分布式数据库HBase的架构设计详解(有彩蛋)
Posted DBAplus社群
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式数据库HBase的架构设计详解(有彩蛋)相关的知识,希望对你有一定的参考价值。
本文根据DBAplus社群第99期线上分享整理而成,文末还有好书送哦~

陈鸿威
云财经大数据CTO
曾任百度高级工程师,现主持设计开发云财经股市情报和大数据中心;
拥有丰富的在线电商、证券实时系统、金融海量数据在线计算的实战经验;致力于各类分布式和大数据开源项目研究。
主题简介:
1、传统数据库回顾
2、分布式基础理论
3、HBase特征
4、HBase底层架构
5、HBase设计要点
传统数据库回顾
近些年来,各种互联网+的公司如雨后春笋般出现,做一个在线平台或者做一个APP基本成为这些公司的标配。Web系统的流行,数据收集越来越容易,促使各类数据库系统应用得越来越广泛。
我们在平时的技术讨论或者实际应用中经常会提到传统数据库。提到传统数据库,很多人会很容易联想到Oracle、mysql、SQL Server等带有很明显关系型数据库特征的数据库系统。在我看来,传统数据库并不等于这些数据库,而是看你怎么用的。一般来说,传统数据库包括以下三个鲜明的特点:
ACID一言以蔽之就是原子性、一致性、隔离性、持久化事务,它是四个单词的缩写:
Atomicity 原子性 事务中所有操作要么全部完成,要么全失败。
Consistency 一致性 在事务开始时或者结束时,数据库应该处于同一状态。
Isolation 隔离性 事务将假定只有它自己在操作数据库,彼此不知晓。
Durablity 一旦事务完成,就不能返回。
要做到ACID,从编程的角度来说,数据库系统一定会用到锁。
一般对事务要求比较高的主要是交易场景,银行系统、大型在线电商交易系统用得比较多。对于绝大多数创业公司而言,事务是一个偏理论的概念。实际上在,在线系统中,事务是一个很有用的东西,我们举个栗子:
用户A在平台购买增值服务的场景,会有很多种处理方式。
一般的程序员会如下处理:
在财务表中增加一条用户A的扣费记录。(扣费)
在用户增值服务表中增加一条用户A的增值服务记录。(开通服务)
用户至上的程序员会如下处理:
在用户增值服务表中增加一条用户A的增值服务记录。(开通服务)
在财务表中增加一条用户A的扣费记录。(扣费)
三年以上工作经验的程序员会如下处理:
在财务表中增加一条用户A的扣费记录。(扣费)
判断财务表中是否扣费成功,不成功通知系统交易失败。
在用户增值服务表中增加一条用户A的增值服务记录。(开通服务)
判断用户增值服务表中是否增加成功,不成功删除财务表中的扣费并且通知系统交易失败。
那么用上事务之后,你只要提交给数据库一般程序员操作,数据库就会给你三年以上工作经验的程序员的操作结果,在主从架构读写分离的数据库结构中效果还会更好。
传统的数据库系统可以存很多种类型的数据,主要包括:
数字家族、整数和小数。整数又可以分为32位的,64位的…
字符串类型。字符串又分为固定长度的和可变长度的…
时间家族。日期、时间…
