Linux企业运维——Hadoop大数据平台(下)hdfs高可用Yarn高可用hbase高可用
Posted 是大姚呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux企业运维——Hadoop大数据平台(下)hdfs高可用Yarn高可用hbase高可用相关的知识,希望对你有一定的参考价值。
Linux企业运维——Hadoop大数据平台(下)hdfs高可用、Yarn高可用、hbase高可用
文章目录
一、Hadoop高可用
1.1、zoomkeeper集群部署
由于一个HDFS集群由一个NameNode节点和多个DataNode节点组成,一旦NameNode节点宕机,那么HDFS将不能进行文件的上传与下载。
Hadoop依赖Zookeeper实现HDFS集群的高可用,由状态为Active的NameNode节点对外提供服务,而状态为StandBy的NameNode节点则负责数据的同步,一旦状态为Active的NameNode节点宕机,则状态为StandBy的NameNode节点将会切换为Active状态对外提供服务。
需要五台虚拟机:两个主节点做高可用server1、server5(2G内存),其余是DN(1G内存)
真实主机再开启一台虚拟机server5

server1停止所有运行的节点,删除/tmp目录下的所有数据,清理hadoop

server2、server3和server4也都把/tmp目录下的数据清空



server5安装nfs

server5添加hadoop用户,挂载nfs中server1分享的/home/hadoop目录到本地的/home/hadoop目录,然后切换到hadoop用户进行测试

真实主机将zookeeper包发送到server1的/home/hadoop目录下

server1解压zookeeper包然后切换到zookeeper目录下,复制zoo_sample.cfg文件为zoo.cfg,然后编辑,因为是nfs文件系统所以其他节点的内容也同步修改了

指定数据目录为/tmp/zookeeper,指定server2在zk集群中节点编号为1,依次类推,server3的编号为2,server4的编号为3,2888端口用来同步数据,3888端口用来选举leader

server2创建/tmp/zookeeper目录,将自己的编号1输入到zookeeper/myid内,开启zkServer

server3创建/tmp/zookeeper目录,将自己的编号2输入到zookeeper/myid内,开启zkServer
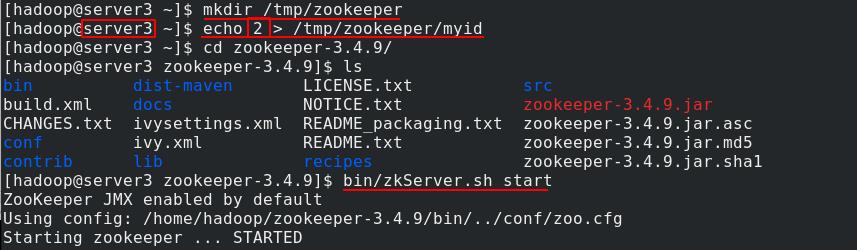
server4创建/tmp/zookeeper目录,将自己的编号3输入到zookeeper/myid内,开启zkServer

server2查看自己的zk集群状态,显示follower

server3查看自己的zk集群状态,显示leader

server4查看自己的zk集群状态,显示follower

server2连接zookeeper作为查询窗口

查看DFS虚拟目录

1.2、hdfs高可用
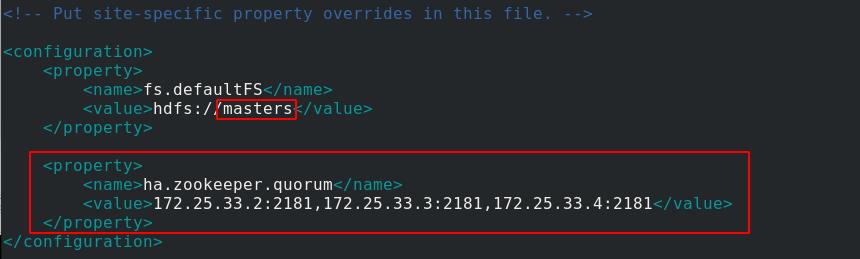
server1编辑core-site.xml文件,指定hdfs的NN为master,指定zookeeper集群主机的地址和端口
[hadoop@server1 hadoop]$ cat core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.33.2:2181,172.25.33.3:2181,172.25.33.4:2181</value>
</property>
</configuration>
再编辑hdfs-site.xml

