大数据组件 in K8S
Posted 大数据肌肉猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据组件 in K8S相关的知识,希望对你有一定的参考价值。
作者颜卫,腾讯高级后台开发工程师,专注于Kubernetes大规模集群管理和资源调度,有过万级集群的管理运维经验。目前负责腾讯云TKE大规模Kubernetes集群的大数据应用托管服务。
大数据的发展历史
大数据技术起源于Google在2004年前后发表的三篇论文,分布式文件系统GFS、分布式计算框架MapReduce和NoSQL数据库系统BigTable,俗称"三驾马车"。在论文发表后,Lucene开源项目的创始人Doug Cutting根据论文原理初步实现了类似GFS和MapReduce的功能。并在2006年,将该部分功能设置成独立的项目即大名鼎鼎的Hadoop项目。Hadoop项目中主要包括分布式文件系统HDFS和大数据计算引擎MapReduce两个组件。
在早期,MapReduce既是一个执行引擎,又是一个资源调度框架,集群的资源调度管理由MapReduce自己完成。但是这样不利于资源复用,也使得MapReduce非常臃肿。于是一个新项目启动了,将MapReduce执行引擎和资源调度分离开来,这就是Yarn。2012年,Yarn成为一个独立的项目开始运营,随后被各种大数据产品支持,成为大数据平台上最主流的资源调度系统。伴随着时代的发展,大数据场景下的计算引擎层出不穷,主要的有内存式计算引擎Spark,分布式实时计算Storm,流计算框架Flink等。这些计算引擎都使用Yarn进行资源管理和调度。
大数据平台目前存在的问题
目前绝大多数大数据平台都是基于Hadoop生态,使用Yarn作为核心组件来进行资源管理和调度。但这样的平台普遍存在如下问题:
(1) 资源弹性不足,无法按需自动扩容。大数据系统资源的高峰往往具有明显的周期性。例如实时计算资源消耗主要在白天。离线分析中,日报型的计算任务资源的高峰一般在22:00以后。周报和月报型的计算任务业务高峰往往也是在一个固定的时间点。并且离线计算有时还有突发的计算任务,例如需要对历史数据做一个统计。目前的大数据系统普遍缺乏资源的弹性,无法按需进行快速扩容,为了应对业务高峰和突发的计算任务只能预留出足够多的资源来保证任务能够正常响应。
