什么是MapReduce?MapReduce整体架构搭建使用介绍
Posted IT行业小趴菜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是MapReduce?MapReduce整体架构搭建使用介绍相关的知识,希望对你有一定的参考价值。
文章目录
- 前言
- reduce阶段
- 总结:仰天大笑出门去,我辈岂是蓬蒿人
前言
本文是MapReduced的详细介绍,MapReduce是hadoop体系下的一种计算模型(计算框架|编程框架),主要是用来对存储在hdfs上的数据进行统计,分析的,分布式计算框架,用来解决分布式大数据平台下数据如何计算,资源调度,任务监控 主要用来整合hadoop集群中的资源(CPU 内存),进行统一调度 同时监控任务的执行情况,联合多个服务器节点的硬件,共同完成一个计算。突破单机服务器的计算能力,还介绍了Yarn分布式集群搭建使用,MapReduce工作的原理源码分析
MapReduce
入门
MapReduce是hadoop体系下的一种计算模型(计算框架|编程框架),主要是用来对存储在hdfs上的数据进行统计,分析的。
MapReduce的核心思想
分而治之:大任务拆分小任务。
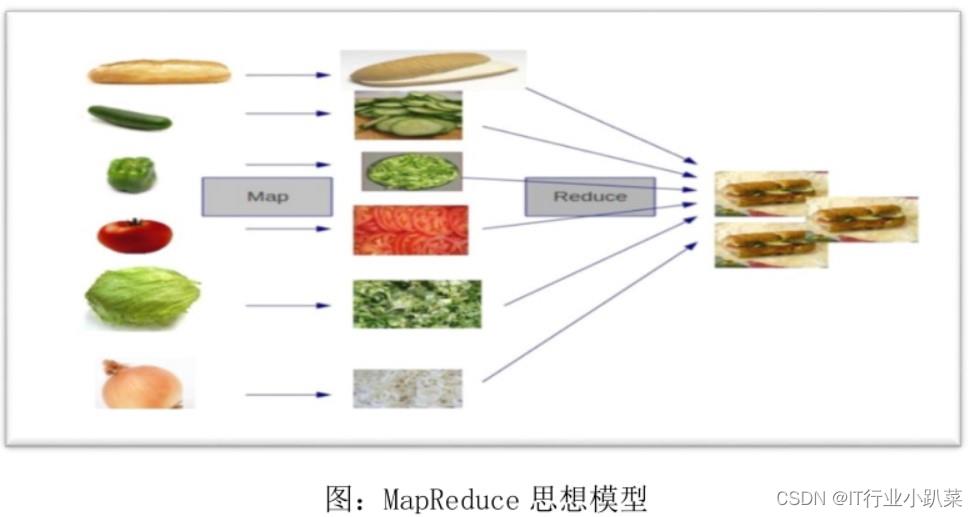
MapReduce
概念:分布式计算框架,用来解决分布式大数据平台下数据如何计算。
简单:分而治之
Job
MapTask * 多个并行
ReduceTask
- Job(一个大型任务)[Application]
一组MapReduce又统称为一个Job作业- MapTask(拆分后的小任务)
局部计算 并行- Reduce(整合任务)
对局部计算结果进行汇总计算。
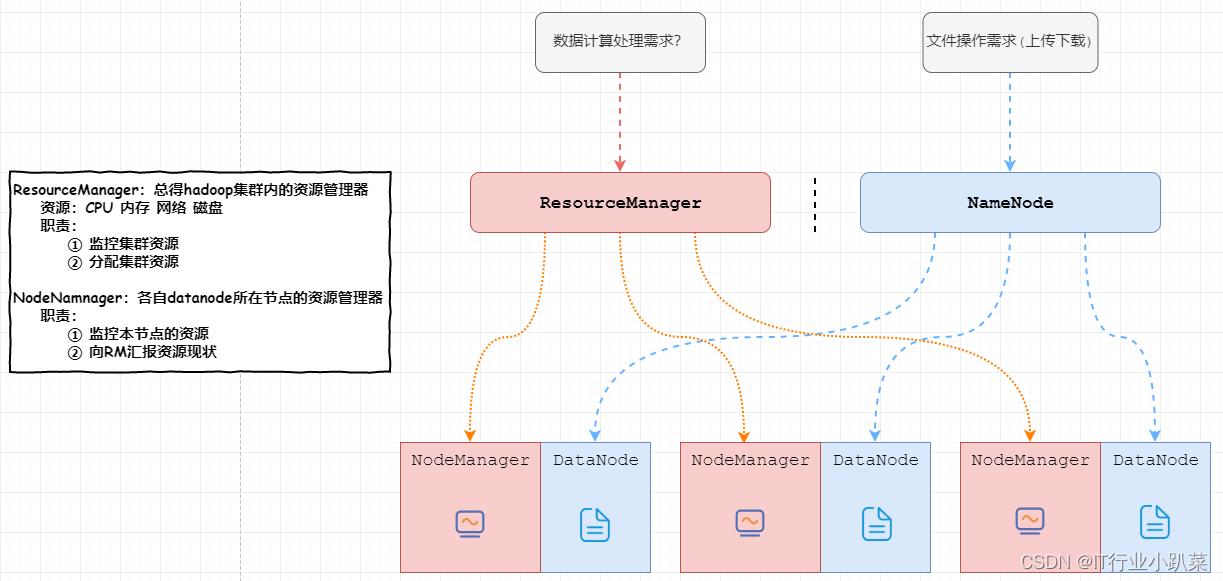
yarn
yarn集群核心组成
NodeManager
ResourceManager
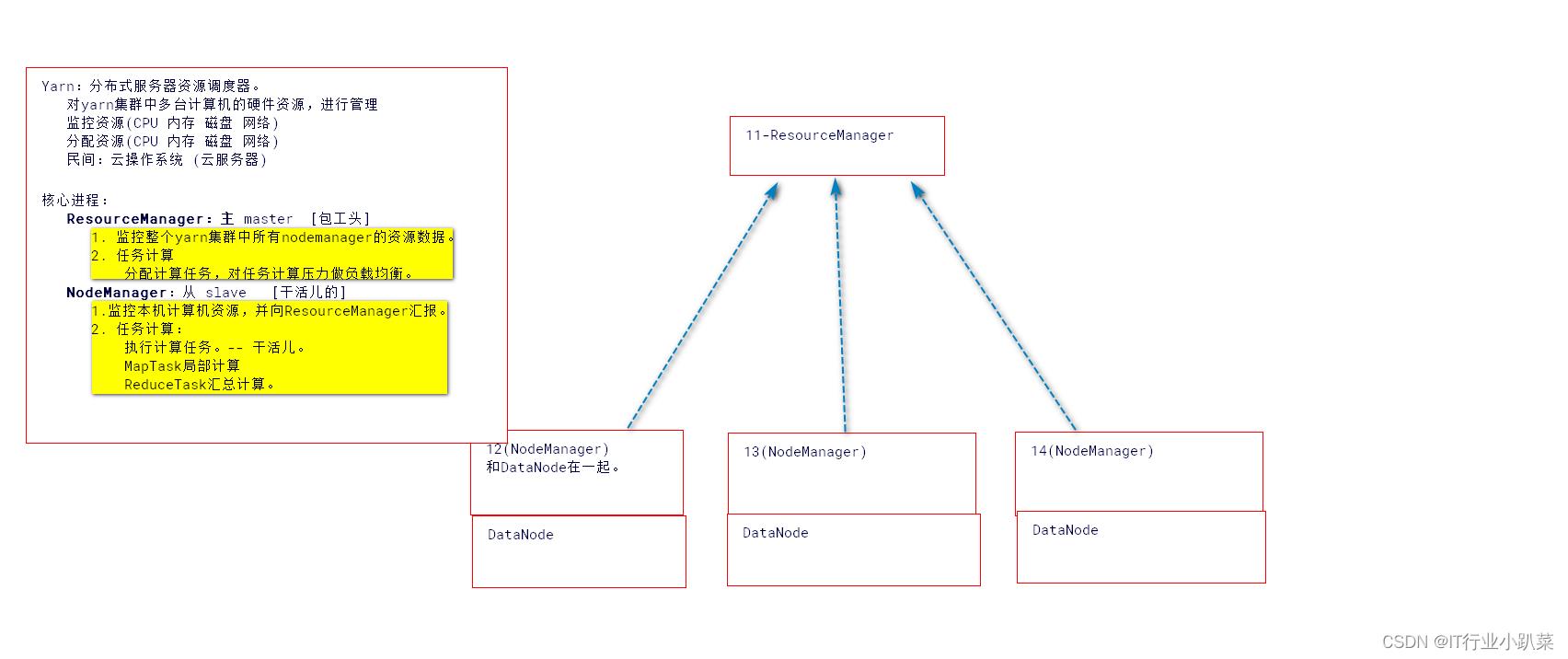
作用(包工队)
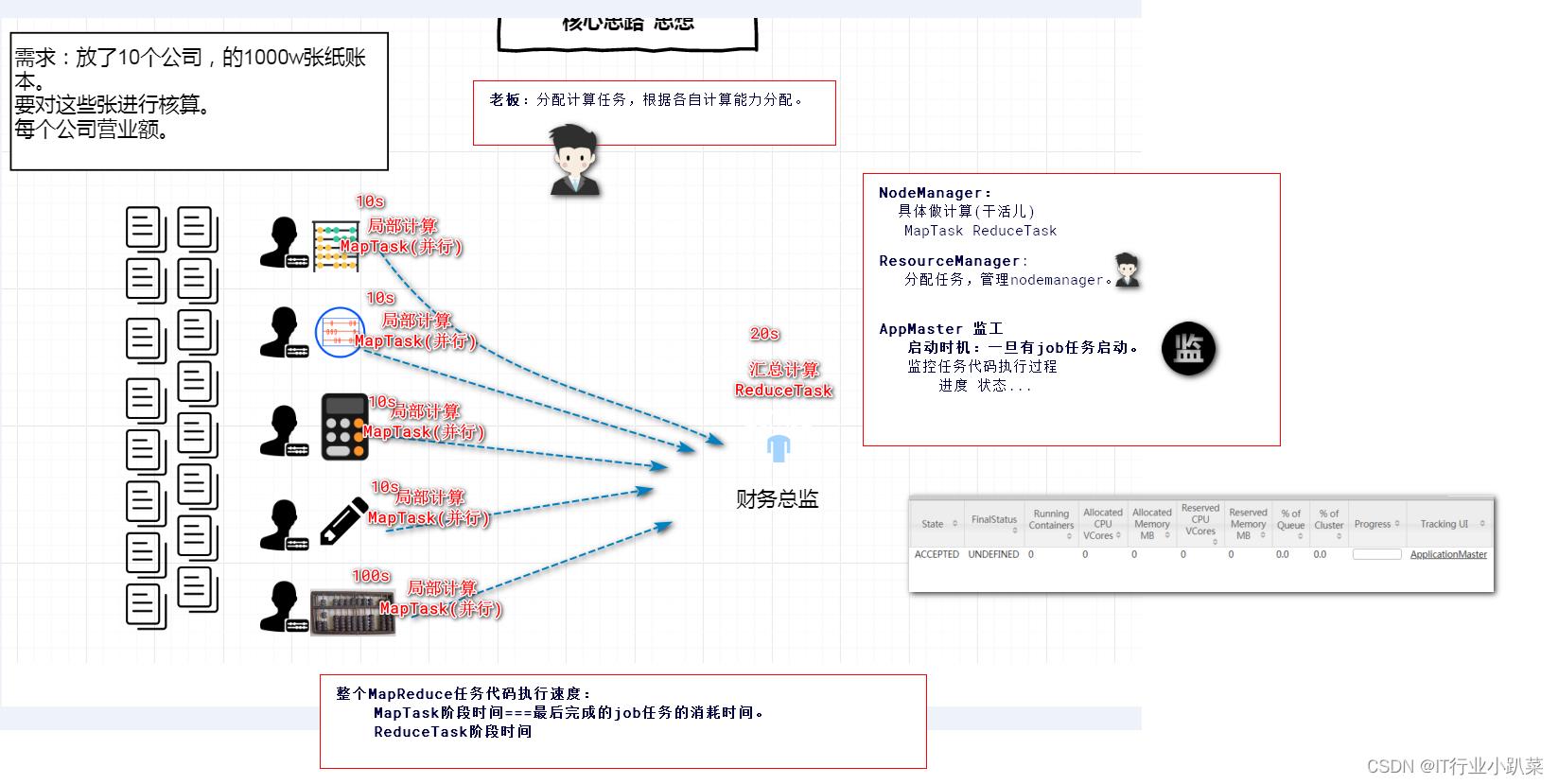
资源调度,任务监控 主要用来整合hadoop集群中的资源(CPU 内存),进行统一调度 同时监控任务的执行情况
总结: 联合多个服务器节点的硬件,共同完成一个计算。突破单机服务器的计算能力。
组成部分
- ResourceManager(包工头)
集群计算资源的管理器,也是yarn架构中的主节点。
功能:
- 监控集群资源
- 为计算分配资源。
- NodeManager(干活的)
yarn集群计算资源的提供者,也是yarn架构中的从节点。
功能
- 真正执行计算任务的节点。
- 监控本节点的资源情况(CPU 内存 网络 硬盘),并通过心跳向RM汇报。
