HBase服务高可用之路的探索
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase服务高可用之路的探索相关的知识,希望对你有一定的参考价值。
参考技术A [toc]这里的高可用并不是指HBase本身的高可用机制。而是HBase主备双服务的高可用,线上业务依赖于主备HBase集群来提供数据支持,主集群首要的任务时负责数据的读写,备集群只是为了容灾。
对于HBase主备服务高可用方案的调研,团队内部从未停止过探索的步伐。从最初手动切换nginx的域名映射,到统计异常日志占比,然后进行自动的域名切换。那时候我们面临的状况是,主集群大量读写超时、甚至服务不可用,造成业务方接口无法为用户提供正常的线上业务时,HBase运维小伙伴们才能感知到HBase集群的异常状态,手动切换流量至备集群,从而在服务恢复的时间内,造成了无法容忍的损失。
针对旧方案的种种痛点,以及受微服务中熔断概念的启发,最终选择集成了饿了么提供的一个熔断框架—— doctor ,实现了HBase主集群服务查询异常时,查询流量能够及时、自动、无感知地进行切换到备集群。
一般在微服架构中,有一个组件角色叫熔断器。顾名思义,熔断器起的作用就是在特定的场景下关掉当前的通路,从而起到保护整个系统的效果。
在微服务架构中,一般我们的独立服务是比较多的,每个独立服务之间划分责任边界,并通过约定协议接口来进行通信。当我们的调用链路复杂依赖多时,很可能会发生雪崩效应。
假设有这么一个场景,有A, B, C, D四个独立服务,A会依赖B,C,D;当D发生负载过高或网络异常等导致响应过慢或超时时,很可能A会因此堆积过多的等待链接,从而导致A的状态也转为异常,后面依赖到A的其他服务跟着发生链式反应,这将会导致大面积的服务不可用,即使本来是一些没有依赖到B,C,D的服务。如下图所示:
这不是我们希望看到的结果,所以这个时候熔断器可以派上用场。最简单的做法,我们为每个依赖服务配置一个熔断器开关,正常情况下是关闭的,也就是可以正常发起请求;当请求失败(超时或者其他异常)次数超过预设值时,熔断器自动打开,这时所有经过这个熔断器的请求都会直接返回失败,并没有真正到达所依赖的服务上。这时服务A本身仍然是能正常服务的。当然,我们针对失败请求的策略,并没有这么简单粗暴。
HBase 虽然提供了 HBase Replication 机制,用来实现集群间单方向的异步数据复制,线上虽然部署了双集群,备集群 SSD 分组和主集群 SSD 分组有相同的配置。当主集群因为磁盘,网络,或者其他业务突发流量影响导致某些 RegionServer 甚至集群不可用的时候,就需要提供备集群继续提供服务,备集群的数据可能会因为 HBase Replication 机制的延迟,相比主集群的数据是滞后的,按照我们集群目前的规模统计,平均延迟在 100ms 以内。所以为了达到高可用,业务方只能接受复制延迟,放弃强一致性,选择最终一致性和高可用性。
有赞技术团队对于HBase高可用服务接口的设计,同样使用了熔断的概念,只是其底层的熔断技术依赖于java微服务中的Hystrix框架。其简单的客户端高可用方案原理图如下所示:
业务方是不想感知到后端服务的状态,也就是说在客户端层面,他们只希望一个 Put 或者 Get 请求正常送达且返回预期的数据即可,那么就需要高可用客户端封装一层降级,熔断处理的逻辑,这里有赞采用 Hystrix 做为底层熔断处理引擎,在引擎之上封装了 HBase 的基本 API,用户只需要配置主备机房的 ZK 地址即可,所有的降级熔断逻辑最终封装到 ha-hbase-client 中。
以上文字描述摘选自有赞的技术博客,详情可以参考链接, 有赞 HBase 技术实践:读流程解析与优化
与微服务中的熔断概念类比,我们也可以把我们的主备HBase集群看做是两个独立的服务,而我们的业务方则需要依赖这一个HBase服务,对外提供自己的服务。这里稍微有一点不一样的地方是,我们HBase服务的角色是由两个集群来担任,正常情况下,只有一个集群来承担起HBase服务的功能。HBase熔断切换的简单示例如下:
如果想要更深入地理解主备熔断切换的设计理念,那么,需要优先理解一下滚动窗口计数,以及阈值判断相关的一些内容。 doctor 熔断框架的设计中,依赖于滑动窗口时间内的滚动计数,来进行阈值计算,从而判断当前服务的健康状况。