(2) 资源利用率低。日志留存和流量清单等存储密集型的业务CPU使用率长期小于30%。而计算类的业务虽然CPU消耗很高,但是存储的资源使用率小于20%。大量资源闲置。并且考虑在线业务往往在低峰期会有大量的资源闲置。这些资源其实离线计算业务是完全可以利用的,但目前大数据的系统架构这部分资源完全没有被利用。导致资源利用率进一步降低。
(3) 资源隔离性差。从Hadoop2.2.0版本开始,Yarn开始使用cgroup实现了CPU资源隔离,通过JVM提供的内存隔离机制来实现内存资源隔离。对于磁盘IO和网络IO的隔离目前社区还在讨论中YARN-2139[2],YARN-2140[3]。对于文件系统环境的隔离,社区在Hadoop 3.0版本中支持通过Classpath isolation HADOOP-11656[4]来避免不同版本的jar包冲突,但无法做到完整的文件系统隔离。整体上看Yarn的资源隔离做的并不完善,这就造成了,多个任务运行到同一个工作节点上时,不同任务之间会存在资源抢占的问题,不同任务之间相互影响。
(4) 系统管理困难。在大数据系统中缺少统一的管理接口,也缺少路由管理,网络管理,磁盘管理等能力。这就造成大数据平台的开发往往需要对管理系统进行深度定制。开发工作量大,系统管理困难,并且平台迁移困难。例如大数据平台中需要提供对大数据组件UI页面的访问能力。在大数据平台构建中,为了能够访问组件的UI页面往往需要单独进行网络的打通,进行额外的路由的配置。并且很多时候这些配置都缺少标准的接口,无法做到自动化,管理起来十分困难。
(5) 管理方式不统一。在线业务和大数据业务虽然属于不同的业务类型,但就管理平台来说提供的功能是类似的。主要提供资源管理,业务(任务)管理,权限管理,可视化展示与操作等方面的功能。但因为管理方式不统一,底层框架与运行方式不同,造成了在线业务和大数据业务往往需要开发不同的平台,由不同的团队运维来管理,这极大的增加了额外的人力投入,造成不必要的人力损失。

Kubernetes编排系统现状介绍
Kubernetes是谷歌开源的生产级的容器编排系统,在谷歌内部长达15年的使用积累,依赖其对功能场景的清晰定义,声明式API的简洁易用,充分的扩展性,逐步在容器编排领域的竞争中胜出,成为这一领域的领导者。伴随着微服务,DevOps,持续交付等概念的兴起和持续发酵,并依托于云原生计算基金会CNCF[5],Kubernetes保持着高速发展,正在成为"云计算时代的操作系统"。
