图文详解HBase 的数据模型与架构原理详解
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文详解HBase 的数据模型与架构原理详解相关的知识,希望对你有一定的参考价值。
HBase 简介

https://hbase.apache.org/
HBase, Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、 实时读写的分布式开源 NoSQL 数据库,面向列存储。主要用来存储非结构化和半结构化的松散数据。
HBase 的设计思想,来源于 Fay Chang所撰写的Google论文 “Bigtable:一个结构化数据的分布式存储系统”。HBase 使用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据。HBase 在 Hadoop 和 HDFS 之上提供类似 Bigtable 的功能。
HBase is a distributed, column oriented open source database. This technology comes from the Google paper “BigTable: a distributed storage system of structured data” written by Fay Chang. Just as BigTable makes use of the distributed data storage provided by Google file system, HBase provides capabilities similar to BigTable on Hadoop. HBase is a subproject of Apache’s Hadoop project. HBase is different from the general relational database. It is a database suitable for unstructured data storage. Another difference is that HBase is column based rather than row based.
HBase 特性
HBase 是一种“NoSQL”数据库。 “NoSQL”是一个通用术语,意思是数据库不是支持 SQL 作为其主要访问语言的 RDBMS,但是 NoSQL 数据库的类型很多:BerkeleyDB 是本地 NoSQL 数据库的一个例子,其中 HBase 非常分布式数据库。
HBase is a type of "NoSQL" database. "NoSQL" is a general term meaning that the database isn’t an RDBMS which supports SQL as its primary access language, but there are many types of NoSQL databases: BerkeleyDB is an example of a local NoSQL database, where as HBase is very much a distributed database.
从技术上讲,HBase 更像是一个“数据存储”而不是“数据库”,因为它缺少您在 RDBMS 中可以找到的许多功能,例如类型化列、二级索引、触发器和高级查询语言等。
Technically speaking, HBase is really more a "Data Store" than "Data Base" because it lacks many of the features you find in an RDBMS, such as typed columns, secondary indexes, triggers, and advanced query languages, etc.
然而,HBase 有许多特性,支持线性和模块化扩展。 HBase 集群通过添加托管在商品类服务器上的 RegionServer 进行扩展。例如,如果一个集群从 10 台 RegionServers 扩展到 20 台,它的存储和处理能力都会增加一倍。 RDBMS 可以很好地扩展,但只能达到一个点——特别是单个数据库服务器的大小——并且为了获得最佳性能,需要专门的硬件和存储设备。值得注意的 HBase 特性是:
1.强一致性读/写:HBase 不是“最终一致性”数据存储。 这使得它非常适合于诸如高速计数器聚合之类的任务。
2.自动分片:HBase 表通过区域分布在集群上,区域会随着数据的增长自动拆分和重新分布。
3.自动 RegionServer 故障转移
4.Hadoop/HDFS 集成:HBase 支持开箱即用的 HDFS 作为其分布式文件系统。
5.MapReduce:HBase 支持通过 MapReduce 进行大规模并行处理,将 HBase 用作源和接收器。
6.Java 客户端 API:HBase 支持易于使用的 Java API 进行编程访问。
7.Thrift/REST API:HBase 还支持非 Java 前端的 Thrift 和 REST。
8.块缓存和布隆过滤器:HBase 支持用于大容量查询优化的块缓存和布隆过滤器。
9.运维管理:HBase 为运维洞察和 JMX 指标提供内置网页。
However, HBase has many features which supports both linear and modular scaling. HBase clusters expand by adding RegionServers that are hosted on commodity class servers. If a cluster expands from 10 to 20 RegionServers, for example, it doubles both in terms of storage and as well as processing capacity. An RDBMS can scale well, but only up to a point - specifically, the size of a single database server - and for the best performance requires specialized hardware and storage devices. HBase features of note are:
1.Strongly consistent reads/writes: HBase is not an "eventually consistent" DataStore. This makes it very suitable for tasks such as high-speed counter aggregation.
2.Automatic sharding: HBase tables are distributed on the cluster via regions, and regions are automatically split and re-distributed as your data grows.
3.Automatic RegionServer failover
4.Hadoop/HDFS Integration: HBase supports HDFS out of the box as its distributed file system.
5.MapReduce: HBase supports massively parallelized processing via MapReduce for using HBase as both source and sink.