MapReduce特点
- 易于编程:只需要使用hadoop接口进行编程,即可实现多台计算机分布式计算和分布式存储。
- 高扩展性:存储空间不足或者计算能力不足,则可以添加计算机完成。
- 容错性高:如果某个节点宕机,hadoop可以自动切换讲计算任务转移到其他节点上完成,不会影响计算结果。
如果计算任务执行了一半失败,出错,内部自动重试机制。- 应用场景:PB级别以上海量数据的离线处理,无法实时处理和流失动态处理。(每日)
Yarn伪分布式搭建
1.准备单机的HDFS架构
要求:安装了并配置了HDFS架构的服务器。
验证:jps
[root@hadoop10 ~]# jps
2224 Jps
2113 SecondaryNameNode
1910 DataNode
1806 NameNode
关闭掉hdfs
stop-dfs.sh
# 2 初始化配置文件
# 拷贝得到mapred-site.xml
[root@hadoop10 hadoop]# cp mapred-site.xml.template mapred-site.xml
1. mapred-site.xml
<!--配置yarn框架作为mapreduce的资源调度器-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2. yarn-site.xml
<!-- mapreduce计算服务方法。 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置resourcemanager的主机ip-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Hadoop</value>
</property>
3. slaves配置文件
指定:DataNode和NodeManager节点的ip地址。
① Datanode节点ip
② Nodemanager的节点ip
# 3. 启动yarn集群
1. 启动HDFS集群
start-dfs.sh
2. 启动yarn集群
start-yarn.sh
关闭yarn
stop-yarn.sh
# 验证
1. jps
[root@hadoop11 ~]# jps
6160 DataNode --- 数据存储节点
6513 ResourceManager -- 计算机资源调度节点
6614 NodeManager -- 局部计算节点
6056 NameNode -- 文件元数据存储节点
6349 SecondaryNameNode -- checkpoint节点。
6831 Jps
2. 访问yarn的资源调度器web网页。
http://resourcemanager所在节点ip:8088
MapReduce编码
需求

MapReduce2.0工作机制
