深入解析Raft模块在ZNBase中的优化改造(上)
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解析Raft模块在ZNBase中的优化改造(上)相关的知识,希望对你有一定的参考价值。
导读
云溪数据库 ZNBase 是由浪潮开源的一款 NewSQL 分布式数据库,具备 HTAP 特性,拥有强一致、高可用的分布式架构。对于一个高可用的分布式系统来说,为了保障不同集群不同节点的数据一致,一致性算法尤为重要。Raft 是一种管理日志复制的分布式一致性算法,包括 ZNBase 在内的很多分布式系统都采用 Raft 作为底层的一致性协议。本系列文章将为大家介绍 Raft 一致性算法在 ZNBase 中的落地实践,并深入解析 ZNBase 技术团队根据自身业务需求对 Raft 协议做出的五大优化改进。
Raft 简介
Raft 作为一种管理日志复制的分布式一致性算法,由斯坦福大学的 Diego Ongaro 和 John Ousterhout 在论文中提出。在 Raft 出现之前,Paxos 一直是分布式一致性算法的标准。但 Paxos 相对难以理解,Raft 的设计目标就是简化 Paxos,使得一致性算法更容易理解和实现。
Paxos 和 Raft 都是分布式一致性算法,其过程如同投票选举领袖(Leader),参选者(Candidate)需要说服大多数投票者(Follower)给他投票,一旦选举出领袖,就由领袖发号施令。Paxos 和 Raft 的区别在于选举的具体过程不同,社区中关于 Raft 算法的详细讲解非常丰富,这里就不再赘述。查看详情:https://my.oschina.net/vivotech/blog/5023558
ZNBase 中的 Raft 算法
云溪数据库 —— ZNBase 是分布式数据库,与 OceanBase、CockroachDB、TiDB 一样都是NewSQL 家族的一员。云溪数据库具备强一致、高可用的分布式架构,能够水平扩展,提供企业级的安全特性,完全兼容 PostgreSQL 协议,能够为用户提供完整的分布式数据库解决方案。ZNBase 的整体架构如图 1 所示:
图1:ZNBase 的整体架构
ZNBase 各方面的强一致性都通过 Raft 算法实现。首先,Raft 算法保证分布式多副本之间数据强一致性以及外部读写的一致性。简而言之,ZNBase 中数据会有多个副本,这些副本存放在不同的机器上,当其中一台机器故障宕机后,数据库依旧能够对外提供服务。此外,ZNBase 会根据插入数据的键,将数据划分为多个 Range,每个 Range 上的数据均由一个 Raft Group 来维持多个副本之间数据的一致性。因此,准确地说 ZNBase 使用的是 Multi-Raft 算法。
具体来说,ZNBase 的存储层基于 RocksDB 开发,利用单机的 RocksDB,ZNBase 可以将数据快速地存储在磁盘上;在出现单机故障时,利用 Raft 算法可以快速地将数据复制到机器上。在这个过程中,数据的写入是通过 Raft 算法接口实现的,而不是直接写入 RocksDB。通过 Raft 算法,ZNBase 变成了一个分布式的键值存储系统,面对不超过集群半数的机器故障情况宕机,完全能够通过 Raft 算法自动把副本补全,做到业务对故障的无感知。