6.Java Client API: HBase supports an easy to use Java API for programmatic access.
7.Thrift/REST API: HBase also supports Thrift and REST for non-Java front-ends.
8.Block Cache and Bloom Filters: HBase supports a Block Cache and Bloom Filters for high volume query optimization.
9.Operational Management: HBase provides build-in web-pages for operational insight as well as JMX metrics.
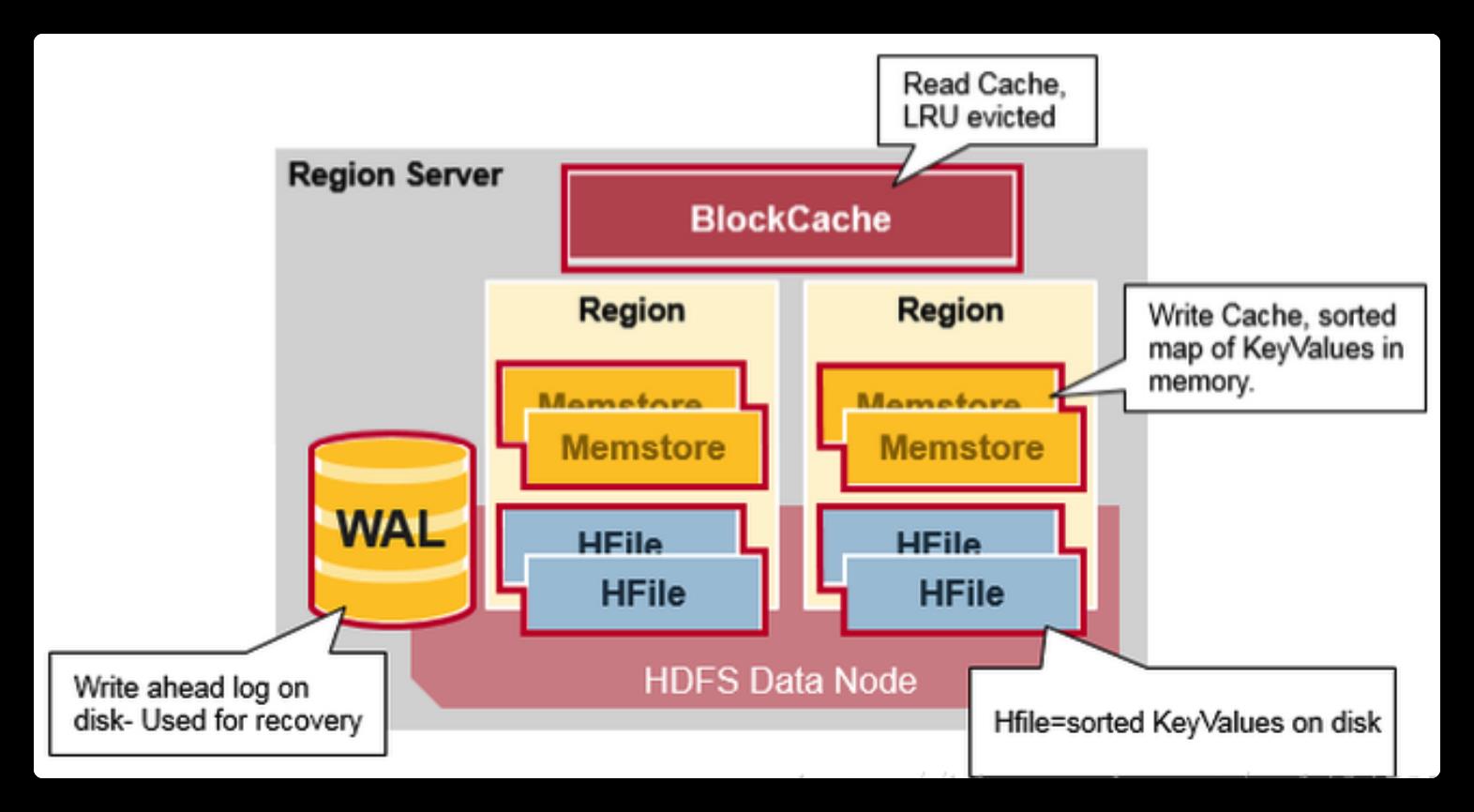
HBase 在整个Hadoop生态圈中如下:
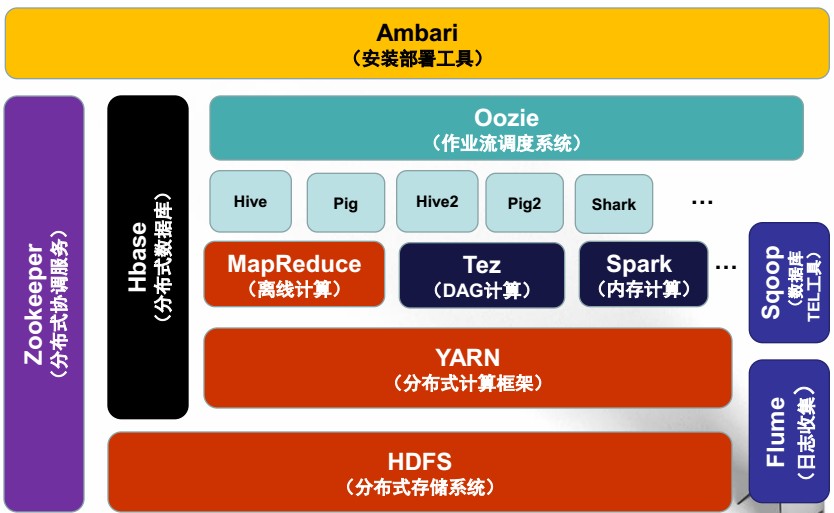
hadoop所有应用都是构建于hdfs(它提供高可靠的底层存储支持,几乎已经成为分布式文件存储系统事实上的工业标准)之上的分布式列存储系统,主要用于海量结构化数据存储。通过Hadoop生态圈,可以看到HBase的身影,可见HBase在Hadoop的生态圈是扮演这一个重要的角色,那就是: 实时、分布式、高维数据 的数据存储;

BigTable 简介
Bigtable是一个分布式存储系统,为了解决Google的结构化数据的管理问题。可扩展,数据量级在PB级,集群机器台数达数千台。Bigtable实现了几个目标:广泛应用、可扩展、高性能和高可用。
BigTable 使用一个类似B+树的数据结构存储片的位置信息。
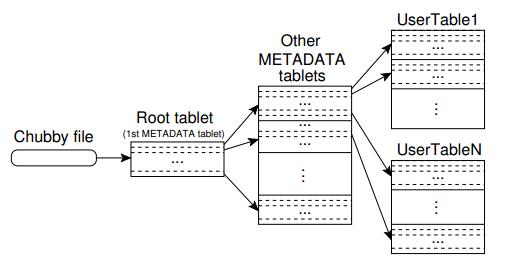
第一层,Chubby file。这一层是一个Chubby文件,它保存着root tablet的位置。这个Chubby文件属于Chubby服务的一部分,一旦Chubby不可用,就意味着丢失了root tablet的位置,整个Bigtable也就不可用了。
第二层,root tablet。root tablet其实是元数据表(METADATA table)的第一个分片,它保存着元数据表其它片的位置。root tablet很特别,为了保证树的深度不变,root tablet从不分裂。
第三层,其他元数据片,它们和root tablet一起组成完整的元数据表。每个元数据片都包含了许多用户片的位置信息。
可以看出整个定位系统其实只是两部分,一个Chubby文件,一个元数据表。
注意元数据表虽然特殊,但也仍然服从前文的数据模型,每个分片也都是由专门的片服务器负责,这就是不需要主服务器提供位置信息的原因。
客户端会缓存片的位置信息,如果在缓存里找不到一个片的位置信息,就需要查找这个三层结构了,包括访问一次Chubby服务,访问两次片服务器。
关于BigTable的详细内容,将会在另外一篇文章中单独讲。
分布式 HBase
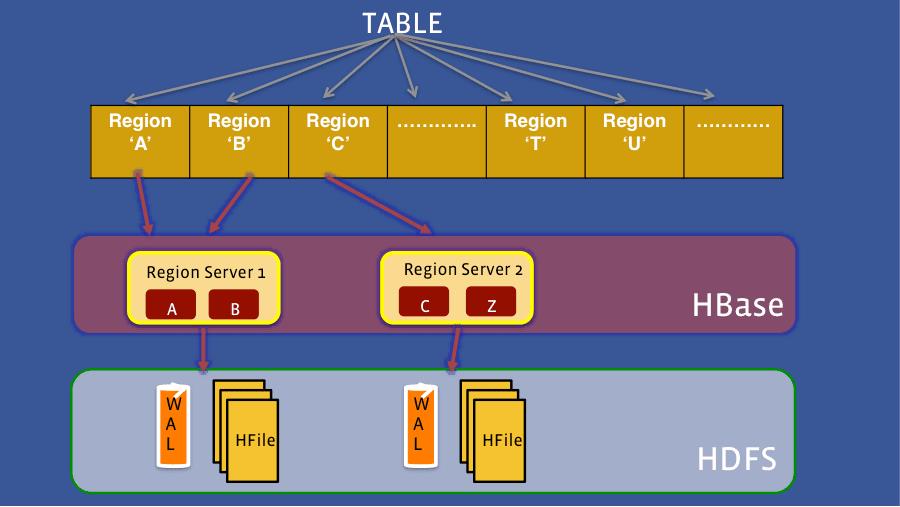
https://www.scaleyourapp.com/what-database-does-facebook-use-a-1000-feet-deep-dive/
HBase使用Zookeeper作为其分布式协同服务。
Zookeeper 为 HBase 集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover(故障转移),或对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。ZooKeeper集群本身使用一致性协议(PAXOS协议)保证每个节点状态的一致性。
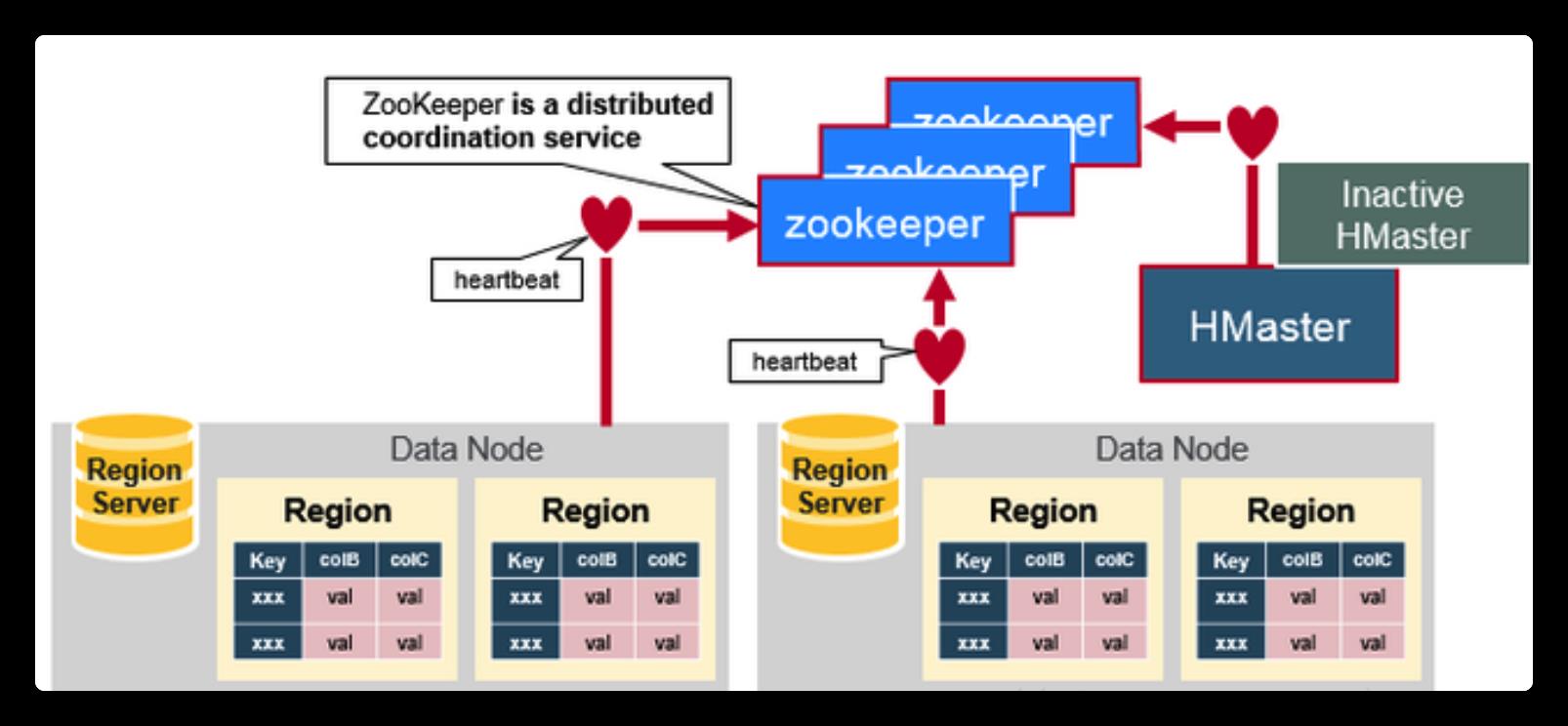
Tables are automatically partitioned horizontally by HBase into regions. Each region comprises a subset of a table’s rows, usually a range of sorted row keys.
Initially, a table comprises a single region, but as the region grows it eventually crosses a configurable size threshold, at which point it splits at a row boundary into two new regions of approximately equal size. Until this first split happens, all loading will be against the single server hosting the original region.
Regions are the units that get distributed over an HBase cluster.
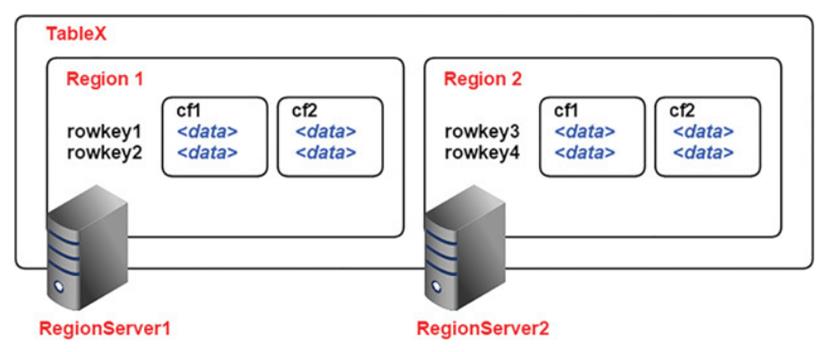
https://jheck.gitbook.io/hadoop/data-storage
HBase适用场景
1.并发、简单、随机查询。
(注:HBase不太擅长复杂join查询,但可以通过二级索引即全局索引的方式来优化性能)
2.半结构化、非结构化数据存储。
一般我们从数仓中离线统计分析海量数据,将得到的结果插入HBase中用于实时查询。
HBase 数据模型 (HBase Data Model)
Here we have a table that consists of cells organized by row keys and column families. Sometimes, a column family (CF) has a number of column qualifiers to help better organize data within a CF.
A cell contains a value and a timestamp. And a column is a collection of cells under a common column qualifier and a common CF.
Within a table, data is partitioned by 1-column row key in lexicographical order, where topically related data is stored close together to maximize performance. The design of the row key is crucial and has to be thoroughly thought through in the algorithm written by the developer to ensure efficient data lookups.
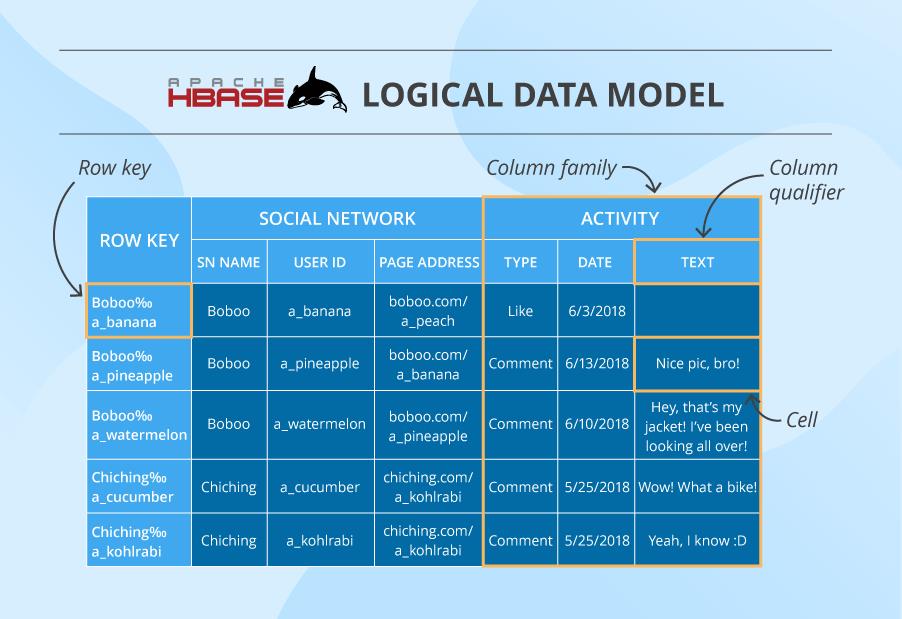
https://www.scnsoft.com/blog/cassandra-vs-hbase
HBase Data Model Introduction
HBase stores data in the form of tables. A table consists of rows and columns.
The column is divided into several column families, as shown in the following figure.