Kubernetes究竟有多热门,根据CNCF年初(2020)的统计数据,在2019年84%的企业在生产环境中使用了Kubernetes。随着在生产环境的广泛使用,Kubernetes的成熟度已经得到了大范围的检验。很多公司已经提出了所有组件容器化的目标,借助云原生的技术,来提升组件运维管理和研发流程的效率。
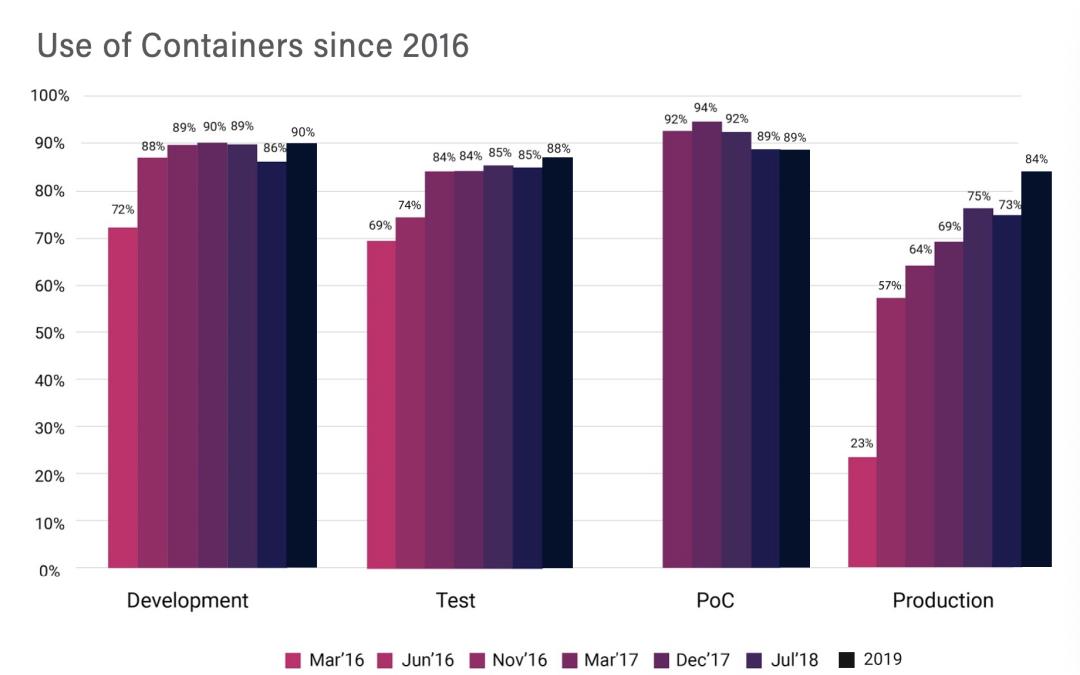
Kubernetes 如何解决大数据的问题
对于在线业务,使用容器技术能够很好的提高资源使用率,基于容器构建CI/CD流程可以大幅提升研发效能和系统管理能力,使用集群的自动伸缩功能可以根据需要动态申请和释放资源,提高资源使用的弹性。那么在大数据场景下,使用容器能否解决大数据平台目前遇到的问题呢?
首先对于资源弹性不足的问题,Kubernetes可以通过弹性扩缩容来实现业务高峰时的快速扩容,避免为了应对业务高峰预留过多的资源。更进一步可以直接使用无服务计算(Serverless)技术,直接将大数据业务跑在无服务计算的容器上,做到按需使用和付费,使资源的使用完全弹性。
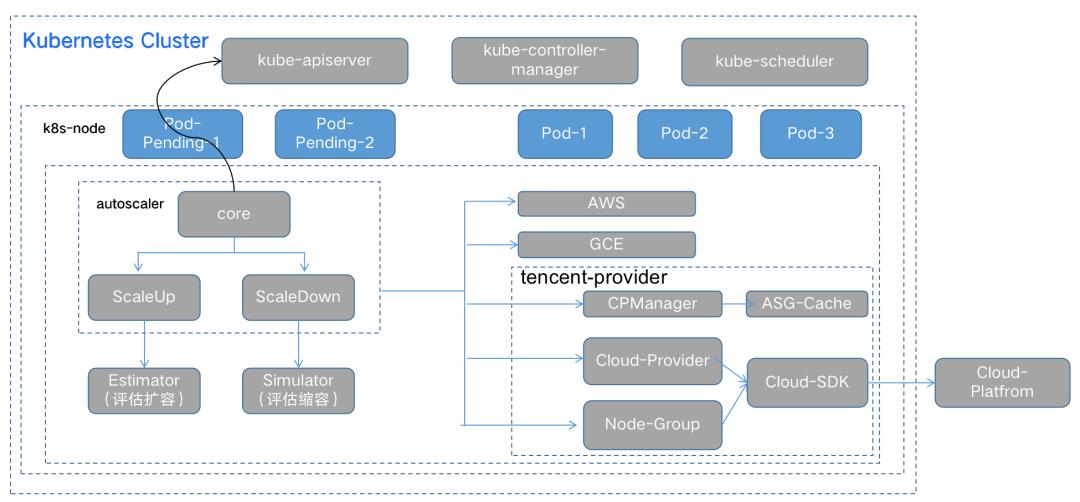
对于资源使用率低的问题。一方面Kubernetes支持更加细粒度的资源划分,这样可以尽量做到资源能用尽用,最大限度的按需使用。另外一方面支持更加灵活的调度,并根据业务SLA的不同,业务高峰的不同,通过资源的超卖和混合部署来进一步提升资源使用率。由于在线业务和离线业务两者之间SLA要求明显不同,业务高峰期也明显不同,容器化后使用离线在线混合部署,一般对资源使用率的提升在30%以上。
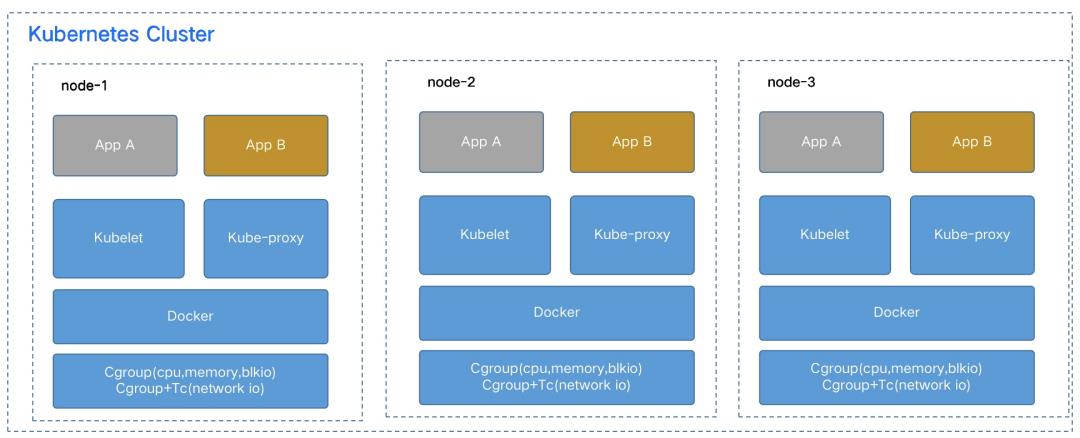
对于资源隔离性差的问题。容器技术从一开始就支持不同资源的隔离。CPU,内存,磁盘IO,网络IO,设备等这些都有比较完整的支持。在线业务使用容器技术,通过Kubernetes编排系统能够很好的将不同业务实例混合部署到相同的节点上,实例之间使用隔离技术,完整的隔离,相互之间完全不受影响。
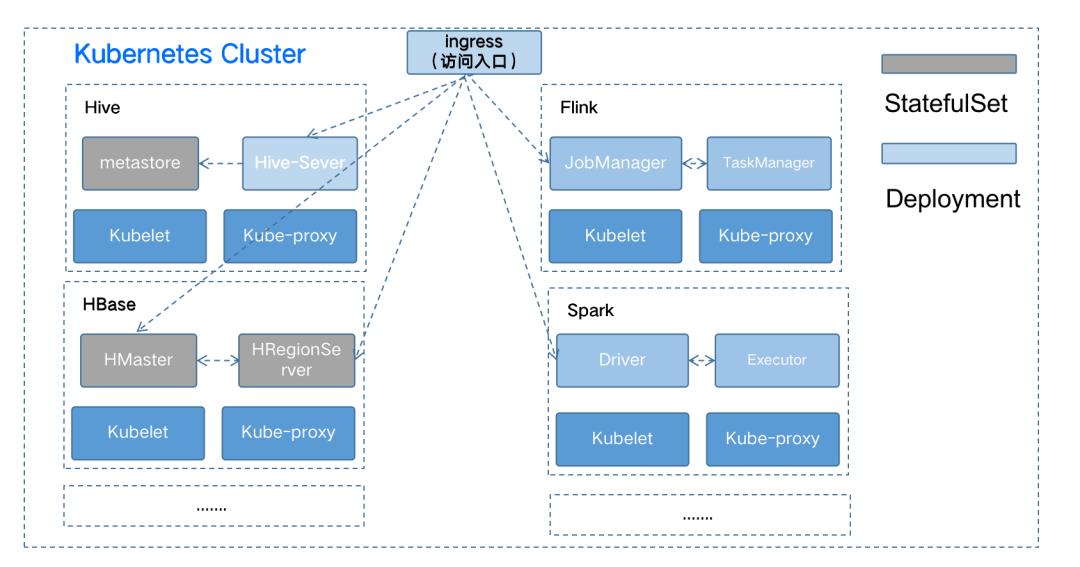