在项目开发前期,ZNBase 中的 Raft 算法采用的是开源的 etcd-raft 模块,该模块主要提供如下几点功能:
Leader 选举;
成员变更,可以细分为:增加节点、删除节点、Leader 转移等;
日志复制。
ZNBase 利用 etcd-raft 模块进行数据复制,每条数据操作都最终转化成一条 RaftLog,通过 RaftLog 复制功能,将数据操作安全可靠地同步到 Raft Group 中的每一个节点上。不过在实际操作中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
但是在后续的生产实践中,ZNBase 研发团队逐渐发现 etcd-raft 的模块仍存在诸多限制,于是陆续开展了如下多个方面的优化工作,具体包括:
新增 Raft 角色
新增 Leader 亲和选举
混合序列化
Raft Log 分离与定制存储
Raft 心跳与数据分离
下文将着重介绍第一点,即 ZNBase 团队根据自身业务需要为 Raft 模块新增的三种角色。
ZNBase 对 Raft 模块的改进
新增 Raft 角色
1、强同步角色
为解决部署在跨地域的多数据中心数据同步问题,达到数据在多地共同写入的效果,实现地域级别的容灾能力,ZNBase 研发团队在 etcd-raft 模块中新增了强同步角色。
具体措施如下:
为副本增加强同步标识以及配置和取消强同步标识的逻辑。
etcd-raft 模块原有的日志提交策略:Leader 得到超过半数副本(包括 Leader 自身)的投票才能提交 Raft 日志。ZNBase 在原有的过半数提交策略基础上,增加了强同步角色的日志提交策略——日志提交还需要得到所有强同步副本的投票。
为强同步角色设计了如图 2 所示的故障识别与处理机制:通过心跳超时机制识别强同步故障,提交日志时忽略故障的强同步角色,并将故障信息录入数据库日志并告知用户。
为强同步角色的心跳超时时间增加热更新功能。
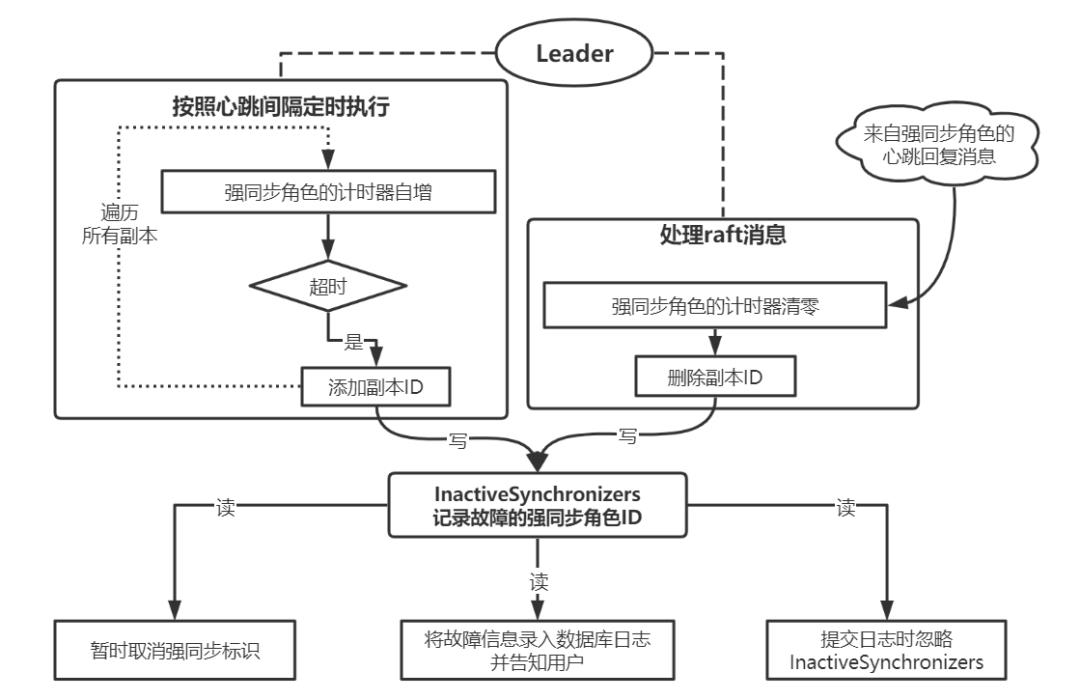
图2 强同步角色的处理逻辑
经过以上四点改造后,etcd-raft 模块新增强同步角色,能够实现如下功能:
允许用户为指定副本配置或取消强同步角色,不影响强同步角色所在副本的原有特性。例如对全能型副本配置强同步角色后,该副本依然存储 Raft 日志和用户数据,参与投票,参与 Leader 选举,当选为 Leader 可提供读写服务,Follower 时可提供非一致性读。
强同步角色的数据与 leader 保持同步。
允许用户配置强同步角色的心跳超时时间。如果强同步角色发生故障,Raft 集群将在该超时时间后恢复写入功能,故障期间的写入也会在超时时间后提交。Raft会在识别到强同步角色故障后暂时取消强同步标记,并在该强同步角色故障解决后自动恢复。强同步角色故障和恢复的信息对用户可见。
允许用户在 SQL 终端查询强同步角色的配置状态。
