你也能看懂Hadoop——Hbase
Posted Hadoop大数据应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你也能看懂Hadoop——Hbase相关的知识,希望对你有一定的参考价值。


上一期我们了解了Hadoop框架下的一个分布式数据库组件--Hbase。就如同情景对话里的情况一样,Hbase有它的优点也有它的局限:对于直接提取列族中数据这样的需求,Hbase完成能够胜任,但是如果需要进行复杂的分析计算,Hbase则显得心有余而力不足了。这时需要Hadoop的另一个组件:Hive来帮用户解决问题。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的类SQL查询功能,可以将类SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
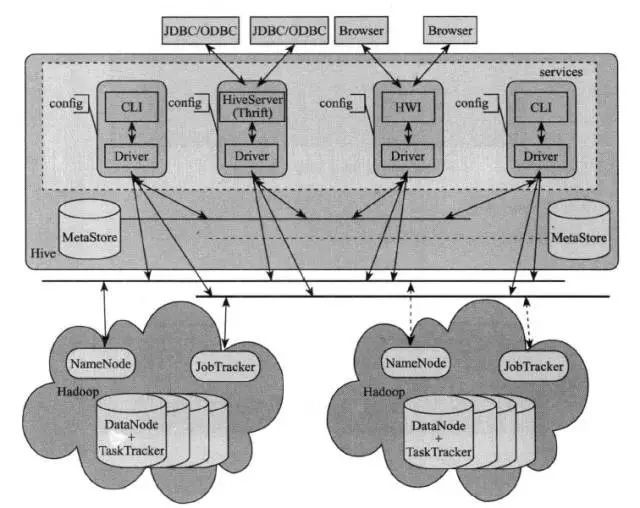
Hive的用户接口主要有三个:CLI , Client和WUI(HWI)。CLI 是Hive的命令行界面,用户通过输入操作指令进行操作查询Hive。Client是Hive的客户端,WUI则是通过浏览器访问Hive。用户连接进入Hive Server以后,通过HQL(类SQL)语句访问Hive数据仓库,查询自己所需要的数据。Hive Server中包含Thrift服务组件,它提供了与其他数据库如ODBC,JDBC链接的服务。
驱动模块(Driver)主要包括解析器,语义分析器,逻辑策略分析器,优化器四个部分。因为用户与Hive交互主要使用的是HQL语句,Driver的作用便是将HQL翻译成具体的指令去执行。解析器将HQL查询字符串解析成解析树表达式,语义分析器则将解析树表达式查询所涉及的列和表进行正确性验证,最后生成内部查询表达式。逻辑策略分析器则将这些内部表达式转换成逻辑策略,在MapReduce 和HDFS中执行相应的操作。优化器则是处理出现在HQL语句中的聚合函数等复杂语句。
Hive的元数据主要包括:表的名字,表的列,分区,表的属性,表的数据所在的目录等。这些数据并没有存储在HDFS中,而是存储在mysql,Derby这样的数据库中,在架构图中用MetaStore表示。
Hive中没有定义专门的数据格式,数据格式可以由用户指定,但需要用户指定列分隔符,行分隔符以及读取文件的格式。Hive默认有三种文件格式可以读取,分别是TextFile、SequenceFile以及RCFile。Hive加载数据时不会对数据本身进行任何修改,只是将数据内容复制或者移动到相应的HDFS目录中。
Hive的数据存储在HDFS中,大部分的查询任务都被解释成MapReduce任务来执行,只有少部分任务(如:查询整张表)直接到HDFS中执行读取文件。整个Hive的架构如下图所示:
之前我们对比了Hbase 与关系型数据库RDBMS的区别,现在我们来对比一下Hive与RDBMS,对比结果如下表所示:
| Hive | RDBMS | |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 索引 | 无 | 有 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
通过上表的对比,我们可以发现Hive的特点:
●查询语言
由于SQL被广泛应用在数据仓库中,因此Hive特性设计了类SQL的查询语言HQL,让熟悉SQL的用户可以方便的使用Hive进行开发。
●索引
Hive在加载数据时不对数据进行任何处理,因此当Hive要访问数据中某个条件的特定值时,需要暴力扫描整个数据,造成访问延迟较高。但由于MapReduce的引入,对于大数据量的访问,Hive仍然可以体现出优势。
●执行及延迟
Hive的大多数查询时通过MapReduce实现了,但由于Hive在查询数据时没有索引,需要扫描整个表,同时MapReduce本身也具有较高的延迟,所以在利用MapReduce执行Hive查询时,会产生较高的延迟。只有在数据规模较大时,Hive的并行计算才能体现出优势。
●可扩展性及规模
Hive建立在Hadoop之上,因此Hive的可扩展性和Hadoop的可扩展性是一致的。而RDBMS数据库由于其设计原因严格限制,扩展性非常有限。Hive也可以因此利用MapReduce进行并行计算,支持很大规模的数据。
小结:
Hive是基于Hadoop的一个数据仓库,它的数据大部分存储在HDFS上,它支持类似SQL语言来代替MapReduce,这使得不会写代码的数据分析师也能利用Hadoop平台对海量数据进行分析。
文章转载自:华星智能制造规划处
Hadoop大数据应用
你也能懂大数据
以上是关于你也能看懂Hadoop——Hbase的主要内容,如果未能解决你的问题,请参考以下文章