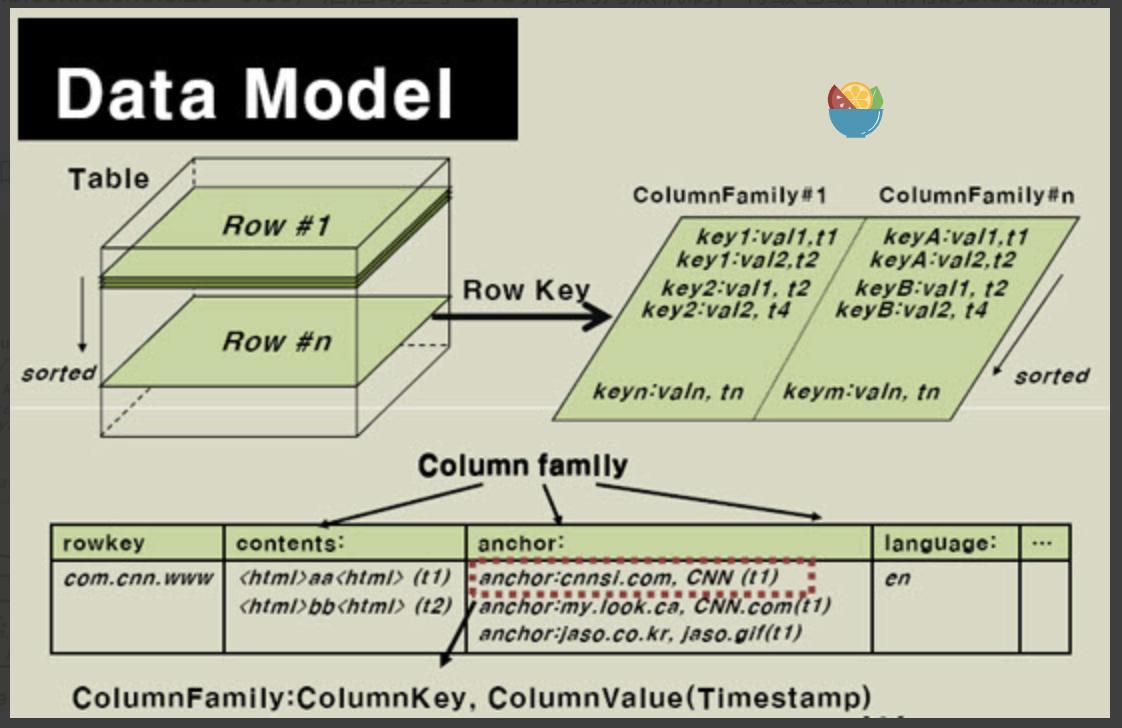
1.Table:
HBase will organize data into tables, but it should be noted that the table name must be a legal name that can be used in the file path, because the table of HBase is mapped to the file above HDFS.
2.Row:
in the table, each row represents a data object. Each row is uniquely identified by a row key. The row key has no specific data type and is stored in binary bytes.
3.Column family:
when defining the HBase table, you need to set the column cluster in advance. All columns in the table need to be organized in the column cluster. Once the column cluster is determined, it cannot be easily modified because it will affect the real physical storage structure of HBase. However, the column qualifier and its corresponding values in the column cluster can be dynamically added or deleted. Each row in the table has the same column cluster, but it is not necessary to have consistent column qualifier and value in the column cluster of each row, so it is a sparse table structure.
4.Column qualifier:
the data in the column cluster is mapped through the column identifier. In fact, the concept of “column” can not be rigidly adhered to here, but can also be understood as a key value pair. Column qualifier is the key. The column ID also has no specific data type and is stored in binary bytes.
5.Cell:
each row key, column cluster and column ID form a cell. The data stored in the cell is called cell data. Cell and cell data have no specific data type and are stored in binary bytes.
6.Timestamp:
by default, the data in each cell is inserted with a timestamp to identify the version. When reading cell data, if the timestamp is not specified, the latest data will be returned by default. When writing new cell data, if no timestamp is set, the current time is used by default. The version number of cell data of each column cluster is maintained separately by HBase. By default, HBase retains three versions of data.
https://developpaper.com/hbase-learning-1-basic-introduction/
HBase table
The HBase table is shown in the following figure:
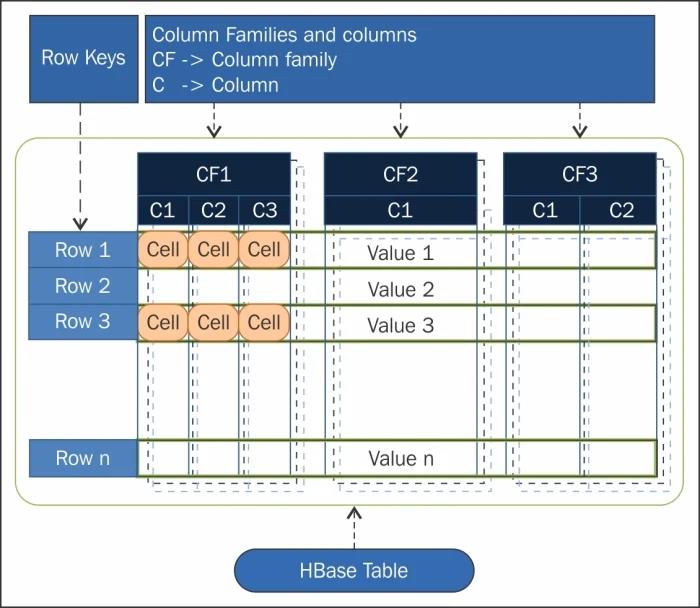
HBase is not a relational database and requires a different approach to modeling your data. HBase actually defines a four-dimensional data model and the following four coordinates define each cell (see Figure.):
1.Row Key: Each row has a unique row key; the row key does not have a data type and is treated internally as a byte array.
2.Column Family: Data inside a row is organized into column families; each row has the same set of column families, but across rows, the same column families do not need the same column qualifiers. Under-the-hood, HBase stores column families in their own data files, so they need to be defined upfront, and changes to column families are difficult to make.
3.Column Qualifier: Column families define actual columns, which are called column qualifiers. You can think of column qualifiers as the columns themselves.
4.Version: Each column can have a configurable number of versions, and you can access the data for a specific version of a column qualifier.
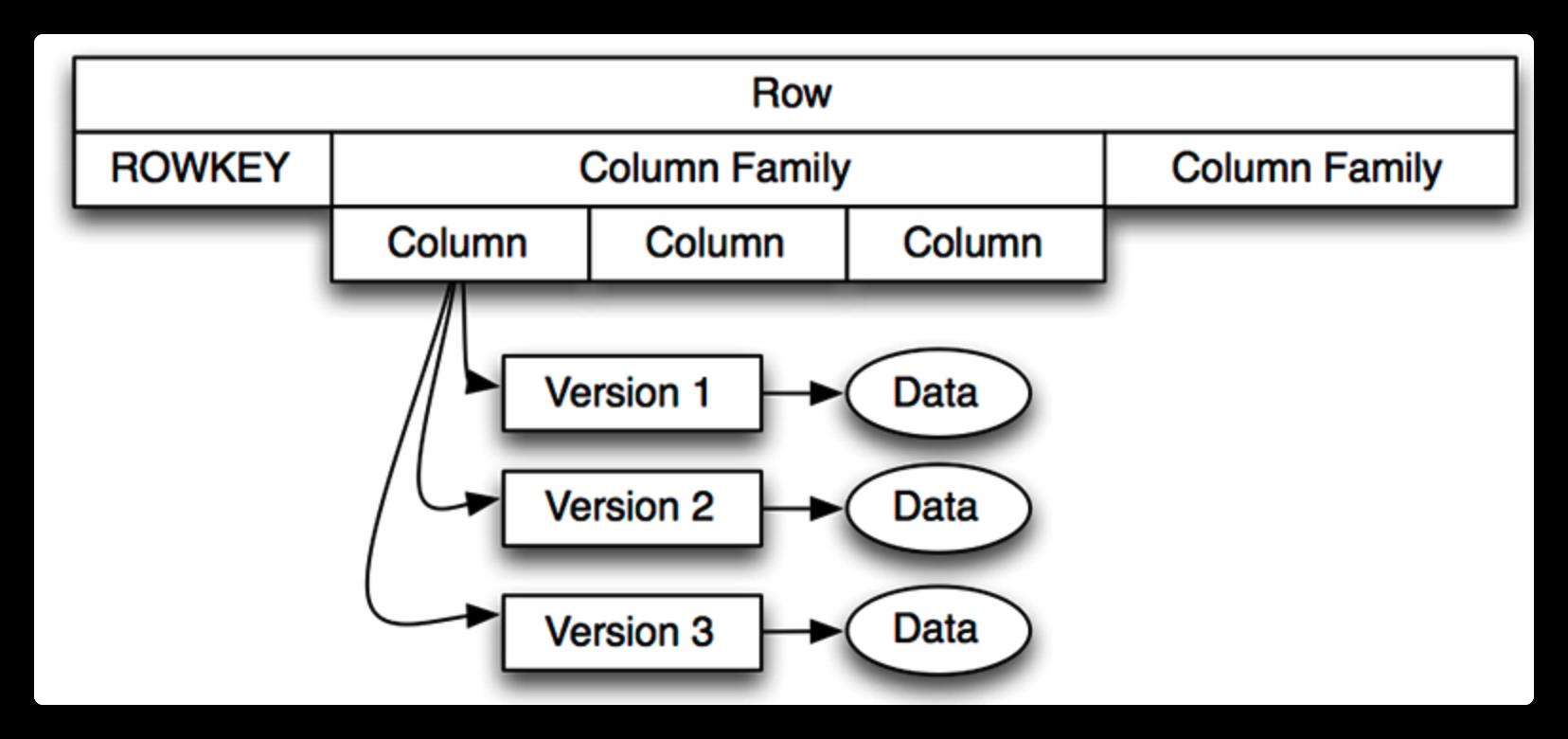
HBase as a Key/Value Store: the key is the row key we have been talking about, and the value is the collection of column families (that have their associated columns that have versions of the data).

