深度学习在自然语言处理方面的运用都有哪些?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习在自然语言处理方面的运用都有哪些?相关的知识,希望对你有一定的参考价值。
深度学习在自然语言处理中的应用已经非常广泛,可以说横扫自然语言处理的各个应用,从底层的分词、语言模型、句法分析等到高层的语义理解、对话管理、知识问答、聊天、机器翻译等方面都几乎全部都有深度学习的模型,并且取得了不错的效果。可以参看ACL2017年的accepted papers list。Accepted Papers, Demonstrations and TACL Articles for ACL 2017。从这里可以看到大部分论文都使用了深度学习的模型。那为什么深度学习在自然语言中取得这么大的进步呢。一、从数据上看,经过前些年互联网的发展,很多应用都积累到了足够量的数据。当数据量增大,以SVM、CRF等为代表的浅层模型,因为模型较浅,无法对海量数据中的非线性关系进行建模,所以不能带来性能的提升。相反,以CNN、RNN为代表的深度模型,能够随着模型复杂性的增加,对数据进行更精准的建模,从而得到更好的效果。二、从算法上看,深度学习也给自然语言处理的任务带来了很多好处。首先,word2vec的出现,使得我们可以将word高效的表示为低维稠密的向量(distributed representation),相比于独热表示表示(one-hot-representation),这一方面一定程度上缓解了独热表示所带来的语义鸿沟的问题,另一方面降低了输入特征的维度,从而降低了输入层的复杂性。其次,由于深度学习模型的灵活性,使得之前比较复杂的包含多流程的任务,可以使用end to end方法进行解决。比如机器翻译任务,如果用传统的方法,需要分词模块、对齐模块、翻译模块、语言模型模块等多个模块相互配合,每个模块产生的误差都有可能对其他模块产生影响,这使得原来的传统方法的构建复杂度很大。在机器翻译使用encoder-decoder架构后,我们可以将源语言直接映射到目标语言,从而可以从整体上优化,避免了误差传递的问题,而且极大的降低了系统的复杂性。深度学习虽然是把利器,但是并不能完全解决自然语言中的所有问题,这主要是由于不同于语音和图像这种自然界的信号,自然语言是人类知识的抽象浓缩表示。人在表达的过程中,由于背景知识的存在会省略很多的东西,使得自然语言的表达更加简洁,但这也给自然语言的处理带来很大的挑战。比如短文本分类问题,由于文本比较简短,文本所携带的信息有限,因此比较困难。像这样的问题,当样本量不够时,如何将深度学习方法和知识信息进行融合来提升系统的性能,将是未来一段时间内自然语言处理领域研究的主要问题。
目前,模型方面有两种大的类型,一是基于检索的 Retrieval-based models ,二是生成式的 Generative models。Retrieval-based models 预先定义好知识库,根据输入和上下文语境,使用启发式算法在预先准备好的知识库中检索并生成答案。启发式的检索算法简单的如基于规则的表达式匹配,复杂点的用机器学习分类器。这种系统不会生成新的文本内容,它只是在预定义好的文本集中挑选“最适合”的应答。Generative models 不依赖预定义的知识库,实现起来也更难。两种模型都各有所长,但也有缺点。两种模型中都有用到深度学习的地方,研究方面更倾向于和Generative models结合,比如sequence to sequence([1409.3215] Sequence to Sequence Learning with Neural Networks)模型能生成文本,看起来也更智能。产品方面更多使用Retrieval-based models,因为后者更容易实现,不会有语法错误,同时也限定了应用场景,以减小准备知识库的开销。
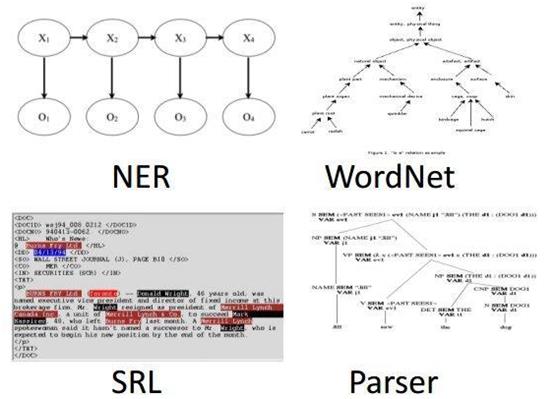
现在neural network这么火,基本上你能想到的NLP task都被刷过了。只是跟vision那边用到的network相比不一定很“深”。下面列一些有代表性的工作:机器翻译(Machine Translation)papers.nips.cc 的页面。事实问答(Factoid Question Answer)例如提问“谁是现任美国总统” 回答“奥巴马”stanford.edu 的页面umd.edu 的页面。社区类型问答(Community-based Question Answering),帮你找到一个语义上尽量类似的提问、或者回答。arxiv.org 的页面http://arxiv.org/pdf/1511.04108v3.pdf。语法解析(Syntactic Parsing)输入一个句子,分析句子的语法结构http://www.petrovi.de/data/acl15.pdfstanford.edu 的页面。信息提取、序列标注(Information Extraction / Tagging)从句子中抽取特殊片段(比如人名),或者标注每个单词类型(例如词性标注)emnlp2014.org的页面aclweb.org 的页面。分类问题:情感分析,文档分类比如判断淘宝京东商品评论是正面的还是负面的;当前新闻是体育相关还是财经相关等等。推荐系统:文档推荐,娱乐内容推荐(电影等, 用text mining)。图片题注: Image captioning, Image to text mapping。
常见的场景分类算法都有哪些
参考技术A 【嵌牛导读】:本文主要介绍一些常见的基于深度学习的场景分类【嵌牛鼻子】:深度学习,场景分类
【嵌牛提问】:基于深度学习的常见分类算法有哪些?
