大数据组件MapReduce
Posted 浮䒤岗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据组件MapReduce相关的知识,希望对你有一定的参考价值。
1,传统计算
传统计算是利用计算机的基本单元进行相关计算。
中央处理器CPU ---字计算
内存Memory ---存储数据和运行程序
输入设备 ---输入文章
输出设备 ---输出文章
硬盘Disk ---存储文章(比较持久化)
传统计算的极限?
一篇文章,可以进行计数计算,中间结果存储在内存或者硬盘,但是,如果是一本书,甚至是整个图书馆的书,单个机器的内存和硬盘无法存储对应的中间结果。
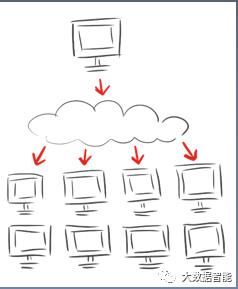
2,分布式计算
一个分布式计算系统是通过若干个网络互连的计算机组成的软硬件计算系统,并且这些计算机相互配合完成一个共同的任务。
并行计算如图c。多个处理器共享内存。
分布式计算b。每个处理器有属于自己的内存。
优点:
可扩展
高性能 -- 多台机器一起工作,可以在很短时间内完成共同的任务。
容错性好(系统故障后,仍然可以恢复任务)。一台机器发生了故障或者小任务失败,可以有新的机器重新进行计数。
可用性好--整个分布式系统可以在长时间内保持正常运行。
缺点:
多台机器管理
二,MapReduce
1,起源和背景
Google在2004年发表论文,引出概念。Hadoop MapReduce是基于此实现大集群上的简单数据处理。
2,MapReduce
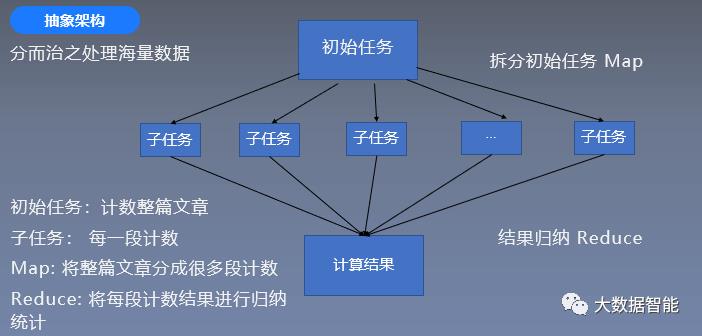
抽象架构
系统架构
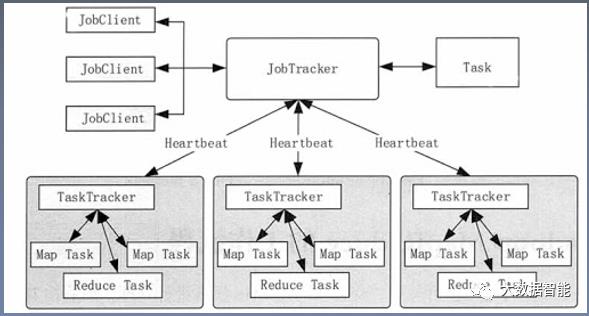
Job Client:用户编写的MapReduce程序通过JobClient提交给JobTracker.
Job Tracer:负责资源监控和作业调度,并且监控所有TaskTracker与作业的健康情况,一旦失败情况发生,就会将相应的任务分配到其他结点上去执行。
TaskTracer:主要负责监控任务进度,并且汇报给Job Tracer。
数据处理流程
Shuffling
Map Shuffle
对Map的结果进行分区、排序、分割然后将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件。
ReduceShuffle
主要分为复制Map输出、排序合并两个阶段。
以上是关于大数据组件MapReduce的主要内容,如果未能解决你的问题,请参考以下文章