大数据采集清洗处理:使用MapReduce进行离线数据分析
Posted IT荐书
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据采集清洗处理:使用MapReduce进行离线数据分析相关的知识,希望对你有一定的参考价值。
1 大数据处理的常用方法
大数据处理目前比较流行的是两种方法,一种是离线处理,一种是在线处理,基本处理架构如下:
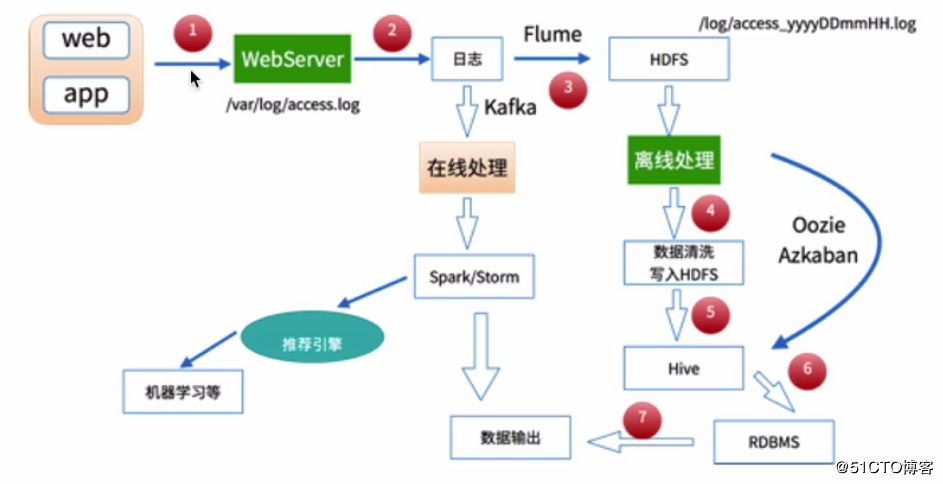
在互联网应用中,不管是哪一种处理方式,其基本的数据来源都是日志数据,例如对于web应用来说,则可能是用户的访问日志、用户的点击日志等。
如果对于数据的分析结果在时间上有比较严格的要求,则可以采用在线处理的方式来对数据进行分析,如使用Spark、Storm等进行处理。比较贴切的一个例子是天猫双十一的成交额,在其展板上,我们看到交易额是实时动态进行更新的,对于这种情况,则需要采用在线处理。
当然,如果只是希望得到数据的分析结果,对处理的时间要求不严格,就可以采用离线处理的方式,比如我们可以先将日志数据采集到HDFS中,之后再进一步使用MapReduce、Hive等来对数据进行分析,这也是可行的。
本文主要分享对某个电商网站产生的用户访问日志(access.log)进行离线处理与分析的过程,基于MapReduce的处理方式,最后会统计出某一天不同省份访问该网站的uv与pv。
2 生产场景与需求
在我们的场景中,Web应用的部署是如下的架构:
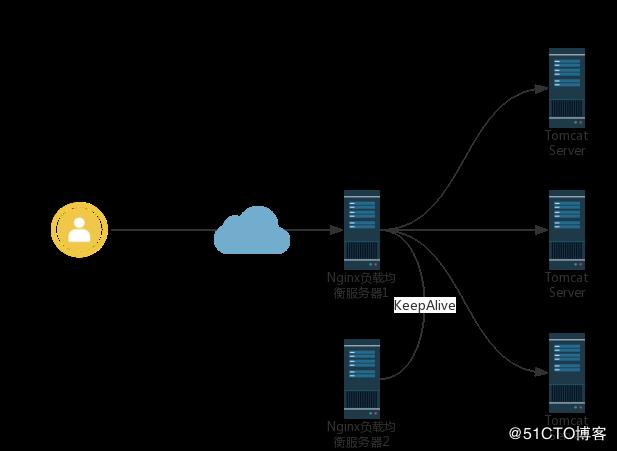
即比较典型的nginx负载均衡+KeepAlive高可用集群架构,在每台Web服务器上,都会产生用户的访问日志
3 数据采集:获取原生数据
数据采集工作由运维人员来完成,对于用户访问日志的采集,使用的是Flume,并且会将采集的数据保存到HDFS中,其架构如下:
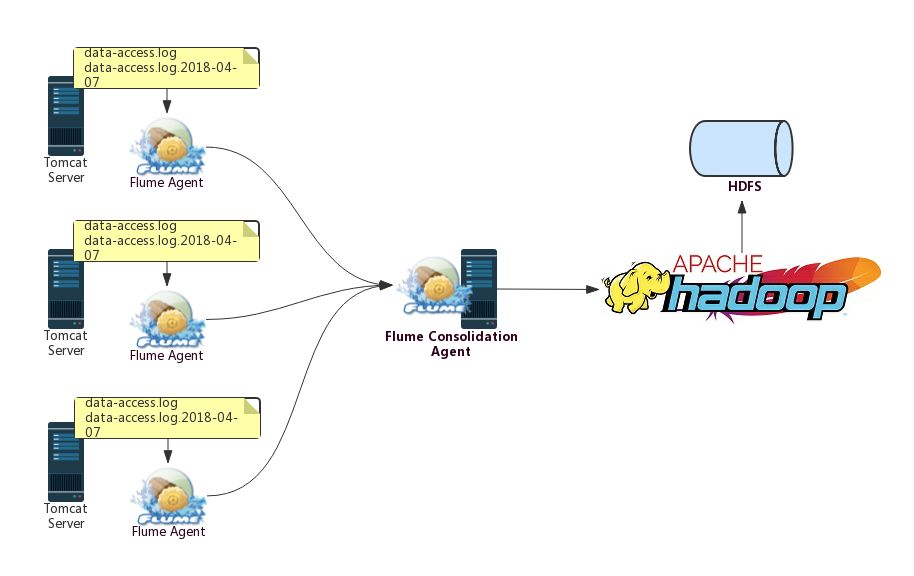
