大数据技术之Hadoop(MapReduce)
Posted 花花叔叔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术之Hadoop(MapReduce)相关的知识,希望对你有一定的参考价值。
文章目录
MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce核心思想
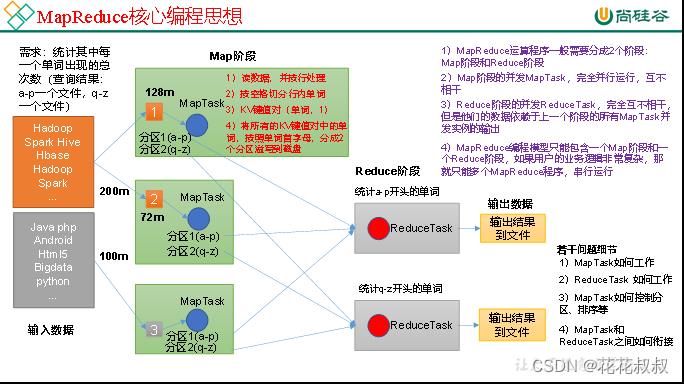
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
WordCount案例

Hadoop序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)==以便于存储到磁盘(==持久化)和网络传输。
一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能送到网络上的另外一台计算机。 然而序列化可以存储“活的由本地的进程使用,不能被发”对象,可以将“活的”对象发送到远程计算机。
MapReduce框架原理

InputFormat数据输入
MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
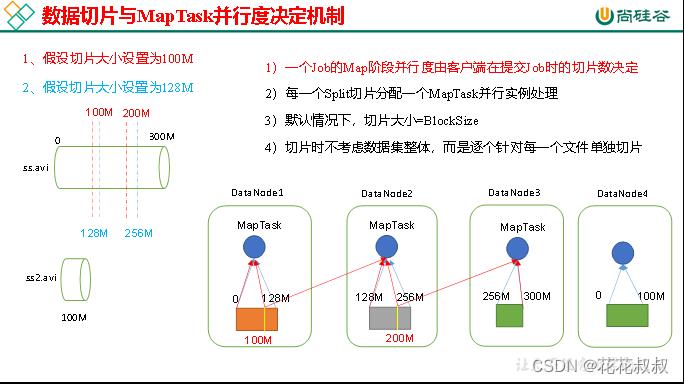
FileInputFormat切片机制

CombineTextInputFormat切片机制
1)应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。

以上是关于大数据技术之Hadoop(MapReduce)的主要内容,如果未能解决你的问题,请参考以下文章