什么是MapReduce?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是MapReduce?相关的知识,希望对你有一定的参考价值。
参考技术A 概念"Map(映射)"和"Reduce(化简)",和他们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。他极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(化简)函数,用来保证所有映射的键值对中的每一个共享相同的键组。 映射和化简 简单说来,一个映射函数就是对一些独立元素组成的概念上的列表(例如,一个测试成绩的列表)的每一个元素进行指定的操作(比如前面的例子里,有人发现所有学生的成绩都被高估了一分,他可以定义一个“减一”的映射函数,用来修正这个错误。)。事实上,每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。 而化简操作指的是对一个列表的元素进行适当的合并(继续看前面的例子,如果有人想知道班级的平均分该怎么做?他可以定义一个化简函数,通过让列表中的元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到了平均分。)。虽然他不如映射函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。编辑本段分布和可靠性 MapReduce通过把对数据集的大规模操作分发给网络上的每个节点实现可靠性;每个节点会周期性的把完成的工作和状态的更新报告回来。如果一个节点保持沉默超过一个预设的时间间隔,主节点(类同Google File System中的主服务器)记录下这个节点状态为死亡,并把分配给这个节点的数据发到别的节点。每个操作使用命名文件的原子操作以确保不会发生并行线程间的冲突;当文件被改名的时候,系统可能会把他们复制到任务名以外的另一个名字上去。(避免副作用)。 化简操作工作方式很类似,但是由于化简操作在并行能力较差,主节点会尽量把化简操作调度在一个节点上,或者离需要操作的数据尽可能近的节点上了;这个特性可以满足Google的需求,因为他们有足够的带宽,他们的内部网络没有那么多的机器。用途 在Google,MapReduce用在非常广泛的应用程序中,包括“分布grep,分布排序,web连接图反转,每台机器的词矢量,web访问日志分析,反向索引构建,文档聚类,机器学习,基于统计的机器翻译...”值得注意的是,MapReduce实现以后,它被用来重新生成Google的整个索引,并取代老的ad hoc程序去更新索引。 MapReduce会生成大量的临时文件,为了提高效率,它利用Google文件系统来管理和访问这些文件。 本回答被提问者采纳漫画:什么是MapReduce?


————— 第二天 —————






————————————



什么是MapReduce?
MapReduce是一种编程模型,其理论来自Google公司发表的三篇论文(MapReduce,BigTable,GFS)之一,主要应用于海量数据的并行计算。
MapReduce可以分成Map和Reduce两部分理解。
1.Map:映射过程,把一组数据按照某种Map函数映射成新的数据。
2.Reduce:归约过程,把若干组映射结果进行汇总并输出。
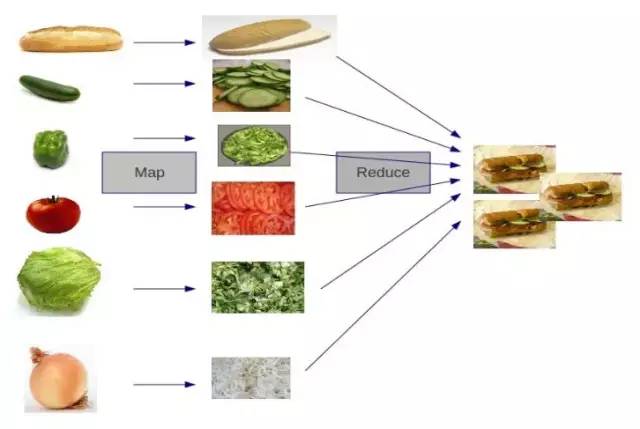
让我们来看一个实际应用的栗子,如何高效地统计出全国所有姓氏的人数?
我们可以利用MapReduce的思想,针对每个省的人口做并行映射,统计出若干个局部结果,再把这些局部结果进行整理和汇总:
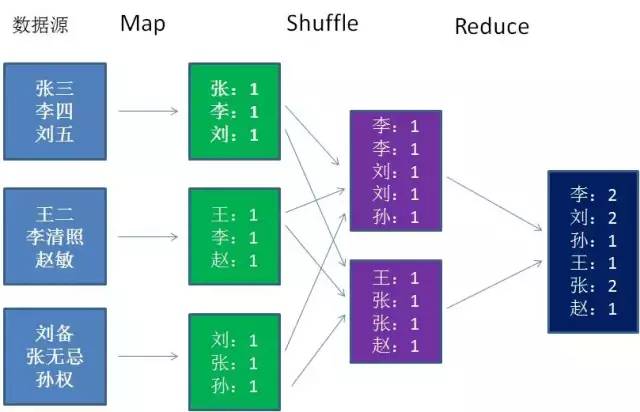
这张图是什么意思呢?我们来分别解释一下步骤:
1.Map:
以各个省为单位,多个线程并行读取不同省的人口数据,每一条记录生成一个Key-Value键值对。图中仅仅是简化了的数据。
2.Shuffle
Shuffle这个概念在前文并未提及,它的中文意思是“洗牌”。Shuffle的过程是对数据映射的排序、分组、拷贝。
3.Reduce
执行之前分组的结果,并进行汇总和输出。
需要注意的是,这里描述的Shuffle只是抽象的概念,在实际执行过程中Shuffle被分成了两部分,一部分在Map任务中完成,一部分在Reduce任务中完成。

Hadoop如何实现MapReduce?

Hadoop是Apache基金会开发的一套分布式系统框架,包含多个组件,其核心就是HDFS和MapReduce。
由于篇幅原因,文本不会对Hadoop做完整的介绍,只是简单介绍一下Haddoop框架当中如何实现MapReduce。
下面这张图是Hadoop框架执行一个MapReduce Job的全过程:
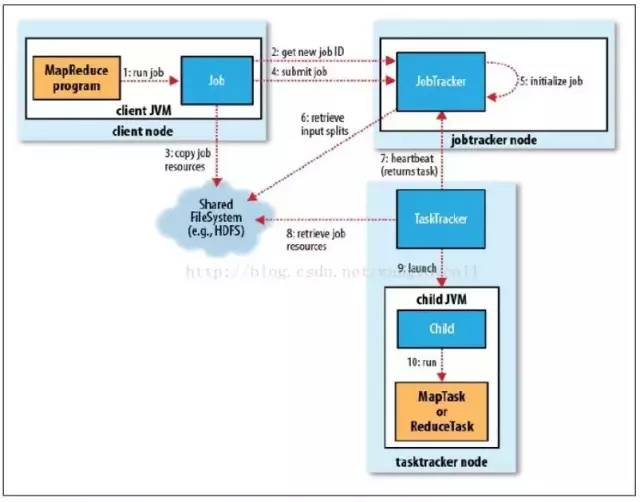
这里需要对几种实体进行解释:
HDFS:
Hadoop的分布式文件系统,为MapReduce提供数据源和Job信息存储。
Client Node:
执行MapReduce程序的进程,用来提交MapReduce Job。
JobTracker Node:
把完整的Job拆分成若干Task,负责调度协调所有Task,相当于Master的角色。
TaskTracker Node:
负责执行由JobTracker指派的Task,相当于Worker的角色。这其中的Task分为MapTask和ReduceTask。



以上是关于什么是MapReduce?的主要内容,如果未能解决你的问题,请参考以下文章