中文分词技术深度学习篇
Posted 58架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文分词技术深度学习篇相关的知识,希望对你有一定的参考价值。
在之前的一文中,我们沿着分词技术的发展介绍了几种有代表性的分词方法,主要包括词典分词、词典和统计结合的分词和基于统计模型的分词(CRF)。本篇将继续之前的脉络,介绍NLP领域当前更流行的一些方法,它们能处理NLP领域的大部分问题而并不局限于中文分词。
本篇所述的深度学习方法均是将分词作为序列标注任务来处理,如上篇的CRF分词。回顾CRF分词,其特点是通过人工配置的特征模板,有针对性的提取局部上下文特征,进而学习特征权重。这类以人类的先验知识将原始数据预处理成特征,然后输入模型学习的方式一般被称作传统或经典机器学习方式,后文也采用如是称谓。这种方式下,需要领域专家将大部分的精力放在特征的设计上,因此特征工程(feature engineering)对其尤为重要。与之相对的是“特征学习”(feature learning)或“表示学习”(representation learning)方式,可以通过深度神经网络模型来实现。
神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,这里的简单单元就是神经元(neuron)模型。神经元模型由线性加权连接和激活函数构成,连接权重则需要通过训练获得。神经元按一定的层次结构连接起来构成的神经网络就能达到特征学习的目的。按这个逻辑,通过加深网络互连的层次,模型可以学习到更多层次的特征表示,那么最终任务的效果就会越好。理论上亦仿佛如此,参数越多的模型复杂度越高、“容量越大”,这意味着它能完成更复杂的学习任务。但一般情形下,复杂模型的训练效率低,易陷入过拟合,因此难以受到人们的青睐。而随着云计算和大数据时代的到来,计算能力的大幅提升可缓解训练的低效性,训练数据的大幅增加则可降低过拟合的风险。因此,这类深度复杂模型开始“大行其道”。
NLP领域的任务大多都是句子层面的任务,处理目标是一句话或一篇文章,而中文文本中涉及到词法、句法、语义等复杂的特征,单靠人的先验知识来提取,是难以做到很全面的。因此,表示学习这种让模型从数据中学习好特征的方式在NLP领域成为了更流行方法。神经网络模型一般分为输入层、隐层和输出层,其核心或者说深度的体现则在隐层,因此隐层的结构尤为重要,它决定了特征提取的好坏。比如我们耳熟能详的CNN、RNN等,在图像领域更多的会使用CNN,而NLP领域则更多的使用RNN。
