深入解析分布式数据库ZNBase的SQL引擎优化
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解析分布式数据库ZNBase的SQL引擎优化相关的知识,希望对你有一定的参考价值。
导读
前文提到,ZNBase 是由浪潮开源的一款 NewSQL 分布式数据库,基于谷歌 Spanner+F1 的论文设计,完美继承了 Spanner 的设计理念,实现了基于对等架构的分布式 SQL 引擎。ZNBase 的 SQL 引擎包含连接、编译、缓存、分布式日志和分布式执行五大服务组件,实现了多集群多节点协同的高效计算,大大提升了用户的查询效率。
为了进一步提升 SQL 引擎的性能,ZNBase 研发团队结合实际业务需求,在原有架构的基础上,针对 SQL 引擎的编译服务、执行服务、算法等方面进行了一系列深度定制化的优化改进工作。本文将这些改进工作逐一展开介绍。
ZNBase 针对 SQL 引擎的优化改进
1.编译服务优化
1.1 类型、功能、语法兼容
随着日益增多的场景需要,ZNBase 陆续完善了对 PostgreSQL 、Oracle、mysql 语法、类型、函数的兼容。
1.2 计划优化
ZNBase 还扩展了统计信息功能,除了:表的行数,表中列的 Distinct 值(某一列的唯一值总共有多少条),还额外引入了直方图。为 CBO 的优化提供了更多的一句。
对每个 range 进行抽样,用蓄水池算法生成样本集合,然后用样本进行各种统计信息的预估,将结果通过写入函数 writeResults,写进系统表 system.table_statistics 中。
ZNBase 扩展了对执行计划的管理,包括执行计划绑定、自动捕获绑定、自动更新绑定等。执行计划绑定功能使得可以在不修改 SQL 语句的情况下选择指定的执行计划。用户通过绑定执行计划,可以将计划存入 ZNBase 中,下次再执行解析后计划相同的 SQL 语句时,只要取出之前存入的计划即可,省去了构建计划的时间。ZNBase 还会智能地自动捕获执行频率较多的并且用户之前没有手动为其创建绑定的 SQL 语句,在后台自动为其创建计划绑定。
由于表数据的变化,如:数据变化、数据结构变化、统计信息变化,可能会导致之前绑定的执行计划执行效率降低,ZNBase 将自动检测执行时间,将绑定好的执行计划进行优化,为用户提高复合当前数据场景的更高的执行效率。
