深度学习下,中文分词是否还有必要?——ACL 2019论文阅读笔记
Posted NLP太难了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习下,中文分词是否还有必要?——ACL 2019论文阅读笔记相关的知识,希望对你有一定的参考价值。
深度学习下,中文分词是否还有必要?
原文:Is Word Segmentation Necessary for Deep Learning of Chinese
知乎讨论:https://zhuanlan.zhihu.com/p/65865071, https://www.zhihu.com/question/324672243/answer/715928859
Abstract
作者基于word级模型(word-based model,需要分词)和char级模型(char-based model,不需要分词),在四个NLP任务上做对比实验(语言模型、机器翻译、句子匹配和文本分类)。
实验结果显示,基于char级模型效果总是比word级模型效果好,作者基于这些实验结果给出了一些原因。
Experiments
作者在基于中文语料的四个NLP任务(语言模型、机器翻译、句子匹配和文本分类)上进行了对比实验,比较word级模型和char级模型在这四个任务上的效果。
1. 语言模型(Language Modeling)
实验结果:
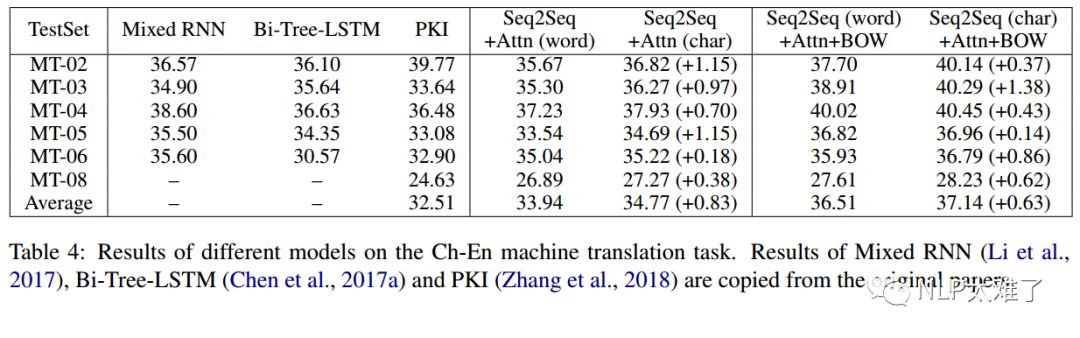
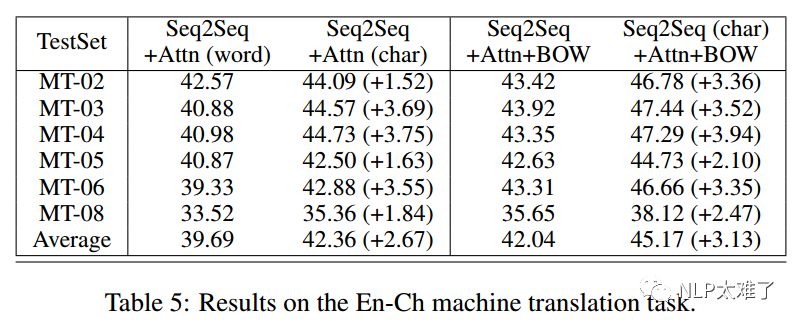
2. 机器翻译(Machine Translation)
实验结果:
3. 句子匹配/释义(Sentence Matching/Paraphrase )
4. 文本分类(Text Classification)
word级模型存在的缺陷
作者基于以上实验,探讨了word级模型可能存在导致效果下降的原因。
1. 数据稀疏(Data Sparsity)
在word级模型中,很多词出现的频率很低,导致产生了数据稀疏。而对于模型来说,要学习一个词的语义信息,需要词的数量需要达到一定量才行。因此,在word级模型中,神经网络并没有充分学习到很多单词的语义信息。
2. OOV词(Out-of-Vocabulary Words)
我们把不存在于词汇表中的词称为Out-of-Vocabulary Words,即OOV词。通常使用UNK这个记号来表示这些词。也可以对OOV词设置一个词频门限(frequency threshold),这样出现次数低于该门槛的词就称为OOV词。对于OOV词来说,因都将其归类为了UNK,我们就拿一个word embedding来表示UNK这一类后面的所有词,模型就比较困难去学习到它的语义信息。虽然我们可以设置一个比较低的门限,但是这样会导致数据集中出现很多词频低的词,产生数据稀疏问题。
作者也使用了实验证明了这个问题。即,将训练集、验证集和测试集中的所有OOV词都剔除。实验结果显示,随着剔除的OOV词数量越多,word级模型的效果就越好,而char级模型的效果越差。因此,作者的结论是:word级模型受OOV问题困扰,而char级模型不受该问题所困扰。在word级模型中,可以通过减少数据集中的OOV词数量来解决该问题。
3. 过拟合(Overfitting)
从数据稀疏问题中的讨论,我们可以得知word级模型会有更多的参数需要被学习到,因此更容易导致产生过拟合。作者使用了dropout技术来解决这个问题。但是,实验证明dropout技术不足以解决word级模型的过拟合问题。
Conclusion
在作者所做的四组实验来看,char级模型效果几乎均好于word级模型。作者将原因归结于word级模型的三点:1.数据稀疏;2.OOV词的存在;3.过拟合。
但作者的初心并不是下一个定性的结论,而是希望大家对这个问题能有更多的探讨,毕竟,我们之前在做NLP任务时,第一步就是无脑地直接分词,确实很少考虑其合理性。
以上是关于深度学习下,中文分词是否还有必要?——ACL 2019论文阅读笔记的主要内容,如果未能解决你的问题,请参考以下文章
推荐(TensorFlow)深度学习中文分词开源了!98%准确率的深度学习分词系统和语料
相比于深度学习,传统的机器学习算法难道就此没落了吗,还有必要去学习吗?