二进制流…
这么多类型,确实很丰富。我们所看到的,都可以是字符,就算二进制流,也可以通过Base64转码用字符串表示。当然,在讲字符串的时候,我们是把编程语言进化到了一个很高级的程度,开发的友好性大于存储成本。
对于传统数据库系统的常用操作,我们一般会说CURD。即对表的增删改查,基本都用SQL语句来实现。SQL语句的结构主要分为以下几大部分:
操作,select、insert、update、delete。
表对象。
字段范围(*/f1/f2…)。
Where条件。
Order排序(desc/asc)。
查询范围限制(top/limit)。
……
SQL语句是为使用者友好而设计的,无论何种数据库引擎,SQL最后都被映射成为IO和内存操作。
在传统数据库系统中,一般来说在第一次写入数据之前,都需要创建库和创建表,而每一个表都有确定的表头,确定列数,每一列的名字以及确定的数据类型。在新数据的写入或者数据的修改的时候,数据库系统会根据创建好的表结构严格校验数据的合法性,对表结构的调整一般都需要很大的修改代价。
在存储单元里,同一行的数据会分布在相邻的存储单元里。
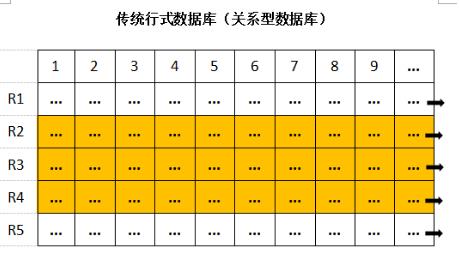
列式存储相对于行式存储而言,其同一列的数据会分布在相邻的存储单元里。
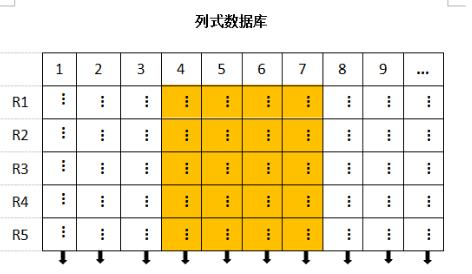
题外话:除了行存储和列存储,常见还有文档模型,典型的代表就是MongoDB。如果用传统的行的角度来看,不同的行列数可以不一样,列的名字和数据类型也可以不一样,列里面可以是另一个嵌套的行。
在互联网化的大环境下,很多系统都很容易在短时间内系统收集上亿的数据,并且这些数据经过加工,还要为几十万、几百万甚至更多用户提供访问。从平台角度来说,一般就是从小到大,从简单到复杂的过程。主要来说,具有一下三方面特点:
对数据高并发读写的要求
数据库读写压力巨大,硬盘IO无法承受。一般处理方法是主从架构,读写分离,分库、分表,缓解写压力,增强读库的可扩展性。
对海量数据的存储和访问
存储记录数量有限,SQL查询效率极低的情况下。通过分库、分表,缓解数据增长压力。
伸缩性,可用性,可靠性方面的需求
横向扩展艰难,无法通过快速增加服务器节点实现,系统升级和维护造成服务不可用。通过主从架构,增强读库的扩展性,利用MMM架构处理写的瓶颈。
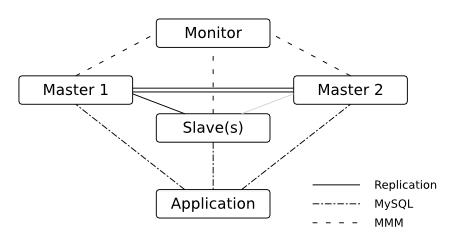
受业务规则影响,需求变动导致分库分表的维护复杂。
系统数据访问层代码需要修改。
Slave实时性的保障,对于实时性很高的场合可能需要做一些处理(在第一个购买增值服务的例子中,添加扣费记录之后,在读写分离的场景下,立马去从库查询扣费记录不一定能查到)。
高可用性问题,Master就是那个致命点,容易产生单点故障。
本身扩展性差,一次只能一个Master可以写入,只能解决有限数据量下的可用性。
分布式基础理论
1、CAP
分布式领域CAP理论
Consistency 一致性:数据一致更新,所有数据变动都是同步的。
Availability(可用性):好的响应性能。