对于系统管理困难的问题,Kubernetes不仅提供资源管理的能力,还提供路由管理,网络管理,监控日志等多方面的能力。同时对外通过统一的声明式API进行访问。基于Kubernete构建大数据平台,可以极大的简化系统开发的难度,减少系统管理的复杂度。例如在大数据平台中,使用Kubernetes提供的路由管理能力Service[7]和 Ingress[8]可以十分方便实现对大数据组件UI的访问,并且Kubernetes还提供标准的声明式API来管理,极大的简化了自动化的复杂度。
如果在线业务和大数据业务都统一使用容器化的方式来部署,使用Kubernetes编排框架来管理。这样就能将大数据业务和在线业务在同一个平台中实现管理和运维。避免平台管理团队的人员分散,大大提高平台管理团队工作效率。
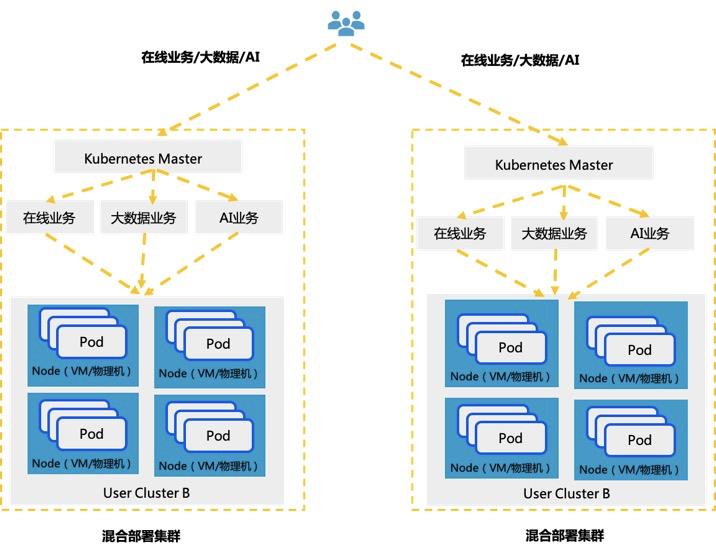
大数据容器化技术现状
大数据组件众多,按照类别大致可以分为文件存储系统,NoSQL数据库,计算框架,消息中间件,查询分析等。常用的大数据组件具体的分类如下表所示:
| 大数据组件分类 | 代表性组件 | 主要作用 |
|---|---|---|
| 文件存储系统 | HDFS | 数据底层存储 |
| NoSQL数据库 | Hbase、MongoDB | 非结构化数据存储 |
| 计算框架 | Hadoop MapReduce、Spark、Storm、Flink | 离线计算和流计算 |
| 消息系统 | Kafka、ZeroMQ、RabbitMQ | 消息存储和转发 |
| 数据查询分析 | Hive、Impala、Druid | 数据查询和分析 |
这些组件现在一般都有对应的开源项目来支持部署到Kubernetes上,本文将对一些常用的组件在Kubernetes的部署进行分析。
文件存储系统
HDFS on Kubernetes
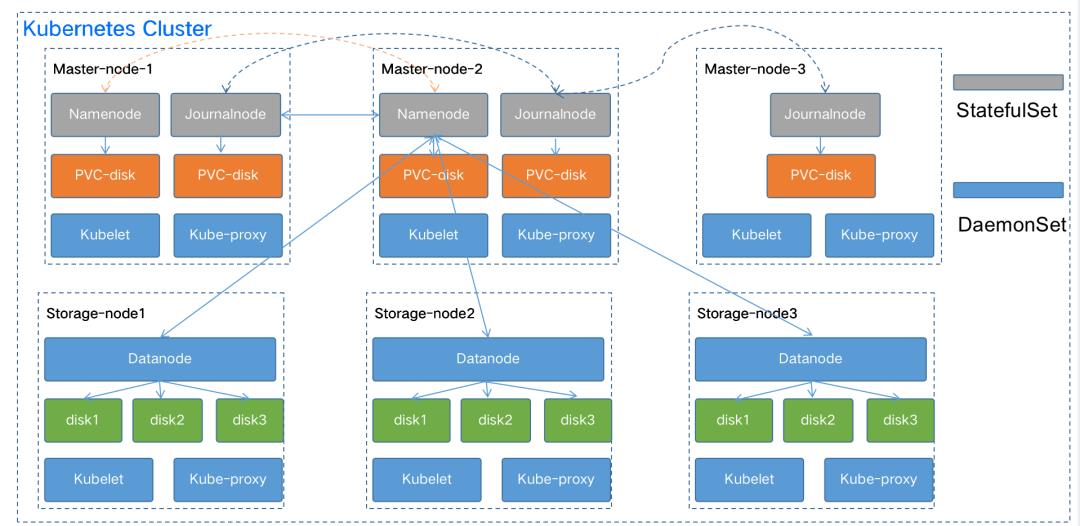
HDFS主要包括Datanode,Namenode和Journalnode三个组件。在Kubernetes中进行部署时,由于Datanode需要存储HDFS中的数据,对磁盘要求非常高,所以在Kubernetes中部署时Datanode采用DaemonSet[9]的方式进行部署,每个存储节点部署一个Datanode实例。而Namenode和Journalnode由于需要保持名称不变,在Kubernetes中采用StatefulSet[10]的方式进行部署。
