让我们一起揭开Etcd背后Raft算法的面纱
Posted 云原生技术爱好者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让我们一起揭开Etcd背后Raft算法的面纱相关的知识,希望对你有一定的参考价值。
背景
最近在使用K8S过程中,一直用到了一个Key-Value数据库Etcd,每当看到有介绍Etcd的教程时,介绍不多,大多都是独立于K8S集群之外,保存状态数据。再深入百度下,发现Etcd是一个可靠的,分布式的Key Value存储系统,它用于存储分布式系统中的关键数据,一个Etcd集群,通常会由3个或者5个节点组成,多个节点之间,通过一个叫做Raft一致性算法的方式完成分布式一致性协同,算法会选举出一个主节点作为leader,由leader负责数据的同步与数据的分发,当leader出现故障后,系统会自动地选取另一个节点成为leader,并重新完成数据的同步与分发。
看到这里,大概知道Etcd之所以可靠,是因为背后的Raft算法的支撑,仔细思考下,Raft协议是什么? 它是如何进行选举的?leader节点挂了,又如何保证各个节点数据一致? 成员节点变更会出现脑裂问题吗?带着这些问题,我们一起揭开Raft本后真实面纱。
Raft算法概念
通俗易懂的来说,Raft算法是一个通过以领导者为准的方式,实现各个节点的通信和数据的一致;如果领导节点宕机,则通过特定规则重新选出新的领导者。