[hadoop@server1 hadoop]$ cat hdfs-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
## 指定副本数为3
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
## 指定 hdfs 的 nameservices 为 masters,要与 core-site.xml 中的设置一致
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
## masters 含有两个 namenode 节点,名称为 h1 和 h2 (名称可自定义)
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
## h1 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.33.1:9000</value>
</property>
## h1 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.33.1:9870</value>
</property>
## h2 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.33.5:9000</value>
</property>
## h2 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.33.5:9870</value>
</property>
## NameNode 元数据在 JournalNode 上的存放位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.33.2:8485;172.25.33.3:8485;172.25.33.4:8485/masters</value>
</property>
## JournalNode 在本地磁盘存放数据的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
## 开启 NameNode 失败自动切换
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
## 配置失败自动切换实现方式
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
## 配置隔离机制方法
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
## sshfence 隔离机制需要 ssh 免密码
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
## sshfence 隔离机制超时时间
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
server2查看java进程看到开启了QuorumPeerMain,再开启journalnode,三个DN节点按照编号顺序依次开启
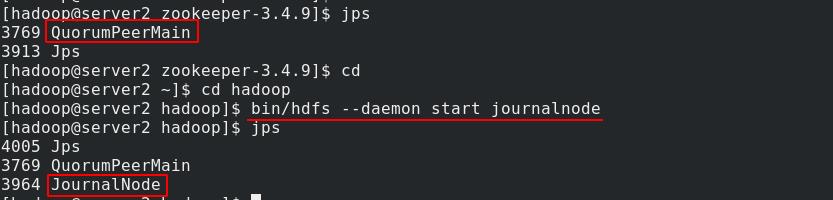
server3开启journalnode
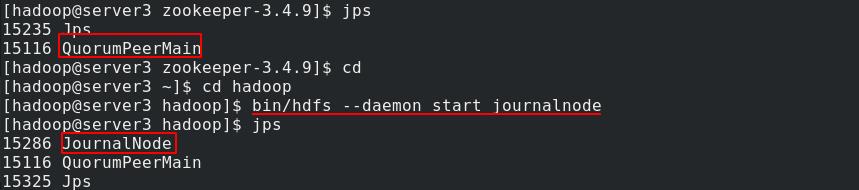
server4开启journalnode

