数的加深,网络性能反而出现下降的现象。
- 自编码结构。自编码结构指的是网络的输出试图重构网络输入的一种结构,形式上它可以是序贯的全连接网络或卷积网络,如卷积自编码器[19],也可以是含有跨层连接的复杂形态,如梯式自编码器[20]。自编码结构通常被认为是深度学习中的无监督学习模型,但严格来讲,它属于一种特殊的有监督学习,称为“自监督”学习。自编码器的主要作用是学习原始数据在另一空间(通常维度更低)更加高效的表示,与主成分分析(PCA)的作用类似。使用自编码结构网络还可以用于图像去噪、图像超分辨处理[21]等应用领域。
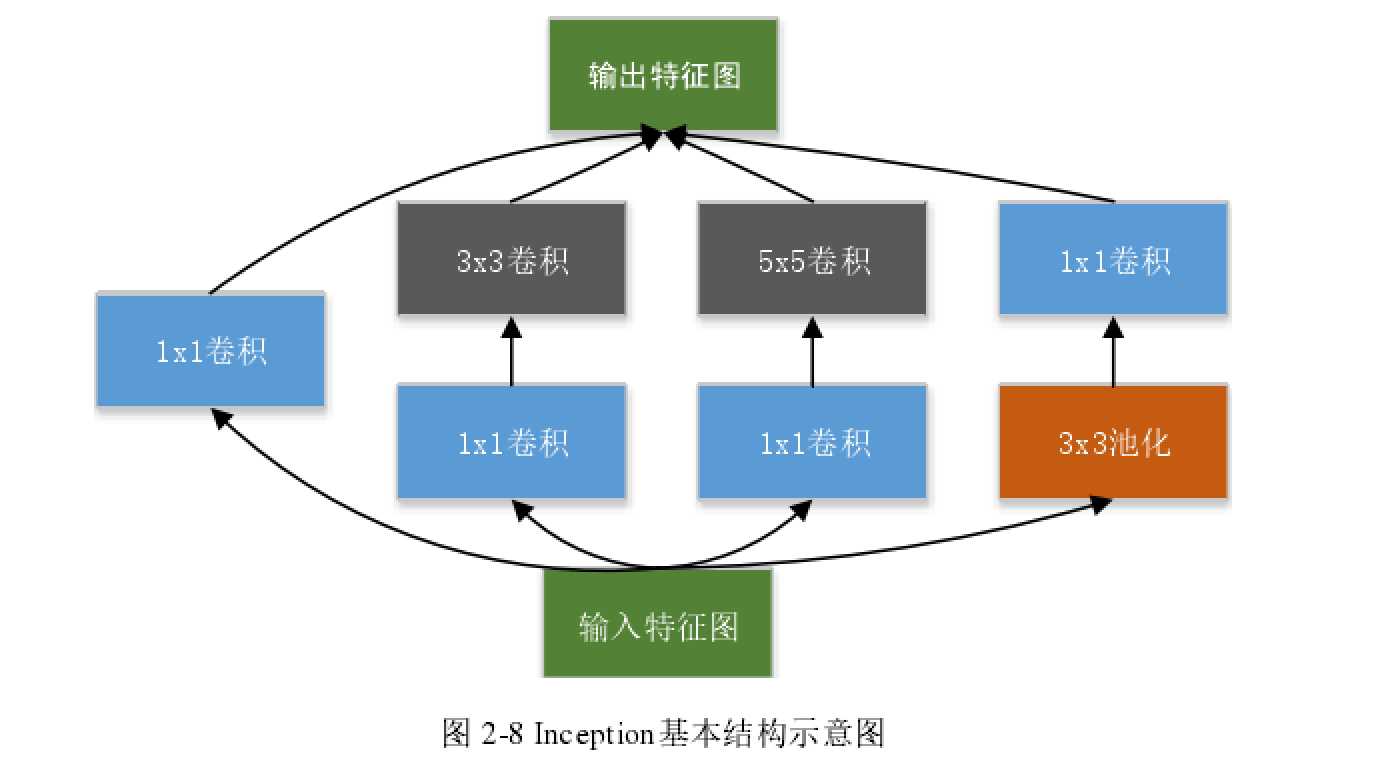
- Inception结构。Inception结构的特征有两点。一是使用了1x1卷积核,二是将卷积运
算分解为多个多个不同尺度的卷积核。前者参考了Network In Network的思想,通过1x1的卷积核合并卷积特征,减少网络参数,在有限内存下能够构建更深的网络。后者的主要思想是将同一个输入数据用多个尺度的卷积核进行卷积,然后再将结果合并,其出发点同样是减少网络参数,使得在相同资源的条件下能够搭建更深的网络模型。
- Highway结构。Highway[22]结构是具有跨层连接特征的结构。其主要的设计目的是为了训练更深层的网络。
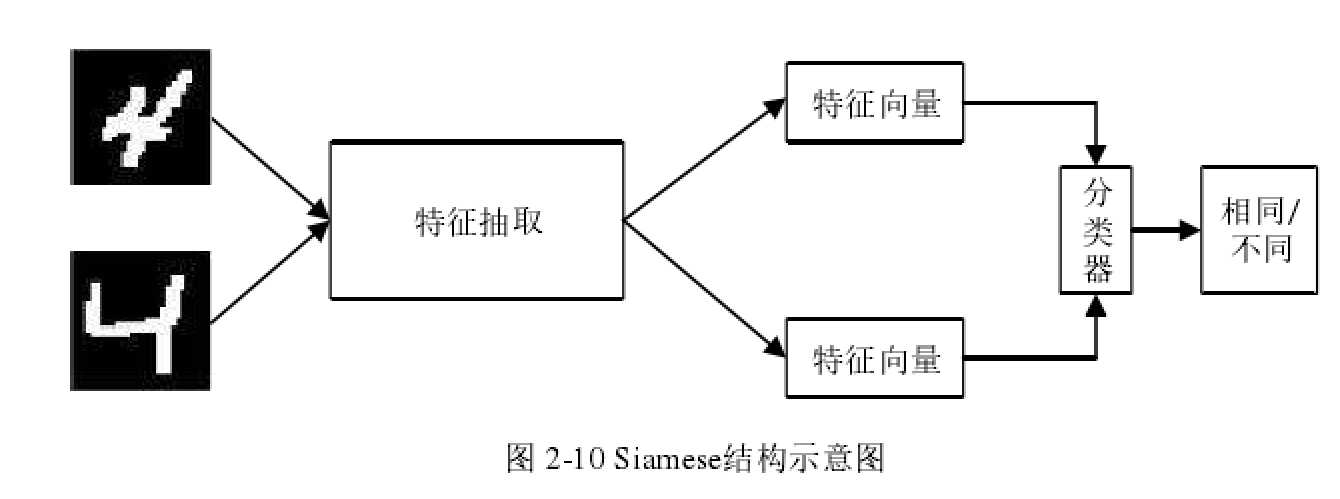
- Siamese结构。Siamese结构是常用于验证类问题,如人脸验证,指纹认证等问题的网络结
构,其基本思想是使用深度神经网络对待验证的图片进行特征提取,然后在末端比较其特征相似度。
- 生成对抗结构。生成对抗模型由生成器??和判别器??构成,生成器负责从一组隐变量??中生成伪样本,而判别器负责判别输入的样本是从训练集采样的真样本还是由生成器生成的伪样本。生成器的目的是尽量生成以假乱真的样本,使得判别器误判。而判别器的目的是避免生成器的迷惑,正确判断出样本的真伪。因此,整个生成判别模型可以表达为对(minlimits_Gmaxlimits_DV(D,G)=E_{xsim P_{data}}[log D(x)]+E_{zsim noise}[log(1-D(G(z)))])的最小化最大化问题的优化。当二者对抗达到平衡时,整个体系达到最优。此时生成器能够产生与真实数据近似同分布的样本。
2.4 常用深度学习技术
- 控制过拟合
- 过拟合和欠拟合