【嵌牛正文】:
目前出现的相对流行的场景分类方法主要有以下三类:
这种分类方法以对象为识别单位,根据场景中出现的特定对象来区分不同的场景;
基于视觉的场景分类方法大部分都是以对象为单位的,也就是说,通过识别一些有
代表性的对象来确定自然界的位置。典型的基于对象的场景分类方法有以下的中间步骤:
特征提取、重组和对象识别。
缺点:底层的错误会随着处理的深入而被放大。例如,上位层中小对象的识别往往会受到下属层
相机传感器的原始噪声或者光照变化条件的影响。尤其是在宽敞的环境下,目标往往会非常分散,
这种方法的应用也受到了限制。需要指出的是,该方法需要选择特定环境中的一些固定对
象,一般使用深度网络提取对象特征,并进行分类。
除了传统的卷积层、pooling层、全连接层。AlexNet加入了
(1)非线性激活函数:ReLU;
(2)防止过拟合的方法:Dropout,Dataaugmentation。同时,使用多个GPU,LRN归一化层。
不同于AlexNet的地方是:VGG-Net使用更多的层,通常有16-19层,而AlexNet只有8层。
同时,VGG-Net的所有 convolutional layer 使用同样大小的 convolutional filter,大小为 3 x 3。
提出的Inception结构是主要的创新点,这是(Network In Network)的结构,即原来的结点也是一个网络。
在单层卷积层上使用不同尺度的卷积核就可以提取不同尺寸的特征,单层的特征提取能力增强了。其使用之后整个网络结构的宽度和深度都可扩大,能够带来2-3倍的性能提升。
ResNet引入了残差网络结构(residual network),通过在输出与输入之间引入一个shortcut connection,而不是简单的堆叠网络,这样可以解决网络由于很深出现梯度消失的问题,从而可可以把网络做的很深。这种方法目前也是业界最高水准了。
首先通过目标候选候选区域选择算法,生成一系列候选目标区域,
然后通过深度神经网络提取候选目标区域特征,并用这些特征进行分类。
技术路线:selective search + CNN + SVMs
算法:Fast-R-CNN
步骤:输入一幅图像和Selective Search方法生成的一系列Proposals,通过一系列卷积层
和Pooling层生成feature map,然后用RoI(region ofineterst)层处理最后一个卷积层
得到的feature map为每一个proposal生成一个定长的特征向量roi_pool5。
RoI层的输出roi_pool5接着输入到全连接层, 产生最终用于多任务学习的特征并用于
计算多任务Loss。
全连接输出包括两个分支:
1.SoftMax Loss:计算K+1类的分类Loss函数,其中K表示K个目标类别。
2.RegressionLoss:即K+1的分类结果相应的Proposal的Bounding Box四个角点坐标值。
最终将所有结果通过非极大抑制处理产生最终的目标检测和识别结果。
Faster-R-CNN算法由两大模块组成:1.PRN候选框提取模块 2.Fast R-CNN检测模块。
其中,RPN是全卷积神经网络,通过共享卷积层特征可以实现proposal的提取;
FastR-CNN基于RPN提取的proposal检测并识别proposal中的目标。
这类方法不同于前面两种算法,而将场景图像看作全局对象而非图像中的某一对象或细节,
这样可以降低局部噪声对场景分类的影响。
将输入图片作为一个特征,并提取可以概括图像统计或语义的低维特征。该类方法的目的
即为提高场景分类的鲁棒性。因为自然图片中很容易掺杂一些随机噪声,这类噪声会对
局部处理造成灾难性的影响,而对于全局图像却可以通过平均数来降低这种影响。
基于上下文的方法,通过识别全局对象,而非场景中的小对象集合或者准确的区域边界,
因此不需要处理小的孤立区域的噪声和低级图片的变化,其解决了分割和目标识别分类方法遇到的问题。
步骤:通过 Gist 特征提取场景图像的全局特征。Gist 特征是一种生物启发式特征,
该特征模拟人的视觉,形成对外部世界的一种空间表
示,捕获图像中的上下文信息。Gist 特征通过多尺度
多方向 Gabor 滤波器组对场景图像进行滤波,将滤波后
的图像划分为 4 × 4 的网格,然后各个网格采用离散傅
里叶变换和窗口傅里叶变换提取图像的全局特征信息。
以上是关于深度学习在自然语言处理方面的运用都有哪些?的主要内容,如果未能解决你的问题,请参考以下文章