NoSQL数据库
Hbase on Kubernetes
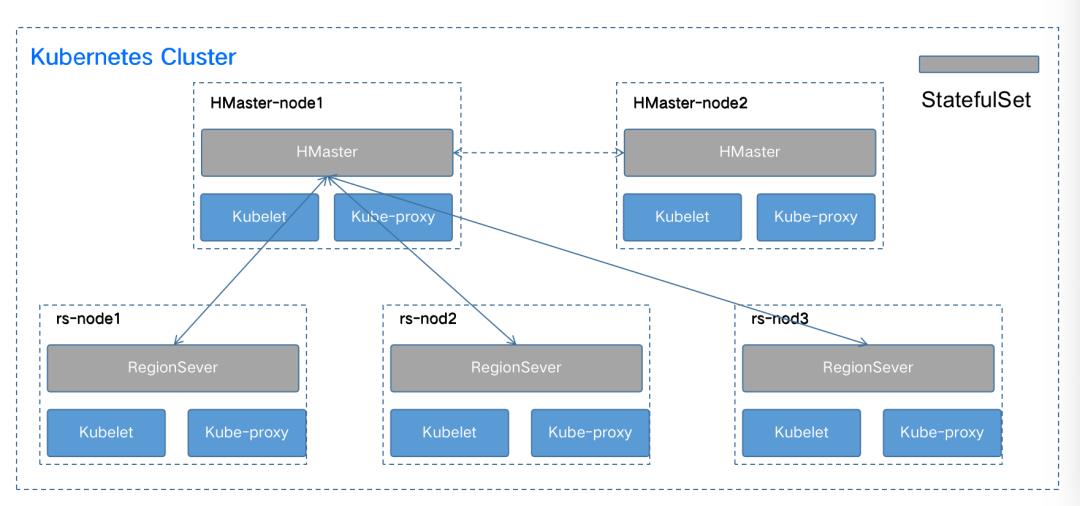
Hbase主要包括两种类型的节点,HMaster节点和HRegionServer节点。其中HMaster节点作为主节点,负责管理多个HRegionServer节点。HRegionServer节点作为worker节点,负责管理各个region。由于Hbase的实际数据存储在HDFS中,Hbase本身并不存储数据,所以HMaster和HRegionServer并不需要挂载磁盘。只是为了保持实例名称不变,HMaster和HRegionServer都采用StatefulSet的方式进行部署。
数据查询分析
Hive on Kubernetes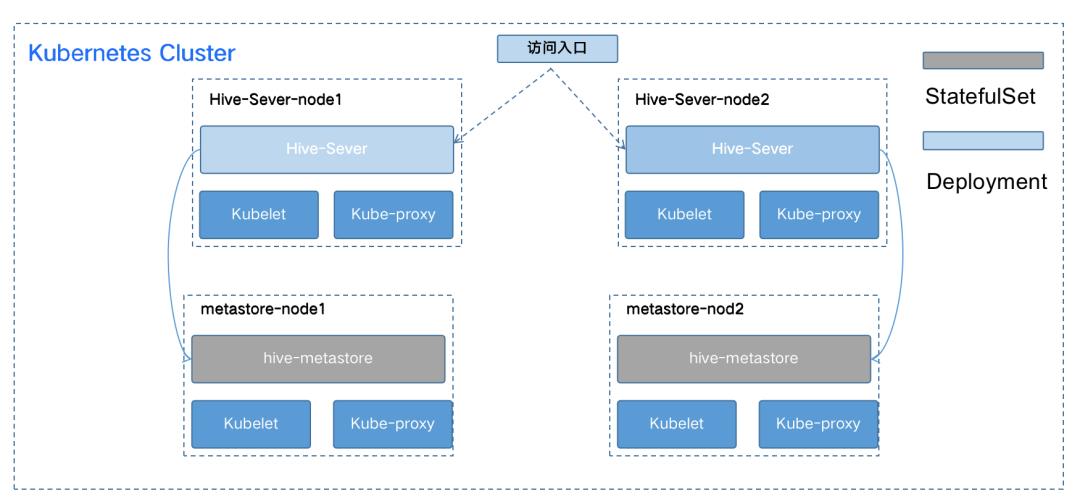
Hive主要包括hive-Server和metastore两个组件。其中hive-Server作为访问入口,可以按照在线服务一样使用Deployment[11]进行部署。metastore因为需要保持名称不变,所以使用了StatefulSet的方式进行部署。
计算框架
Spark on Kubernetes
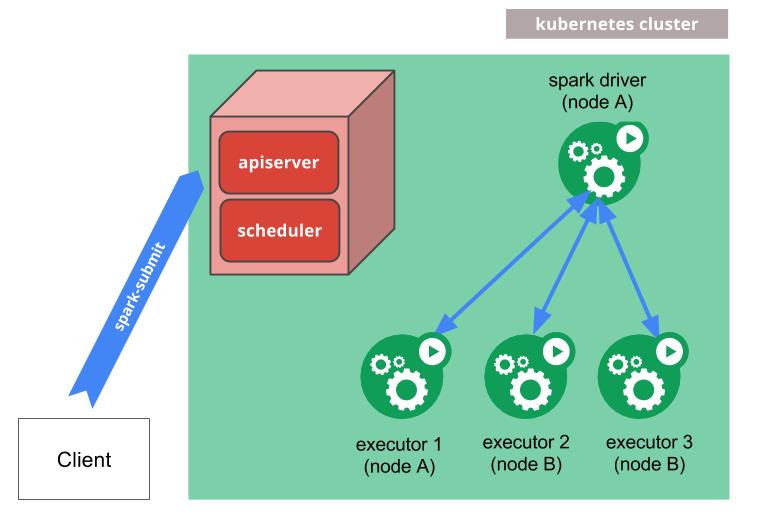
Spark是大数据领域比较早做容器化的一个组件。Spark从2.3版本支持原生的方式将任务跑在Kubernetes上。具体的实现原理如上图所示,通过spark-submit脚本向kube-apiserver提交创建请求,先创建spark的driver实例。然后driver实例按照任务执行需要的资源大小,向kube-apiserver发起请求,创建对应的executor实例,由executor实例来执行任务。Driver实例通过监听kube-apiserver中pod的信息,对executor实例的生命周期进行管理。
Flink on Kubernetes
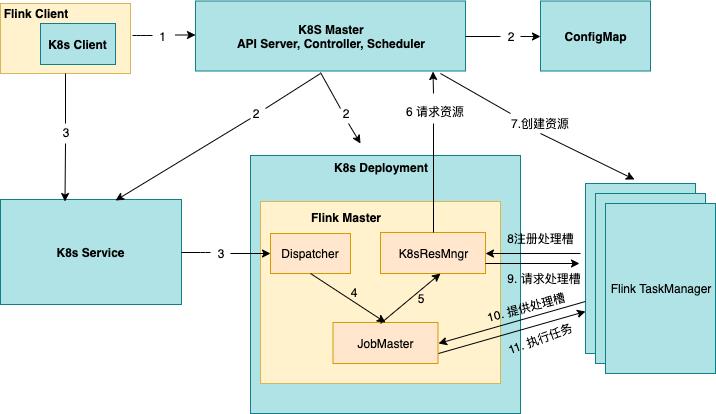
Flink与Spark类似,在其内核中直接对接了Kubernetes的kube-apiserver,以提高资源的使用效率。在Flink Client提交后,会先创建Flink Job Manager实例,然后再由Job Manager会调用Kubernetes的接口,根据任务的并行度来动态的创建对应的TaskManager实例。