BiLSTM+CRF分词方法
模型介绍
在介绍BiLSTM之前,先了解下RNN、LSTM、BiLSTM的关系。RNN结构可简化如下图,其具有一种重复神经网络模块(图中隐层节点A)的链式结构。每个输入对应隐层节点,隐层节点之间形成有向的线性序列,隐层节点的输出取决于输入和前一个节点的状态输出。RNN之所以能流行于NLP并占据过主导地位,主要还是源于RNN的结构天然适配处理NLP中的不定长序列问题。下图右部分所示结构即可解决序列标注问题,比如分词、词性标注、实体识别和语义标注等。
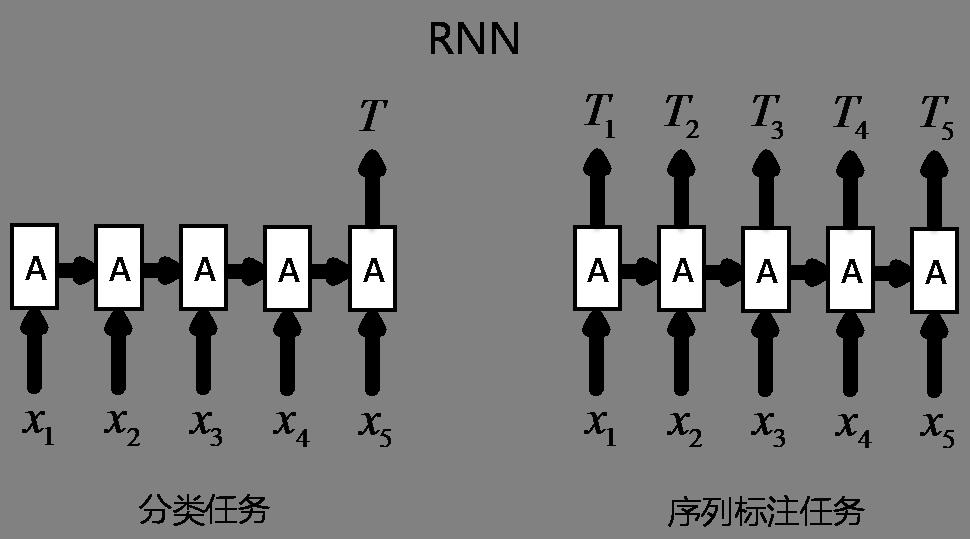
LSTM是RNN的一种特殊类型,其总体结构也如上图,而与标准的RNN的区别则在于重复神经网络模块的结构不同。LSTM通过刻意的设计来避免长期依赖问题,而标准的RNN为实现长期依赖往往需要更大的代价(难于训练)。BiLSTM则是两个不同方向的LSTM累加而成,可以同时捕获过去特征和未来特征。BiLSTM本身已经可以处理序列标注问题,下图给出了其结构,右部分为BiLSTM单元的局部结构图。
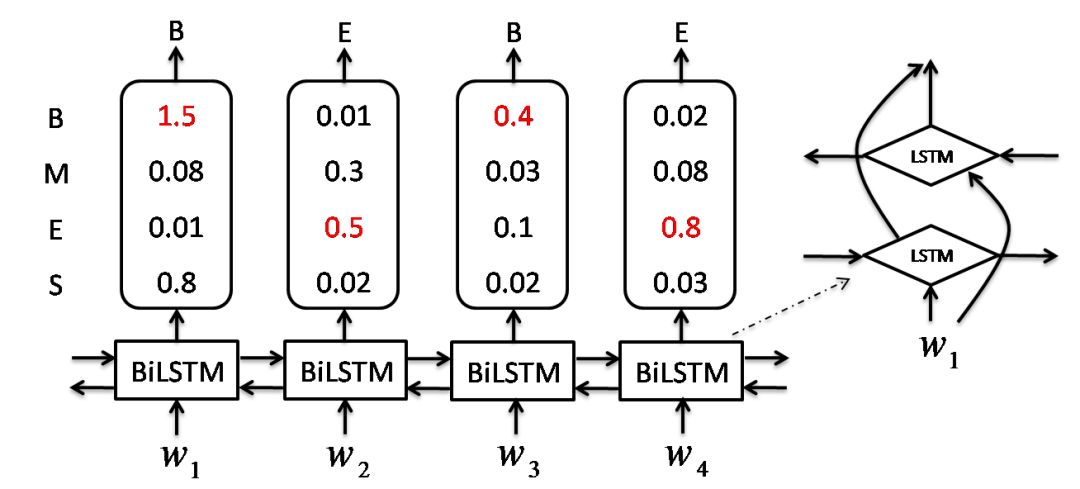
输入为字序列,每个字可以表示为Word Embedding,可以由外部的模型预训练获得(直接使用),比如Word2Vec、GloVe等,也可以通过在本模型中直接作为参数来训练。这里需要指定Word Embedding的维数dim_embedding。BiLSTM层需要指定三个参数:1)BiLSTM的最大链长num_steps(或称时间步数,即模型能处理文本序列的最大长度);2)BiLSTM层数num_layers,一层BiLSTM由一左向一右向的LSTM层构成;3)LSTM单元中各网络模块(LSTM单元中有4个网络模块)的隐层节点数hidden_size,则各LSTM单元输出的状态向量的维数也是hidden_size。输出层需加一个softmax层,将隐层输出映射为字被标为各标签的概率,这里需要指定标签的个数num_labels。