- 网络正则。一种经典的控制过拟合手段是对网络参数添加正则项。正则项可以看作是对网络参数的约束或惩罚,它能引导网络的参数朝某个规定的方向进行优化。常见的正则项有L1范数、L2范数、L1+L2约束(Elastic Net约束)等。
- 数据增强。数据增强是深度学习发展过程中提出的一种控制过拟合的方法。网络正则的方法是从降低模型复杂度的方面着手,而数据增强则从提升数据复杂度的方向着手。数据增强多用于图像处理领域,其基本思想是通过噪声、翻转、平移、旋转等方法,在不改变图片语义信息的前提下增加数据的多样性,从而抵消网络对训练集单个样本特征的关注度,提高模型泛化能力。数据增强特别适用于图像分类、目标识别等高级图像处理。
- Dropout。Dropout是一种随机断开神经元的技术,其具体内容前文已有介绍。Dropout控制过拟合的原理有两点。第一是在神经网络的局部构造集成学习模型,在处理测试集样本时,网络作出的推断实际上是不同神经元断开时的子网络所做出推断的平均。集成学习模型,如随机森林,梯度提升树等在控制过拟合上往往效果明显。第二是减少神经元之间的耦合,由于Dropout每次断开的神经元都不相同,这就阻止了神经元耦合起来提取同一种特征的可能性,使得网络在缺失一些信息的情况下仍然能够做出正确推断。
- EarlyStopping。EarlyStropping是一种在训练中使用的回调函数,其基本思想是在训练过程中监视神经网络在验证集上的性能,当验证集上的性能在连续的多轮训练中没有得到提高,则提前终止训练。EarlyStopping控制过拟合的原理是控制模型的拟合程度,在适当时机阻止模型继续学习而达到过拟合状态。当模型在验证集性能没有提示时,意味着训练集已经不能提供更多的提高模型泛化能力的信息了,若继续训练下去,模型会开始拟合训练集样本中的自身特点,从而进入过拟合。
- BatchNormalization。BatchNormalization的主要作用是加速网络的训练。但同时,它也具有一定的控制过拟合的能力。
- 激活函数。激活函数是深度学习的重要组件之一,它主要被设置在每一层神经元之后,对神经元的输出做非线性变换。常见的有Sigmoid和Tanh两种激活函数。$$Sigmoid(x)=frac{1}{1+e^{-x}}$$ $$ Tanh(x)=frac{ex-e{-x}}{ex+e{-x}}$$Sigmoid将神经元的输出映射到0到1的区间内,在许多场合可以当作概率解释,其物理意义也最接近生物神经元。Tanh将神经元输出映射到-1到1之间,具有关于原点对称的特性,这种特性对神经网络的优化有利。