通过对上面组件在Kubernetes的部署情况的分析,可以看到目前大部分的大数据组件都已经有项目来支持在Kubernetess上部署,并且借用Kubernetes不同类型的资源管理能力,就能实现对大数据组件的部署。大数据组件的容器化正在从尝试走向成熟。
腾讯大数据容器化实践
近两年腾讯内部多个部门展开了大数据容器化的实践,并取得了非常不错的效果。充分证明了大数据容器化的可行性和大数据容器化在简化运维管理成本,提升资源利用率上的效果。
云原生流计算平台Oceanus容器化实践
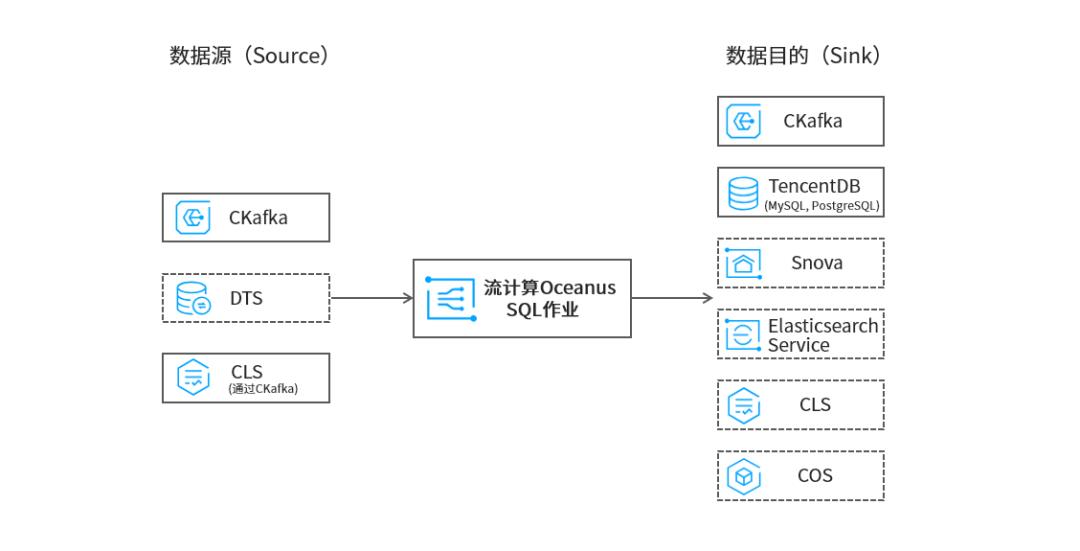
Oceanus[12] 是腾讯云推出的流计算产品,其基于 Apache Flink 构建,提供全托管的云上服务,最大规模可达万亿级。使用流计算平台Oceanus 可以方便的进行云端流式数据汇聚、计算,轻松的构建网站点击流分析、电商精准推荐、物联网 IoT 等应用。
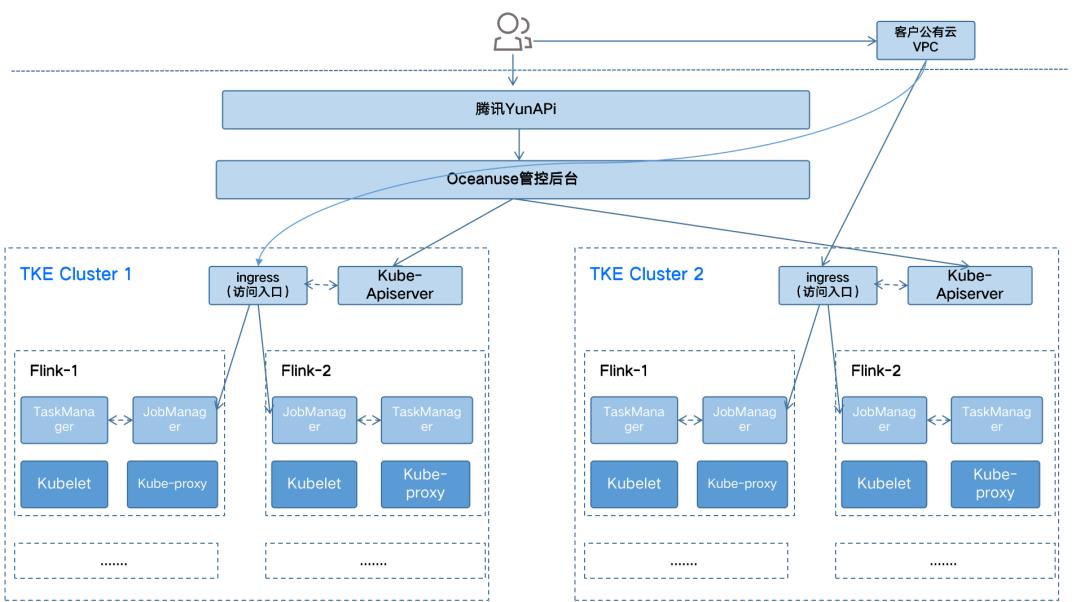
近期腾讯云容器团队和大数据团队联合推出了Oceanus on TKE[13](Tencent Kubernetes Engine)版本,通过将流计算任务运行在Kubernetes上,高效的解决了资源管理和隔离的问题。同时使用容器统一的日志采集方案,实现更好的日志采集和查看。另外使用Kubernetes提供的Ingress能力,灵活的支持查看各个大数据组件的运维页面。
腾讯云容器团队和大数据团队正打算将大数据组件逐步都运行到Kubernetes上,以实现更好的资源隔离和资源管控。为客户提供在离线统一的管理平台,达到资源运维管理的极简化,资源运行效率的极大化。
QAPM数据分析平台全面容器化实践
QAPM(Quick Application Performance Monitor) 数据分析平台是腾讯云推出的客户端性能分析平台,其依托于腾讯云的全方位定位检测APP性能的专项解决方案,实现对APP性能的高效性能分析。2018年,在开始设计和开发QAPM平台时,为了在云上充分利用资源的弹性,在云下支持私有化交付,并且尽可能降低管理成本,平台在设计之初就采用全容器化的方式进行部署。
