漫画:什么是MapReduce?
Posted ItStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了漫画:什么是MapReduce?相关的知识,希望对你有一定的参考价值。


————— 第二天 —————






————————————



什么是MapReduce?
MapReduce是一种编程模型,其理论来自Google公司发表的三篇论文(MapReduce,BigTable,GFS)之一,主要应用于海量数据的并行计算。
MapReduce可以分成Map和Reduce两部分理解。
1.Map:映射过程,把一组数据按照某种Map函数映射成新的数据。
2.Reduce:归约过程,把若干组映射结果进行汇总并输出。
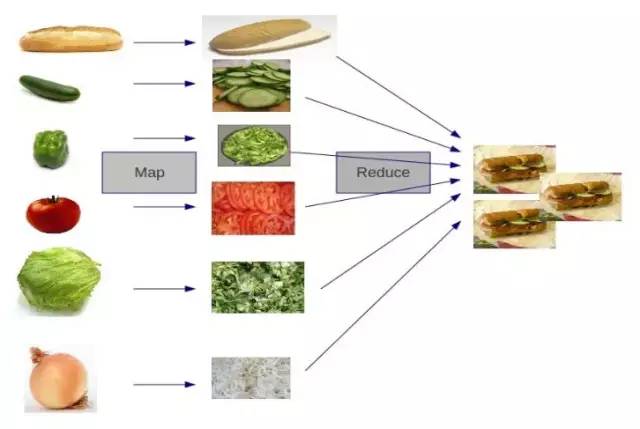
让我们来看一个实际应用的栗子,如何高效地统计出全国所有姓氏的人数?
我们可以利用MapReduce的思想,针对每个省的人口做并行映射,统计出若干个局部结果,再把这些局部结果进行整理和汇总:
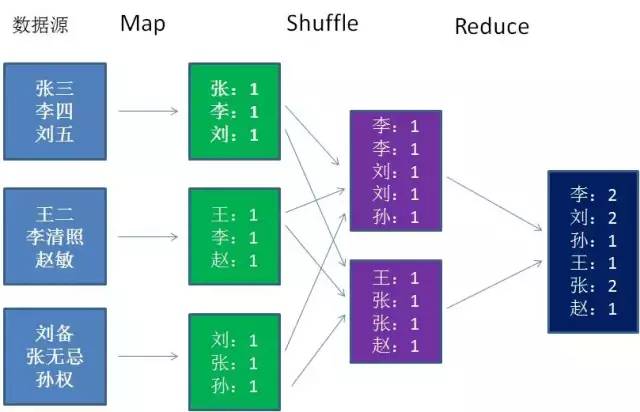
这张图是什么意思呢?我们来分别解释一下步骤:
1.Map:
以各个省为单位,多个线程并行读取不同省的人口数据,每一条记录生成一个Key-Value键值对。图中仅仅是简化了的数据。
2.Shuffle
Shuffle这个概念在前文并未提及,它的中文意思是“洗牌”。Shuffle的过程是对数据映射的排序、分组、拷贝。
3.Reduce
执行之前分组的结果,并进行汇总和输出。
需要注意的是,这里描述的Shuffle只是抽象的概念,在实际执行过程中Shuffle被分成了两部分,一部分在Map任务中完成,一部分在Reduce任务中完成。

Hadoop如何实现MapReduce?

Hadoop是Apache基金会开发的一套分布式系统框架,包含多个组件,其核心就是HDFS和MapReduce。
由于篇幅原因,文本不会对Hadoop做完整的介绍,只是简单介绍一下Haddoop框架当中如何实现MapReduce。
下面这张图是Hadoop框架执行一个MapReduce Job的全过程:
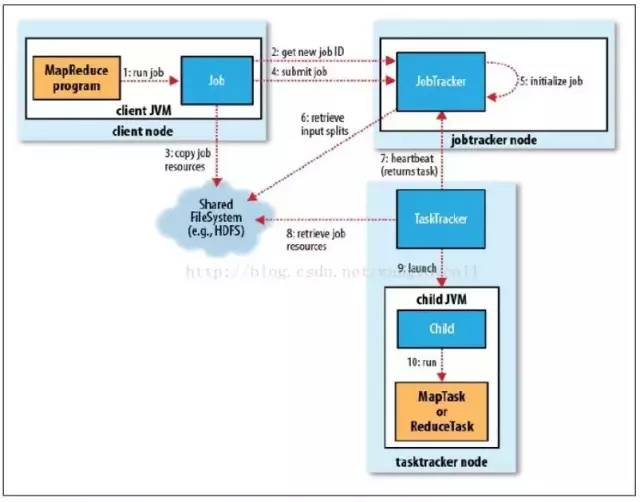
这里需要对几种实体进行解释:
HDFS:
Hadoop的分布式文件系统,为MapReduce提供数据源和Job信息存储。
Client Node:
执行MapReduce程序的进程,用来提交MapReduce Job。
JobTracker Node:
把完整的Job拆分成若干Task,负责调度协调所有Task,相当于Master的角色。
TaskTracker Node:
负责执行由JobTracker指派的Task,相当于Worker的角色。这其中的Task分为MapTask和ReduceTask。



以上是关于漫画:什么是MapReduce?的主要内容,如果未能解决你的问题,请参考以下文章
漫画揭秘Hadoop MapReduce | 轻松理解大数据