2. 执行优化
2.1 矢量算子
ZNBase 还引入了矢量算子,相比基于 Goetz Graefe 论文的“火山”模型,“矢量”模型在计算行数明显大于列数的场景下,性能会有极大的提升。
从原理上讲,这是用一系列专门针对数据类型和计算的特定编译循环代替了通用的类似于解释器的 SQL 表达式评估器,因此计算机可以连续执行许多更简单的任务,大大节省了重复的计算所需要的时间。配合 ZNBase 团队开发的列式存储,查询性能还将有进一步的提升。
目前矢量算子支持的类型有:Array、BIT、BOOL、BYTES、COLLATE、DATE、DECIMAL、INET、INT、INTERVAL、JSONB、SERIAL、TIME、TIMESTAMP、TIMESTAMPTZ、UUID、FLOAT、STRING 等。
目前 ZNBase 支持的矢量算子有:Noop、TableReader、Distinct、Ordinality、Hashjoiner、MergeJoiner、Sorter、Windower 等。
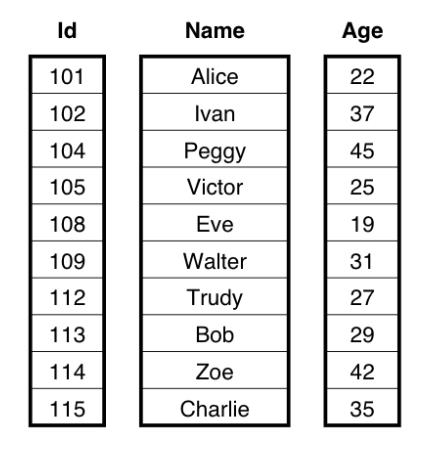
举例来说,请考虑一个包含三列的 People 表:Id,Name 和 Age。在火山模型中,每个数据行由每个算子处理一次 —— 一种逐行执行方法。相比之下,在矢量化执行引擎中,我们一次传递了有限大小的面向列数据的批处理。我们使用一组列,而不是使用元组数组的数据结构,其中每一列都是特定数据类型的数组。在该示例中,分批处理将由一个Id的整数数组,一个 Name 的字节数组和 Age 的整数数组组成。下图显示了两个模型中数据布局之间的区别:
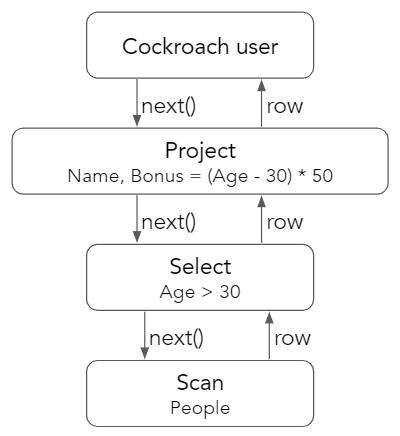
SELECT Name, (Age - 30) * 50 AS Bonus FROM People WHERE Age > 30;
这样的语句查询,在火山模型中,顶级用户向 Project 算子请求一行,该请求被传播到底层的 Scan 算子。扫描从键值存储中读取一行,并将其传递给 Select,Select 将检查该行是否通过了 Age> 30 的谓词。如果该行通过了检查,则将其返回给 Project 算子以计算 Bonus = (Age - 30) * 50 作为最终输出。