但两种激活函数都具有梯度消失的缺点,即函数在左右边缘区域导数接近于0,当输入落入左右边缘区(称为饱和区)时,会产生回传梯度消失的现象,不利于深层网络的训练。此外,两种激活函数都需要进行较多的指数运算,计算效率不高。为了解决Sigmoid和Tanh的梯度消失问题,研究者提出了修正线性单元ReLU(Rectified Linear Units)作为激活函数。$$ReLU(x)=max(0,x)$$在输入大于0的区域,函数表现为一条(?? = ??)的直线,在输入小于0的区域则将输出抑制到0。显然,ReLU对大于0的输入会产生恒为1的导数,因此有效抑制了梯度弥散问题。使用ReLU作为激活函数可以将网络堆叠较深,因为ReLU运算简单,效果显著,得到了广泛应用。但ReLU也有自身的缺点。首先,ReLU的输出形式不是0中心的,输出恒大于0会导致网络收敛性变差。其次,ReLU存在神经元死亡的问题,由于ReLU的输出恒大或等于0,如果出现梯度过大使神经元的输入权重为负,则该神经元不再产生大于0的输出,经过ReLU作用后的输出恒为0。因此,该神经元的权重将不能得到更新,这种情况称为神经元的“死亡”。神经元死亡问题会降低网络的表达能力,影响网络训练。为了解决ReLU带来的神经元死亡问题,研究人员提出了Maxout[23]和PReLU[24]。
- 网络训练
- 其他深度学习技术
- 目标函数
- 网络参数初始化
- 迁移学习
- 处理样本不均衡
三、 神经网络压缩
神经网络压缩的方法
- 基于张量分解的网络压缩。张量是向量和矩阵的自然推广,向量可称为一阶张量,矩阵可称为二阶张量,将矩阵堆叠形成“立方体”,这种数据结构则称为三阶张量。在神经网络中,参数通常以“张量”的形式集中保存。对全连接层而言,全连接通过权重矩阵将输入向量变换到输出向量,其参数为二阶张量。对卷积层而言,设输入数据为具有??通道的三阶张量。则卷积层中的每一个卷积核也都是具有??通道的三阶卷积核,故一层卷积层所包含的一组卷积核构成了形如?? ×?? ×?? × ??的四阶张量。基于张量分解的网络压缩的基本思想,就是利用张量分解的技术将网络的参数重新表达为小张量的组合。重新表达后的张量组一般能够在一定的精度下近似与原张量相同,而所占用的空间又得到大大降低,从而获得网络压缩的效果。文献[25]和文献[26]分别是利用张量CP分解和Tucker分解的网络压缩工作。文献[27]利用的是较新的Tensor Train分解方法,经过Tensor Train分解得到的张量组可以通过反向传播算法获得更新,实际上形成了一种占用空间更小的网络层。