滚动计数的行为类似于一个拥有固定长度的先进先出队列,或者时间戳序列上的滑动窗口。一个滚动计数的值是队列元素的和,时钟结束时,最后一个元素的值将滚动到先前的位置,传递了一个时间粒度,这个时间粒度,默认1s。下面将借助一个小例子,具体来说明这种机制。
上述便是对HBase熔断思想所做的一个由浅入深的解释,用于实现业务方访问HBase时,对于主备HBase集群的状态切换无感知。即使主集群处于异常状态,我们依旧可以为业务方提供正常的HBase服务。
linux运维架构之路-keepalived高可用

一、Keepalived介绍
Keepalived起初是专为LVS负载均衡软件设计的,用来管理并监控LVS集群系统中各个服务节点的状态,后来又加入了可以实现高可用的VRRP功能,Keepalived是一款高可用软件,它的功能主要包括:
1、管理LVS负载均衡软件
2、实现对LVS集群节点健康检查功能
3、作为系统网络服务的高可用功能

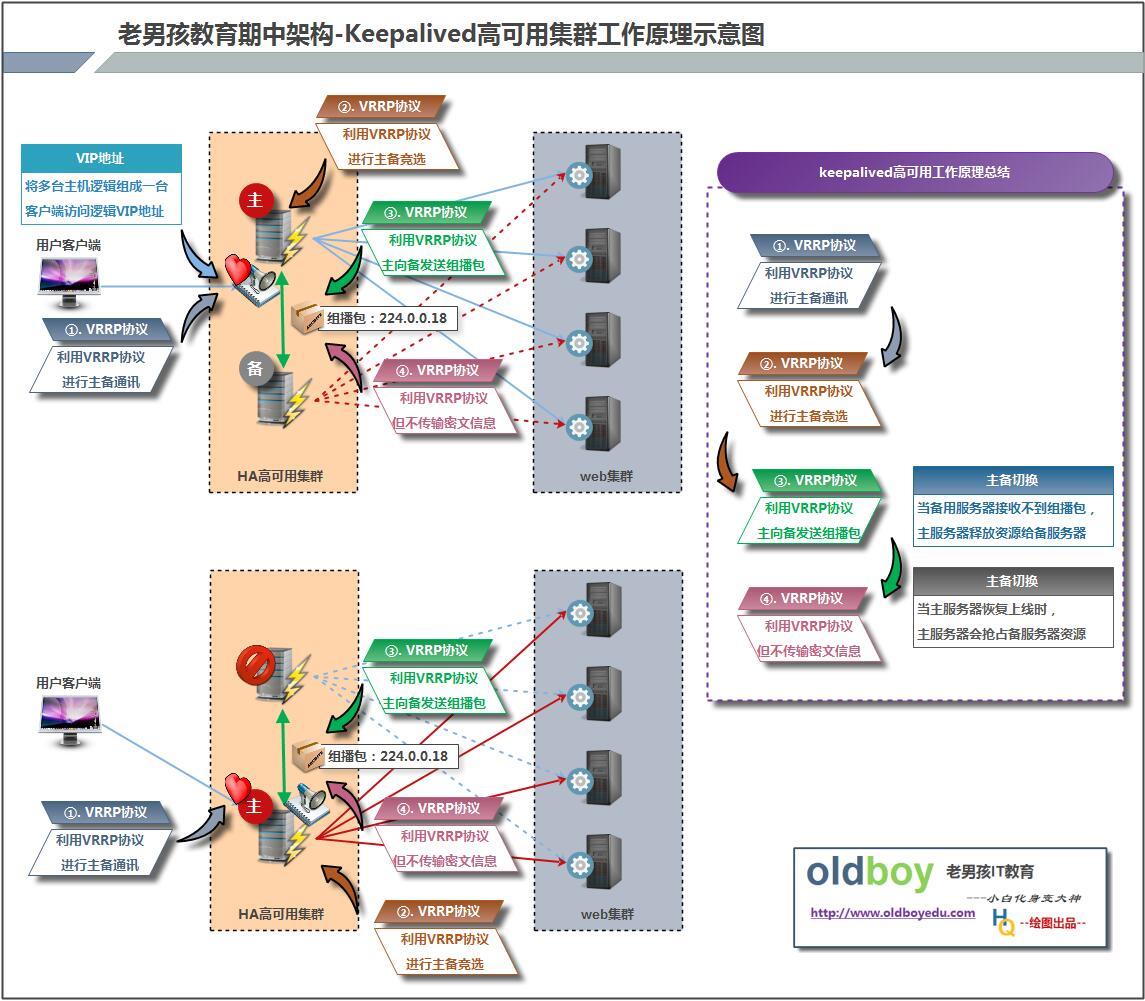
二、Keepalived工作原理
Keepalived的实现基于VRRP
1、VRRP协议,全称Virtual Router Redundancy Protocol,中文名为虚拟路由冗余协议,VRRP的出现是为了解决静态路由的单点故障。
2、VRRP是用过IP多播的方式(默认多播地址(224.0.0.18))实现高可用对之间通信的。
3、工作时主节点发包,备节点接包,当备节点接收不到主节点发的数据包的时候,就启动接管程序接管主节点的资源。备节点可以有多个,通过优先级竞选,但一般Keepalived系统运维工作中都是一对
三、keepalived部署
1、安装keepalived(lb01 lb02)
rpm -qa keepalived
yum install keepalived -y
2、keepalived配置文件详解
global_defs { --- 全局配置标题
notification_email { --- 定义管理员邮箱信息,
330882721@qq.com
330442721@qq.com
}
notification_email_from oldboy@163.com --- 定义利用什么邮箱发送邮件
smtp_server smtp.163.com --- 定义邮件服务器信息
smtp_connect_timeout 30 --- 定义邮件发送超时时间
router_id oldboy01 --- (重点参数)局域网keepalived主机身份标识信息,每一个keepalived主机身份标识信息唯一
}
vrrp_instance VI_1 { --- vrrp协议相关配置(vip地址设置)
state MASTER --- keepalived角色描述(状态)信息,可以配置参数(MASTER BACKUP)
interface eth0 --- 表示将生成虚IP地址,设置在指定的网卡上
virtual_router_id 51 --- 表示keepalived家族标识信息
priority 100 --- keepalived服务竞选主备服务器优先级设置(越大越优先)
advert_int 1 --- 主服务组播包发送间隔时间
authentication { --- 主备主机之间通讯认证机制,
auth_type PASS --- 采用明文认证机制
auth_pass 1111 --- 编写明文密码
}
virtual_ipaddress { --- 设置虚拟IP地址信息
10.0.0.3
}
}
3、搭建基础的keepalived配置文件
|
#lb01主 global_defs { router_id LVS_01 }
vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } } 虚拟IP地址显示信息: |
#lb02备 global_defs { router_id LVS_02 }
vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } } 虚拟IP地址显示信息: |
测试说明:进行抓包观察配置效果;并且对比两个负载均衡服务器的配置文件
四、keepaliver裂脑