一次处理一行,对于每一行,我们都在调用一个完全通用的标量表达式的过滤器!表达式可以是任何东西:乘法,除法,相等检查或内置函数,甚至可以是一长串这样的东西。由于这种通用性,计算机在每一行上都有很多工作要做——必须在甚至无法执行任何工作之前检查表达式的含义。与编译后的语言相比,这种计算方式与解释型语言同样麻烦。
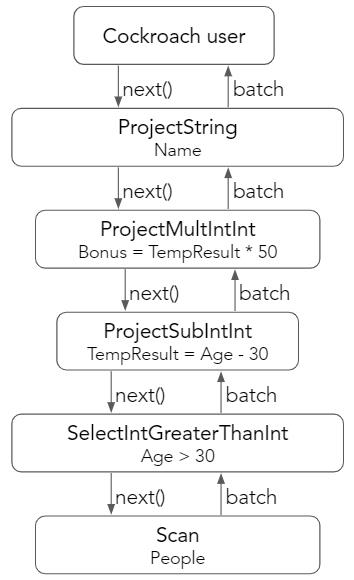
在矢量化模型中,我们采用不同的方式。每个矢量化算子背后的原理是在执行期间不允许任何自由度或运行时选择。这意味着对于任务,数据类型和属性的任意组合,应该由一个专门的算子来负责这项工作。对于示例查询,用户从算子链中请求一批。每个算子都向其子级请求一批,执行其特定任务,然后将一批返回给其父级。
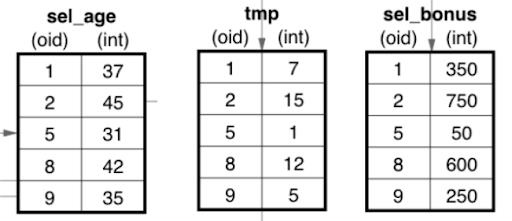
为了对此进行可视化,请考虑由 SelectIntGreaterThanInt 处理的 People batch。该算子将选择所有大于 30 的 Age 值。这个新的 sel_age batch 然后传递到 ProjectSubIntInt 算子,该算子执行简单的减法运算以生成 tmp batch。最后,将这个 tmp batch 传递给 ProjectMultIntInt 算子,该算子将计算最终 Bonus =(Age-30)* 50 值。
2.2 并行优化
在ZNBase的开发过程中也对算子进行了优化,提高了运算效率。
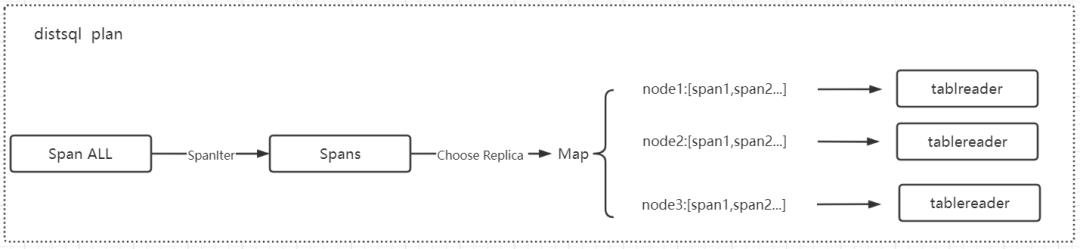
Tablereader 通过拆分 Span 进行并行的 baRequest 下发读取数据,返回的数据封装进 baResponse 里面,放入管道由 tablereader 进行并行处理。
Step1:Span 拆分,逻辑计划完成后会生成一个 Span ALL(索引、主键查询除外),Span ALL 会根据 table 的 range 边界拆分从成多个范围更小的 Span,每个 Span 会获得相应的 range 信息,根据 rangeID 可以取得对应 range 的副本信息,再根据副本选择策略(就近选择、随机选择、lease holder(默认)),获取到对应副本的 nodeID,再将该 Span 放入一个 Map 结构(Map[nodeID][]Span)中;