-
数据变化(要干什么)
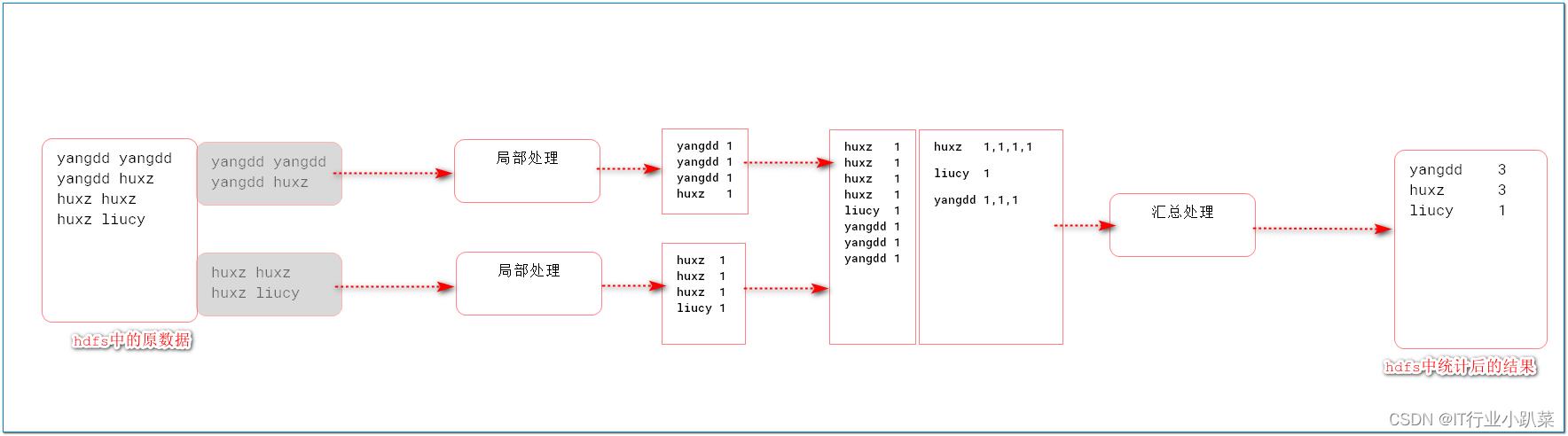
-
工作角色(谁来干)
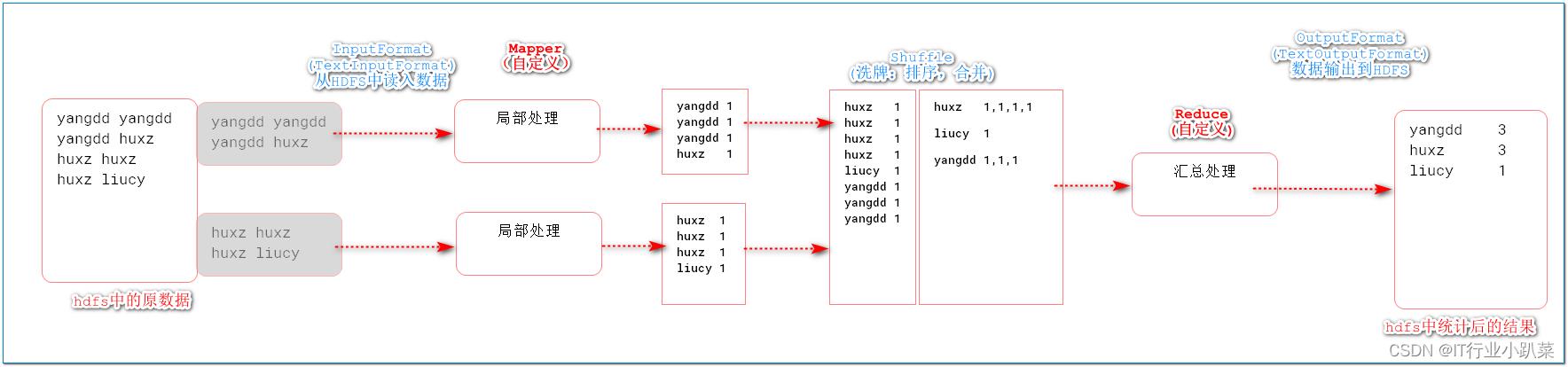
MapReduce数据流转机制
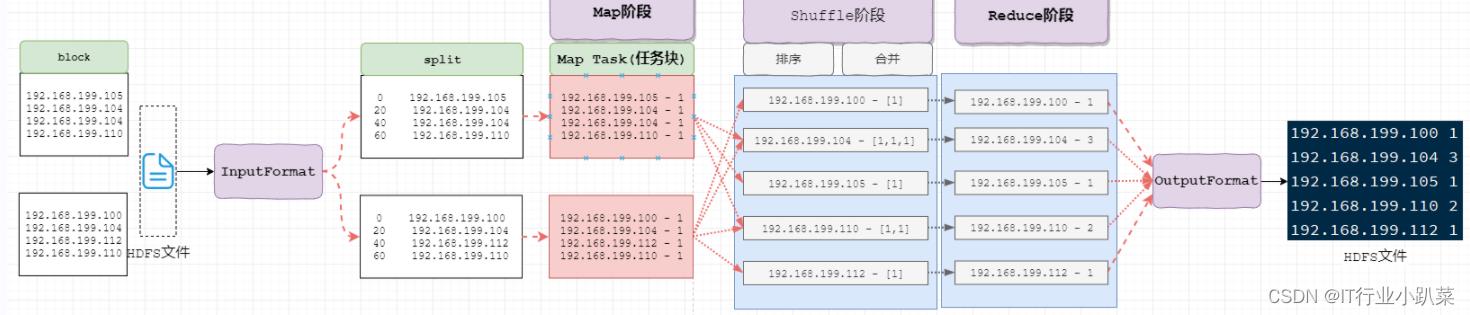 > 1. InputFormat(mr自动处理)
> 1. InputFormat(mr自动处理)
讲block文件转化成split,其中每条数据是key-value组成。
key是数据偏移量
value是每条数据
2. Map(程序员编码)
将split逐条输入给map,由map负责,对每条数据进行处理,转化为keyOut-valueOut
3. Shuffle(MR的默认处理器)
对map输出的每条数据的key-value进行排序,分组。
4. Reduce(程序员编码)
对Shuffle分组后的数据的key-value进行处理,转化为新的key-value。
5. OutputFormat
讲reduce产生的数据,存储HDFS文件系统中
MR编码准备
# 导入pom依赖
<!--hadoop公共依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<!--hadoop hdfs 依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--map reduce-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.9.2</version>
</dependency>
# 导入log4j配置文件
MR编码
# 编写map程序
/*Mapper:
* 接受:k(0)-v(yangdd yangdd)
* 输出:k(name)-v(1)
*
* */
/**
* 继承类上的泛型:
* Keyin
* ValueIn
* KeyOut
* ValueOut
*
*/
static class WordCountMapper extends Mapper<LongWritable,Text, Text, IntWritable>
/**
* 执行时机:每读取一行k-v,调用一次map方法
* @param key 输入k
* @param value 输入v
* @param context 输出k-v写出工具。
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException
//1. 接受k-v
//2. 对v进行拆分
String sv = value.toString();
String[] names = sv.split(" ");