Partition tolerance:分区容忍性。
在分布式系统中,这三个要素最多只能同时实现两点,不可能三者兼顾;对于分布式数据系统,分区容忍性是基本要求;对于大多数Web应用,牺牲一致性而换取高可用性,是目前多数分布式数据库产品的方向。
Basically Available:基本可用 支持分区失败。
Soft state 软状态:状态可以有一段时间不同步,异步。
Eventually consistent:最终一致性 ,最终数据是一致的就可以了,而不是时时一致。
Google的BigTable
BigTable提出了一种很有趣的数据模型,它将各列数据进行排序存储。数据值按范围分布在多台机器,数据更新操作有严格的一致性保证。
Amazon的Dynamo
Dynamo使用的是另外一种分布式模型。Dynamo的模型更简单,它将数据按key进行hash存储。其数据分片模型有比较强的容灾性,因此它实现的是相对松散的弱一致性:最终一致性。
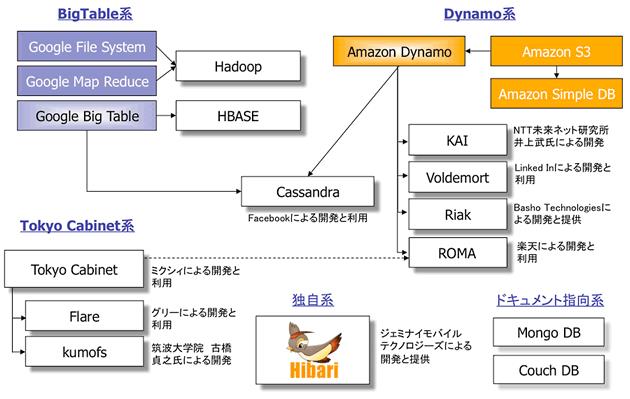
HBase特征
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用ZooKeeper作为对应。
主要特点
列的可以动态增加,并且列为空就不存储数据,节省存储空间。
HBase自动切分数据,使得数据存储自动具有水平scalability。
HBase可以提供高并发读写操作的支持,分布式架构,读写锁等待的概率大大降低。
不能支持条件查询,只支持按照Rowkey来查询。
暂时不能支持Master server的故障切换,当Master宕机后,整个存储系统就会挂掉。
HBase底层架构
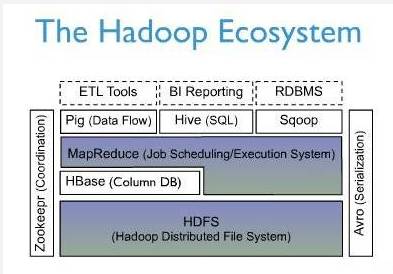
HBase是一个列式存储的数据库系统,跟所有的数据库系统一样,数据库是依赖文件系统的,在传统数据库里面我们经常提到存储引擎,例如MySQL有MyISAM/InnoDB,Oracle/SqlServer不开源,没有那么多选择,但都会有自己的存储引擎,说得通俗一点就是虚拟文件系统,HBase的文件系统是HDFS,一种分布式文件系统,所以HBase天然具备分布式的特性。同时Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。
HBase设计要点
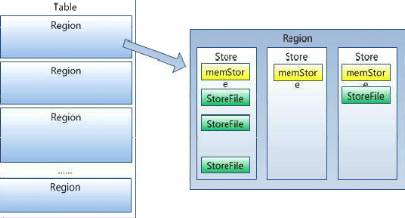
1、逻辑数据模型
Table
Region
ColumnFamily
Row
Column
Value
TimeStamp
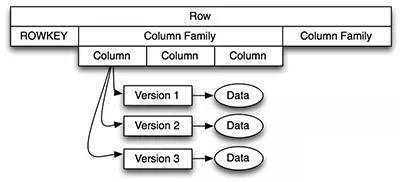
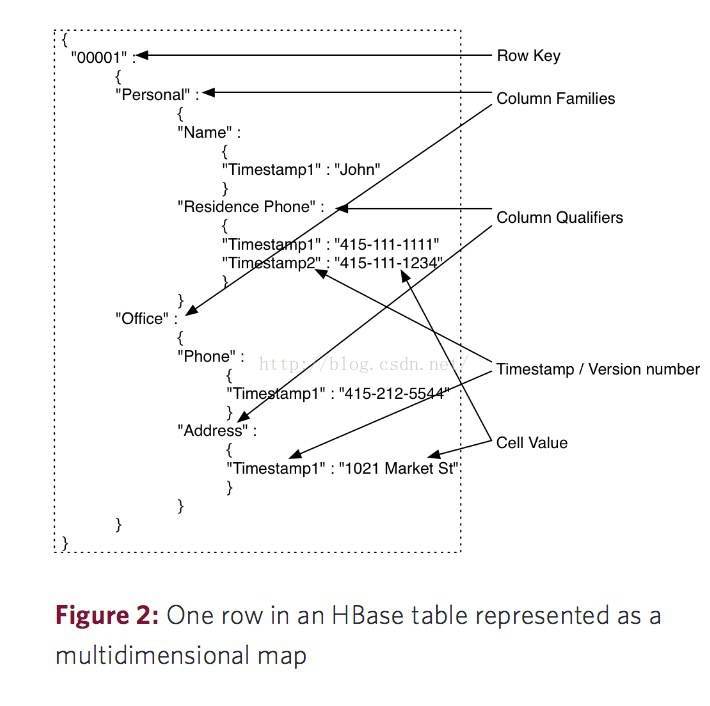
你也可以把HBase看成一个多维度的Map模型去理解它的数据模型。正如下图。
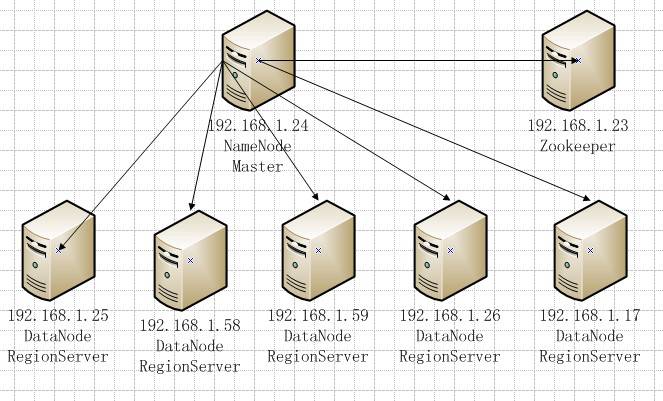
NameNode存储DataNode信息,ZooKeeper负责调度。
