重要你也能看懂Hadoop——Hadoop生态体系
Posted Hadoop大数据应用
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重要你也能看懂Hadoop——Hadoop生态体系相关的知识,希望对你有一定的参考价值。
数据分析师
Hadoop最重要的几个组件,我已经介绍完啦,你是否都看明白了呢?
工程师
虽然听了你前几期的介绍,但是我对Hadoop还是感觉一头雾水啊。


数据分析师
那是因为前几期都是分开组件介绍,重点是阐述原理,今天我们在之前理解的基础之上,用漫画的形式再回顾一下它们的作用。理解了他们,咱们再来了解一下Hadoop的生态体系架构。
Hadoop的核心技术
Hadoop的核心技术都是为了把传统的单点式结构转变为分布式结构:把单机文件存储转变为分布式存储——HDFS;把单机计算转变为分布式计算——MapReduce;把单机数据库转换为分布式数据库——Hbase和Hive。我们在前几期介绍原理的基础上,通过如下漫画再来理解Hadoop的这4个组件。
HDFS原理


单点存储者

数据太大了,仓库(硬盘)装不下,查找起来也费劲。
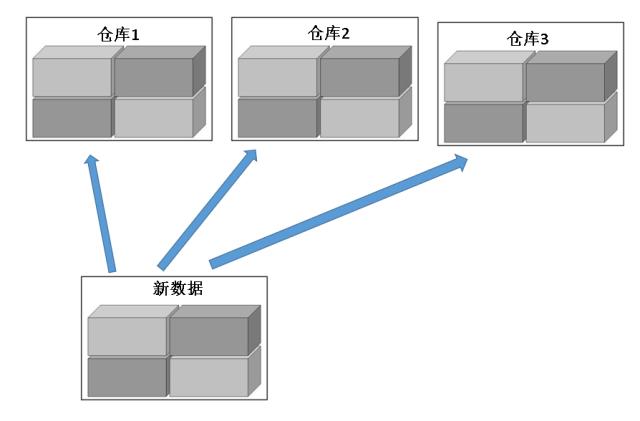

HDFS
把数据拆分成标准大小,分别放进不同的仓库里,某个仓库失火了也不怕,其他仓库有备份。
NameNode
我管理所有的仓库,所有数据放在哪个库哪个角落我都清楚,你要找数据问我就行。
MapReduce原理

用户
我这里有1亿个数据,你赶紧告诉我这一亿个数据中最大的是多少。
单点计算者
一亿个数据,我脑子都装不下这么多数据,更别说找它们的最大值了。
用户
我这里有1亿个数据,你赶紧告诉我这一亿个数据最大的多少。
MapReduce
没问题,我不是一个人在战斗。

我来计算前100万个数据的最大值
我来计算中间100万个数据的最大值
我来计算最后100万个数据的最大值

我来将大家计算的结果汇总,再计算一次最大值,汇报给领导。
Hbase原理

仓库管理者
数据存进仓库以后,没好的方法管理,太混乱了想找个数据可难了。

同一列族的数据放在一个“货架”上,并标上序号。
Hbase
我来帮您解决问题,我告诉你哪些数据是一类(同一CF列),你将它们放在同一个货架上,再编上号。这样用户再查找某一列族的数据就不费劲了。
Hive原理
仓库管理者
如果用户查的是列族中某些数据的复杂计算,怎么办?
例如下图中,用户要查第7货架第3行的前两个数据与第3货架第3行的第6,7个数据之和。

Hive
这个问题我在行!交给我的团队去做吧。HQL,MapReduce,HDFS干活了!

HQL解析者
我来做用户需求分析,将用户需求转换成数据提取需求和计算需求,交付给MapReduce和HDFS。
MapReduce
分布式计算交给我,我不是一个人在战斗。
HDFS
数据存放在哪里我最熟,找数据尽管来问我。
Hadoop生态体系架构
在Hadoop介绍的最后,我们来看看完整的Hadoop 1.x 版本所包含的组件有哪些:
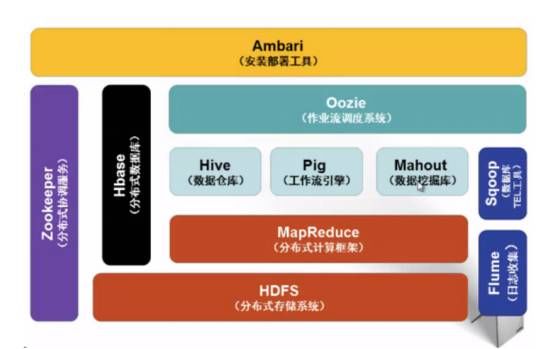
在前几期的介绍中,我们重点介绍了HDFS,MapReduce,Hbase,Hive 4个重要组件,也了解了Zookeeper对Hbase的协助作用,它们在Hadoop的架构中占据了半壁江山。其他的一些组件虽然没有他们那样举足轻重,但也各司其职,发挥着不同的作用,让我们来了解一下吧。
Pig
Pig的作用与Hive类似,Pig 包括对数据进行分析的脚本语言以及对程序进行评估的基础结构。它突出的特点是经得起大量并行任务的检验,能够处理大规模数据集。
Mahout
Mahout 是一个基于分布式计算的机器学习算法库,主要包括:频繁模式挖掘,聚类,分类,推荐引擎,频繁子项挖掘5个部分。
Sqoop
如果想要从传统的关系型数据库传数据到Hadoop体系中,Sqoop便不可缺少。Sqoop使用MapReduce任务来完成Hadoop与关系型数据库之间的数据传输,实现高并发,高容错。
Oozie
Oozie提供了一个可视化的Hadoop任务调度系统,当Hadoop任务逻辑复杂时,用户可以通过Oozie对这些任务进行管理和编辑。
小结
相信通过今天对Hadoop核心技术的回顾和整个生态体系的讲解,大家对Hadoop框架有了更深入的了解。对Hadoop的基础讲解也告一段落了,大家还想听什么内容呢?或者有任何的建议和疑问,欢迎在留言区和我互动。
文章转载自:华星智能制造规划处
Hadoop大数据应用
你也能懂大数据
以上是关于重要你也能看懂Hadoop——Hadoop生态体系的主要内容,如果未能解决你的问题,请参考以下文章