//遍历数组,将得到每个name,作为k输出。
for (String name : names)
//3. 将k(name)-v(1)
context.write(new Text(name),new IntWritable(1));
# 编写reduce程序
/*Reducer:
* 对maptask输出后,mapreduce合并后的k-vs中的value之,累加和。
* keyint
* valuein
* keyout
* valueout
* */
static class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>
/**
* 执行时机:每读取Reduce端合并后的一组数据(k-vs),调用一次reduce方法。
* @param key 输入k
* @param values 输入value [1,2,3,1]
* @param context 输出k-v
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException
//1: 接受k-vs
//2. 对vs 遍历累加
int sum = 0;
for (IntWritable value : values)
sum = sum+value.get();
//3. 输出
// k(name)-v(累加和)
context.write(key,new IntWritable(sum));
# 编写job程序
public static void main(String[] args) throws Exception
/*组装Job 启动Job*/
//1. 初始化hdfs的配置文件 入口
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://192.168.199.10:9000");
//2. 创建job,未来是要运行在yarn集群中。
Job job = Job.getInstance(conf);
job.setJarByClass(JobForWordCount.class);
//3. 配置job(MapTask一端): TextInputFormat keyout valueout Mapper
TextInputFormat.addInputPath(job,new Path("/baizhi/mapreduce/demo1/namecount.txt"));
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMapper.class);
//4. 配置job(ReduceTask一端): TextOutputFormat keyout valueout Reducer