可以看到,不同的Web Server上都会部署一个Agent用于该Server上日志数据的采集,之后,不同Web Server的Flume Agent采集的日志数据会下沉到另外一个被称为Flume Consolidation Agent(聚合Agent)的Flume Agent上,该Flume Agent的数据落地方式为输出到HDFS。
在我们的HDFS中,可以查看到其采集的日志:
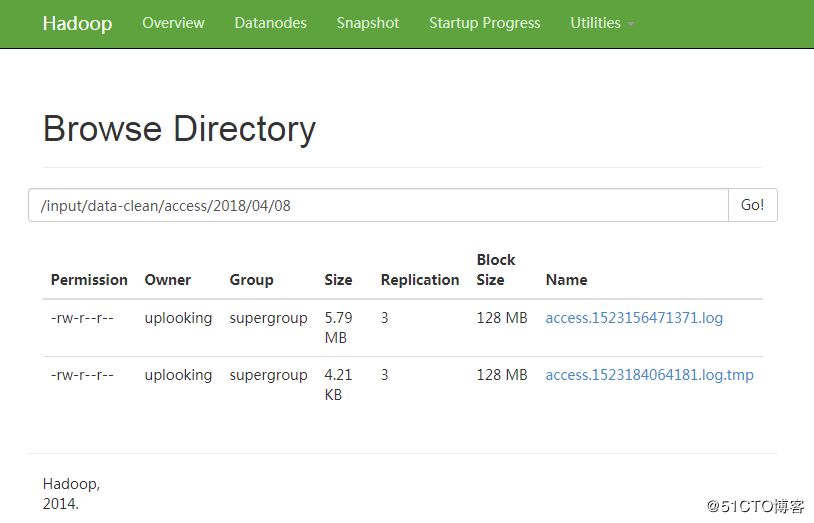
后面我们的工作正是要基于Flume采集到HDFS中的数据做离线处理与分析。
4 数据清洗:将不规整数据转化为规整数据
4.1 数据清洗目的
刚刚采集到HDFS中的原生数据,我们也称为不规整数据,即目前来说,该数据的格式还无法满足我们对数据处理的基本要求,需要对其进行预处理,转化为我们后面工作所需要的较为规整的数据,所以这里的数据清洗,其实指的就是对数据进行基本的预处理,以方便我们后面的统计分析,所以这一步并不是必须的,需要根据不同的业务需求来进行取舍,只是在我们的场景中需要对数据进行一定的处理。
4.2 数据清洗
4.3 数据清洗过程:MapReduce程序编写
数据清洗的过程主要是编写MapReduce程序,而MapReduce程序的编写又分为写Mapper、Reducer、Job三个基本的过程。
5 数据处理:对规整数据进行统计分析
经过数据清洗之后,就得到了我们做数据的分析统计所需要的比较规整的数据,下面就可以进行数据的统计分析了,即按照业务需求,统计出某一天中每个省份的PV和UV。
我们依然是需要编写MapReduce程序,并且将数据保存到HDFS中,其架构跟前面的数据清洗是一样的:

推荐阅读
《离线和实时大数据开发实战》
以上是关于大数据采集清洗处理:使用MapReduce进行离线数据分析的主要内容,如果未能解决你的问题,请参考以下文章
大数据采集清洗处理:使用MapReduce进行离线数据分析完整案例
ETL项目2:大数据清洗,处理:使用MapReduce进行离线数据分析并报表显示完整项目
Flume+Kafka+Storm+Redis构建大数据实时处理系统:实时统计网站PVUV+展示