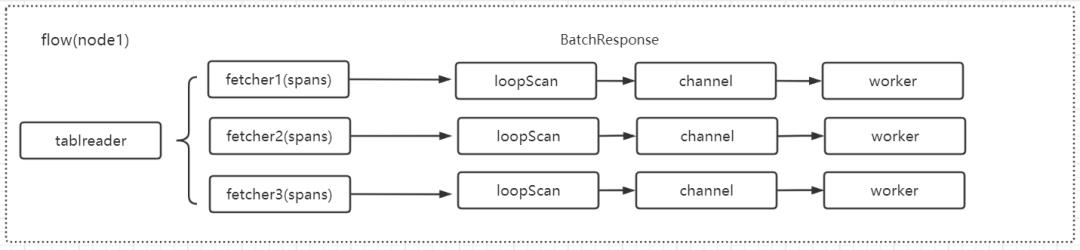
当 tablereader 下发到了对应节点后,再将 Spans 进行均匀分配进 tablereader 的各个 worker fethcer 当中进行并行的数据读取:
Step2:BatchRequest 下发,对应节点的 tablereader 的每个 fetcher 的 spans 的每一个 span 会封装为一个 ScanRequest 请求,多个 ScanRequest 请求封装进一个 BatchRequest(BacthRequest 请求中 header 信息可以指定一次请求返回的最大 kv 数目),该 BacthRequest 经过分发层逻辑后下发至对应节点的对应 Store 进行数据查询,返回的数据封装为 BatchResponse,包含多个对应的 ScanResponse,将 ScanResponse 的 kv 数据放入 channel 中,再由每个 fetcher 绑定的 worker 进行 kv 解码以及后续的处理:
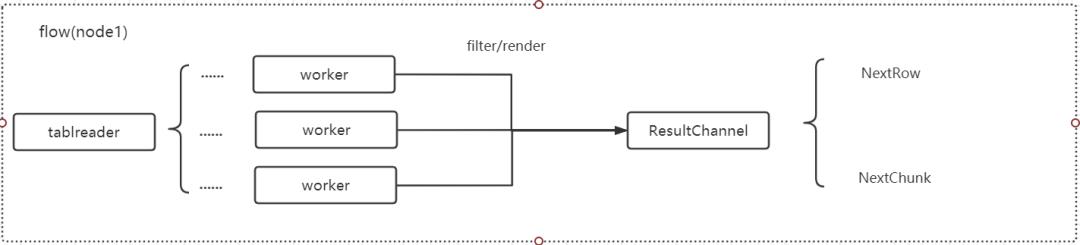
Step3:数据返回,每个 fetcher 的 worker 协程处理(经过 filter 或 render )完每行 kv 数据后都会放入一个 buffer 当中(默认 buffer 缓存<= 64 行),每个 worker 每完成一个 buffer 会将该 buffer 放入 tablereader 的结果管道中,提供 NextRow 和 NextChunk 两类接口供上层算子调用:
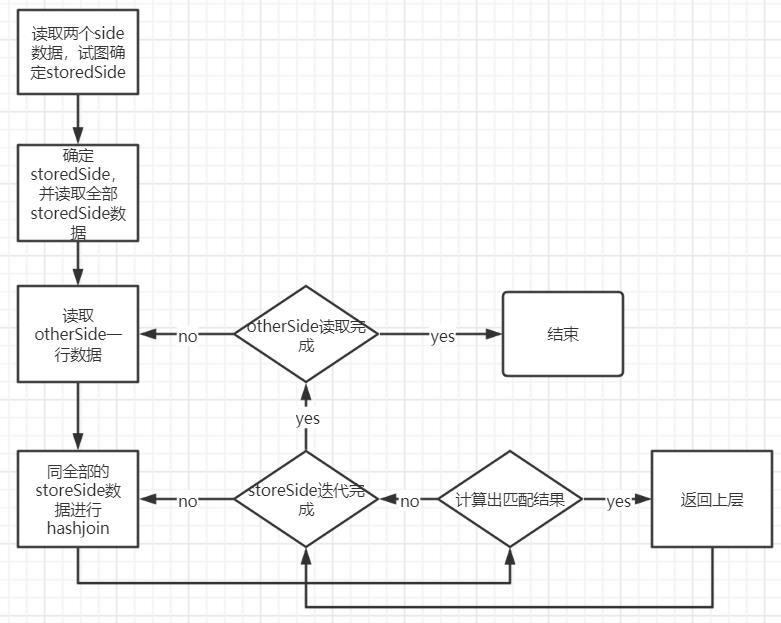
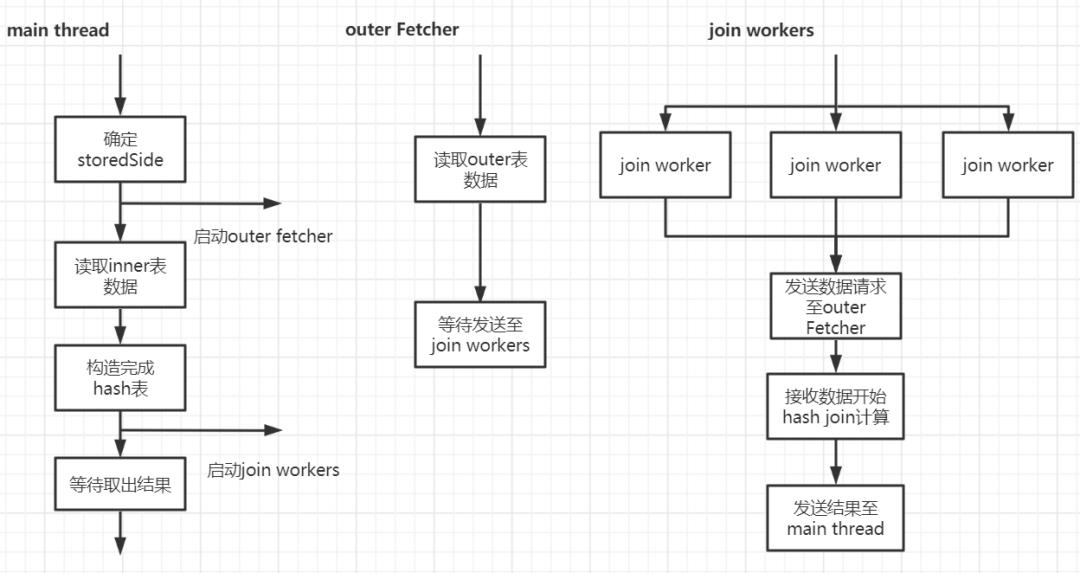
经过优化后 hashjoin 由 3 个部分完成:
Main thread:构造 hash 表;启动 Outer Fecther 和 Join Workers;从 join Woker 拿取计算结果,返回至上层;等待所有的 join worker 结束,更新状态为计算完成。
Outer Fetcher(协程):循环读取 Outer 表每一行数据,将读取的数据通过 channel 传递给 Join Woker 进行计算;通知 Join Wokers Outer 表读取完成。