TextOutputFormat.setOutputPath(job,new Path("/baizhi/mapreduce/demo1/namecountout"));//最后一集目录不能存在,执行目录。
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//5. 启动job
boolean b = job.waitForCompletion(true);
System.out.println(b);
# 本地直接运行。
使用本地的方式提交任务,需要HDFS开启写入文件的权限。
hdfs dfs -chmod -R 777 /hdfs
MapReduce核心api
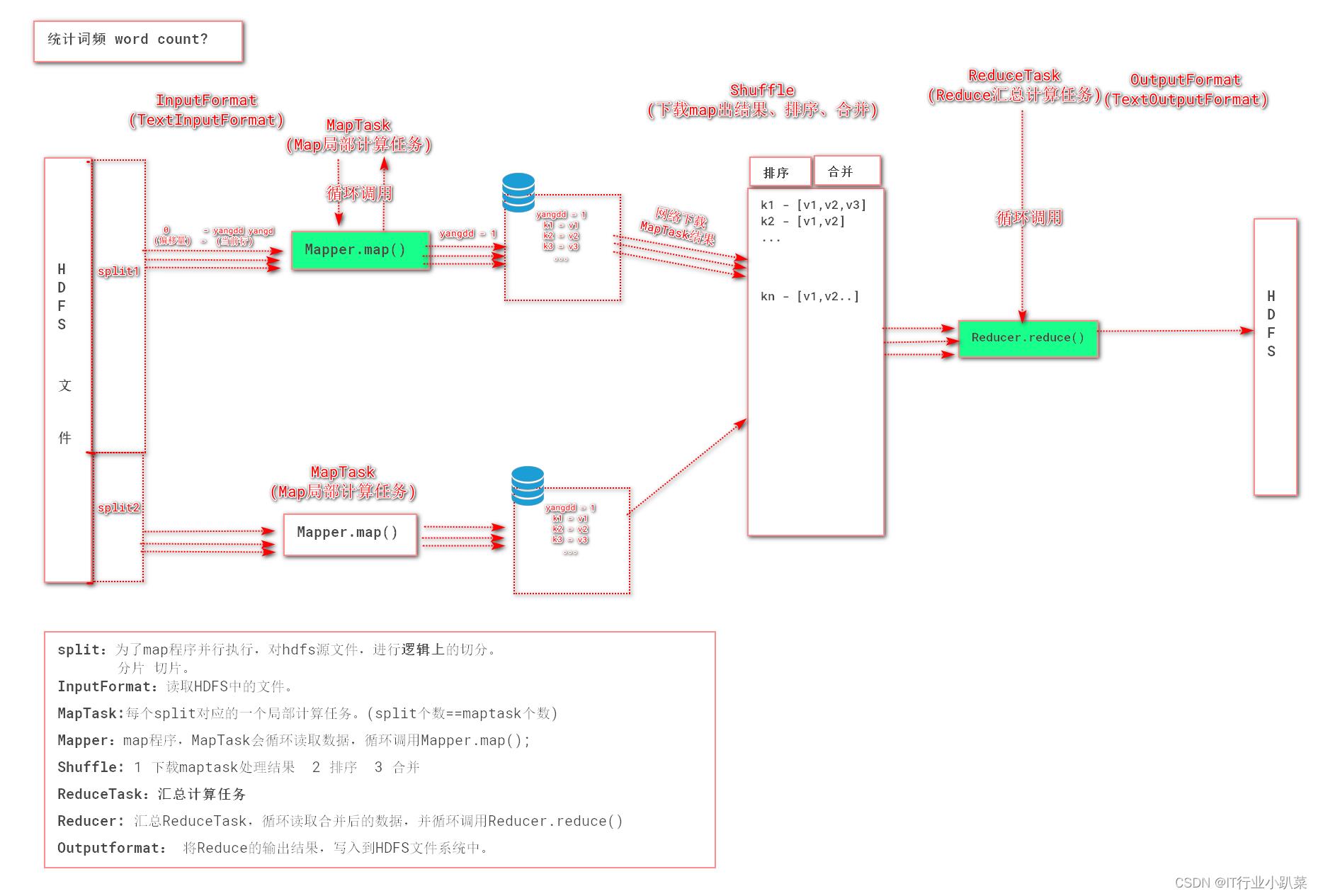
- InputFormat
- MapTask
- maper
- ReduceTask
- reducer
- OutputFormat
Mapreduce补充细节
Hadoop的MapReduce适合做大数据的离线处理,不适合做实时处理。
mapreduce的sort排序,无法取消。
生产中提交MR任务1

# 打包
# 1. 设置maven的打包的环境
<properties>
<!--解决编码的GBK的问题-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<build>
<!--指定打包的jar的名字-->
<finalName>mr1</finalName>
<!--指定打包的信息-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<!--指定入口主函数所在的类名-->
<manifest>
<mainClass>demo1.job.WordCountJob</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
# 2. 执行打包
在当前项目所在的目录下执行如下命令
> mvn package
# 3. 上传jar到hadoop的ResourceManager所在的机器
# 4. 执行程序
> yarn jar mr1.jar
maven自动化部署插件wagon
# 1. 配置maven远程提交插件
1. 添加maven的ssh扩展
2. 添加maven的远程拷贝插件wagon(货车)
<!--加入maven的扩展ssh-->
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<!--maven的远程拷贝插件-->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--上传的本地jar的位置-->