示例
以一个公司员工表为案例来讲解,此表中包含员工基本信息(员工姓名、年龄),员工详细信息(工资、角色),以及时间戳。
1. ImployeeBasicInfoCLF ,员工基本信息列族:姓名、年龄。
2. DetailInfoCLF ,详细信息列族:薪水、角色。
整体表结构如下:
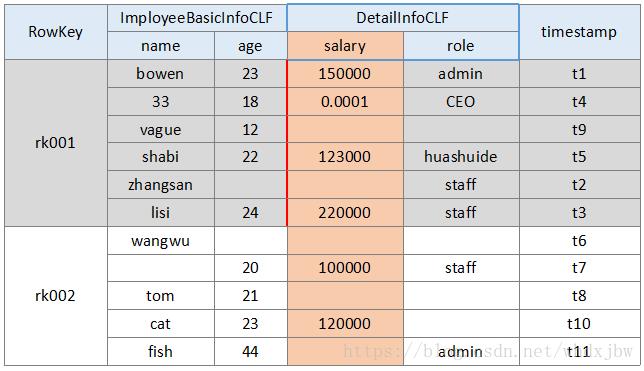
如上,每一行有一个RowKey用于唯一地标识和定位行,各行数据按RowKey的字典序排列,列族下又有多个具体列。
Row Key:
决定一行数据的唯一标识
RowKey是按照字典顺序排序的。
Row key最多只能存储64k的字节数据。
Column Family列族(CF1、CF2、CF3) & qualifier列:
HBase表中的每个列都归属于某个列族,列族必须作为表模式(schema) 定义的一部分预先给出。如create ‘test’, ‘course’;
列名以列族作为前缀,每个“列族”都可以有多个列成员(column,每个列族中可以存放几千~上千万个列);如 CF1:q1, CF2:qw,新的列族成员(列)可以随后按需、动态加入,Family下面可以有多个Qualifier,所以可以简单的理解为,HBase中的列是二级列,也就是说Family是第一级列,Qualifier是第二级列。两个是父子关系。
权限控制、存储以及调优都是在列族层面进行的;
HBase把同一列族里面的数据存储在同一目录下,由几个文件保存。
目前为止HBase的列族能能够很好处理最多不超过3个列族。
Timestamp时间戳:
在HBase每个cell存储单元对同一份数据有多个版本,根据唯一的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,最新的数据版本排在最前面。
时间戳的类型是64位整型。
时间戳可以由HBase(在数据写入时自动)赋值,此时时间戳是精确到毫 秒的当前系统时间。
时间戳也可以由客户显式赋值,如果应用程序要避免数据版本冲突, 就必须自己生成具有唯一性的时间戳。
Cell单元格:
由行和列的坐标交叉决定;
单元格是有版本的(由时间戳来作为版本);
单元格的内容是未解析的字节数组(Byte[]),cell中的数据是没有类型的,全部是字节码形式存贮。由
row key,column(=<family> +<qualifier>),version
唯一确定的单元。
HBase 数据模型术语说明
HBase 的数据模型是分布式的、多维的、持久的,并且是一个按列键、行键和时间戳索引的排序放大器,这也是 Apache HBase 也被称为键值存储系统的原因。
以下是 Apache HBase 中使用的数据模型术语。
1. 表
Apache HBase 将数据组织成表,表由字符组成,易于与文件系统一起使用。
2. 行
Apache HBase 基于行存储其数据,每一行都有其唯一的行键。行键表示为字节数组。
3. 列族
列族用于存储行,它还提供了在 Apache HBase 中存储数据的结构。它由字符和字符串组成,可以与文件系统路径一起使用。表中的每一行都将具有相同的列族,但一行不需要存储在其所有列族中。
4. 列限定符
列限定符用于指向存储在列族中的数据。它始终表示为一个字节。
5. Cell
单元格是列族、行键、列限定符的组合,一般称为单元格的值。
6. 时间戳
存储在单元中的值是版本化的,每个版本都由在创建期间分配的版本号标识。如果我们在写入数据时不提及时间戳,则考虑当前时间。
Apache HBase 中的示例表应如下所示。
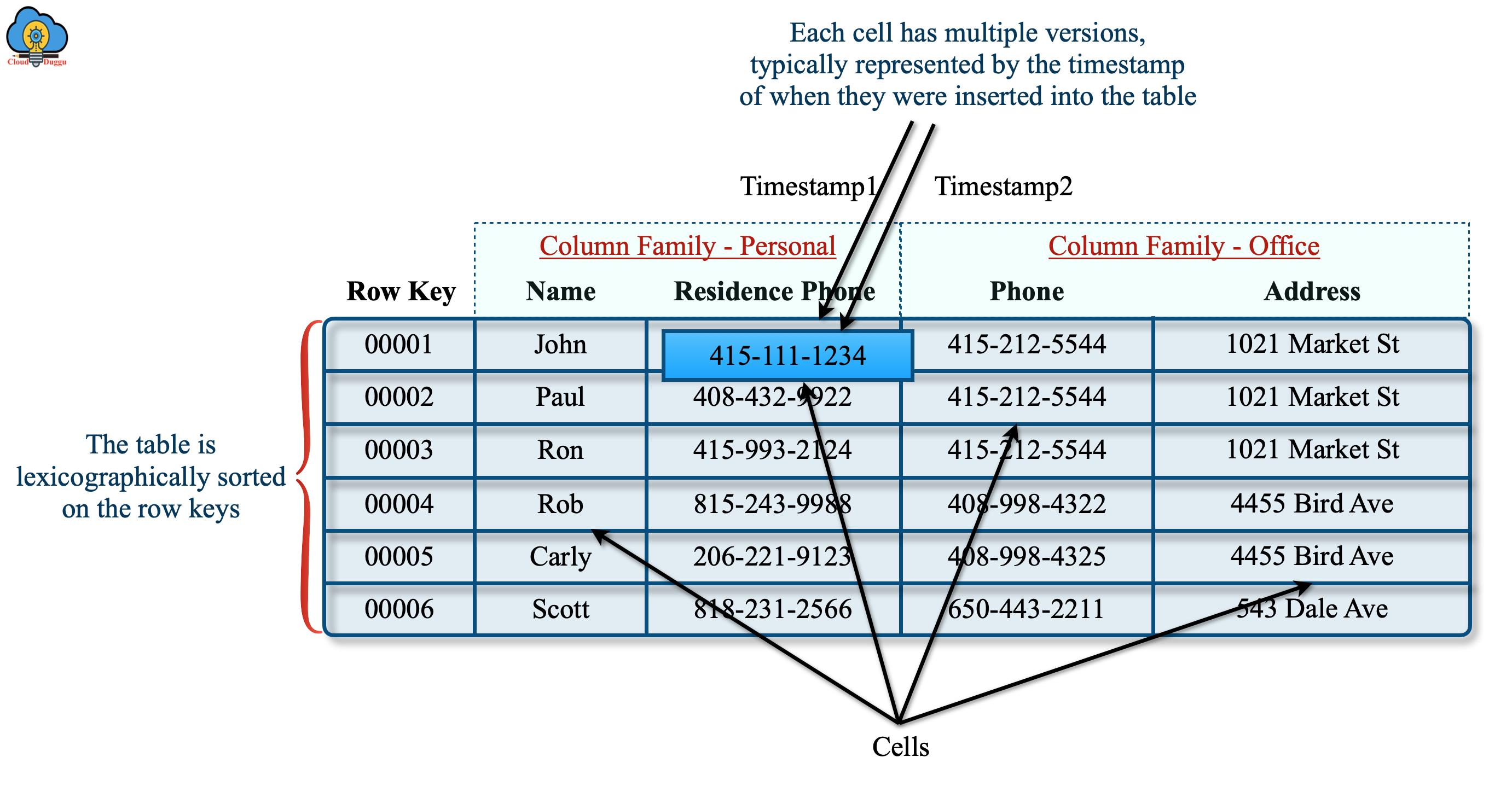
上表有两个列族,分别命名为 Personal 和 Office。两个列族都有两列。数据存储在单元格中,行按行键排序。
The following are the Data model terminology used in Apache HBase.
1. Table
Apache HBase organizes data into tables which are composed of character and easy to use with the file system.
2. Row
Apache HBase stores its data based on rows and each row has its unique row key. The row key is represented as a byte array.
3. Column Family
The column families are used to store the rows and it also provides the structure to store data in Apache HBase. It is composed of characters and strings and can be used with a file system path. Each row in the table will have the same columns family but a row doesn't need to be stored in all of its column family.
4. Column Qualifier
A column qualifier is used to point to the data that is stored in a column family. It is always represented as a byte.
