Raft算法在分布式存储系统Curve中的实践
Posted 网易杭州研究院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Raft算法在分布式存储系统Curve中的实践相关的知识,希望对你有一定的参考价值。
作为网易数帆开源的高性能、高可用、高可靠的新一代分布式存储系统,Curve对于多副本数据同步、负载均衡、容灾恢复方面都有较高的要求。网易数帆存储团队选用Raft算法作为Curve底层一致性协议,并基于Raft的特性,实现了异常情况下的数据迁移和自动恢复。本文首先简要介绍一下Raft算法的一些基本概念和术语,再详细介绍其在Curve中的实践。
Raft一致性算法介绍
Raft算法中,有Leader、Follower、Candidate三种角色,它们之间的转换关系如下图:
在同一时刻,只能有一个Leader,当选Leader后到发起下一次选举称为一个任期(term),Leader负责通过心跳向follower保持统治,并同步数据给Follower。Follower发起选举的前提是超时未收到Leader的心跳。
Leader竞选:RAFT是一种Majority的协议,即赢得选举的条件是获得包括自己以内的大多数节点的投票。Follower超时未收到Leader的心跳,则会成为Candidate,发起新一轮的选举。每个节点在每个Term内只能投一次票,且服从先到先服务原则。为了避免多个Follower同时超时,raft中的选举超时时间是一个固定时间加一个随机时间。
日志复制:在任期内,Leader接收来自client的请求,并将其封装成一个日志条目(Raft Log Entry)把它append到自己的raft log中,然后并行地向其它服务器发起AppendEntries RPC,当确定该entry被大多数节点成功复制后(这个过程叫commit),就可以执行命令(这一步叫apply),并返回给client结果。log entry由三个部分组成,分别是:1、log index,2、log所属的term,3、要执行的命令。
配置变更:在Raft中,称复制组有哪些成员称为配置,配置并不是固定的,会根据需求增删节点或异常情况下需要替换掉有问题的节点。从一个配置直接切换到另一个配置是不安全的,因为不同的服务器会在不同的时间点进行切换。因此Raft配置变更时,会先创建一个特殊的log entry Cold,new,这条entry被commit后,会进入共同一致阶段,即新旧配置一起做决定。这时候,再生成一个Cnew的log entry,等这条entry被commit后,就可以由新配置独立做决定了。
安装快照:Raft快照指的是某个时刻保存下来的系统状态的集合。快照有两方面的作用:一个是日志压缩,打了快照之后,在此时刻之前的log entry就可以删除了。另一个是启动加速,系统起来的时候不需要重新回放所有日志。当Leader同步日志给Follower的时候,发现所需的log entry已经被快照删掉了,即可通过发送InstallSnapshot RPC给Follower进行同步。
Raft算法在Curve中的应用
Curve系统是一个分布式存储系统,在Curve系统中,数据分片的最小单位称之为Chunk,默认的Chunk大小是16MB。在大规模的存储容量下,会产生大量的Chunk,如此众多的Chunk,会对元数据的存储、管理产生一定压力。因此引入CopySet的概念。CopySet可以理解为一组ChunkServer的集合,一个Copyset管理多个Chunk,多副本间的同步和管理已Copyset为单位组织。ChunkServer,Copyset和Chunk三者之间的关系如下图:
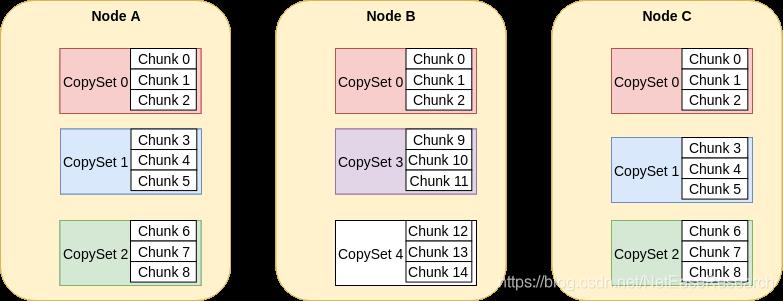
Curve copyset选用了braft作为一致性协议的组件,使用方式为multi-raft,即同一个机器,可以属于多个复制组,反过来说,一个机器上,可以存在多个raft实例。基于braft,我们实现了副本间数据同步,系统调度,轻量级raft快照等功能,下面一一详细介绍。
副本间数据同步
CopysetNode在ChunkServer端封装了braft node,具体关系如下图所示:
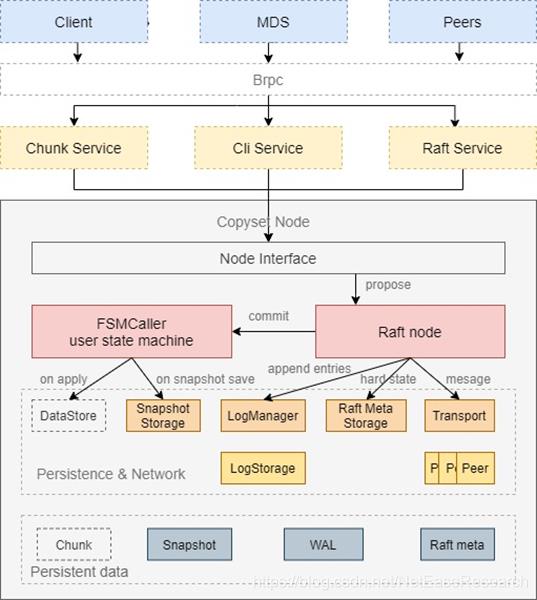
Curve client发送一个写请求时,三副本情况下的具体的步骤如下:
Client发送写请求给Leader ChunkServer。
ChunkServer收到请求,将请求封装成一个log entry,提交给raft。
braft模块在本地持久化entry的同时发送entry给其他副本(ChunkServer)。
本地持久化entry成功,且另一个副本也落盘成功则commit。
commit后执行apply,apply即执行我们的写盘操作。
在此过程中,用户的数据和操作,通过braft中的log entry的方式在副本间传递,进行数据同步。在三副本场景下,向上层返回的时间取决于两个较快的副本的速度,因此可以减少慢盘的影响。对于较慢的那个副本,leader也会通过无限重试的方式同步数据,因此在系统正常工作的前提下,最终三个副本的数据是一致的。
基于Raft的系统调度
在Curve中,ChunkServer定期向元数据节点MDS上报心跳,心跳中除了ChunkServer自身的一些统计信息,还包含ChunkServer上面的CopySet的统计信息,包含它的leader,复制组成员,是否有配置变更执行中,配置的epoch等。MDS基于这些统计信息,会生成一系列的Raft配置变更请求并下发给Copyset的leader所在的ChunkServer。
下发配置变更
Curve ChunkServer会定期向MDS上报心跳。MDS调度下发配置变更是在心跳的response中完成的。上报心跳的过程如下图:
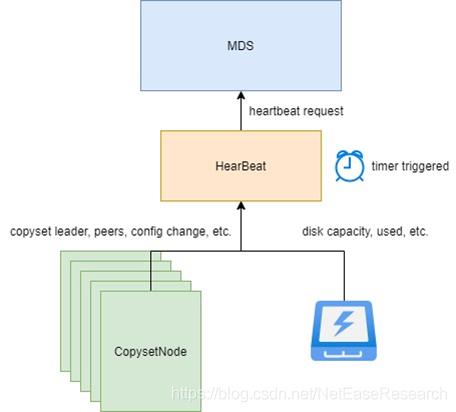
心跳是定时任务触发的,ChunkServer除了上报一些自己的容量信息等统计信息外,还会上报Copyset的一些信息,比如leader,成员,epoch,是否有进行中的配置变更等。
MDS在心跳response中下发配置变更的过程如下图:
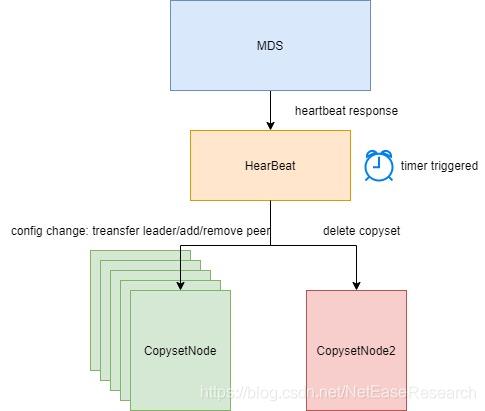
ChunkServer收到response后,解析其中的配置变更信息,并下发给每个Copyset。
Curve epoch
epoch同步配置。MDS生成的调度信息,是由后台定时任务触发,并在ChunkServer下一次请求到来时在response中下发的,因此MDS下发的配置变更有可能是过期的。为了实现MDS和ChunkServer之间的配置同步,Curve引入了epoch机制,初始状态,epoch初始为0,每进行一次配置变更(包括leader变更),epoch都会加一。当MDS中的epoch等于ChunkServer端的epoch时,即将下发的配置变更才被认为是有效的。epoch与term有何区别?term用于表示Leader的任期,即只跟选举有关,而epoch是与配置变更相关的,也包括了Leader选举这种情况。