<fromFile>target/$project.build.finalName.jar</fromFile>
<!--远程拷贝的地址-->
<url>scp://用户名:密码@ip:/opt/app</url>
</configuration>
</plugin>
3. 添加远程执行命令,和参数。
# 清空
mvn clean
# 打包本地jar
mvn package
# 远程上传jar
mvn wagon:upload-single
ApplicationMaster
ResourceManager:任务分配,和nodemanager管理;领导、团队管理[工头]
NodeManager: 负责运行执行MapTask和ReduceTask。具体干活的人。[工人]
MRAppMaster:监控、管理 MapReduce任务的执行(开始-过程-结束)。工地监工。
只有在启动mapreduce程序,才会启动MRAppMaster
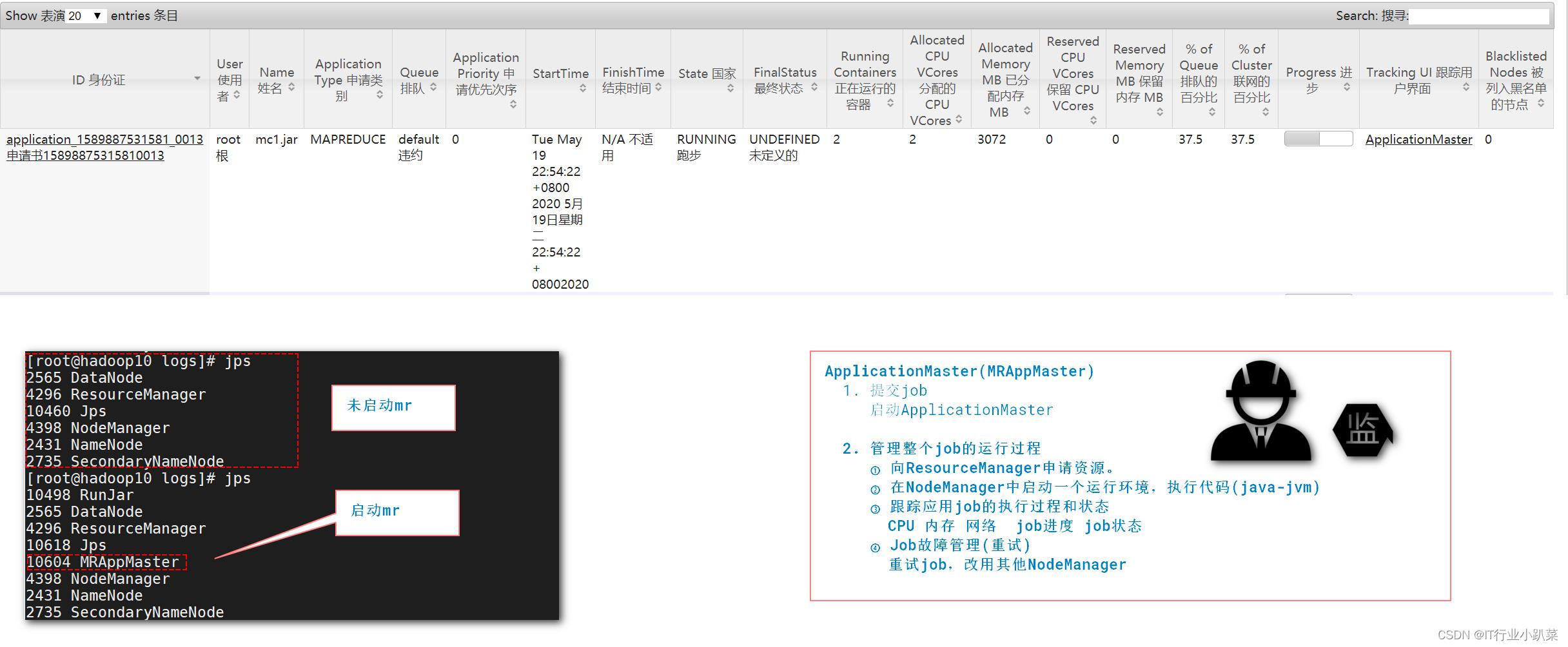
负责某个任务全部执行过程的监控管理。(监工)
- 提交job
启动ApplicationMaster|MRAppMaster- 管理整个job的运行过程
① 向ResourceManager申请资源。
② 在NodeManager中启动一个运行环境,执行代码。()
③ 跟踪应用job的执行过程和状态
④ Job故障管理;
一旦job任务执行失败(MapTask),AppMaster,自定让NodeManager重启执行任务代码。
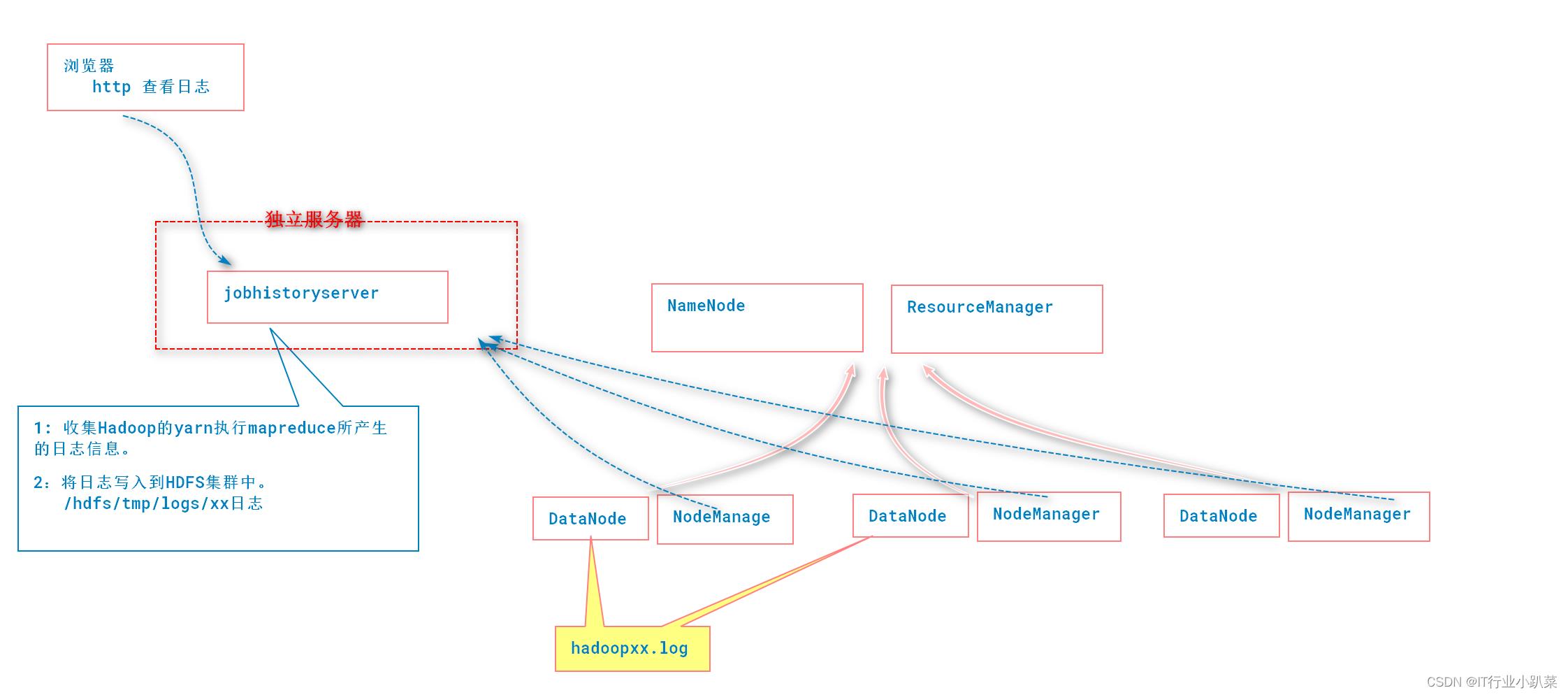
配置yarn的日志服务器-Historyserver
Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录
比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
默认未启动。
# 1. 配置mapred-site.xml,指定历史日志服务器的地址
<!--job历史日志服务器的服务地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop10:10020</value>
</property>
<!--job的历史日志服务器的web地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop10:19888</value>
</property>
# 2. 配置yarn-site.xml,指定开启日志聚合和日志保留时间,使得日志文件保存在hdfs上。
<!--开启日志聚合-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!--日志保存时间 单位秒 这里是7天-->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