这就好比村里选举一样,首先村里会有一个村长,村长就是这个村子里的扛把子,一切都得听他的,后来呢,因为抗疫不力,被干掉了,村子不可一日无长,重新推举出候选人,如何选举村长? 首先推举候选人,然后投票选举。所以整个raft算法中存在这样三个角色:分别是跟随者、候选人、领导者。
跟随者:普通群众,默默听从指挥,如果找不到领导者,那么推荐自己为候选人;
候选人:候选人向其它节点请求投票,如果获得大多数的投票,那么将成为领导者;
领导者:一切以我为准,所有节点都得听我的。
如何进行选举?
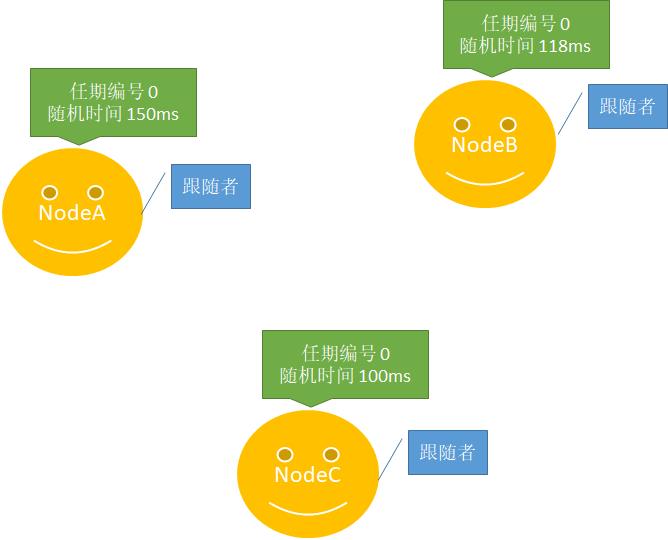
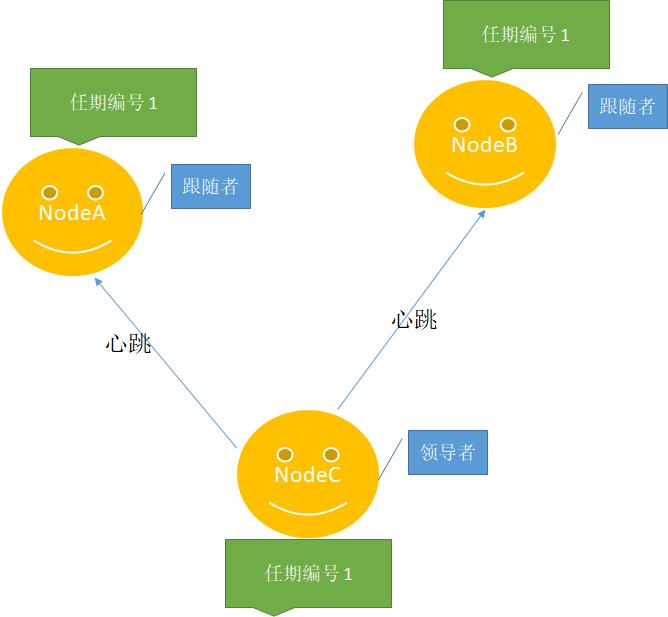
1、初始状态下,所有节点都是跟随者。每个跟随者都会携带一个任期编号和随机超时时间。如下图所示:
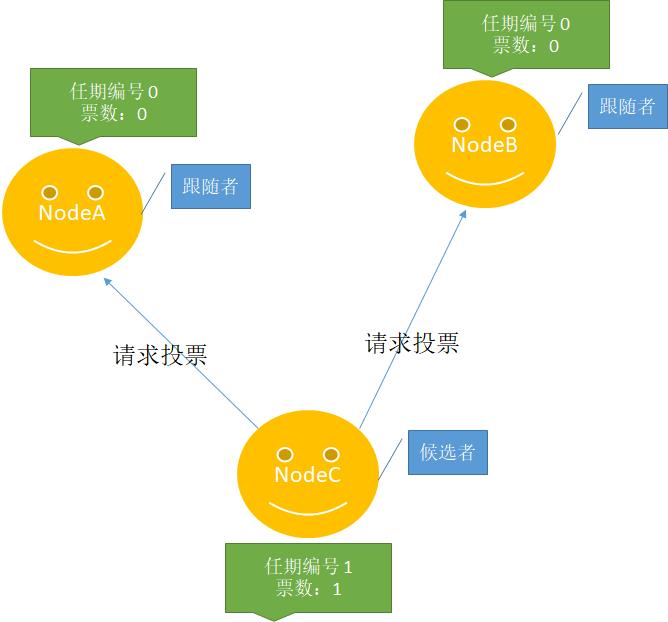
2、NodeC时间最先出现超时,那么它将推荐自己为候选人。如下图所示:
3、其它节点发现该任期编号还没有进行过投票,通过RPC方式进行调用,那么将按照一节点一票的规则进行投票,在投票过程中验证候选者的编号大于自己、验证日志的完整性并增加自己任期编号。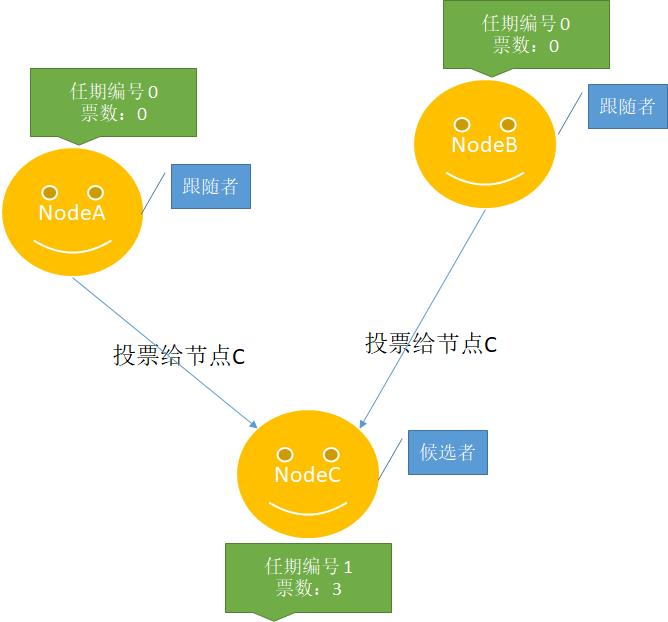
4、NodeC当选为领导者节点以后,将周期性往其它节点发送消息,告诉其它节点,一切以我为主,阻止其它节点发起选举,而其它节点如果能够在超时时间内跟领导者保持心跳,将不会发起选举。
如何保证数据的一致性?