裂脑产生的原因
①高可用服务器之间心跳线链路发生故障,导致无法正常通信,心跳线坏了(包括断了,老化)
②网卡及相关驱动坏了,IP配置及冲突问题(网上直连)
③心跳线间连接的设置故障(网上及交换机)
④高可用服务器上开启了iptables防火墙阻挡了心跳消息传输
⑤高可用服务器上心跳网卡地址等信息配置不正确,导致发送心跳失败
解决裂脑常见方案
①同时使用串行电缆和以太网电缆连接,同时用两条心跳线路
②当检测裂脑时强行关闭一个心跳节点(这个功能需要特殊设备支持,如stonith、fence)
③运维层面做好对裂脑的监控报警
#制作监控脚本---lb02
报警的条件:只要lb02 上面有vip
1.lb01 挂了
2.心碎
#!/bin/bash
#desc: jiankong lb02 vip
if [ `ip a s eth0 |grep -c "10.0.0.3"` == 1 ];then
echo "baojing"
fi
五、企业实践案例一:nginx反向代理只监听vip地址,防攻击
1、企业keepalived服务应用(修改nginx反向代理只监听vip地址)
#lb01 lb02 nginx配置
worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; log_format main \'$remote_addr - $remote_user [$time_local] "$request" \' \'$status $body_bytes_sent "$http_referer" \' \'"$http_user_agent" "$http_x_forwarded_for"\'; upstream server_pools { server 10.0.0.7; server 10.0.0.8; server 10.0.0.9; } server { listen 10.0.0.3:80; server_name www.etiantian.org; location / { proxy_pass http://server_pools; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; } access_log logs/access_www.log main; } server { listen 10.0.0.3:80; server_name blog.etiantian.org; location / { proxy_pass http://server_pools; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; } access_log logs/access_blog.log main; } }
说明:在修改反向代理服务器配置文件监听地址时,多个server都需要配置监听地址,否则仍旧使用默认监听所有,nginx修改ip相关的必须重启服务,平滑重启不启作用
2、lb02上不存在vip地址,无法监听,需要修改内核文件
解决方法:
echo \'net.ipv4.ip_nonlocal_bind = 1\' >>/etc/sysctl.conf
sysctl -p
六、企业实践案例二:keepalived结合脚本监控nginx服务
1、nginx服务停止,keepalived服务自动停止,vip飘走
#!/bin/bash #name: check_web.sh #desc: check nginx and kill keepalived if [ `ps -ef |grep nginx |grep -v grep |wc -l` -lt 2 ];then /etc/init.d/keepalived stop fi
2、把监控脚本放入keepalived配置文件中
global_defs { router_id LVS_02 } vrrp_script check_web { script "/server/scripts/check_web.sh" --- 表示将一个脚本信息赋值给变量check_web interval 2 --- 执行监控脚本的间隔时间 weight 2 --- 利用权重值和优先级进行运算,从而降低主服务优先级 使之变为备服务器(建议先忽略) } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } track_script { check_web } }