2、只读型角色
由于 ZNBase 具备 HTAP 的特性,因此需要在 Raft Group 中增加一种相对独立的特殊副本,对外仅提供读服务(例如将该类型副本的存储引擎替换成列存引擎)以实现 OLAP 的功能。为了在 Raft Group 中增加这种特殊副本,同时不影响原有的集群特性,ZNBase 研发团队在 Raft 中设计了一种新的只读型角色。
具体实现措施如下:
增加只读型角色标识,增加只读型角色的创建、删除、重平衡逻辑。
增加只读型副本接收到请求后读取数据的逻辑:如果只读型角色的时间戳不小于请求的时间戳,则提供读服务;否则会重试多次,重试达到限制后会将读取超时错误返回到 SQL 终端。
为只读型副本的时间戳更新间隔、读取时的最大重试次数等参数增加热更新功能。
etcd-raft 模块新增只读型角色后,能够实现如下功能:
允许用户在指定位置创建、删除或移动只读型角色。只读型角色支持基于负载均衡的重平衡功能,移动到压力相对较小的节点。
该角色对外仅提供读服务,存储 Raft 日志和用户数据,不参与投票,不参与 Leader 选举,可提供读服务。
允许用户配置只读型副本的时间戳更新间隔、读取时的最大重试次数,可以用于对只读型副本的读取性能进行调优。
允许用户在 SQL 终端查询只读型角色的配置情况。
3、日志型角色
ZNBase 不支持在两数据中心三副本部署模式下提供双活模式,无论如何部署副本的位置,总有一个数据中心拥有过半数的副本。当拥有过半数副本的数据中心故障时,另一个数据中心由于所拥有的可用副本数不满足过半数,会导致 ZNBase 无法对外正常提供服务。为解决此类问题,提高 ZNBase 的容灾能力,同时充分利用和整合资源,避免出现资源闲置造成的浪费现象,提升双活数据中心的服务能力,项目团队在 etcd-raft 模块增加了日志型角色。
具体实现措施如下:
日志型副本参与 Leader 选举,拥有投票权,并且可以成为 Leader。在普通副本缺少最新日志的故障场景下,为了恢复集群的可用性,需要日志型副本当选为 Leader,并向其他副本追加日志,使得该副本拥有最新的日志。然后发起 Leader 转移,拥有最新日志的副本当选为 Leader 和 Leaseholder,完成集群恢复。
日志型副本不能发送快照。由于日志型副本不含用户数据,若发送快照将导致其他副本丢失数据,因此禁止日志型副本发送快照。
日志型副本不能成为 LeaseHolder。禁止从日志型副本读取数据,且在日志型副本成为Leader 的情况下,在其他副本拥有最新日志后,将立即转移 Leader 到该副本上。
日志型副本保留日志。日志型副本的日志可用于故障恢复,因此延长其日志保留时间。原有的日志清理策略为当可清理的日志 index 数量大于等于 100 或实际大小大于等于 64KB 时,执行日志清理操作。当出现节点宕机时,待清理的日志超过 4MB 执行日志清理操作。日志型副本的日志清理策略为:将日志清理请求按小时打包、延迟处理,默认清理时间值为24,即将日志清理请求延迟24小时处理,达到日志保留的效果。用户可配置清理时间值,可配置范围是[-1, MaxInt],若配置为 -1 则表示不保留日志,按照原来的逻辑执行清理操作。