server1格式化 HDFS 集群

将/tmp/hadoop-hadoop里的数据拷贝到server5的/tmp目录下,因为NN数据默认存放在/tmp目录下

在server1上执行格式化zookeeper

server2作为查询窗口连接zookeeper

可以正常访问文件系统

server1启动hdfs集群,完成后可以看到DFSZKFailoverController开启

server2刚才已经连接了zookeeper,查看NN主备,可以看到server1是主

在server1的hadoop管理页面也可以看到server1状态为活跃

server5 的状态为备用

server1新建/user/hadoop虚拟目录,上传input目录
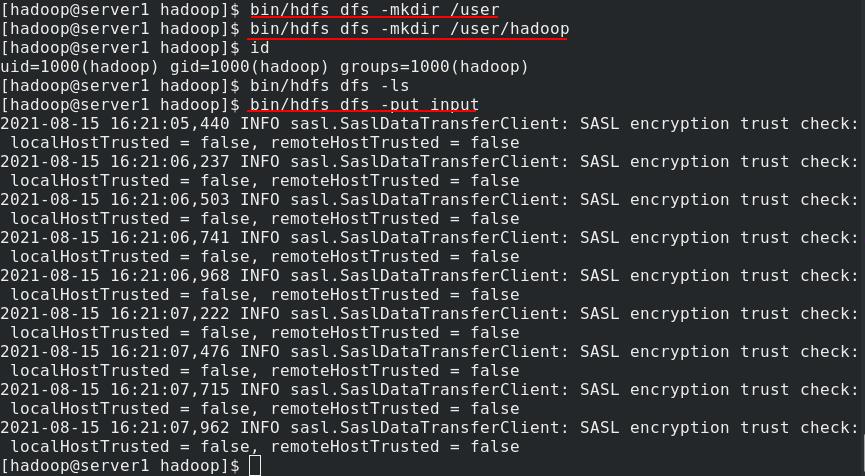
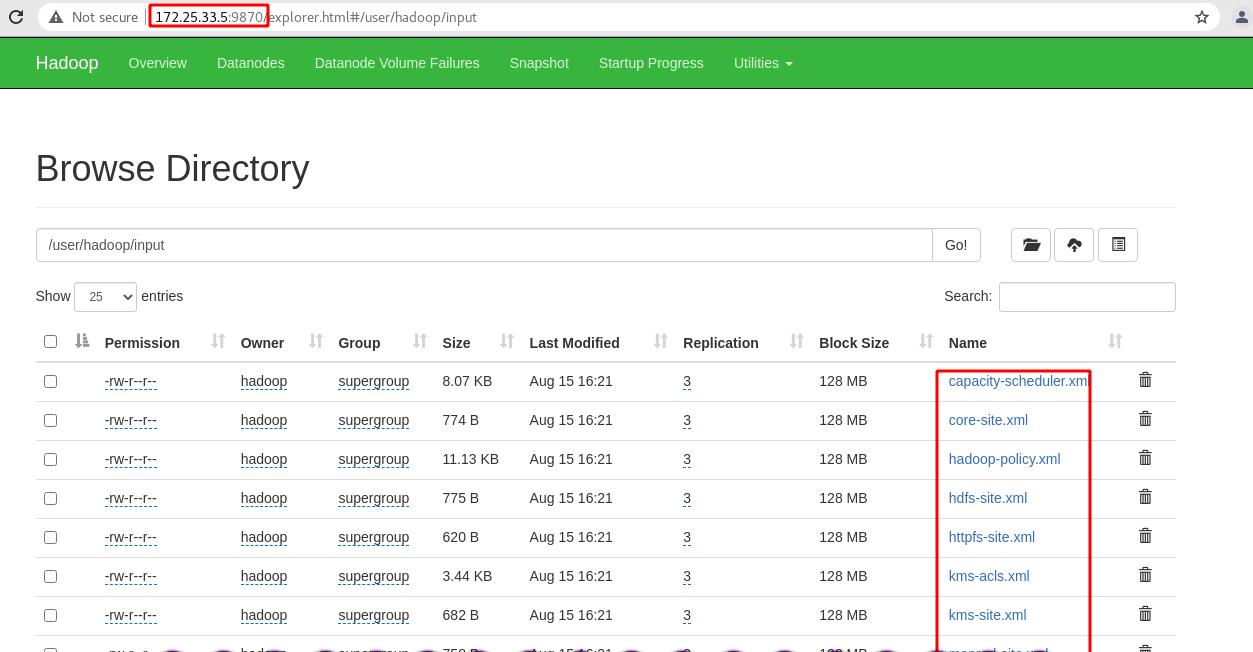
先登录server1的hadoop管理页面查看,可以正常访问/user/hadoop/input里的内容

查看capacity-scheduler.xml文件可以看到server2、server3和server4为hadoop集群主机

而在server5的hadoop管理页面就无法查看目录内容

1.3、高可用测试
server1查看NN进程id,杀掉该进程

server2与zookeeper保持着连接,查看NN主备,可以看到现在server5是主

浏览器访问server1的hadoop主页,无法访问

再访问server5的hadoop管理页面,可以看到现在显示server5是active

server5现在也可以正常查看文件系统目录内容
server1查看input目录正常,现在重新开启namenode进程

server1的hadoop管理页面现在可以正常访问,显示状态为备用

二、Yarn高可用
1.1、RM高可用部署
由于一个Yarn集群由一个ResourceManager节点和多个NodeManager节点组成,一旦ResourceManager节点宕机,那么YARN集群将不能进行资源的调度。
server1编辑yarn-site.xml

[hadoop@server1 hadoop]$ cat yarn-site.xml
<configuration>
## 配置可以在 nodemanager 上运行 mapreduce 程序
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
## 指定环境变量
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
## 激活 RM 高可用
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
## 指定 RM 的集群 id
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
## 定义 RM 的节点
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
## 指定 RM1 的地址
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.33.1</value>
</property>
## 指定 RM2 的地址
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.33.5</value>
</property>
## 激活 RM 自动恢复
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
## 配置 RM 状态信息存储方式,有 MemStore 和 ZKRMStateStore
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
## 配置为 ZKRMStateStore 存储时,指定 zookeeper 集群的地址
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.33.2:2181,172.25.33.3:2181,172.25.33.4:2181</value>
</property>
</configuration>
server1启动yarn服务,可以看到ResourceManager是server1和server5