epoch的更新。epoch是在ChunkServer端更新的,braft在实现上提供了一个用户状态机,在braft内部发生变化,比如apply,出错,关闭,打快照,加载快照,leader变更,配置变更等时会调用用户状态机中对应的函数。Curve copyset通过继承的方式实现这个用户状态机来完成与braft的交互,epoch是在on_configuration_committed函数中加一的。在braft中,当Leader变更的时候会把当前的配置再提交一遍,因此在on_configuration_committed中增加epoch即可保证在配置发生变化或者Leader变更时epoch顺序递增。
epoch的持久化。在MDS端,epoch随着CopySet的其他信息一起持久化在etcd中。ChunkServer也对epoch进行了持久化,但是ChunkServer中持久化epoch并不是每次epoch发生变化都需要持久化的。这是利用了raft的日志回放和快照功能。考虑以下两种情况:
假设raft没有打快照,那么就不需要持久化epoch,因为所有操作日志,包括配置变更的entry都已持久化,当服务重启的时候,回放这些日志的时候会依次再调用一遍on_configuration_committed,最后epoch会恢复到重启前的值。
当raft有快照时,打快照前的entry都会被删除,就不能通过上面的方式回放,因此必须要持久化。但我们只需要在打raft快照时持久化epoch的当前值即可。这样当系统重启的时候,会先安装raft快照,安装后epoch恢复到快照时的值,再通过执行后面的log entry,最终epoch恢复到重启前的值。在打快照时更新epoch是在on_snapshot_save函数中完成的。
Raft轻量级快照
上面介绍Raft算法的时候介绍过,Raft需要定时打快照,以清理老的log entry,否则Raft日志会无限增长下去。打快照的时候需要保存系统当前的状态,对于Curve块存储场景来说,系统状态就是Chunk当前的数据。直观的方案是将打快照时刻的全部chunk拷贝一遍备份起来。但是这样有两个问题:
空间上要多出一倍,空间浪费非常严重。
Curve默认打快照的间隔是30分钟一次,这种方案下会有频繁的数据拷贝,对磁盘造成很大的压力,影响正常的IO。
因此,Curve中使用的Raft快照是轻量级的,即打快照的时候只保存当前的Chunk文件的列表,不对Chunk本身做备份。具体流程如下:
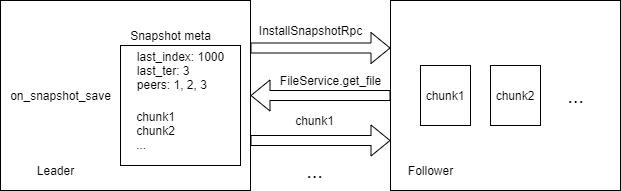
这样操作,Follower下载到的chunk文件不是打快照时的状态,而是最新的状态,在回放日志的时候,会把这些新数据再写一遍。但这对于我们的场景是可以接受的,因为底层都是覆盖写是幂等的,即写一次和写多次结果是一致的。
小结
本篇文章首先介绍了Raft一致性算法的一些基本概念。随后介绍了Raft算法新一代高性能分布式存储系统Curve中的应用,分别从数据同步、系统调度和Raft快照三个角度介绍了Curve中使用Raft的细节。关于Curve的更多介绍详见我们的代码仓库:https://github.com/opencurve/curve。另外,Curve开源分享也在火热进行中,分享的PPT可以在https://github.com/opencurve/curve-meetup-slides仓库中获取。
作者简介
查日苏,网易数帆存储团队高级C++开发工程师,高性能分布式存储系统Curve核心开发。
相关视频:
相关文章:
分享预告:
Curve系列技术课程,每周五晚19:00 B站直播,本周五主题为 Curve 快照克隆,敬请点击左下角“阅读原文”或识别下图二维码收看!
以上是关于Raft算法在分布式存储系统Curve中的实践的主要内容,如果未能解决你的问题,请参考以下文章