日志型副本异地重启。日志型副本异地重启时会因尝试提交心跳消息携带的 Commit 值而宕机。修改 follower 处理心跳的逻辑,如果日志型 follower 收到心跳消息的 Commit 值比实际的 lastIndex 值大,就将心跳回复消息的 Reject 字段置为 true、RejectHint 字段置为实际的 lastIndex。Leader 收到 Reject 为 true 的心跳回复消息时,将对应 follower 副本 progress 的 Match 和 Next 更新为实际值,并向该副本追加日志,将其丢失的日志补全。
针对日志型角色增加 Logonly 语法支持,使用 Alter 语句配置样例如下,表 t 拥有 3 个副本,其中将 2 个全能型副本放在北京和济南,日志型副本放在天津:
ALTER TABLE t CONFIGURE ZONE USING num_replicas=2, num_logonlys=1, constraints='{"+region=beijing": 1,"+region=jinan": 1}', logonly_constraints='{"+region=tianjin":1}';
以两中心三副本(一个全能型、一个强同步、一个日志型)模式进行部署为例,全能型副本与强同步副本分别存放在 DC-1 与 DC-2 的高配机器(或多数机器)中,日志型副本存放在 DC-1 或 DC-2 的低配机器(或少量机器)中,日志增量复制到另一个数据中心的低配机器(或少量机器)。若遭遇数据中心级别的故障,在失去两个副本(一个全能型、一个日志型)后,在另一个数据中心手动启动存放日志型副本的节点,该日志型副本含有基于增量复制得到的日志数据。
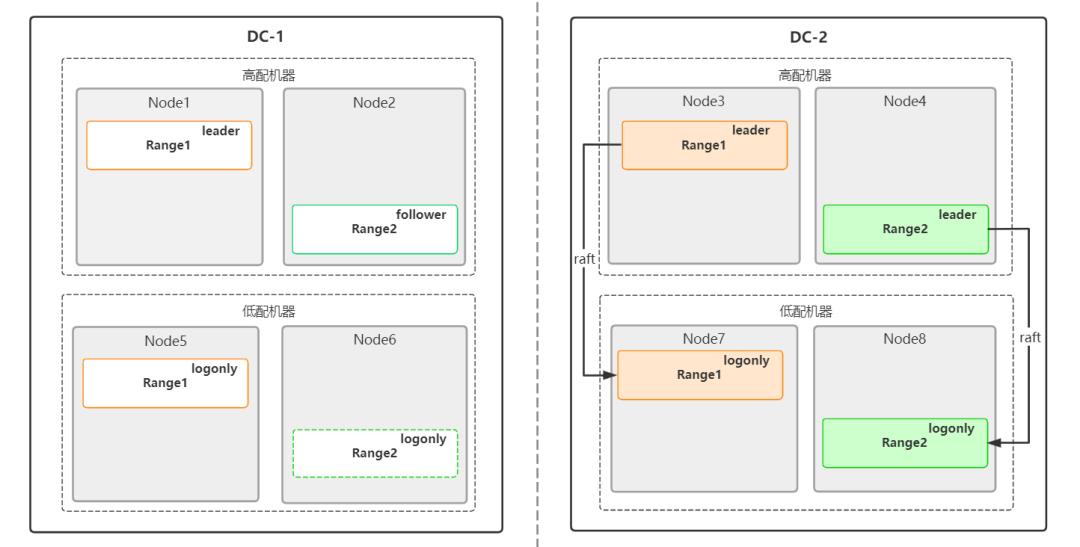
遭遇数据中心级别的故障时的容灾处理(Node7 的日志型副本需要手动重启)
通过给 Raft 算法增加 3 种新的角色,ZNBase 在跨地域集群容灾、支持 OLAP 等方面的能力得到了显著加强。
小结
本文介绍了 Raft 一致性算法在分布式 NewSQL 数据库 ZNBase 中发挥的重要作用,以及 ZNBase 项目团队根据自身业务特性与需求,在 Raft 算法中新设计的三种角色,从而提高了 ZNBase 的异地容灾和 HTAP 的能力。除了新增 Raft 角色以外,ZNBase 研发团队还针对 Raft 模块做了新增 Leader 亲和选举、混合序列化、Raft Log 分离与定制存储和 Raft 心跳与数据分离等优化改进,受篇幅限制,我们将在接下来的文章中详细解析这四大改进。
关于 ZNBase 的更多详情可以查看:
官方代码仓库:https://gitee.com/ZNBase/zn-kvs
ZNBase 官网:http://www.znbase.com/
对相关技术或产品有任何问题欢迎提 issue 或在社区中留言讨论。
以上是关于深入解析Raft模块在ZNBase中的优化改造(上)的主要内容,如果未能解决你的问题,请参考以下文章