在server1和server5上均可以看到ResourceManager进程

server2上运行NodeManager进程

server3上运行NodeManager进程

server4上运行NodeManager进程

server2与zookeeper保持着连接,查看主备,可以看到rm1是主

浏览器访问server1的yarn资源管理页面,可以看到状态是active
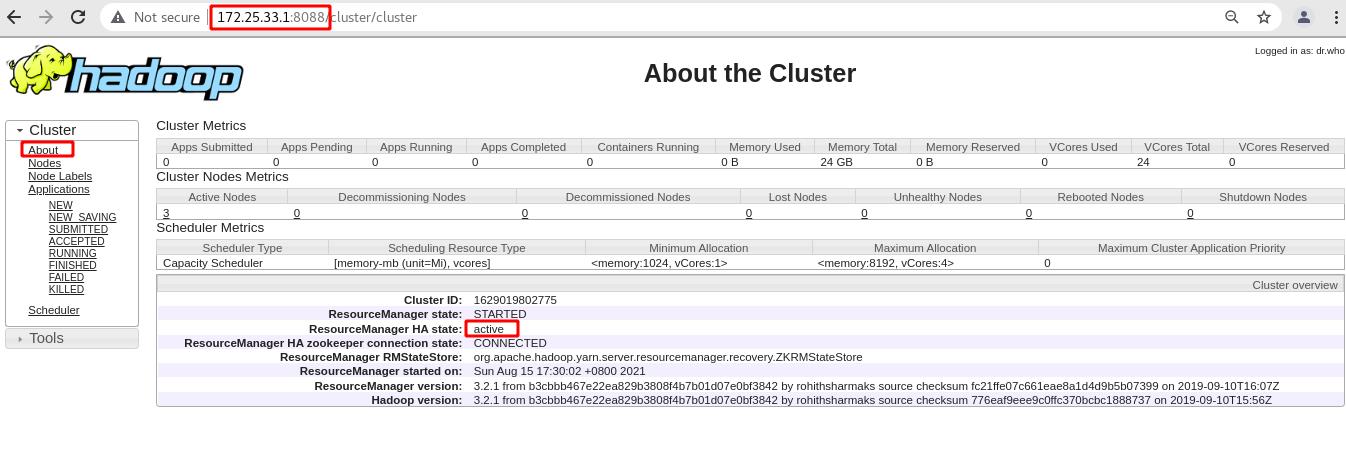
浏览器访问server5的yarn资源管理页面,查看状态是standby备用
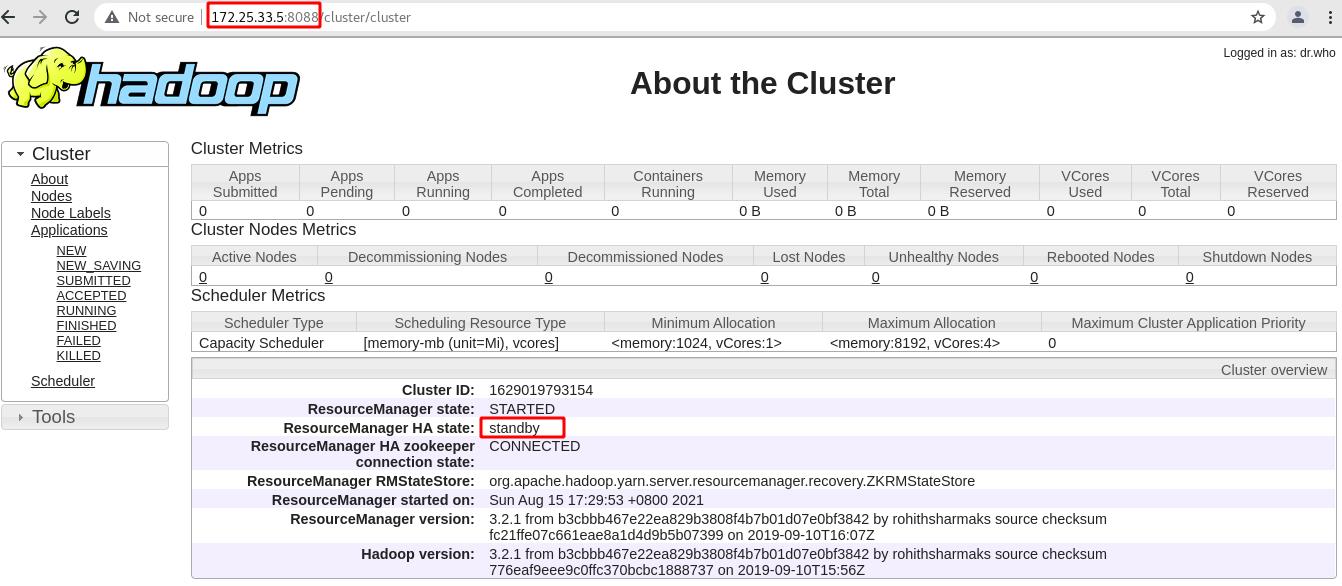
1.2、RM高可用测试
server1查看RM进程的id,然后杀死该进程