5. Cell
The cell is the combination of the column family, row key, column qualifier, and generally, it is called a cell's value.
6. Timestamp
The value which is stored in the cell are versioned and each version is identified by a version number that is assigned during creation time. In case if we don't mention timestamp while writing data then the current time is considered.
HBase 数据类型
在 Apache HBase 中,没有这样的数据类型概念。都是字节数组。它是一种字节输入和字节输出数据库,其中,当插入一个值时,使用 Put 和 Result 接口将其转换为字节数组。Apache HBase 使用序列化框架将用户数据转换为字节数组。
我们可以在 Apache HBase 单元中存储最多 10 到 15 MB 的值。如果该值更高,我们可以将其存储在 Hadoop HDFS 中,并将文件路径元数据信息存储在 Apache HBase 中。
HBase 数据存储
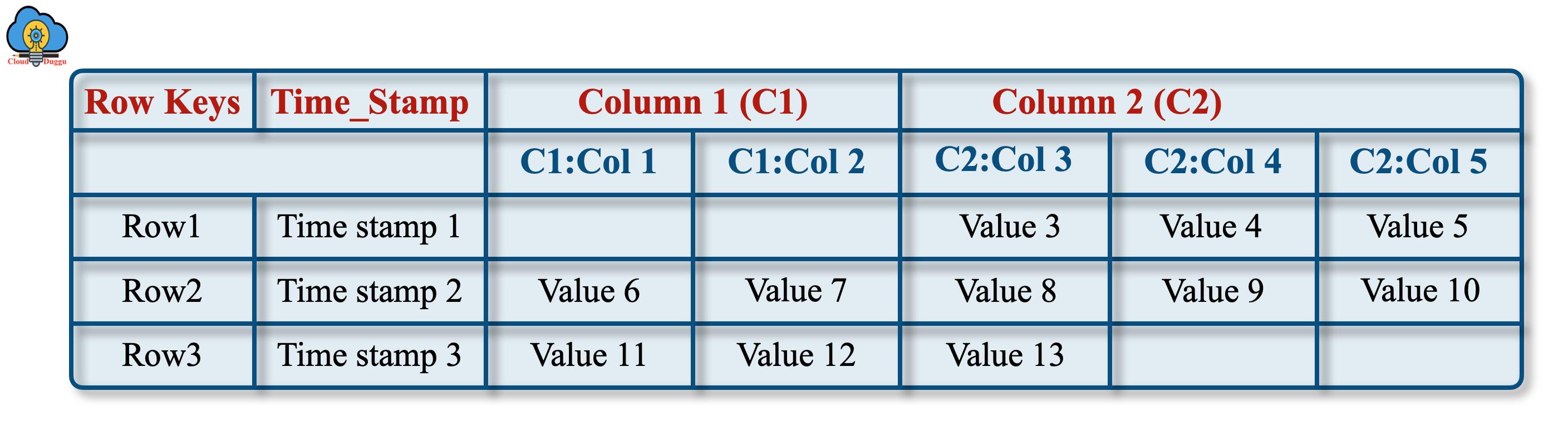
以下是 Apache HBase 的概念和物理视图。
1. 概念视图
我们可以看到一个表在概念层面被视为一组行。
以下是HBase中数据如何存储的概念图
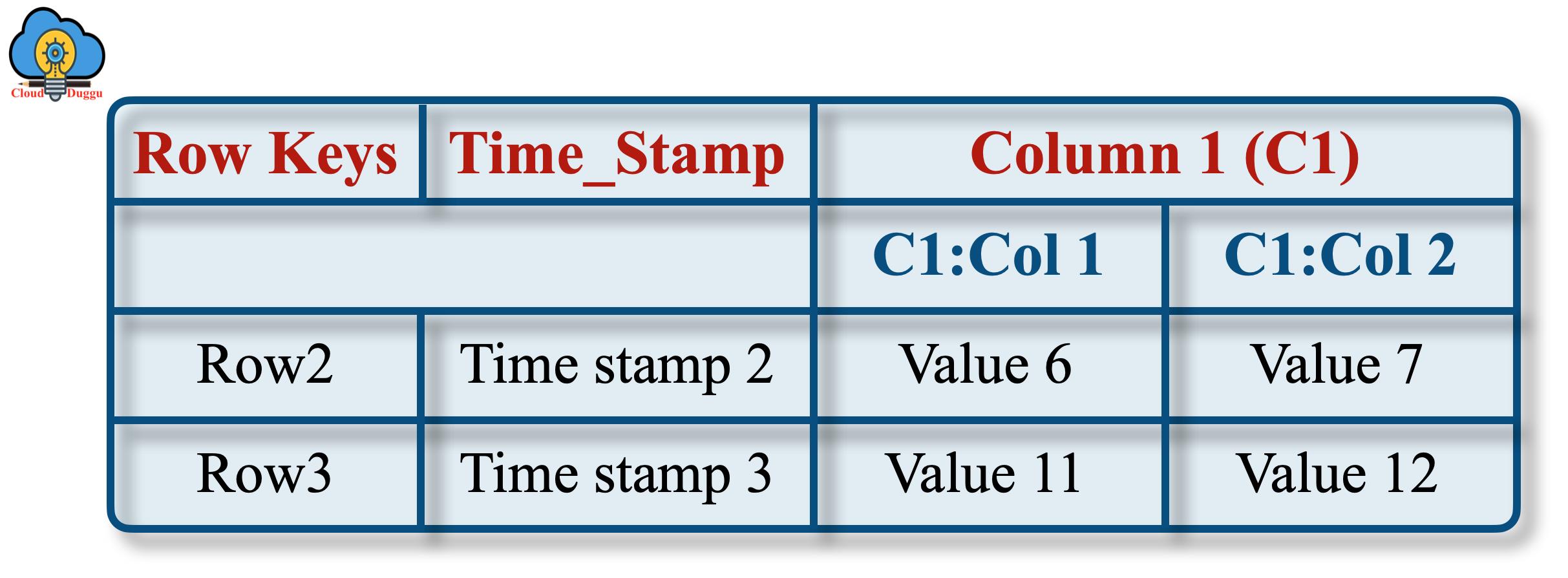
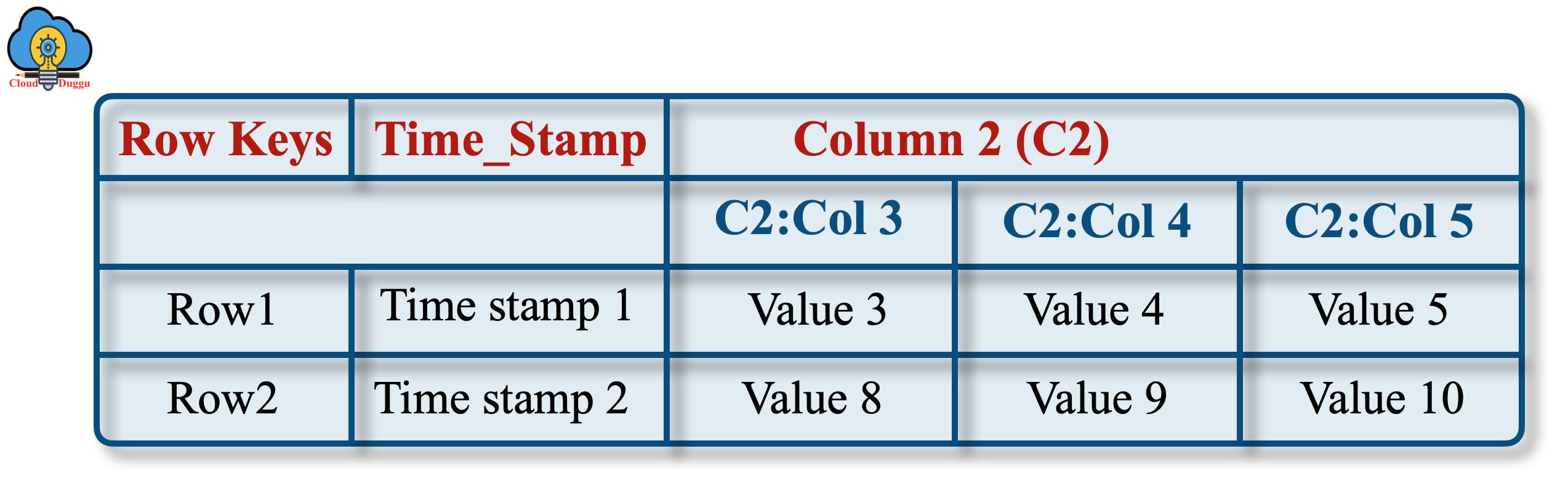
2. 实物视图
物理视图表由列族物理存储。
以下示例表示将存储为基于列族的表的表。
命名空间
命名空间是表的逻辑分组。它类似于组相关表中的关系数据库。
让我们看看命名空间的表示。
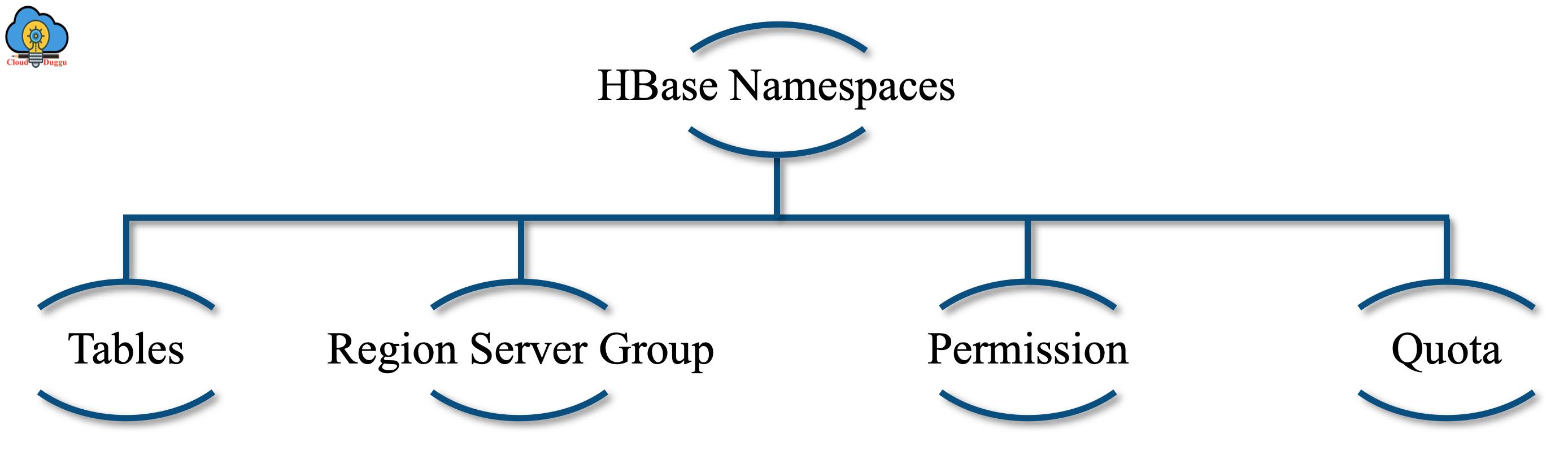
现在让我们看看命名空间的每个组件。
1. 表
所有表都是命名空间的一部分。如果没有定义命名空间,那么该表将被分配到默认命名空间。
2. RegionServer 组
命名空间可以有一个默认的 RegionServer 组。在这种情况下,创建的表将成为 RegionServer 的成员。
3. 许可
使用命名空间,用户可以定义访问控制列表,例如读取、删除和更新权限,并且通过使用写入权限,用户可以创建表。
4. 配额
该组件用于定义命名空间可以为表和区域包含的配额。
5. 预定义的命名空间
有两个预定义的特殊命名空间。
hbase:这是一个系统命名空间,用于包含 HBase 内部表。
default:此命名空间适用于所有未定义命名空间的表。
Now let us see each component of the namespace.
1. Table
All tables are part of the namespace. If there is no namespace defined then the table will be assigned to the default namespace.
2. RegionServer group
It is possible to have a default RegionServer group for a namespace. In that case, a table created will be a member of RegionServer.
3. Permission
Using namespace a user can define Access Control Lists such as a read, delete, and update permission, and by using write permission a user can create a table.
4. Quota
This component is used to define a quota that the namespace can contain for tables and regions.
5. Predefined namespaces
There are two predefined special namespaces.
hbase: This is a system namespace that is used to contain HBase internal tables.
default: This namespace is for all the tables for which a namespace is not defined.
HBase 数据模型操作
主要的操作数据模型有Get、Put、Scan和Delete。使用这些操作,我们可以从表中读取、写入和删除记录。
让我们详细了解每个操作。
1.Get
Get操作类似于关系数据库的Select语句。它用于获取 HBase 表的内容。
我们可以在 HBase shell 上执行 Get 命令,如下所示。
hbase(main):001:0> get'table name','row key'<filters>
2. Put
Put操作用于读取表的多行。它不同于我们需要指定一组要读取的行的进入。使用 Scan 我们可以遍历表中的一系列行或所有行。