这种结构用来解决序列标注问题时,还有个小问题,对每个字,模型都能预测到它对应最大概率的标签,但最终的得到标注序列并不一定最优。比如会出现下图这种情形。
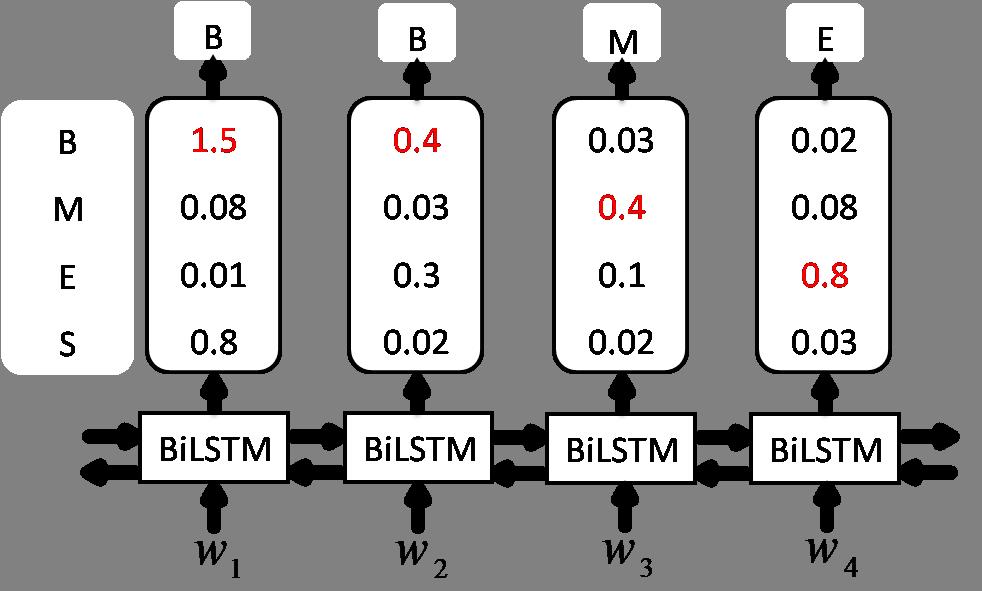
最终会预测出“BBME”这种明显错误的序列。此时若再加一层CRF,考虑到转移概率则能有效避免此类情形,完整结构如下。
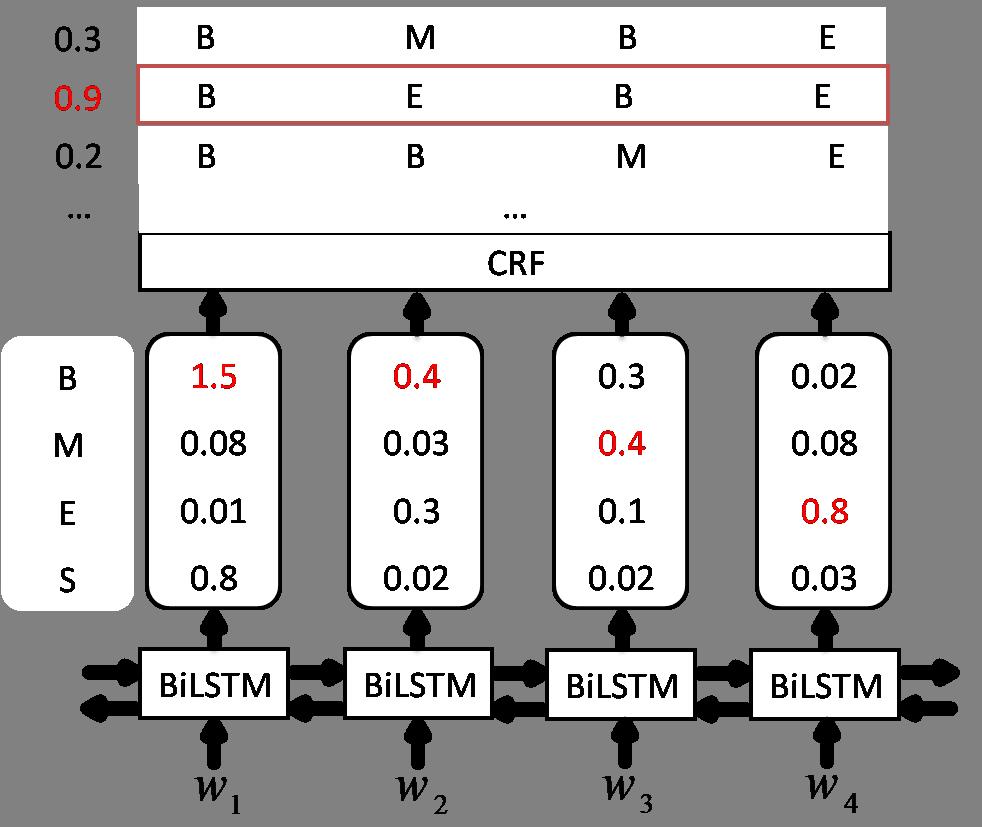
对每一个输入序列X,其标注为序列y的得分为:
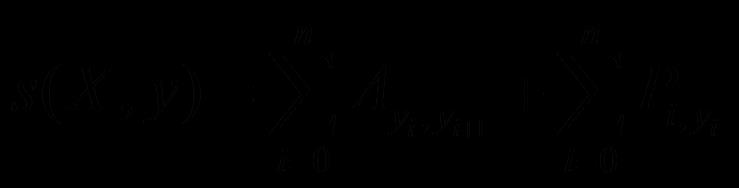
式中P为字被标注对应标签的概率;A为转移概率矩阵。得分经过归一化可得标注序列的概率:
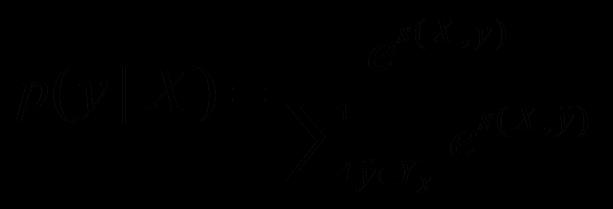
式中Yx为输入序列X所有可能的标注序列的集合。则损失函数可表示为:
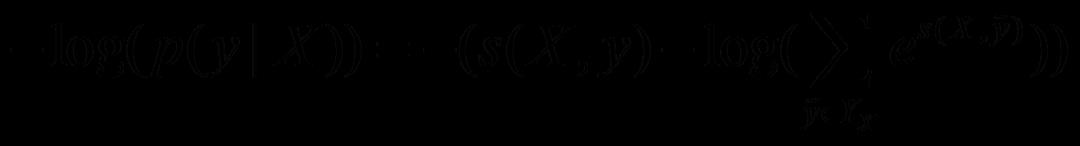
损失函数最小则意味着真实的标注序列概率最大,优化该损失函数即可求解模型参数。
当模型训练完毕后,根据训练好的参数求出对应最大得分的标注序列y即为最终结果,这里也可使用维特比算法求解。预测过程即求解下式:
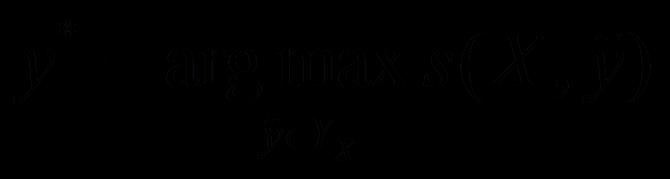
模型训练
模型训练我们采用TensorFlow框架实现,训练数据为人工标注的58场景语料以及少量的人民日报对齐语料总计在30w句。下面按实现过程提几点需要注意的细节问题:
训练前需准备两份数据:训练样本(包括输入的文本序列和输出的标签序列)和WordEmbedding。如果有外部WE,则在模型初始化时读入,并锁定即不作为训练的参数,如果没有,则需初始化WE,并作为参数参与训练。
设定序列最大长度为num_steps,那么在Embedding输入文本时,超出部分需截断,不足则应Padding。批量训练的话,则一次喂给BiLSTM层的数据大小是batch_size*num_steps*embedding_size。
TensorFlow中有定义好的基础LSTM单元和多层RNN网络单元,只要设定好num_layers、hidden_size和drop_out就能方便的构建BiLSTM层。每个LSTM单元输出hidden_size大小的向量,因为是双向,则BiLSTM层输出的数据大小为batch_size*num_steps*2*hidden_size。BiLSTM层上套全连接softmax层,得到各节点的标注概率,数据大小为batch_size*num_steps*num_classes,num_classes为标签个数。