浏览器访问server5的yarn资源管理页面,查看状态,现在变成了active活跃

server1再重新开启RM进程

浏览器访问server1的yarn资源管理页面,查看状态,现在server1是standby备用

三、hbase高可用
真实主机将hbase包发送到server1的/home/hadoop目录下

server1收到hbase压缩包后进行解压,然后进入hbase目录。再进入conf目录
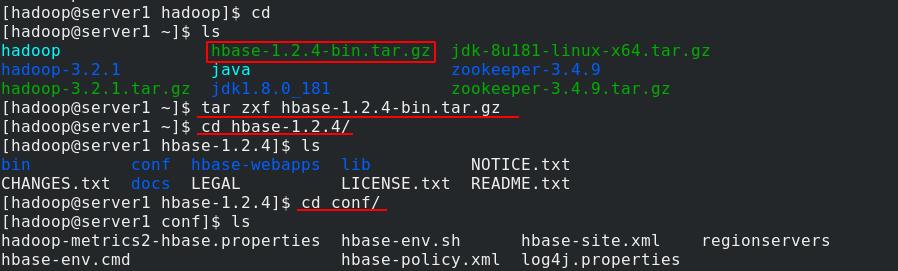
编辑hbase-env.sh环境变量配置文件,HBASE_MANAGES_ZK参数设为false,因为hbase自带zk,而我们已经配置好了

填入java和hadoop的环境变量

再编辑hbase-site.xml文件
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
## 启用 hbase 分布式模式
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
## 配置zk集群节点的地址
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.33.2,172.25.33.3,172.25.33.4</value>
</property>
## 指定hbase的master
<property>
<name>hbase.master</name>
<value>h1</value>
</property>
</configuration>

编辑完成并保存

server1编辑regionservers文件,输入zk集群的节点ip

由于文件系统共享,server5可以直接进入到hbase目录下,作为主节点运行hbase,jps查看可以看到HMaster进程

server1作为备用节点运行hbase,jps查看可以看到HMaster进程

server2、server3和server4可以看到本地运行HRegionServer进程作为集群节点



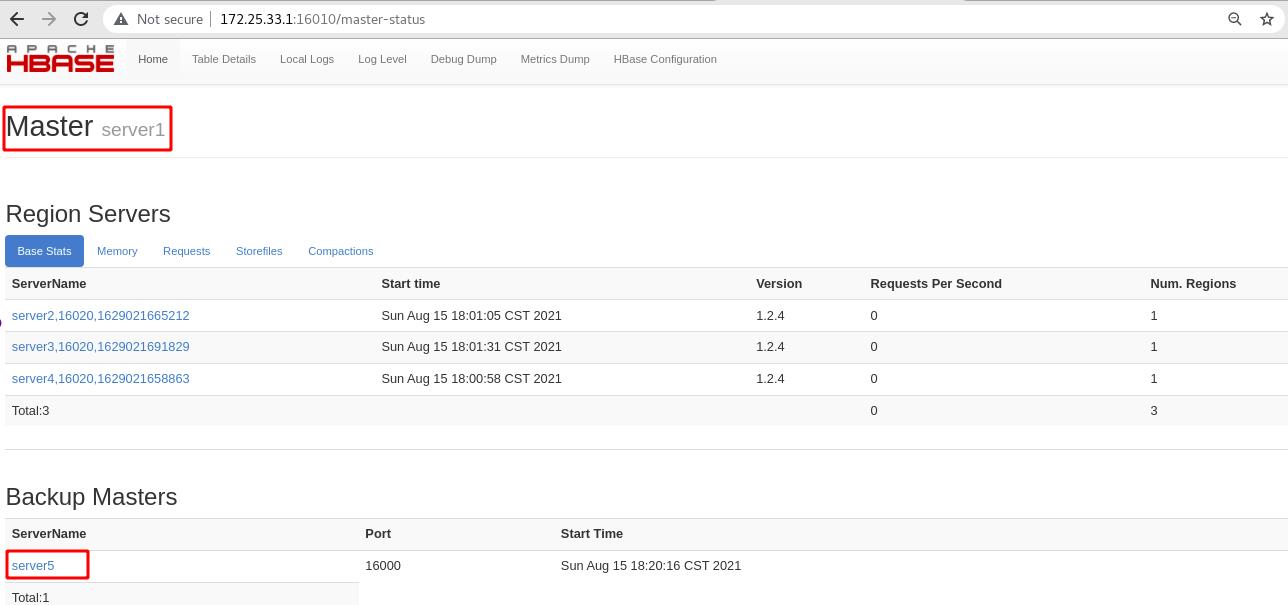
浏览器访问server5的16010端口进入hbase管理页面,可以看到身份是Master,还可以看到集群节点server2、3、4和备用节点server1