具体的业务流程包括离线计算和流计算两个主要部分。在离线计算中,数据从客户端上报后,使用kafka进行转发,然后将数据通过Hive写入HDFS。Spark计算引擎把数据读出,经过处理后将处理的结果存入ES,Postgres,Druid等后端存储,用于前台的展示与查询。
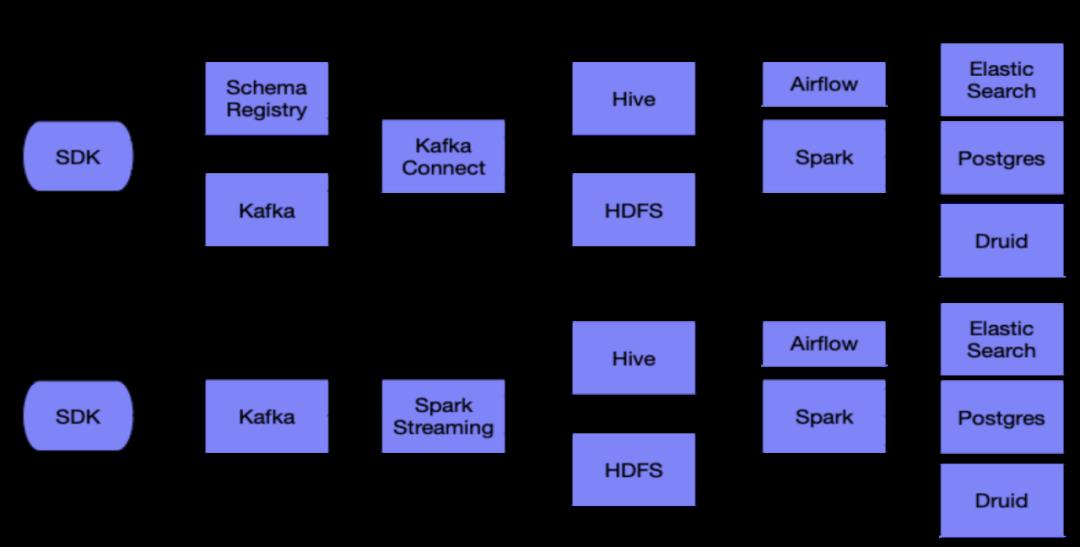
在实时计算中,数据从客户端上报后,使用kafka进行转发,然后直接经过Flink进行流式处理。处理完后数据写入入ES,Postgres,Druid等后端存储,用于前台的展示与查询。
因为所有组件都使用容器化部署,每个组件都设计成了单独的Charts包,这样部署新的环境变得非常简单。之前按照传统的方式部署一套完整的环境,花费的时间在两天甚至更多。但因为使用了容器化部署,一般半小时以内就可以完成部署和相关配置的修改。极大的提升了效率。
为了进一步提高资源资源利用率,QAPM平台在容器化的基础上通过将流计算业务和离线计算业务混合部署到了同一个集群。使用一个固定的资源池作为基础资源,在业务高峰期使用弹性扩容的方式来补充资源,使整体资源使用效率提升了30%~50%。
总结
大数据与容器编排技术,一个是在数据处理领域历史相对比较长久的互联网的基石技术,一个是在业务编排领域近年来才兴起的新兴技术。两者本来都在各自的生态中处于不断发展壮大的阶段,相互直接融合比较少。但近年来随着Kubernete技术的成熟,使大数据容器化从设想变成了可能。通过容器化技术可以像在线业务场景一样在大数据场景进一步提升运维管理和资源使用的效率,进一步释放大数据的活力。
参考链接:
图片来源于网络—大数据发展历史: https://www.damalink.com/en/buyuk-veri-yonetimi-platformu-informatica-big-data-management-uzerine/
[2]YARN-2139: https://issues.apache.org/jira/browse/YARN-2817
[3]YARN-2140: https://issues.apache.org/jira/browse/YARN-2140
[4]HADOOP-11656: https://issues.apache.org/jira/browse/HADOOP-11656