七、企业实践案例三:keepalived多实例配置
#lb01
global_defs { router_id LVS_01 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } } vrrp_instance VI_2 { state BACKUP interface eth0 virtual_router_id 52 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.4/24 dev eth0 label eth0:2 } }
#lb02 global_defs { router_id LVS_02 } vrrp_instance VI_1 { state BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.3/24 dev eth0 label eth0:1 } } vrrp_instance VI_2 { state MASTER interface eth0 virtual_router_id 52 priority 150 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 10.0.0.4/24 dev eth0 label eth0:2 } }
#lb01 lb02 nginx.conf worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile on; keepalive_timeout 65; log_format main \'$remote_addr - $remote_user [$time_local] "$request" \' \'$status $body_bytes_sent "$http_referer" \' \'"$http_user_agent" "$http_x_forwarded_for"\'; upstream server_pools { server 10.0.0.7; server 10.0.0.8; server 10.0.0.9; } server { listen 10.0.0.3:80; server_name www.etiantian.org; location / { proxy_pass http://server_pools; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; } access_log logs/access_www.log main; } server { listen 10.0.0.4:80; server_name blog.etiantian.org; location / { proxy_pass http://server_pools; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $remote_addr; } access_log logs/access_blog.log main; } }
windows hosts解析
10.0.0.3 www.etiantian.org 10.0.0.4 bbs.etiantian.org
八、指定文件接收Keepalived服务日志
vi /etc/sysconfig/keepalived
KEEPALIVED_OPTIONS="-D -S 0 -d"
vi /etc/rsyslog.conf
local0.* /var/log/keepalived.log
/etc/init.d/keepalived restart
查看生成的接收keepalived日志文件
ll /var/log/keepalived.log
-rw------- 1 root root 5600 Oct 13 11:43 /var/log/keepalived.log
以上是关于HBase服务高可用之路的探索的主要内容,如果未能解决你的问题,请参考以下文章