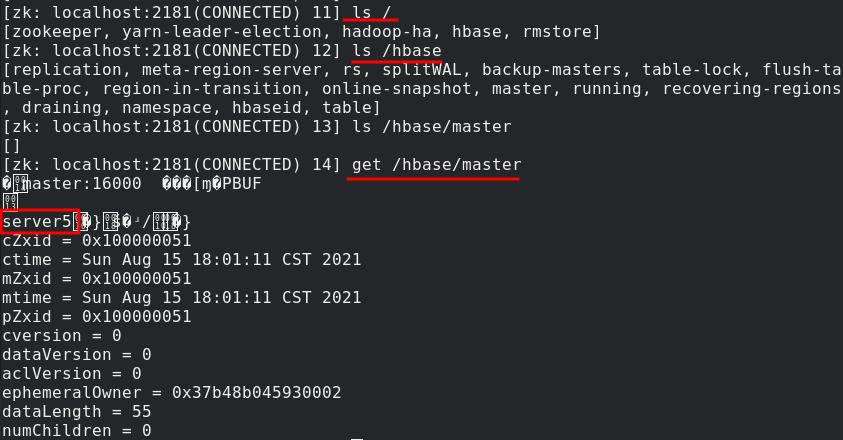
server2与zookeeper保持着连接,查看hbase的master,可以看到是server5
测试:
server5进入hbase shell,创建test表
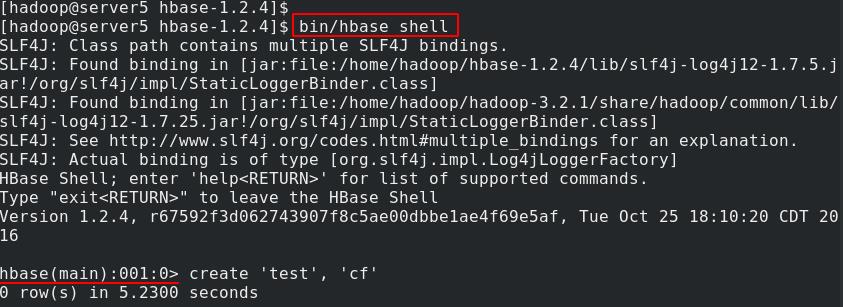
向test中插入数据,查看test内容

server5查看HMaster进程ID,杀死该进程

浏览器访问server1的16010端口进入hbase管理页面,可以看到现在server1是Master,备用主节点无内容

浏览器访问server5的16010端口进入hbase管理页面,但是已经无法访问

server5作为备用主节点启动hbase

在hbase管理页面中可以看到server1还是master,备用主节点为server5
server2与zookeeper保持着连接,查看hbase的master,可以看到现在是server1

server5再次进入hbase shell,查看test内容,内容依然存在,正常显示

浏览器访问server5的9870端口进入hadoop页面,可以看到hbase目录

进入hbase目录下可以正常查看目录内的文件

以上是关于Linux企业运维——Hadoop大数据平台(下)hdfs高可用Yarn高可用hbase高可用的主要内容,如果未能解决你的问题,请参考以下文章