在提到raft算法一致性这个问题时,就不得不说日志的概念,什么时日志呢?各个节点副本数据就是以日志的形式存在,客户端发送写请求到服务端,领导者接收到写请求,处理写请求的过程就是复制和提交日志项的过程。如下图所示:
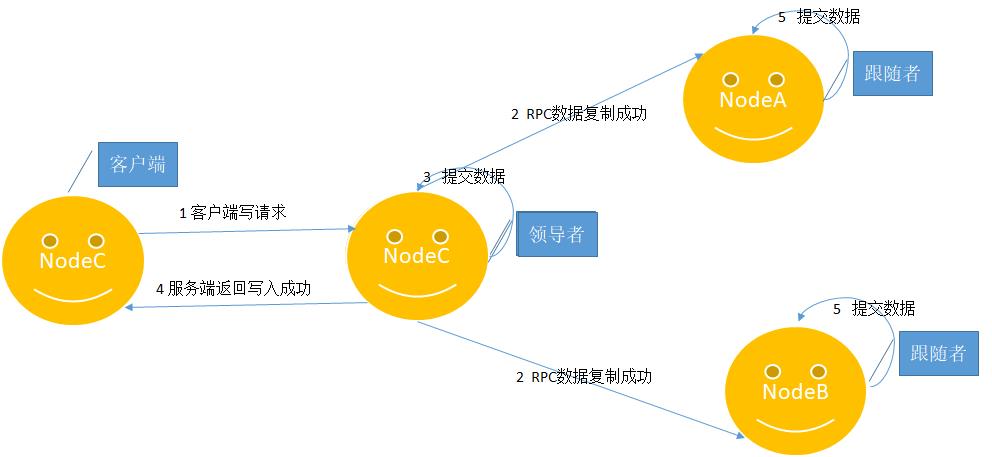
1、客户端发送数据到领导者节点,领导者节点基于客户端数据创建日志项,添加到本地日志中。
2、领导者把日志信息通过RPC复制到其它跟随者节点。
3、大多数节点复制成功后,那么领导者节点会提交数据到状态机。
4、返回给客户端。
5、其它节点接收到日志复制RPC信息,发现领导者已经提交数据,那么其它节点也会跟随提交数据。
当然看完这个过程,顺风顺水的情况下,没有什么问题,但是在分布式系统中,任何一个节点都有随时宕机的可能。举一个,最常见的例子,在上面第二步中,领导者刚好成功日志复制到其它节点,这个时候主节点恰好宕机,raft算法如何处理呢?这个时候其实可以分为领导者节点已经提交并成功返回给客户端和未提交两种情况,但是处理比较类似,都是重新选举出新的领导者节点继续进行数据提交,你可能有两个疑问。
raft算法不是要求所有节点数据都以领导者节点为准,如果领导者节点的数据不是最新的怎么办?
“首先能被选举的领导者日志一定是最新的,否则选举不能成功;另外如果跟随者比领导者日志数据多,那么也要强制跟领导者保持一致。
”
对于客户端在不知道是否提交成功的前提下,如何处理?
“可以尝试重复提交到主节点,raft算法要求各个节点实现幂等性,也就是去重机制。
”
成员节点变更问题
在没有了解成员节点变更之前,先思考一个问题,假设有两个节点同时加入三节点集群,会不会出现集群分裂问题呢?如下所示,一个稳定运行的raft集群现在需要加入两个节点。
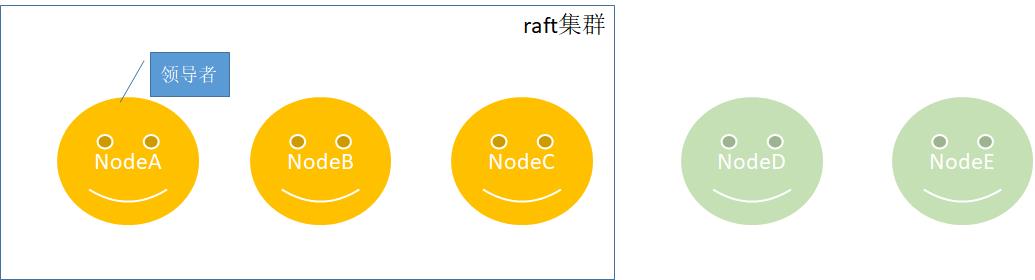 恰巧这个时候NodeC和NodeA、NodeB发生了集群分裂,因为NodeC的编号和日志索引都是最大的,顺利上位成为领导者,如下所示:
恰巧这个时候NodeC和NodeA、NodeB发生了集群分裂,因为NodeC的编号和日志索引都是最大的,顺利上位成为领导者,如下所示:
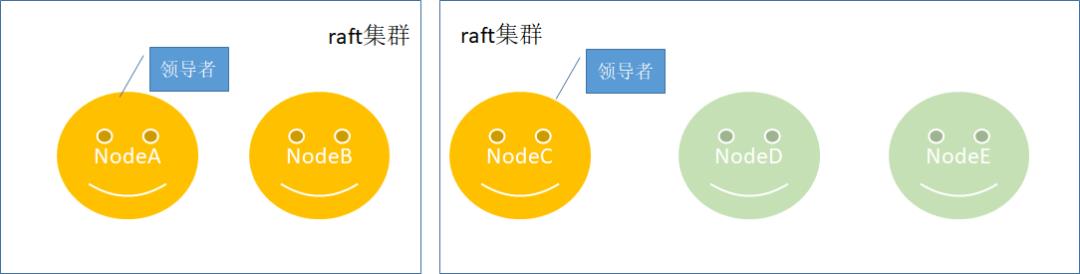 对于上述问题,很多分布式系统中都存在该问题,raft算法是如何解决的呢?