3.Scan
扫描操作用于读取表的多行。它与 Get 不同,Get 中我们需要指定一组要读取的行。使用 Scan 我们可以遍历表中的一系列行或所有行。
4.Delete
删除操作用于从 HBase 表中删除一行或一组行。可以通过HTable.delete()来执行。
一旦执行了删除命令,它就会被标记为墓碑,当压缩发生时,该行最终从表中删除。
各种类型的内部删除标记如下。
删除它用于列的特定版本。
删除列可用于所有列版本。
删除族它用于特定 ColumnFamily 的所有列。
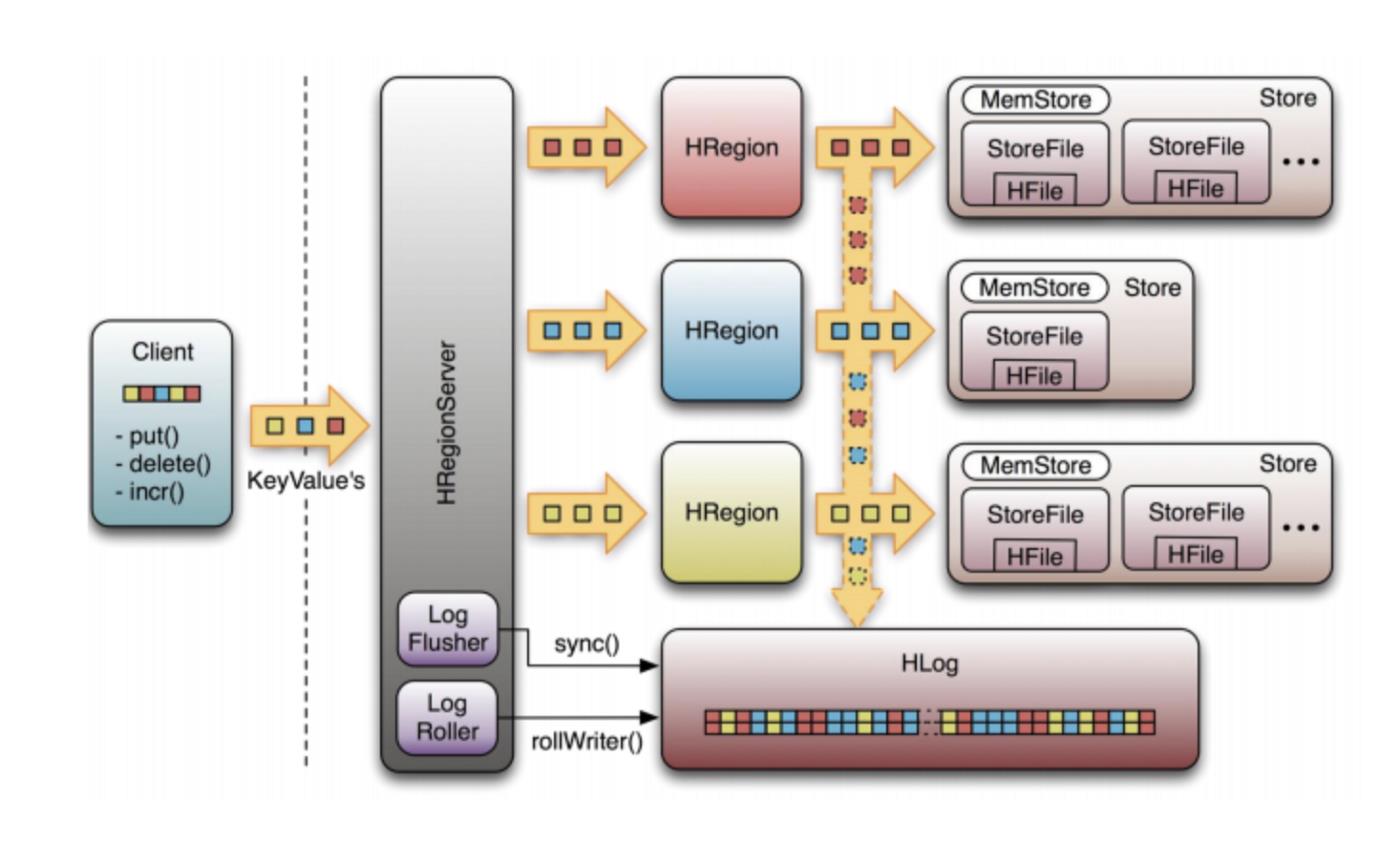
HBase 系统架构
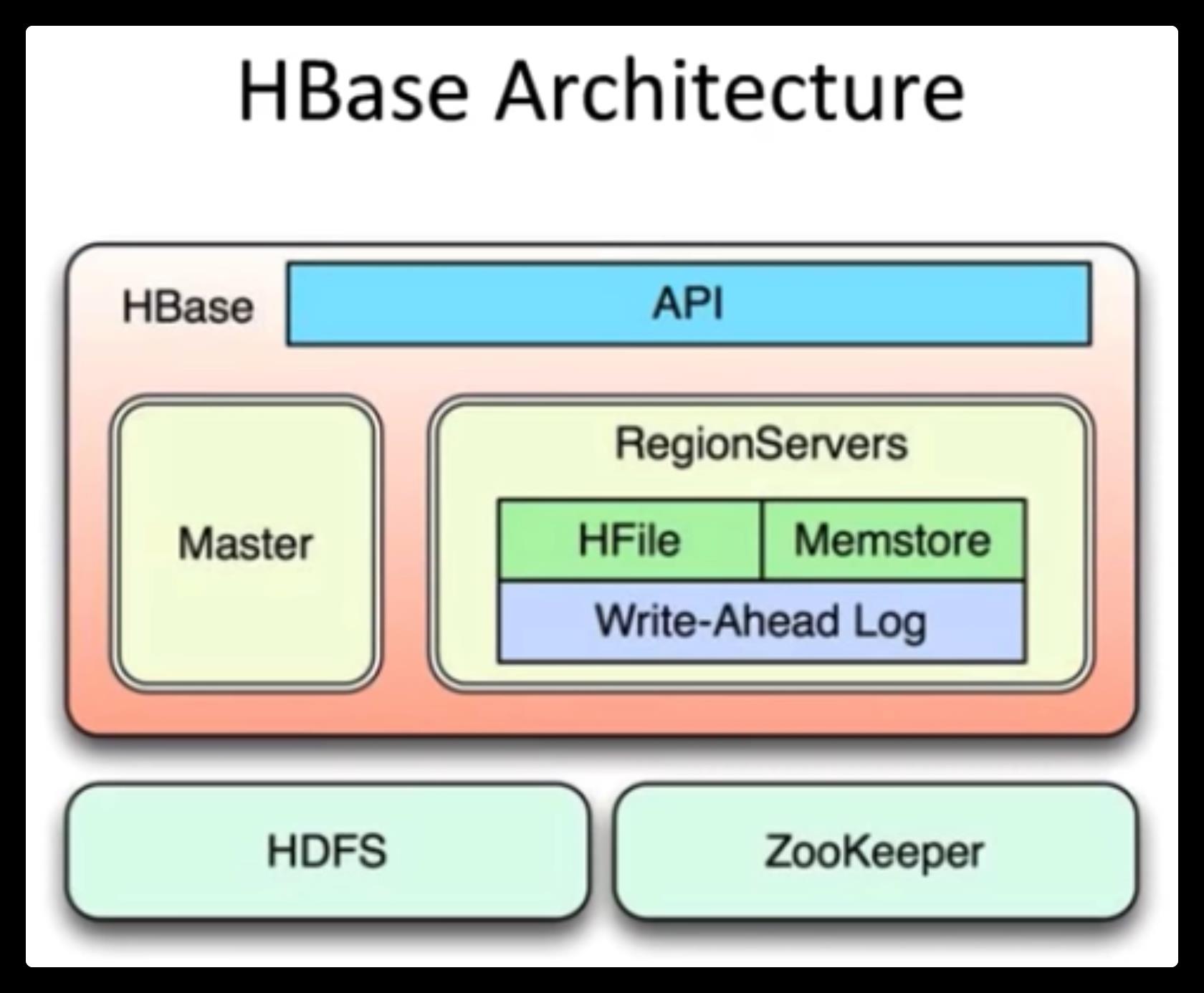
HBase 更多的适用场景是数据存储,而不是数据库。 HBase 可以通过在集群中添加商品节点来线性扩展和模块化扩展。如果我们将节点从 20 个增加到 40 个,那么在 HBase 集群中,存储和容量也会同时增加。
HBase is represented as Data Store rather than a database. HBase can scale linear as well as modular by adding commodity nodes in the cluster. If we are increasing the nodes from 20 to 40 then in the HBase cluster then the storage and the capacity also increases concurrently.
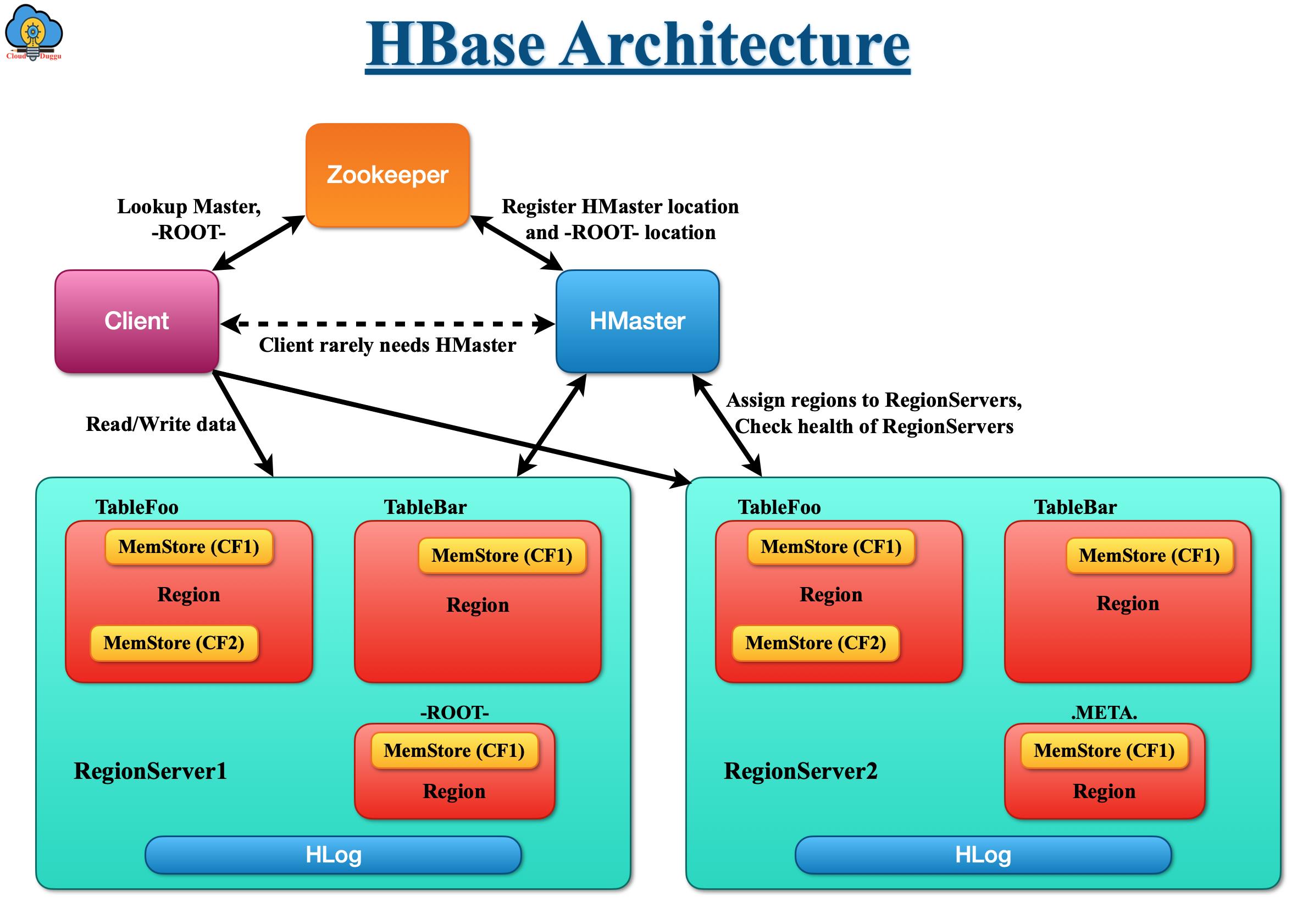
HBase is represented as Data Store rather than a database. HBase can scale linear as well as modular by adding commodity nodes in the cluster. If we are increasing the nodes from 20 to 40 then in the HBase cluster then the storage and the capacity also increases concurrently.
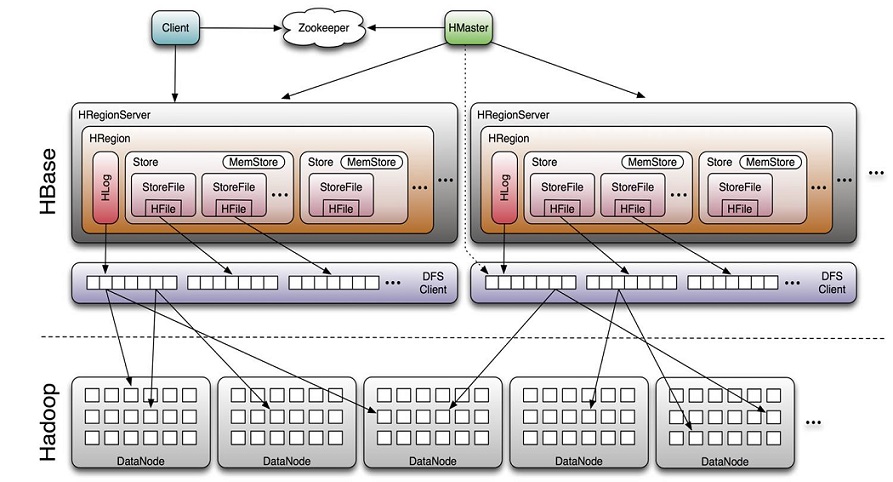
Client
包含访问HBase的接口并维护cache来加快对HBase的访问
Zookeeper
保证任何时候,集群中只有一个master
存贮所有Region的寻址入口。
实时监控Region server的上线和下线信息。并实时通知Master
存储HBase的schema和table元数据
Master
为Region server分配region
负责Region server的负载均衡
发现失效的Region server并重新分配其上的region
管理用户对table的增删改操作
RegionServer
Region server维护region,处理对这些region的IO请求
Region server负责切分在运行过程中变得过大的region
HLog(WAL log):
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和 region名字外,同时还包括sequence number和timestamp,timestamp是” 写入时间”,sequence number的起始值为0,或者是最近一次存入文件系 统中sequence number。
HLog SequeceFile的Value是HBase的KeyValue对象,即对应HFile中的 KeyValue
Region
HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会 两个新的region(裂变);
当table中的行不断增多,就会有越来越多的region。这样一张完整的表 被保存在多个Regionserver上。
Memstore 与 storefile
一个region由多个store组成,一个store对应一个CF(列族)
store包括位于内存中的memstore和位于磁盘的storefile写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile
当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、 major compaction),在合并过程中会进行版本合并和删除工作 (majar),形成更大的storefile。
当一个region所有storefile的大小和超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡。
客户端检索数据,先在memstore找,找不到再找storefile
HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的HRegion server上。
HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。
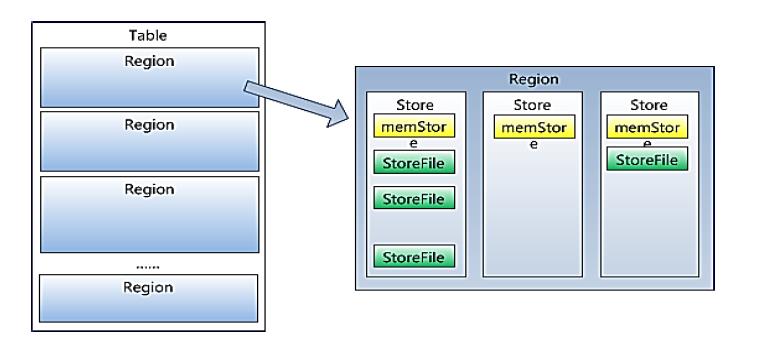
HBase Components
Let us discuss various components of HBase.