CRF层需要提供的就是状态转移矩阵,结合softmax层输出的节点标注概率,按上部分推出的公式则可计算任一标注序列的得分,进而求得归一化概率。代入样本即可求得损失值,实现中使用AdamOptimizer来优化损失值。
BiLSTM模型中还有个比较关键的地方在WordEmbedding的选择上,之前也说过WE可以从外部模型获取,比如Word2Vector、GloVe等,然后直接使用,也可以在模型训练中作为参数学习。两种方式我们都有尝试,其中第一种方式使用的是58场景的语料训练的Word2Vec模型,最终结果是后一种方式分词效果更好。不过这也不能否定第一种方式,可能是我们预训练的Word Embedding本身不佳。按目前的趋势,通过预训练加迁移学习的模式在很多NLP任务都表现的很优秀。也就是说如果你有一个很好的外部Word Embedding,然后使用BiLSTM+CRF模型有可能会有更好的效果。下面篇幅的内容也能体现这一点。
基于BERT的分词方法
模型介绍
BERT的大名相信很多人都听说过,它应该是目前通过大规模语料预训练语言模型来解决具体的NLP问题这种方式的最优秀代表了。在BERT之前这种处理问题的方式就已经存在了,这里先以LSTM为例来简单介绍下这种方式,方便过渡。
上部分有提到,LSTM是可以用做语言模型的,其结构可如下图。
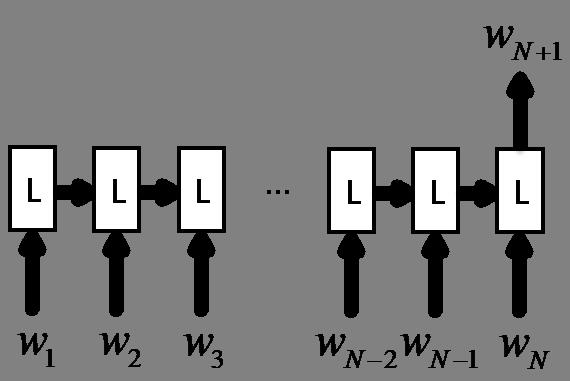
输入是一句话的前N个字序列,输出是第N+1个字。语言模型的训练是一个无监督训练的过程,可以很方便的获取大量样本数据,学习到丰富的语言特征。细心的读者可能发现了上图的结构也很适合做文本分类的任务,只需稍稍改动下输出层的结构。比如语言模型训练时输出层通过全连接将隐层变量映射到字典空间,而分类任务则是映射到标签维度(比如0和1),而他们的输入和隐层结构基本一致。预训练的思想就是先通过大量的文本按语言模型的方式预训练模型参数,然后改造输出层结构即可直接用于分类任务。之前训练好的参数此时可作为分类任务的初始化参数,然后将分类任务的样本数据喂给模型来微调网络参数(fine-tune)。这样做有几个好处:1)在只有少量标注数据的情况下,也能使用复杂的模型;2)加快训练速度;3)充分利用了大量的文本语料训练而来的语言特征。