Join Workers(协程):将 Outer Fetcher 发送来的数据进行 hash join 计算;将计算结果通过 channel 发送至 Main thread。
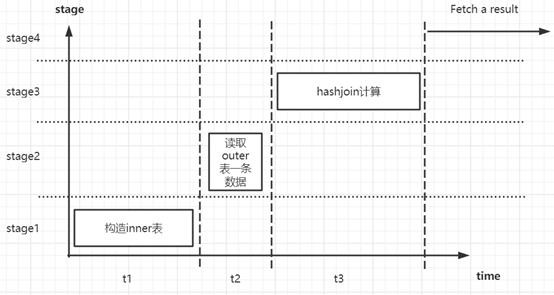
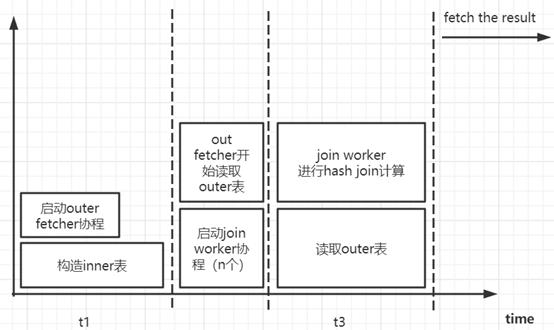
设构造 inner(storedSide)一侧的 hash 表时间为 t1
设读取一条 outer(otherSide)数据时间为 t2
设执行一轮 hashjoin 时间为 t3
设 outer(otherSide)表有 m 条数据
预期:随着 outer 表数据增多和 join worker 协程数增加,理论上优化越明显。
计算读取分离:将读取 outer 表和 hash join 计算分离,使得读取 outer 表下一行数据不必再等待上一个 hash join 计算完成。
并行计算:启用多个 join worker 参与 hash join 计算,提高了并行度。
展望未来
大数据行业的发展促进了国产分布式数据库的演进,为适应这种发展大潮,云溪 NewSQL 数据库 ZNBase 也会促使分布式 SQL 引擎更趋向完善,未来会在语法上完全兼容 Oracle 等传统数据库,计划上加入更丰富的 HBO,完善 Cascade 框架,更加智能的提高用户的使用体验,执行上会兼容 HTAP 计算方式,顺应当下飞速增长的数据量,适配更多的大数据、人工智能、机器学习场景,提供一个更智能、更高效的 SQL 计算引擎。
参考文档 [1]. Volcano-An Extensible and Parallel Query Evaluation System
官方代码仓库:https://gitee.com/ZNBase/zn-kvs
ZNBase 官网:http://www.znbase.com/
以上是关于深入解析分布式数据库ZNBase的SQL引擎优化的主要内容,如果未能解决你的问题,请参考以下文章
深入解析Raft模块在ZNBase中的优化改造(下)
openGauss数据库源码解析系列文章—— SQL引擎源解析
大数据SQL引擎架构浅析
大数据SQL引擎架构浅析
ZNBase分布式存储的负载均衡
Flink SQL 之 Calcite Volcano优化器(源码解析)