1. ZooKeeper
Apache ZooKeeper is a high-performance, centralized, multi coordination service system for distributed applications, which provides a distributed synchronization and group service to HBase. It directs the focus of users on the application logic despite cluster coordination. It also provides an API using which a user can coordinate with the Master server.
Apache ZooKeeper APIs provide consistency, ordering, and durability, it also provides synchronization and concurrency for a distributed clustered system.
2. HMaster
Apache HBase HMaster is an important component of the HBase cluster that is responsible RegionServers monitoring, handling the failover, and managing region split.
HMaster functionalities are as below.
It Monitors the RegionServers.
It Handles RegionServers failover.
It is used to handle metadata changes.
It will assign/disallow regions.
It provides an interface for all metadata changes.
It is used to perform reload balancing in idle time.
HMaster provides a web user interface that shows information about the HBase cluster.
3. RegionServers
RegionServers are responsible for storing the actual data. Just like in the Hadoop cluster, a NameNode stores metadata, and DataNode stores actual data similar way in HBase, mater holds the metadata, and RegionServers stores actual data. RegionServer runs on a DataNode in a distributed cluster environment.
RegionServer performs the following tasks.
It handles the serving regions (tables) assigned to it.
It Handles read and write requests performed by the client.
It will flush the cache to HDFS.
It is responsible for handling region splits.
It maintains HLogs.
Components of a RegionServer
Let us see the components of RegionServer.
3.1 WAL(Write-Ahead logs)
Apache HBase WAL is an intermediate file also called an edit log file. When data is read or modified to HBase, it's not directly written in the disk rather it is kept in memory for some time but keeping data in memory could be dangerous because if the system goes down then all data would be erased so to overcome to this issue Apache HBase has a Write-Ahead logfile in which data will be written at first place and then on memory.
3.2 HFile
This is the actual file where row data is stored physically.
3.3 Store
It corresponds to a column family for a table in HBase.Here the HFile is stored
3.4 MemStore
This component resides in the main memory and records the current data operation so if data is stored in WAL then RegionServers stores key-value in the memory store.
3.5 Region
Regions are the splits of a table which is divided based on the key and hosted by RegionServers.
4. Client
The client can be written in Java or any other language and using external APIs to connect to RegionServer which is managing actual row data. Client query to catalog tables to find out the region and once the region is found, the client directly contacts RegionServers and performs the data operation and cached the data for fast retrieval.
5. Catalog Tables
Catalog Tables are used to maintain metadata for all RegionServers and regions.
There are two types of Catalog tables that exist in HBase.
-ROOT- This table will have information about the location of the META table.
.META This table contains information about all regions and their locations.
HBase Basic Architecture
HBase consists of HMaster and HRegionServer and also follows the master-slave server architecture. HBase divides the logical table into multiple data blocks, HRegion, and stores them in HRegionServer.
HMaster is responsible for managing all HRegionServers. It does not store any data itself, but only stores the mappings (metadata) of data to HRegionServer.
All nodes in the cluster are coordinated by Zookeeper and handle various issues that may be encountered during HBase operation. The basic architecture of HBase is shown below:
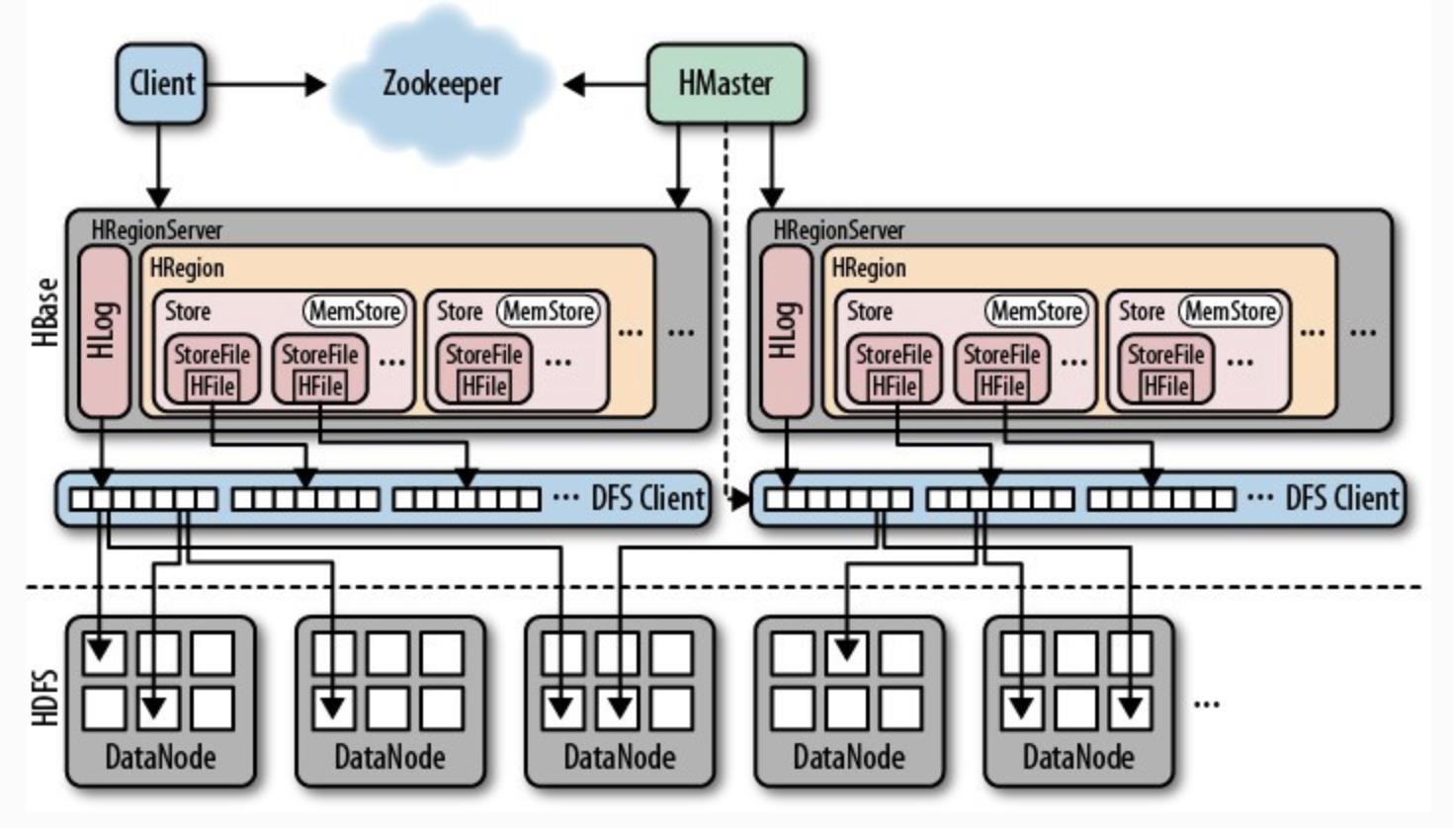
Client : Use HBase’s RPC mechanism to communicate with HMaster and HRegionServer, submit requests and get results. For management operations, the client performs RPC with HMaster. For data read and write operations, the client performs RPC with HRegionServer.
Zookeeper: By registering the status information of each node in the cluster to ZooKeeper, HMaster can sense the health status of each HRegionServer at any time, and can also avoid the single point problem of HMaster.
HMaster: Manage all HRegionServers, tell them which HRegions need to be maintained, and monitor the health of all HRegionServers. When a new HRegionServer logs in to HMaster, HMaster tells it to wait for data to be allocated. When an HRegion dies, HMaster marks all HRegions it is responsible for as unallocated and then assigns them to other HRegionServers. HMaster does not have a single point problem. HBase can start multiple HMasters. Through the Zookeeper’s election mechanism, there is always one HMaster running in the cluster, which improves the availability of the cluster.
HRegion: When the size of the table exceeds the preset value, HBase will automatically divide the table into different areas, each of which contains a subset of all the rows in the table. For the user, each table is a collection of data, distinguished by a primary key (RowKey). Physically, a table is split into multiple blocks, each of which is an HRegion. We use the table name + start/end primary key to distinguish each HRegion. One HRegion will save a piece of continuous data in a table. A complete table data is stored in multiple HRegions.
HRegionServer: All data in HBase is generally stored in HDFS from the bottom layer. Users can obtain this data through a series of HRegionServers. Generally, only one HRegionServer is running on one node of the cluster, and the HRegion of each segment is only maintained by one HRegionServer. HRegionServer is mainly responsible for reading and writing data to the HDFS file system in response to user I/O requests. It is the core module in HBase. HRegionServer internally manages a series of HRegion objects, each HRegion corresponding to a continuous data segment in the logical table. HRegion is composed of multiple HStores. Each HStore corresponds to the storage of one column family in the logical table. It can be seen that each column family is a centralized storage unit. Therefore, to improve operational efficiency, it is preferable to place columns with common I/O characteristics in one column family.
HStore: It is the core of HBase storage, which consists of MemStore and StoreFiles. MemStore is a memory buffer. The data written by the user will first be put into MemStore. When MemStore is full, Flush will be a StoreFile (the underlying implementation is HFile). When the number of StoreFile files increases to a certain threshold, the Compact merge operation will be triggered, merge multiple StoreFiles into one StoreFile, and perform version merge and data delete operations during the merge process. Therefore, it can be seen that HBase only adds data, and all update and delete operations are performed in the subsequent Compact process, so that the user’s write operation can be returned as soon as it enters the memory, ensuring the high performance of HBaseI/O. When StoreFiles Compact, it will gradually form a larger and larger StoreFile. When the size of a single StoreFile exceeds a certain threshold, the Split operation will be triggered. At the same time, the current HRegion will be split into 2 HRegions, and the parent HRegion will go offline. The two sub-HRegions are assigned to the corresponding HRegionServer by HMaster so that the load pressure of the original HRegion is shunted to the two HRegions.
