HBase高可用集群运维实践
Posted 京东大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase高可用集群运维实践相关的知识,希望对你有一定的参考价值。
在94版本中,经常困扰我们的一个问题就是集群上的某些机器会因为某些用户的不恰当操作,例如热点问题,大量的scan操作等导致机器上的其他表正常读写受到影响。之前的运维经验,一般的做法就是stop balance,然后通过move region的方式把有影响的表移到某些机器上。由于存在这个原因和业务的压力,往往只能采用拆分集群的方式,在一个HDFS 上往往运行几个HBase集群,但是带来的是运维成本的增加。
今年618之前,在我们决定采用新版本之后,我们将HBase 2.0 尚未发布的rsgroup功能迁移到我们的自己维护的1.1.X版本中,从而实现在HBase集群上隔离和控制。整个架构如下:
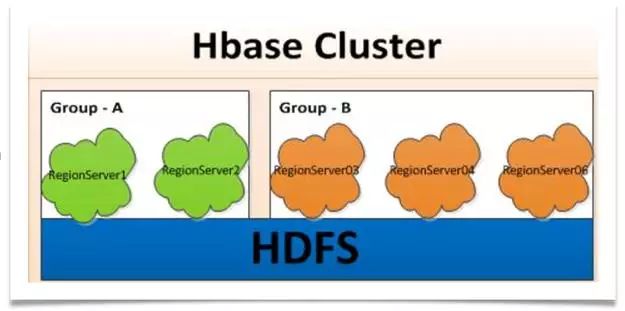
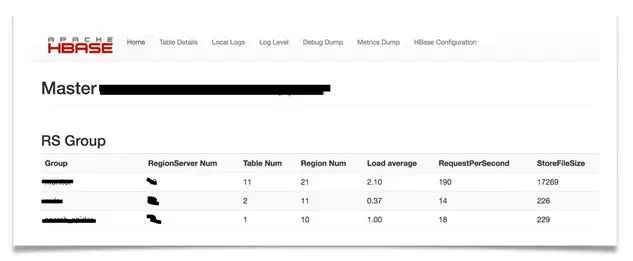
最后我们把分组功能接入了BDP运维平台。DBA在配置实例的时候,根据业务选择不同的分组。通过rsgroup 解决拆分集群问题,可运维性也得到了提升。另外,不同于之前的平滑滚动重起,动不动就需要几天,我们也通过移动分组的方式进行集群滚动从而缩短维护时间。考虑到不同分组的replication可能会产生影响,我们也开发不同分组的replication功能,主集群的日志只能发送到备份集群的同一个分组的regionserver中。在集群页面上,我们也添加不同分组统计,效果如下:
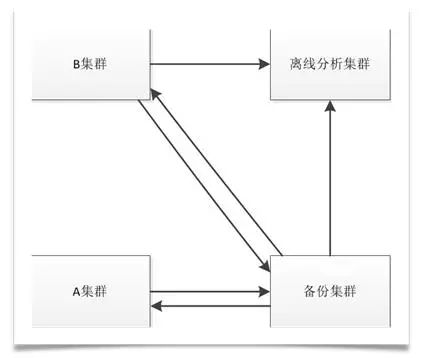
HDFS提供了三个备份的功能,但是对于重要的业务还远远不够。HBase本身的replication功能可以实现集群间秒级的数据同步,而且整个replication的过程是异步化,对于主集群几乎没有影响。考虑业务的重要性,在新版本的集群配置了集群间的主主同步。如果机房出现问题或者主集群异常短时间无法恢复,那么用户可以切换到备份集群。
由于采用实例来管理集群,所以DBA配置的时候可以选择实例是否进行主备以及集群:增加备份集群之后,我们把所有需要抽取的表从主集群改成为备份集群,这样对于大量的抽取可以减少对主集群的影响。
目前集群的数据,除了用户普通的写入之外,还有采用bulkload的方式入库,不同用户在不同的集市生成HFile导入到HBase中。针对这种情况,我们把2.0 版本的HBASE-13153(Bulk Loaded HFile Replication)打进到我们的版本中,实现了HFile的replication。
最终通过replication实现数据的备份和聚合,这样在用户申请实例的时候,可以选择不同的套餐组合。例如只需要实时数据存储,可以选择主主备份,需要离线分析的可以选择主备同步到离线分析集群。
虽然rsgroup 起到了隔离功能,HBase本身读写队列分离,但是同个分组的表还会互相影响,而且京东这么多业务部门,不可能都独立分组。HBase1.0 发布了一个针对读写进行限制的功能——配额管理。使用配额管理做到对namespace和table 的rpc请求的限制,目前是限制读写次数和流量。这个功能很适合我们,作为底层提供者,很大程度上我们没有办法预估用户的所有情况,在运维过程中,经常有用户出现热点问题导致单台服务的请求量过高从而影响到了其他表的读写。我们针对实例,也就是表空间的请求进行限制,这就需要用户在申请的时候衡量资源了。
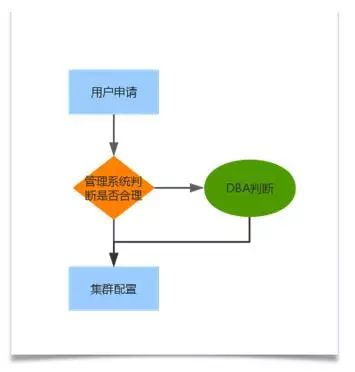
通过配额,我们可以做到对集群的资源整体把控。唯一的遗憾是当前HBase的quotas 只能限制单台的ReginServe。目前配额管理功能在开发集成自动化配置流程当中,预计年后上线。
目前我们准备这三把利剑保障了集群的稳定性,但是随着业务规模的增大,我们也越来越重视客户端,目前也在对客户端进行改造。希望通过SDK 实现集群主备切换,接入UMP采集更多性能指标,做到提前发现问题,从而保障集群稳定。
以上是关于HBase高可用集群运维实践的主要内容,如果未能解决你的问题,请参考以下文章
Linux企业运维——Hadoop大数据平台(下)hdfs高可用Yarn高可用hbase高可用
Linux企业运维——Hadoop大数据平台(下)hdfs高可用Yarn高可用hbase高可用