预训练除了fine-tune这种操作外,另一种有效的方式是将预训练得到的网络参数比如词嵌入(Word Embedding),直接迁移到另一个具体任务(其模型结构可以与原模型完全不同)中直接使用。BERT的文章中也提到fine-tune的方式要略优于后者。因此我们使用的也是fine-tune方式。
NLP任务大致可分为四大类:1)序列标注,比如分词、实体识别、语义标注等;2)分类任务,比如文本分类、情感分析、文本相似性等;3)句子关系判断,比如QA、自然语言推理等;4)生成式任务,比如机器翻译、摘要等。而BERT可以解决前三类中的大部分问题,并且在很多的任务中都有当前最佳表现。BERT模型是一个多层双向的Transformer编码器结构,其简化结构图如下。
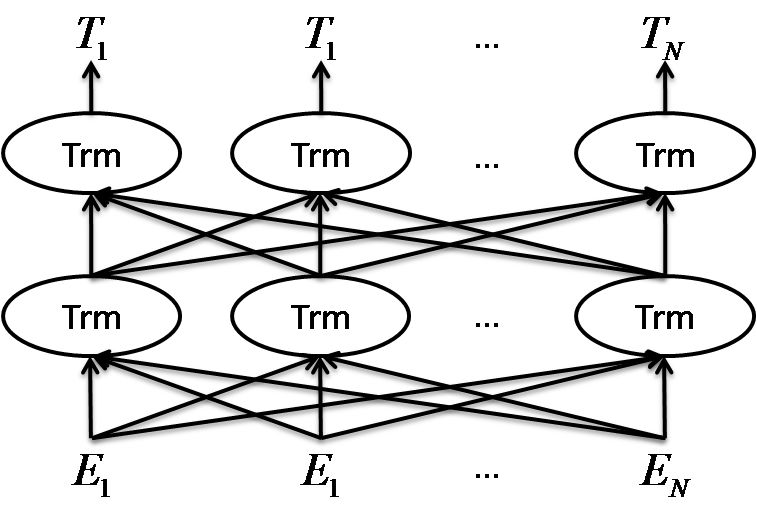
可以看出,这个图和前面BiLSTM用作序列标注任务时的结构有些相似。主要区别是隐层使用的基本单元不一样,BERT中使用的是Transformer,输入和隐层之间均是全连接,同层各Transformer之间没有信息传递,这种连接结构也是由Transformer的特性决定的。Transformer是目前NLP领域最优秀的特征抽取器,其本质是自注意力机制(self-attention)的叠加,该模型由Google 团队在Attentionis all your need论文中提出。
注意力机制最早是在图像领域提出来的,它们认为要对一个场景做出一种特定判断时,往往不需要关注场景的所有区域,关注某几个区域就足以做出该判断。比如给你一个人像图,让你判断喜欢与否,为了快速而准确的识别(注意力资源是有限的),那么你只需关注某几个位置就足以做出判断了,而可以忽略其他位置信息的干扰。注意力模型简单概括下就是,给予需要重点关注的目标区域更重要的注意力(可理解为权重),同时给予周围的区域更低的注意力。
在NLP领域,最早是有效的应用在了机器翻译的任务上:为了预测目标句子(翻译之后的句子)中某个位置的词,使用注意力向量(权重向量)来估计它与源句子(被翻译的句子)中各词的相关程度有多强,并将其加权总和作为目标词的近似值。比如源句“machine learning”翻译为目标句子“机器学习”,则翻译“机”、“器”时更关注“machine”,“学”、“习”时更关注“learning”。