HLog: Each HRegionServer has an HLog object, which is a pre-written log class that implements the Write Ahead Log. Each time a user writes data to MemStore, it also writes a copy of the data to the HLog file. The HLog file is periodically scrolled and deleted, and the old file is deleted (data that has been persisted to the StoreFile). When HMaster detects that an HRegionServer is terminated unexpectedly by the Zookeeper, HMaster first processes the legacy HLog file, splits the HLog data of different HRegions, puts them into the corresponding HRegion directory, and then redistributes the invalid HRegions. In the process of loading HRegion, HRegionServer of these HRegions will find that there is a history HLog needs to be processed so the data in Replay HLog will be transferred to MemStore, then Flush to StoreFiles to complete data recovery.
https://towardsdatascience.com/hbase-working-principle-a-part-of-hadoop-architecture-fbe0453a031b
HBase优化最佳实践
1.预先分区
默认情况下,在创建 HBase 表的时候会自动创建一个 Region 分区,当导入数据的时候,所有的 HBase 客户端都向这一个 Region 写数据,直到这个 Region 足够大了才进行切分。一种可以加快批量写入速度的方法是通过预先创建一些空的 Regions,这样当数据写入 HBase 时,会按照 Region 分区情况,在集群内做数据的负载均衡。
2.Rowkey优化
HBase 中 Rowkey 是按照字典序存储,因此,设计 Rowkey 时,要充分利用排序特点,将经常一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
此外,Rowkey 若是递增的生成,建议不要使用正序直接写入 Rowkey,而是采用 reverse 的方式反转Rowkey,使得 Rowkey 大致均衡分布,这样设计有个好处是能将 RegionServer 的负载均衡,否则容易产生所有新数据都在一个 RegionServer 上堆积的现象,这一点还可以结合 table 的预切分一起设计。
3.减少列族数量
不要在一张表里定义太多的 ColumnFamily。目前 Hbase 并不能很好的处理超过 2~3 个 ColumnFamily 的表。因为某个 ColumnFamily 在 flush 的时候,它邻近的 ColumnFamily 也会因关联效应被触发 flush,最终导致系统产生更多的 I/O。
4.缓存策略
创建表的时候,可以通过 HColumnDescriptor.setInMemory(true) 将表放到 RegionServer 的缓存中,保证在读取的时候被 cache 命中。
5.设置存储生命期
创建表的时候,可以通过HColumnDescriptor.setTimeToLive(int timeToLive)设置表中数据的存储生命期,过期数据将自动被删除。
6.硬盘配置
每台 RegionServer 管理 10~1000 个 Regions,每个 Region 在 1~2G,则每台 Server 最少要 10G,最大要1000*2G=2TB,考虑 3 备份,则要 6TB。方案一是用 3 块 2TB 硬盘,二是用 12 块 500G 硬盘,带宽足够时,后者能提供更大的吞吐率,更细粒度的冗余备份,更快速的单盘故障恢复。
7.分配合适的内存给RegionServer服务
在不影响其他服务的情况下,越大越好。例如在 HBase 的 conf 目录下的 hbase-env.sh 的最后添加export HBASE_REGIONSERVER_OPTS="-Xmx16000m$HBASE_REGIONSERVER_OPTS”
其中 16000m 为分配给 RegionServer 的内存大小。
8.写数据的备份数
备份数与读性能成正比,与写性能成反比,且备份数影响高可用性。有两种配置方式,一种是将 hdfs-site.xml拷贝到 hbase 的 conf 目录下,然后在其中添加或修改配置项 dfs.replication 的值为要设置的备份数,这种修改对所有的 HBase 用户表都生效,另外一种方式,是改写 HBase 代码,让 HBase 支持针对列族设置备份数,在创建表时,设置列族备份数,默认为 3,此种备份数只对设置的列族生效。
9.WAL(预写日志)
可设置开关,表示 HBase 在写数据前用不用先写日志,默认是打开,关掉会提高性能,但是如果系统出现故障(负责插入的 RegionServer 挂掉),数据可能会丢失。配置 WAL 在调用 JavaAPI 写入时,设置 Put 实例的WAL,调用 Put.setWriteToWAL(boolean)。
10. 批量写
HBase 的 Put 支持单条插入,也支持批量插入,一般来说批量写更快,节省来回的网络开销。在客户端调用JavaAPI 时,先将批量的 Put 放入一个 Put 列表,然后调用 HTable 的 Put(Put 列表) 函数来批量写。
11. 客户端一次从服务器拉取的数量
通过配置一次拉去的较大的数据量可以减少客户端获取数据的时间,但是它会占用客户端内存。有三个地方可进行配置:
1)在 HBase 的 conf 配置文件中进行配置hbase.client.scanner.caching;
2)通过调用HTable.setScannerCaching(intscannerCaching)进行配置;
3)通过调用Scan.setCaching(intcaching)进行配置。三者的优先级越来越高。
12. RegionServer的请求处理I/O线程数
较少的 IO 线程适用于处理单次请求内存消耗较高的 Big Put 场景 (大容量单次 Put 或设置了较大 cache 的Scan,均属于 Big Put) 或 ReigonServer 的内存比较紧张的场景。
较多的 IO 线程,适用于单次请求内存消耗低,TPS 要求 (每秒事务处理量 (TransactionPerSecond)) 非常高的场景。设置该值的时候,以监控内存为主要参考。
在 hbase-site.xml 配置文件中配置项为hbase.regionserver.handler.count。
13. Region的大小设置
配置项为hbase.hregion.max.filesize,所属配置文件为hbase-site.xml.,默认大小256M。
在当前 ReigonServer 上单个 Reigon 的最大存储空间,单个 Region 超过该值时,这个 Region 会被自动 split成更小的 Region。小 Region 对 split 和 compaction 友好,因为拆分 Region 或 compact 小 Region 里的StoreFile 速度很快,内存占用低。缺点是 split 和 compaction 会很频繁,特别是数量较多的小 Region 不停地split, compaction,会导致集群响应时间波动很大,Region 数量太多不仅给管理上带来麻烦,甚至会引发一些Hbase 的 bug。一般 512M 以下的都算小 Region。大 Region 则不太适合经常 split 和 compaction,因为做一次 compact 和 split 会产生较长时间的停顿,对应用的读写性能冲击非常大。
此外,大 Region 意味着较大的 StoreFile,compaction 时对内存也是一个挑战。如果你的应用场景中,某个时间点的访问量较低,那么在此时做 compact 和 split,既能顺利完成 split 和 compaction,又能保证绝大多数时间平稳的读写性能。compaction 是无法避免的,split 可以从自动调整为手动。只要通过将这个参数值调大到某个很难达到的值,比如 100G,就可以间接禁用自动 split(RegionServer 不会对未到达 100G 的 Region 做split)。再配合 RegionSplitter 这个工具,在需要 split 时,手动 split。手动 split 在灵活性和稳定性上比起自动split 要高很多,而且管理成本增加不多,比较推荐 online 实时系统使用。内存方面,小 Region 在设置memstore 的大小值上比较灵活,大 Region 则过大过小都不行,过大会导致 flush 时 app 的 IO wait 增高,过小则因 StoreFile 过多影响读性能。
14.操作系统参数
Linux系统最大可打开文件数一般默认的参数值是1024,如果你不进行修改并发量上来的时候会出现“Too Many Open Files”的错误,导致整个HBase不可运行,你可以用ulimit -n 命令进行修改,或者修改/etc/security/limits.conf和/proc/sys/fs/file-max 的参数,具体如何修改可以去Google 关键字 “linux limits.conf ”
15.Jvm配置
修改 hbase-env.sh 文件中的配置参数,根据你的机器硬件和当前操作系统的JVM(32/64位)配置适当的参数。
HBASE_HEAPSIZE 4000 HBase使用的 JVM 堆的大小
HBASE_OPTS "‐server ‐XX:+UseConcMarkSweepGC" JVM GC 选项
HBASE_MANAGES_ZKfalse 是否使用Zookeeper进行分布式管理
16. 持久化
重启操作系统后HBase中数据全无,你可以不做任何修改的情况下,创建一张表,写一条数据进行,然后将机器重启,重启后你再进入HBase的shell中使用 list 命令查看当前所存在的表,一个都没有了。是不是很杯具?没有关系你可以在hbase/conf/hbase-default.xml中设置hbase.rootdir的值,来设置文件的保存位置指定一个文件夹,例如:file:///you/hbase-data/path,你建立的HBase中的表和数据就直接写到了你的磁盘上,同样你也可以指定你的分布式文件系统HDFS的路径例如:hdfs://NAMENODE_SERVER:PORT/HBASE_ROOTDIR,这样就写到了你的分布式文件系统上了。
17. 缓冲区大小
hbase.client.write.buffer
这个参数可以设置写入数据缓冲区的大小,当客户端和服务器端传输数据,服务器为了提高系统运行性能开辟一个写的缓冲区来处理它,这个参数设置如果设置的大了,将会对系统的内存有一定的要求,直接影响系统的性能。
18. 扫描目录表
hbase.master.meta.thread.rescanfrequency
定义多长时间HMaster对系统表 root 和 meta 扫描一次,这个参数可以设置的长一些,降低系统的能耗。
19. split/compaction时间间隔
hbase.regionserver.thread.splitcompactcheckfrequency
这个参数是表示多久去RegionServer服务器运行一次split/compaction的时间间隔,当然split之前会先进行一个compact操作.这个compact操作可能是minorcompact也可能是major compact.compact后,会从所有的Store下的所有StoreFile文件最大的那个取midkey.这个midkey可能并不处于全部数据的mid中.一个row-key的下面的数据可能会跨不同的HRegion。
20. 缓存在JVM堆中分配的百分比
hfile.block.cache.size
指定HFile/StoreFile 缓存在JVM堆中分配的百分比,默认值是0.2,意思就是20%,而如果你设置成0,就表示对该选项屏蔽。
21. ZooKeeper客户端同时访问的并发连接数
hbase.zookeeper.property.maxClientCnxns
这项配置的选项就是从zookeeper中来的,表示ZooKeeper客户端同时访问的并发连接数,ZooKeeper对于HBase来说就是一个入口这个参数的值可以适当放大些。
22. memstores占用堆的大小参数配置
hbase.regionserver.global.memstore.upperLimit
在RegionServer中所有memstores占用堆的大小参数配置,默认值是0.4,表示40%,如果设置为0,就是对选项进行屏蔽。
23. Memstore中缓存写入大小
hbase.hregion.memstore.flush.size
Memstore中缓存的内容超过配置的范围后将会写到磁盘上,例如:删除操作是先写入MemStore里做个标记,指示那个value, column 或 family等下是要删除的,HBase会定期对存储文件做一个major compaction,在那时HBase会把MemStore刷入一个新的HFile存储文件中。如果在一定时间范围内没有做major compaction,而Memstore中超出的范围就写入磁盘上了。
小结
HBase is a NoSQL database commonly referred to as the Hadoop Database, which is open-source and is based on Google's Big Table white paper. HBase runs on top of the Hadoop Distributed File System (HDFS), which allows it to be highly scalable, and it supports Hadoop's map-reduce programming model. HBase permits two types of access: random access of rows through their row keys and offline or batch access through map-reduce queries.
HBase 是一种 NoSQL 数据库,通常称为 Hadoop 数据库,它是开源的,基于 Google 的 Big Table 白皮书。 HBase 运行在 Hadoop 分布式文件系统 (HDFS) 之上,这使其具有高度可扩展性,并且支持 Hadoop 的 map-reduce 编程模型。 HBase 允许两种类型的访问:通过行键随机访问行和通过 map-reduce 查询离线或批量访问。
参考资料
https://blog.csdn.net/weixin_40535323/article/details/81704854
https://www.jianshu.com/p/3832ae37fac4
https://hbase.apache.org/book.html#arch.overview
https://blog.csdn.net/whdxjbw/article/details/81101200
https://www.cloudduggu.com/hbase/data_model/
https://www.informit.com/articles/article.aspx?p=2253412
https://towardsdatascience.com/hbase-working-principle-a-part-of-hadoop-architecture-fbe0453a031b
https://developpaper.com/hbase-learning-1-basic-introduction/
以上是关于图文详解HBase 的数据模型与架构原理详解的主要内容,如果未能解决你的问题,请参考以下文章