# 3. 启动历史日志服务器
0. 启动hdfs
1. 重启yarn
[root@hadoop10 ~]# stop-yarn.sh
[root@hadoop10 ~]# start-yarn.sh
2. 启动
[root@hadoop10 ~]# mr-jobhistory-daemon.sh start historyserver
如果需要关闭执行如下命令
[root@hadoop10 ~]# mr-jobhistory-daemon.sh stop historyserver
# 4. 查看日志
1. 访问http://ip:8088(访问yarn集群,看到执行过的job信息)
2. 点击"Applications"找到刚才执行的job的"history"
3. 点击logs


MapReduce详解
Hadoop序列化
案例数据
手机使用的流量数据,每次手机上网记录一条信息。
需求:统计每个手机号的 上传总流量 下载总流量 总流量
分析核心点:
希望那些数据相同的合并在一起,map端就以它为key输出即可。
# 案例数据
id 手机号 ip地址 上传 下载 状态码
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
# 期望结果
13726230503 上传流量:4962 下载流量:49362 总数据流量: 54324
13826544101 上传流量:528 下载流量:0 总数据流量: 528
13926251106 上传流量:480 下载流量:0 总数据流量: 480
13926435656 上传流量:264 下载流量:3024 总数据流量: 3288
# hadoop序列化
mapreduce执行过程中,被处理的key-value数据,需要在网络中传输,就需要对象转化为字节,字节转化为对象,这就是序列化和反序列化过程;
key和value都要经过序列化传输。
1. Java序列化(序列化数据+对象描述信息)
序列化会包含java的继承关系,验证信息,验证信息。(重量级)
不便于在网络中传输。
2. Hadoop序列化(仅关注数据序列化)
空间紧凑
传输快速,网络开销小。
结论:
mapreduce中所有key-value都要支持序列化。

hadoop内置可序列化类型
| Java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| long | LongWritable |
| float | FloatWritable |
| double | DoubleWritable |
| string | Text |
| array | ArrayWritable |