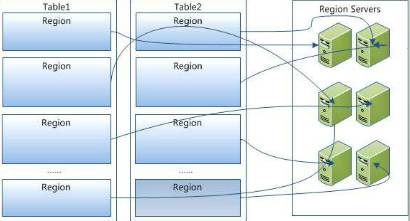
一个Region只会存在一台RegionServer上,一台RegionServer上可以包含多个Region。
一个逻辑的表包含多个Region,分布在各个RegionServer上,对应用程序来说只有一个大表不用管分表分库。
Region的定位
-ROOT-
.META
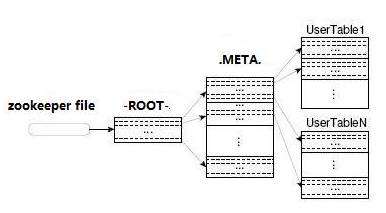
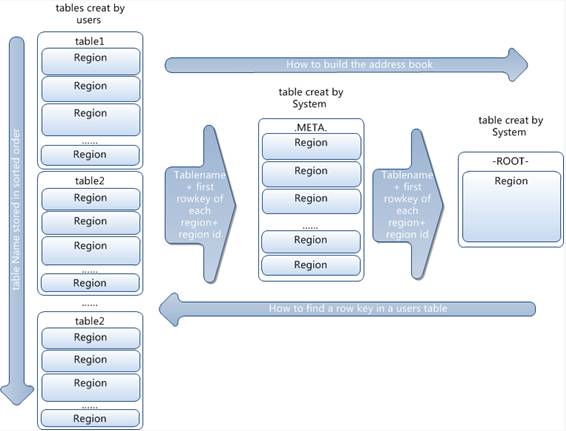
存储分布
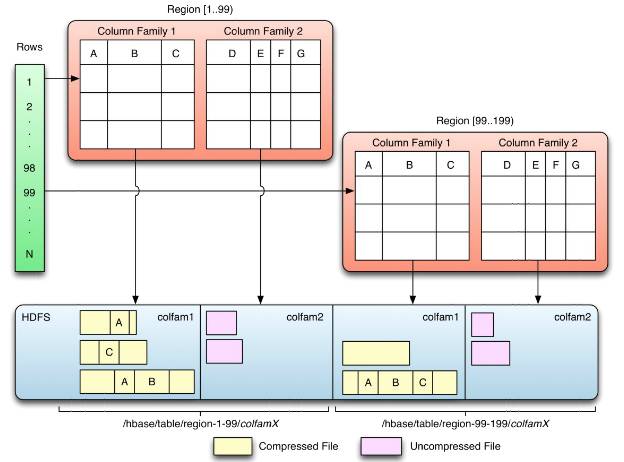
每一行包含N个列,以列的形式分布在不同Region里面。
Client
HBase的访问接口,维护cache加快HBase的访问。
Zookeeper
监控Master,保证只有一个Master;
监控RegionServer上下线,并告知Master;
存储Hbase shcema和Table的元数据。
Master
分配Region到RegionServer;
RegionSever的负载均衡;
发现失效的RegionServer并重新分配其上的Region
管理用户对Table的增删改查操作。
RegionServer
维护Region,处理对这些Region的IO;
Split&Compact。
HBase是三维有序存储的,通过RowKey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度可以对HBase中的数据进行快速定位。
RowKey是HBase表结构设计中很重要的一环 ,HBase中RowKey可以唯一标识一行记录,在HBase查询的时候,有以下2种方式:
按指定RowKey获取唯一一条记录,get方法
(org.apache.hadoop.hbase.client.Get)
按指定的条件获取一批记录,scan方法
(org.apache.hadoop.hbase.client.Scan)
第一种类似key-value查找,第二种可以实现简单的条件查询功能。
Q1:HBase是不是没有传统表的概念了。感觉都像是键值存储。
A1:如果存储角度看是涵盖了的,但是去掉了关系。
Q2:HBase 与MongoDB的使用场景的区别老师能否简单介绍一下?
A2:HBase适合做数据分析,MongoDB在线服务性能很好,尤其是读,HBase要结合MapReduce,还有就是MongoDB适合Web服务,例如php。
回听直播请戳:
https://m.qlchat.com/topic/240000397746115.htm
密码:222
好书相送
在本文微信订阅号(dbaplus)评论区留下足以引起共鸣的真知灼见,并在本文发布后32小时之内成为点赞数最多的一名,可获得以下书籍一本~
特别鸣谢清华大学出版社提供图书赞助。
◆ MVP专栏 ◆
丨丨丨丨
丨丨丨丨
◆ 近期活动 ◆
云数据库架构设计与实践沙龙火热报名中
以上是关于分布式数据库HBase的架构设计详解(有彩蛋)的主要内容,如果未能解决你的问题,请参考以下文章