Transformer使用的是自注意力机制,从机器翻译中可理解到注意力机制是目标句子中各词和源句子中各词间的相关性程度,那么自注意力则是描述同一句子中各词之间的相关关系,也就是说该句子既是源也是目标。每个位置的目标向量就是其他各位置词向量与注意力权重的加权总和。回想下RNN的结构,字与字之间的相关作用需要经过线性结构一步一步传递过来,而Transformer这种注意力机制使得每个字与其他各字的作用都是一步直达的。这种构造也使得Transformer是可以并行计算的,而RNN很难做这一点。
我们再来看一下Transformer的编码器(完整的还包括了解码器模块,BERT中仅使用了编码器部分)结构如下图所示。
第一层是Multi-HeadAttention,所谓多头可以理解为有多组注意力权重,则每个位置可得到多个目标向量,然后将这多个目标向量拼接成一个向量即为该层输出,这可能是作者认为词与词之间会存在多种相关关系吧。再之上是一层前馈神经网络,目的是让模型中的参数有更多的互动。每个子层采用残差连接和层规范化,便于训练。多层Transformer互连即构成了BERT模型。
官方给出了BERT base和BERT large两种模型,我们使用的是中文的BERT base模型,隐层深度(Transformer叠加的层数)layer=12,hidden_size=768(Transformer输出向量维度),多头个数为12,整个模型约110M参数,我们可直接使用官方训练好的预训练模型。
除了隐层的特色结构外,BERT在输入、输出层的细节设计上也做了些精巧的设计,比如在每个文本输入的首位加了CLS向量位(用于分类任务),在文本中间加了SEP向量位(用于句子关系判断任务)用于区分前后是否分别为两个句子等。在模型训练上,他们不再使用标准的从左到右预测下一个词作为目标任务,而是提出了两个新的任务:一个是随机挡住句子中的部分词,然后去预测挡住的词;另一个任务是预测下一个句子,即预测输入的两个句子是不是NEXT关系,是个分类任务。大概也是这几点巧妙的设计在配合大量的文本语料造就了BERT的强势表现吧。更详细的介绍可阅读原文或其他的介绍文章,这里不详细介绍了。