对于上述问题,很多分布式系统中都存在该问题,raft算法是如何解决的呢?
“很简单,节点一个一个按序加入集群,永远不存在两个大多数的问题。
”
具体加入方式,如下所示:
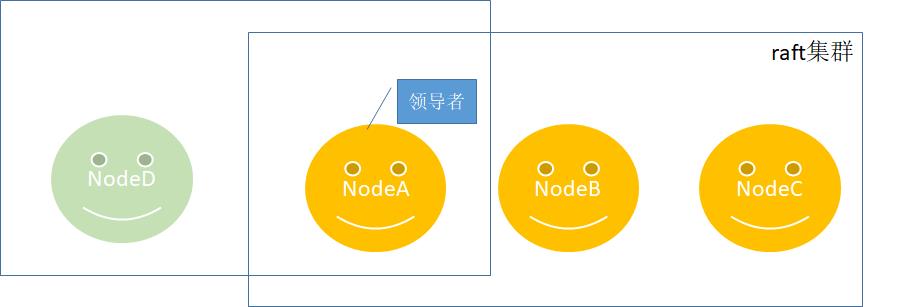 在整个加入过程中,主要步骤:首先领导者向NodeD同步数据; 同步完成后, 把NodeD的节点加入信息同步到其它跟随者节点,最后提交日志,完成变更。待本次完成变更后,下个节点按照上述步骤再次执行。
在整个加入过程中,主要步骤:首先领导者向NodeD同步数据; 同步完成后, 把NodeD的节点加入信息同步到其它跟随者节点,最后提交日志,完成变更。待本次完成变更后,下个节点按照上述步骤再次执行。
通过如上方式进行节点变更,保证了永远只有一个领导者节点,这样保证了大多数节点的数据一致性,从这里可以看出Raft并不是严格一致性算法,而是共识算法。
另外考虑另外一种极端情况,NodeA、NodeB、NodeC是一个raft集群,这时NodeA跟NodeB、NodeC之间发生了网络连接错误,即NodeA和NodeB、NodeC发生了隔离,如下所示:
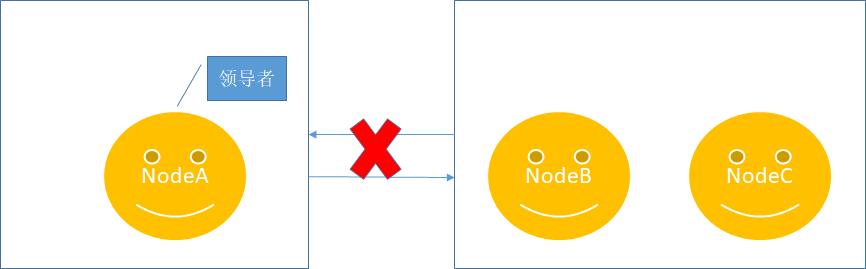
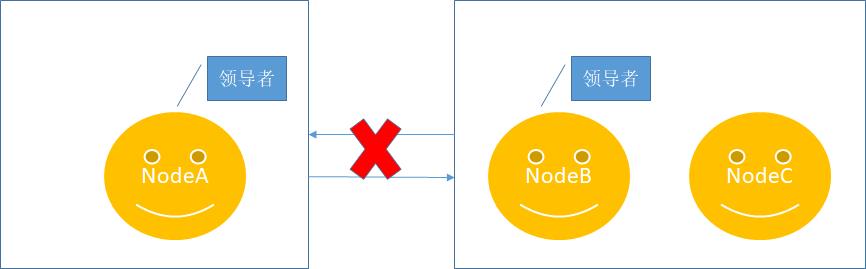
最后如果网络恢复,NodeA更新任期数据,发现集群存在任期更新,那么NodeA将降级为一个跟随者加入到raft集群,并复制领导者节点数据。
总结
推荐
原创不易,随手关注或者”三连“,诚挚感谢!
以上是关于让我们一起揭开Etcd背后Raft算法的面纱的主要内容,如果未能解决你的问题,请参考以下文章