- 基于量化的网络压缩。这里的量化主要包含两层含义,第一是用低精度参数代替高精度参数,对参数进行精度截取,其本质是均匀量化。第二是进行权重共享,限制网络权重可取的种类。有限的权重种类可以随后进行进一步编码,这种量化的手段本质是非均匀量化。
- 基于裁剪的网络压缩。基于张量分解和量化的网络压缩方法,其着眼点都是网络的参数。在网络压缩的过程中网络的拓扑结构保持不变。在基于裁剪的网络压缩中,网络的拓扑结构和数据的推断方法都可能发生改变。基于裁剪的网络压缩将直接改变网络的结构,其本质是将网络中的冗余部分剔除。依据裁剪对象的不同,网络裁剪可以分为层级裁剪,神经元级裁剪,神经连接级裁剪等多个粒度。
四、 渐次全局网络裁剪
算法

五、 实验结果
??作者训练了一个用于CIFAR-10图片分类的栈式神经网络。在迁移学习的场景下,使用VGG-16在ImageNet上的预训练权重作为迁移学习的模型,以Kaggle数据竞赛猫狗大战?为学习目标。
在栈式神经网络上比较了所提出的渐次裁剪框架与全局等比例裁剪的性能。以模型在验证集上的准确率作为模型性能的衡量指标。最后,选取一种冗余神经元筛选方法,在给定性能指标的情况下进行自动化裁剪,展示了渐次全局裁剪框架具有能够自动发现网络在给定性能指标下的近似最优结构的能力,并通过参数量与运算速度的比较检查网络裁剪的实际效果。
??经过多次实验,全局裁剪相对于逐层裁剪的有稳定的优势,但性能上的微弱优势并非是全局裁剪的主要优点。事实上,经过仔细试错的逐层裁剪能够达到比所提出的渐次全局裁剪更好的性能。作者强调,渐次全局裁剪的优势体现在计算复杂度低,以及不需要确定各层裁减比例两个方面。全局裁剪的方法将网络裁剪所需要的微调轮数从网络层数转移到网络裁剪步长上,使得对更深层的网络而言,网络裁剪的效率更高。
??在裁剪的过程中作者观察到,全连接层的裁剪对模型性能影响较小,而卷积层内的裁剪对模型性能影响较大。对全连接层的裁剪不但能够有效降低模型大小,而且能够最大限度的保持模型精度。此外,数据无关的冗余神经元筛选标准更适合于一般的应用场景,而在迁移学习场景下,数据相关的冗余神经元筛选标准更为适合,但经过几轮的裁剪后,由于微调过程对权重的调整,使得数据无关的评价准则也逐渐变得可用。
文献
以上是关于基本概念 深度神经网络压缩与优化研究_王征韬的主要内容,如果未能解决你的问题,请参考以下文章