模型训练
基于BERT的模型训练,我们要做的主要事情就是在自己的数据集上进行fine-tune。下面也按照流程简要描述些细节问题:
在github上Google的开源项目中可下载源码和已经训练好的中文的BERT base模型,里面主要包含了checkpoint文件和vocab.txt词典文件。
源码中已经提供了用于分类任务的fine-tune实现run_classsifier.py,对于序列标注任务其中的大部分可复用,只需在样本数据的处理和最后损失值的计算需要稍做修改。首先,我们需要针对自己的分词样本数据实现对应的processor,对于输入侧都是一句文本(如果是上下两句文本则以SEP分隔,分词任务为一句文本),处理是一致的,区别在于标签,分类输出一个标签,而序列标注输出为一组标签。
分类任务隐层的输出取的是CLS位对应的输出,源码中通过get_pooled_output()获取,其数据大小应该为batch_size*hidden_size,而序列标注时,应该获取隐层CLS位之后的整个序列的输出,可通过get_sequence_output()获取,则其数据大小为batch_size*num_steps*hidden_size。
输出层都是softmax层,将隐变量(维度hidden_size)映射为各标签的概率值(维度为4),概率取负则为损失值,累加所有样本、序列所有位置的损失值之和则为本次输入样本的总损失。
最后再介绍下对比实验的结果,总的来说BERT较传统的CRF模型在效果上有明显的提升,在我们目前最大的数据量上(训练数据26w句,测试数据4w句)测试,准确率和召回率可达到96%-97%,较CRF提升了1%-2%。当标注数据比较匮乏时,BERT优势更为明显,较CRF可以提升4%以上。在性能方面,前面提到Transformer是支持并行计算的,更适合发挥GPU的性能。我们通过Tensorflow Serving(源码中输出的模型为checkpoint格式,需要将其转换为SavedModel格式)部署了BERT分词模型的在线预测服务(模型的最大序列长度为64),在CPU上单次请求平均耗时在250ms,在P40 GPU上单次请求平均耗时为10ms,qps增加到400左右时,能打满GPU。
结语
以上是关于中文分词技术深度学习篇的主要内容,如果未能解决你的问题,请参考以下文章