[5]CNCF: http://static.zybuluo.com/yan234280533/mc6w0m64ws5i0di8zygbybfg/image.png
[6]图片来源于网络—Use of Containers since 2016: https://www.forbes.com/sites/janakirammsv/2020/03/04/15-most-interesting-cloud-native-trends-from-the-cncf-survey
[7]Service: https://v1-16.docs.kubernetes.io/docs/concepts/services-networking/service/
[8]Ingress: https://v1-16.docs.kubernetes.io/docs/concepts/services-networking/ingress/
[9]DaemonSet: https://v1-16.docs.kubernetes.io/docs/concepts/workloads/controllers/daemonset/
[10]StatefulSet: https://v1-16.docs.kubernetes.io/docs/concepts/workloads/controllers/statefulset/
[11]Deployment: https://v1-16.docs.kubernetes.io/docs/concepts/workloads/controllers/deployment/
[12]Oceanus: https://cloud.tencent.com/document/product/849/16784
[13]TKE: https://cloud.tencent.com/document/product/849/16784
[14]BIG DATA MANAGEMENT PLATFORM ABOUT INFORMATICA BIG DATA MANAGEMENT: https://www.damalink.com/en/buyuk-veri-yonetimi-platformu-informatica-big-data-mana
--end--
以上是关于大数据组件 in K8S的主要内容,如果未能解决你的问题,请参考以下文章