| map | MapWritable |
| null | NullWritable |
自定义序列化类型
将要封装的数据,放在一个类中。
自定义一个类实现WritableComparable
- 可以被hadoop序列化传输。
- 可以支持排序。
注意序列化和反序列化的属性操作顺序要完全一致
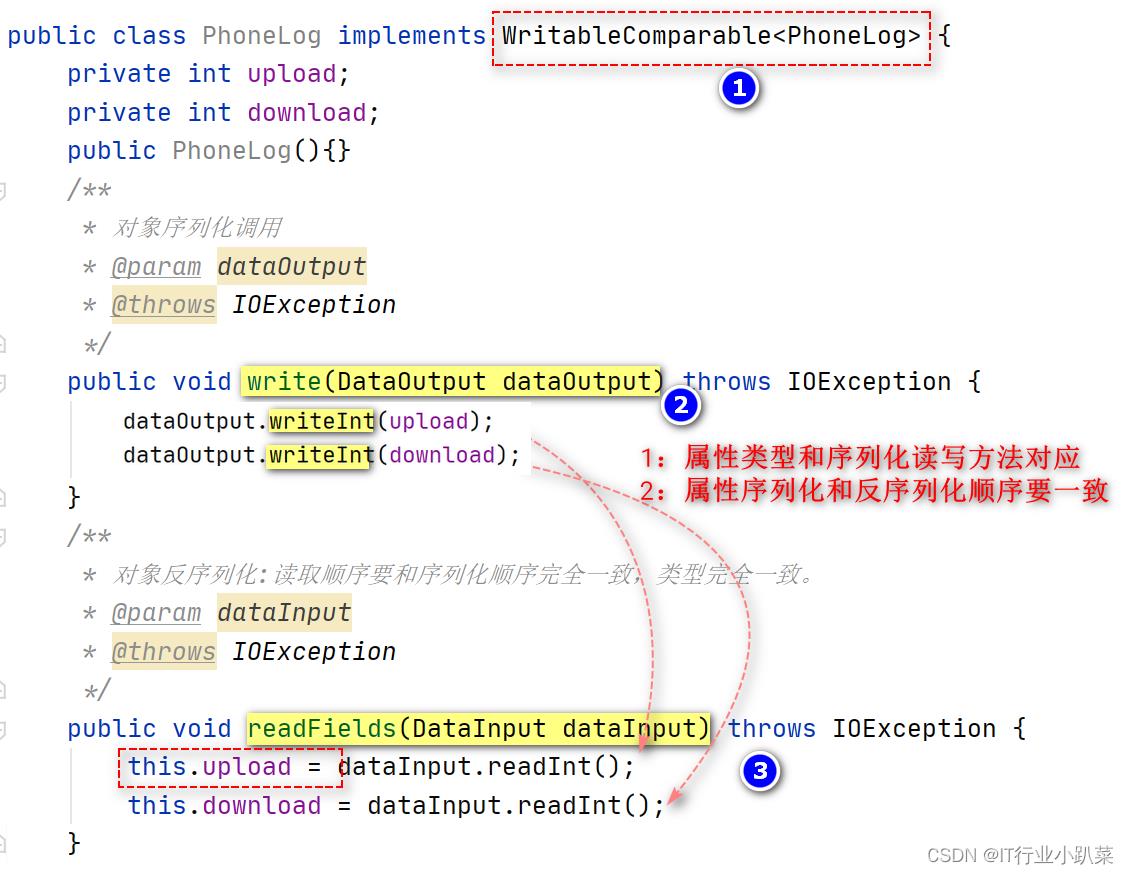
//序列化示例代码
public class PhoneLogWritable implements WritableComparable<PhoneLogWritable>
private Logger log = Logger.getLogger(PhoneLogWritable.class);
private int upload;
private int download;
private int sum;
public PhoneLogWritable(int upload, int download, int sum)
this.upload = upload;
this.download = download;
this.sum = sum;
public PhoneLogWritable()
log.info("----对象创建----");
public int compareTo(PhoneLogWritable o)
log.info("--比较--");
return this.sum-o.sum;
public void write(DataOutput dataOutput) throws IOException
log.info("------write---");
dataOutput.writeInt(upload);
dataOutput.writeInt(download);
dataOutput.writeInt(sum);
public void readFields(DataInput dataInput) throws IOException
log.info("--read---");
upload = dataInput.readInt();
download = dataInput.readInt();
sum = dataInput.readInt();
@Override
public boolean equals(Object o)
System.out.println("--equals---");
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return f以上是关于什么是MapReduce?MapReduce整体架构搭建使用介绍的主要内容,如果未能解决你的问题,请参考以下文章